
究竟是一篇什么样的中国 AI 论文,能让马斯克等一众硅谷大佬在深夜的 X(推特)上疯狂讨论?答案就是 Kimi 最新发布的架构级神作《Attention Residuals》。今天,我们将用最通俗的比喻带你拆解这篇“动了深度学习十年祖坟”的硬核研究,看看他们是如何激活成功教程大模型越深越笨的魔咒的。
更让人震撼的是,这篇引发硅谷巨头热议、动了深度学习十年祖坟的底层架构论文,其第一作者竟然是一位 17 岁的深圳高中生!
这篇论文之所以能引发如此轰动,是因为它动了深度学习过去十年来最神圣不可侵犯的基石——残差连接(Residual Connections)。
如果你了解过一点 AI 历史,一定知道何恺明在 2015 年提出的 ResNet(残差网络)。在它之前,神经网络只要稍微深一点(比如超过20层),就会因为“梯度消失”而彻底**——因为信号在层层传递中衰减了。
残差连接给出的解法极其优雅且简单粗暴:。 也就是:下一层的输入 = 上一层的输出 + 当前层的新特征。 这就像是给信息修建了一条直通车道(Highway),让早期的原始信号可以无损地跨越层级传递。自此,Transformer、GPT-3、甚至 GPT-4,所有的现代大模型都在沿用这个公式。
但到了 2026 年,当我们的大模型动辄几百层、上万亿参数时,这个简单粗暴的“直接相加”出大问题了。在学术界,这被称为 PreNorm 稀释(PreNorm Dilution)问题。
为了让你秒懂,我们打个生活化的比喻——“工厂流水线”与“大锅炖”:
假设大模型的每一层(Layer)都是流水线上的一个工人,他们的任务是一起熬一锅绝世好汤(最终的语义表征)。
- 传统的残差连接怎么做? 1号工人往锅里扔了一把盐,2号工人扔了一把胡椒,然后直接把整锅汤原封不动地递给3号工人。3号工人不管三七二十一,闭着眼睛往这锅已经混杂了盐和胡椒的汤里,再倒半瓶酱油。
- PreNorm 怎么起作用? 为了防止这锅汤味道太重(数值爆炸),每经过一个工人,系统就会强制加一桶水把汤稀释一下(Layer Normalization)。
当这锅汤传递到第 80 个、第 100 个工人手里时,由于经历了太多次的“无脑相加”和“强制稀释”,1号工人放的那把盐(浅层特征)、甚至是 50 号工人放的葱花(中层特征),早就被稀释得连味儿都尝不出来了! 同时,深层的工人发现,无论自己往锅里加什么,最终都会被庞大而浑浊的“历史残留汤底”所掩盖,于是他们开始“摆烂”——导致深层网络中出现了大量无效计算(Lazy Layers)。所有的特征都糊在了一起,网络变得“臃肿且迟钝”。
目前几乎所有的大模型都采用 PreNorm(前置层归一化)+ 残差连接 的标准配置。
在传统残差结构中,第 层的输出计算公式非常简单:
如果你把这个公式从第 1 层一直展开到第 层,它实际上长这样:
看懂这个展开式,你就看懂了“稀释”的根源:第 层的输入,本质上是前面所有层输出的“无差别等权求和”。
在这个公式里,不管是第 1 层还是第 99 层的输出,它们的权重全部固定为 1。网络就像一个没有重点的录音机,把所有历史声音都以同样的音量混在一起。
PreNorm 稀释 就像是大群聊里的“信息过载”。每个人都在群里发同样长的一条语音(等权相加),最后进群的人根本听不清群主(关键特征)一开始说了什么。
Kimi 提出的 Attention Residuals,就是为了打破这种僵化的“等权累加”。它用注意力机制(Softmax 加权)替换了那个固定的公式,让网络学会“屏蔽废话,精准倾听”,从而解决了数值膨胀和信息稀释的问题。
可以看看下图关于 PreNorm 稀释的图示
通过上面的模拟器你可以看到,当模型达到百层时,新特征的贡献度已经跌到了可怜的 10% 以下。这就是摆在 Kimi 以及全球所有大语言模型研究者面前的残酷现实:深层网络正在被陈旧的残差机制拖垮。
既然“大锅炖(等权相加)”不行,能不能让网络每一层自己决定要“品尝”历史中的哪一味料?这就是我们在下一章要讲的核心洞察——将注意力机制翻转 90 度的 Attention Residuals(注意力残差)!
