
一个反直觉的事实:把Agent从1个加到10个,效果不但没提升,错误反而被放大了17倍。
这是Google DeepMind白纸黑字的实验结论。
过去两年,整个AI圈都在疯狂堆Multi-Agent,仿佛Agent数量越多就越智能。
但真正在生产环境里摸爬滚打过的人都知道,事情远没有那么简单。
这话听着糙,但逻辑是对的。
你想想,如果大模型天生就能记住所有行业知识,精准执行每一个任务,那今天我们折腾的RAG、Multi-Agent、Workflow,全都没有存在的必要。
问题就在于,现在的模型既记不住海量领域知识,也管不好长期记忆。
早期大家的思路是向内改,用SFT、DPO微调,用RLHF强化学习,想把知识刻进模型参数里。
但踩过坑的人都知道,这条路有三个致命问题:训练成本高到离谱,效果评测极难量化,最要命的是你花三个月训完的模型,新基座一出来直接碾压你,刚毕业就失业。
既然向内改模型走不通,大家就开始向外搭架构。
用工程手段帮模型检索知识、组装上下文、维护记忆。
从最简单的提示词注入,到RAG检索增强,再到多智能体协作,本质上都是在模型外面搭脚手架。
这就是Agent架构不断进化的底层逻辑。
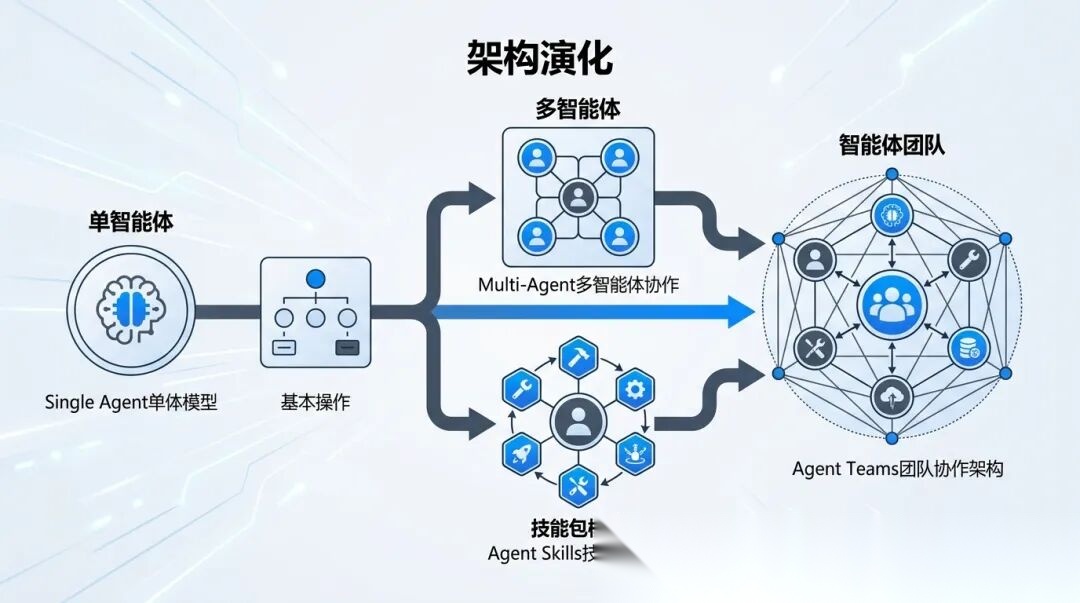
最原始的方案就是单Agent:把领域知识塞进System Prompt,让模型用ReAct模式串行调工具、解决问题。开发快、链路短、效率高,验证想法的性价比拉满。
但它有一个致命瓶颈,上下文窗口会爆炸。
别被支持百万Token的宣传忽悠了。
实际生产中,你真把海量文档扔给模型,它大概率会Lost in the Middle,注意力分散,关键信息直接被淹没。
长上下文不等于长记忆,这是很多人交了学费才明白的事。
于是RAG来了,先搜后答,只把最相关的片段喂给模型。
听起来很美对吧?但RAG的效果完全取决于前置检索的质量。
检索用的是BERT、BGE这类小模型,语义理解能力跟大模型差了好几个量级。
搜错了,后面模型能力再强也白搭,垃圾进,垃圾出。
所以单Agent的适用边界很清楚:业务逻辑简单、核心知识两万Token内能说清楚、检索准确率有保障。