大家都知道,Transformer 之所以伟大,是因为它的核心机制 Self-Attention(自注意力机制)。但传统的 Attention 是作用在 “序列维度(Sequence/Token Dimension)” 上的。 通俗地说:模型在读第 100 个词(Token)时,会回头去看前面的 99 个词,决定哪些词对当前重要。这是横向的“时间旅行”。
Kimi 的研究员灵光一闪:为什么我们不能把 Attention 翻转 90 度,应用到“深度/网络层维度(Depth Dimension)”上呢? 当网络运行到第 31 层时,它不应该只是机械地接收前面所有层的一锅烩,而是应该“回头审视”历史上的第 1 层、第 10 层、第 30 层,看看谁的特征对现在的计算最有帮助!这就是 Attention Residuals 名字的由来。
Kimi 团队一拍大腿:既然 Attention 这么好用,能帮一个字找到它最需要的其他字,那为什么不让它帮“层”找到最需要的“历史层”呢?
想象一个有 100 层的大模型,就像一个有 100 名警探参与的连环调查案。
- 第 1 层是最早去现场的警探,他收集了脚印。
- 第 2 层警探拿到了脚印,又找到了凶器。
- 以此类推……
在传统的残差连接下,信息是怎么传递的呢? 第 100 层的“总探长”要下结论时,他拿到的案卷,是前 99 个警探把自己的报告直接用订书机钉在一起的超级大合集。 总探长被迫把这 99 份报告同时、同等用力地看一遍(等权相加)。结果就是:大量无用的废话掩盖了第 1 层警探那至关重要的“脚印”线索。这就是之前说的“稀释”。
加上了这个新机制后,第 100 层的“总探长”不再去啃那份厚厚的混合报告了。他现在有了自己的一套所谓的机制运作:
- 第一步:提出需求(Query / Q)
第 100 层生成了一个自己的“提问向量”。这就好比总探长广播了一句:“我现在需要关于嫌疑人鞋码的信息,谁有?”
- 第二步:历史层亮出招牌(Key / K)
前面 1 到 99 层的警探,每个人手里都举着一个牌子(代表他们各自提取的特征)。第 1 层举着“我有脚印”,第 50 层举着“我有财务记录”。
- 第三步:智能匹配与拿取(Value / V & Attention Weight)
总探长的需求(Q)和第 1 层警探的牌子(K)完美匹配上了!
于是,系统自动给第 1 层分配了 90% 的注意力权重,给第 50 层分配了 1% 的权重。总探长直接跨过中间几十层,精准提取了第 1 层的具体报告(V)。
总结一下它的“诞生逻辑”
Kimi 创造这个机制,本质上就是把原本用于“解决一句话里词汇关系”的技术,挪用到了“解决极深网络里不同层之间信息传递”的问题上。
它把原本僵化的、必须一层层强行累加的物理直达管道(残差),改造成了一个可以随时根据当前需要,向前面任意一层索要信息的智能调度中心(注意力残差)。
用下图做个简略的讲解吧
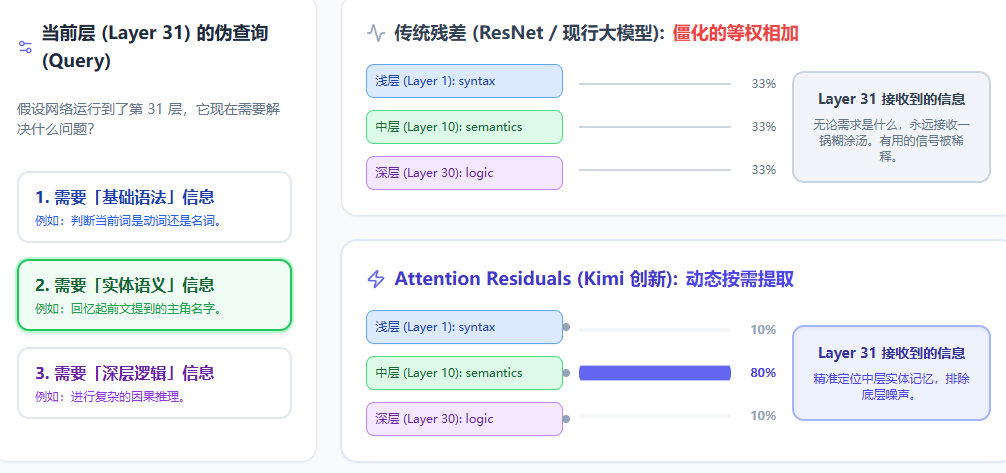
而在 Attention Residuals 中,Kimi 引入了 Softmax 注意力加权:
- 可学习的伪查询(Learnable pseudo-query, ): 在传统的 Attention 里,Query 是由当前输入的词算出来的。但在 AttnRes 里,当前层(比如第 31 层)拥有一个自己专属的、可以在训练中不断学习优化的“雷达信号”(也就是伪查询向量 )。这就好像第 31 层的工人自带了一个对讲机,时刻广播:“我现在需要解决复杂的逻辑问题(Query)!”
- 历史层作为键值(Keys & Values):
前面所有的层(从 1 到 30 层)输出的特征,就是 Keys 和 Values。
- 点积与 Softmax(动态分配权重):
第 31 层的雷达信号()会和前面每一层的特征(Keys)计算匹配度(点积)。如果第 30 层的逻辑特征最匹配,它的得分就高。最后通过 Softmax 归一化,可能第 30 层获得了 80% 的权重,而只懂简单语法的第 1 层只分配到 5% 的权重。
结果就是:网络从“被动接受垃圾桶”,变成了“主动去自助餐厅按需取餐”。 浅层的原始信号不再被无意义地稀释,深层网络也终于摆脱了沉重的历史包袱,重新焕发了活力!
至此,理论上完美了。但是!任何一个算法工程师看到这里都会惊出一身冷汗。
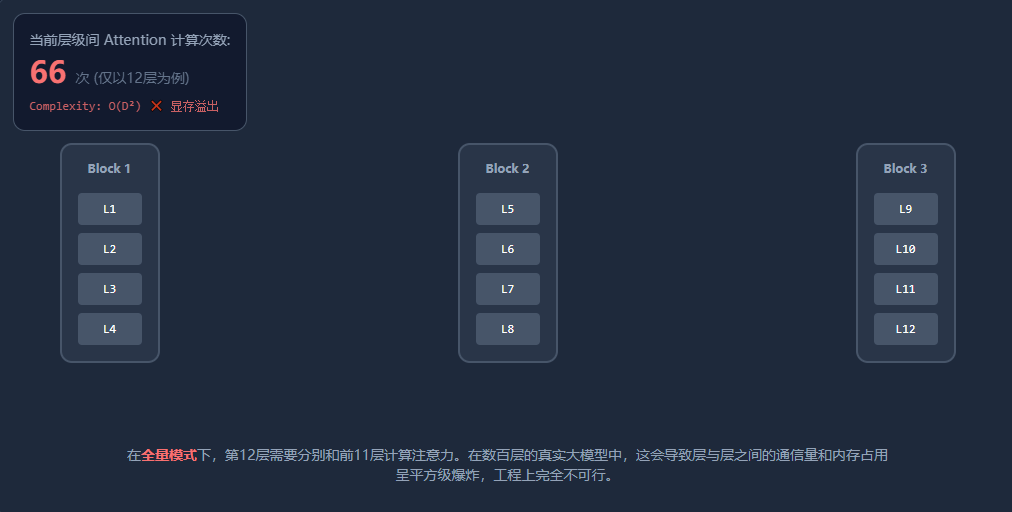
因为如果第 100 层要和前面 99 层算一遍注意力,第 1000 层要和前面 999 层算一遍……这会导致显存爆炸( 的复杂度),工程上根本没法落地!
Kimi 是如何用极其硬核的工程手段跨越这堵“算力墙”的?