满足这三个条件,单Agent就是最优解,别折腾了。
知识量一大,单Agent扛不住,Multi-Agent就上场了。
一个主Agent负责路由分发,一堆子Agent各管一个垂直领域,知识隔离、独立调优,听起来很工程化。
实际用起来呢?两个大坑等着你。
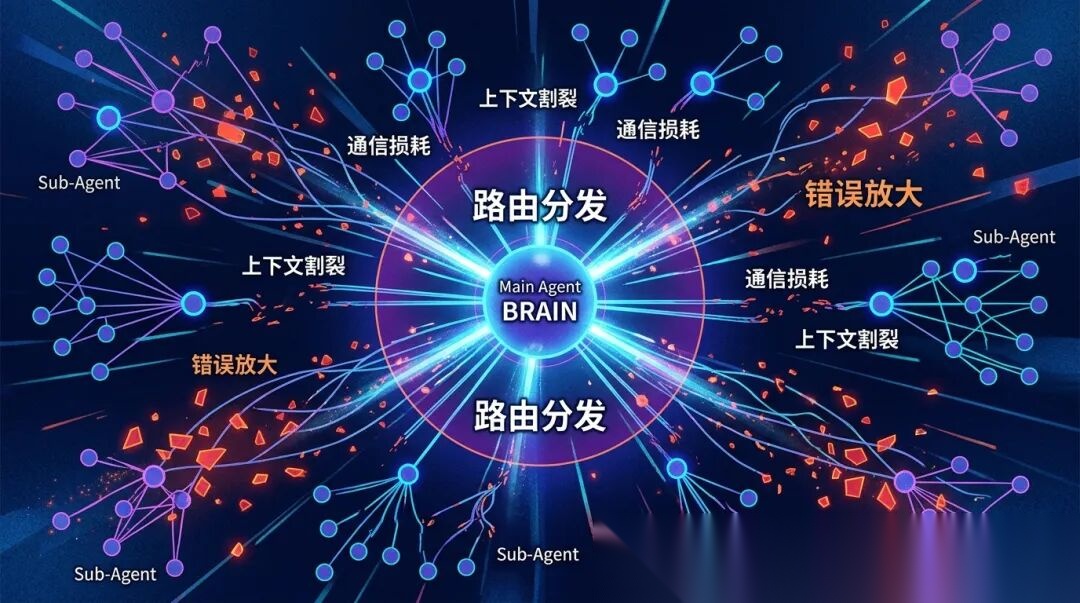
第一个坑:路由准确率。
当子Agent数量到了几十上百个,主Agent要在极短的上下文里判断这问题该交给谁。
一旦路由错了,后面全白干。
Agent越多,这个风险越高,是真正的一着不慎,满盘皆输。
第二个坑更隐蔽:上下文割裂。
子Agent各干各的,彼此不知道对方做了什么。
用户问ECS连不上,Agent A查了负载;用户追问为什么负载高,Agent B接手后又查了一遍负载,重复劳动、结论冲突,用户体验直接崩盘。
你说让Agent之间共享上下文?可以,但共享就意味着通信开销。信息压缩会丢关键细节,不压缩又Token爆炸。
Google的实验数据也证实了这一点:固定Token预算下,Agent间沟通越频繁,整体效果越差。
Anthropic提出了一个思路,不堆Agent数量,而是给单个Agent装上技能包。
核心逻辑是这样的:把领域知识封装成一个个独立的Skills文件,像操作手册一样。
Agent运行时不预加载所有知识,而是根据当前任务动态读取对应的Skills。
读一点、做一点、再读一点,渐进式披露。
这里有个关键的技术细节,很多人之前试过动态替换System Prompt,效果很差。
因为System Prompt变了,但对话历史还是基于旧指令生成的,模型直接精神分裂。
Agent Skills的做法不一样。
System Prompt始终不变,保持模型人设和核心指令的稳定;
Skills内容通过User Prompt动态注入,模型把它理解为用户提供的新参考资料,而不是身份被篡改了。
认知冲突消除了,输出质量就稳了。
这个方案的好处非常明显。
知识注入成本比Multi-Agent低得多,比RAG精准得多;
全程一个Agent执行,上下文完全一致,没有信息割裂;
通过流式加载控制瞬时上下文长度,不容易爆炸。