我们在第二阶段设想了一个完美的机制,但如果我们把这个机制直接生搬硬套到拥有 100 甚至上千层的大模型上,立刻就会撞上一堵物理层面的“算力墙”。
现实的算力墙: 的灾难
在理想的 全量注意力残差 (Full AttnRes) 中,假设网络有 层,每一层都需要去回顾它前面的所有层。
- 第 2 层需要计算 1 次;
- 第 100 层需要计算 99 次;
- 总计算次数和内存占用量,是一个高斯求和公式:。
这在数学上叫做 的深度复杂度。这意味着,模型的层数每翻一倍,用于残差连接的计算量和显存(为了保存每一层的特征输出,需要巨量的 KV Cache)就会翻四倍!在几万张 GPU 组成的算力集群中,层与层之间的频繁通信会直接把通信带宽撑爆。
分块策略 (Block AttnRes):既要效果,又要速度
Kimi 的算法工程师们极其聪明地采取了“粗细结合”的工程化折中方案,提出了 Block AttnRes(分块注意力残差)。
其核心逻辑如下:
- 打包建块 (Blocking): 将总共 层的网络,切分成 个块(Block),每个块里面包含 层()。比如 100 层的网络,分成 10 个 Block,每个 Block 包含 10 层。
- 块内 (Intra-block) - 维持现状: 在一个 Block 内部的这 10 层,依然使用最传统的 ResNet 等权相加残差:
为什么?因为局部几层之间的特征差距不大,“大锅炖”依然有效且计算极快。
- 块间 (Inter-block) - 动态聚合: 当一个 Block 的计算彻底结束时,才召唤注意力机制,去回顾前面所有 历史 Block 的输出特征。
严谨的数学逻辑(硬核警告)
我们用数学公式来严谨地定义 Block AttnRes 在第 个 Block 处的行为:
设 为第 个 Block 的最终输出特征向量。当我们准备输入第 个 Block 时,它的初始输入 不再是简单的上一层输出,而是之前所有 Block 输出的注意力加权和:
这里的权重 就是我们心心念念的注意力分数,它通过当前 Block 的可学习查询向量 (Learnable Query, ) 与历史 Block 的输出进行点积匹配,并经过 Softmax 归一化得出:
(注:是特征维度缩放因子,用于防止 Softmax 梯度消失)
降维打击:从 到
通过这个数学上的小手术,发生了什么奇迹?
原本层与层之间的注意力计算复杂度是 。
现在,我们只在 Block 之间计算,复杂度瞬间暴降为 ,也就是 !
如果 (每10层一个块),那么计算复杂度和通信开销直接被砍掉了 100 倍!
这就是工程架构的魅力——用 1% 的算力代价,换取了 99% 的 Attention Residuals 理论收益。 它彻底把这篇论文从“实验室里的漂亮玩具”,变成了“能真正在万卡集群上跑起来的工业界杀手锏”。
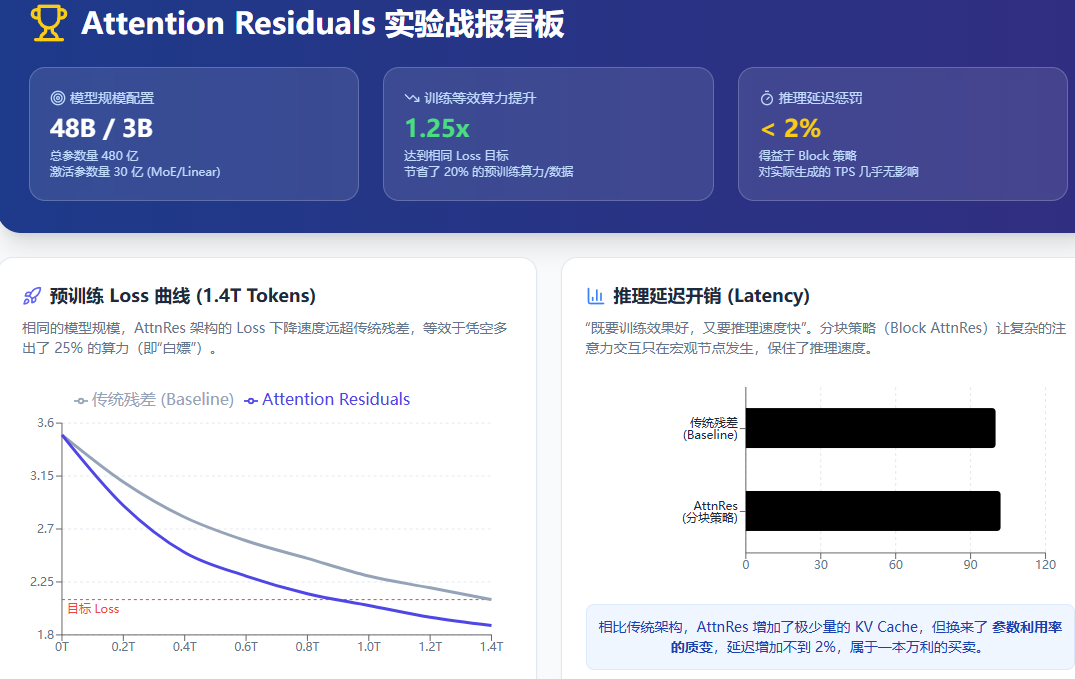
Kimi 团队没有停留在玩具模型上,而是直接在一个 Kimi Linear 架构(总参数 48B / 激活参数 3B 的 MoE 混合专家模型) 上,使用了 1.4T Tokens 的海量数据进行了严谨的预训练对比验证。
结合上面的面板,我们总结出两个最致命的结论:
- “1.25倍等效算力提升”的含金量: 在图表左侧的 Loss 曲线中你可以看到,要想达到特定的模型智能水平(验证集 Loss = 2.1),传统残差模型可能需要吃掉 1.4T 的数据;而使用了 AttnRes 的模型,在 1.0T 左右就达到了这个水平。 这意味着什么? 在当今大模型训练动辄耗费数千万美金算力的时代,1.25 倍的算力提升相当于为公司白白省下了 20% 的 GPU 集群使用费和时间成本。这不是通过增加参数堆出来的,而是纯粹靠“架构优化”白嫖来的!