对大多数企业级场景来说,这可能才是性价比最高的方案。
Anthropic还提出了Agent Teams,多个Agent并行探索同一个问题,共享上下文,实时感知队友进度。
它不是为了解决知识注入,而是为了应对那些完全没有标准答案的复杂未知问题。
一个Agent走一条路,走错了全盘皆输。
Agent Teams同时走五条路,最后挑最好的那条,或者把多条路的优点融合。
代价是算力成本成倍增加,而且必须配套强大的中心化决策机制。
否则Google的数据告诉你,没有监管的集体智慧会变成集体幻觉,错误放大17倍。
Google DeepMind那篇论文里有个45%阈值法则,当单Agent的任务成功率超过45%时,加Agent数量的收益就开始递减,甚至变成负的。
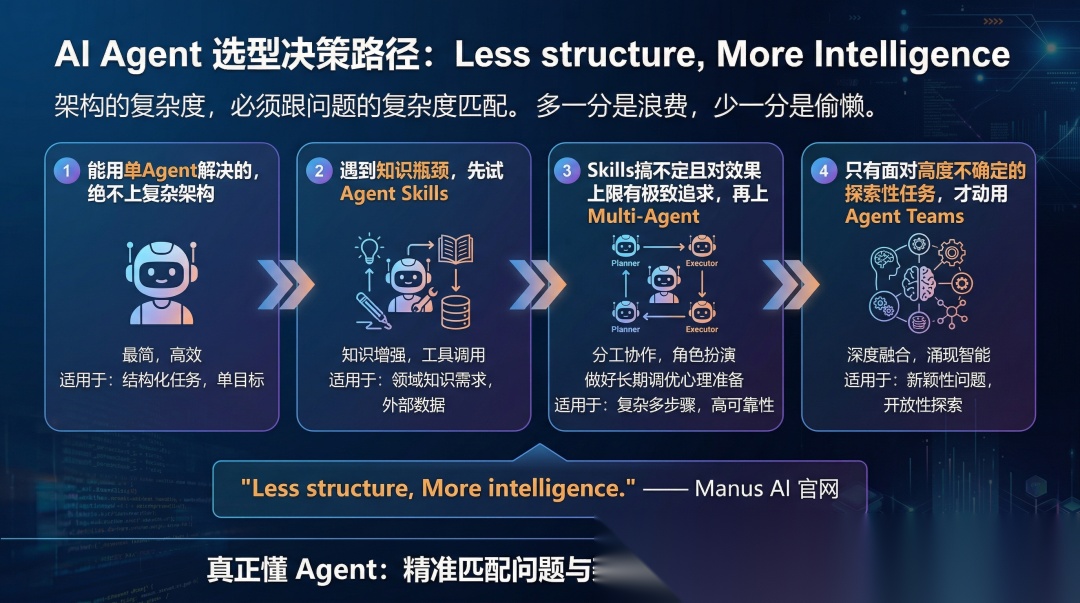
所以选型路径应该是这样的。
能用单Agent解决的,绝不上复杂架构;
遇到知识瓶颈,先试Agent Skills;
Skills搞不定且对效果上限有极致追求,再上Multi-Agent,做好长期调优的心理准备;
只有面对高度不确定的探索性任务,才动用Agent Teams。
Manus AI官网有句话说得好:Less structure, More intelligence。
架构的复杂度,必须跟问题的复杂度匹配。多一分是浪费,少一分是偷懒。
能把这个度拿捏住的人,才是真正懂Agent的人。
假如你从2026年开始学大模型,按这个步骤走准能稳步进阶。
接下来告诉你一条最快的邪修路线,
3个月即可成为模型大师,薪资直接起飞。

阶段1:大模型基础

阶段2:RAG应用开发工程

阶段3:大模型Agent应用架构

阶段4:大模型微调与私有化部署

配套文档资源+全套AI 大模型 学习资料,朋友们如果需要可以微信扫描下方二维码免费领取【保证100%免费】👇👇






配套文档资源+全套AI 大模型 学习资料,朋友们如果需要可以微信扫描下方二维码免费领取【保证100%免费】👇👇

版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/249492.html