- 几乎为零的推理惩罚(Free Lunch): 很多理论惊艳的架构(比如各种复杂的 Router 或动态路由),一到推理部署(Inference)阶段就因为极慢的生成速度被抛弃。但我们在第三期讲的 Block AttnRes(分块策略) 发挥了神效。因为它只在 Block 边界进行 Attention 聚合,最终对推理延迟(Latency)的增加不到 2%!这是极其罕见的“既要又要”的双赢结果。
降维评价:为何引爆硅谷,连马斯克都在关注?
这篇论文发布后,在 X(原 Twitter)上引起了广泛讨论,不仅是 AI 研究员,连马斯克等科技巨头也为之侧目。为什么它的影响力如此之大?
1. 动了深度学习过去十年的“底层祖坟” 自从 2015 年何恺明提出 ResNet,2017 年 Google 提出 Transformer 以来,残差连接(Residual Connection)就像是空气和水一样,被默认是“完美”的,十年间几乎没有任何本质的改动。 Kimi 团队这篇论文,第一次系统性、工程化地证明了:被奉为圭臬的传统残差,在千亿/万亿规模的极深网络中,已经成了阻碍模型变聪明的“毒瘤”。这种敢于挑战底层的创新,在被“大力出奇迹(Scaling Law)”统治的当下,显得尤为难得。
2. 打破了“模型深度”的物理封锁线 在过去的两年里,大家发现大模型可以做宽(增加维度、增加 MoE 专家数量),但很难做深。当层数超过 100 层后,由于我们第一期讲的“PreNorm 稀释现象”,再增加层数收益极低。 AttnRes 的出现,赋予了网络“深呼吸”的能力。它让极深网络(比如未来可能出现的 200层、500层大模型)成为可能,这极有可能开启大模型 Scaling Law(缩放定律)的一个新维度。
3. “中国 AI 力量”的底层话语权 这几年,AI 的底层架构创新(如 Transformer, MoE, FlashAttention)大多来自欧美科技巨头。而 Kimi(月之暗面)凭借这篇扎实的、在工业级规模验证过的底层架构论文,向世界证明了中国 AI 团队不仅能在“应用和算力优化”上卷,同样能在最核心的“大模型底层数学架构”上做出引领全球的创新。
从浅水区的“大锅炖”危机,到潜水区的“翻转 90 度”天才洞察;从深水区的“分块工程降维”,再到最终登岸的“1.25倍算力飞跃”。
Kimi 的《Attention Residuals》不仅仅是一篇漂亮的学术论文,它是打在现行僵化的大模型架构上的一记重拳。它告诉我们:在通往 AGI(通用人工智能)的道路上,仅仅靠堆显卡是不够的,对算法第一性原理的无尽追问,永远是突破物理极限的最强武器。
希望这次由浅入深的四段式拆解,不仅让你看懂了这篇前沿论文,也能让你感受到算法工程背后的极致之美!
很多媒体都在吹捧“注意力残差”的理论多牛,但我必须稍微泼点冷水:Idea 其实是廉价的。
其实吧,用 Attention 替掉残差这个点子,我打赌无数研究员都推导过,但又会发现 这个逆天的复杂度,又默默回去继续用 ResNet 了。
所以 Block AttnRes 的设计才是我觉得很惊艳的点,当然,目前的架构依然带有妥协的痕迹,它距离 100% 的完全体还有一段路要走。
我认为,接下来针对 Block 计算复杂度的极致优化,才是下一波大模型 Scaling 真正的重头戏。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/249239.html