

你是否有过这种烦恼?面对几百页的文档,问 AI 一个宏观问题,它要么只能搜到零星的片段,要么就开始胡言乱语。传统的 AI 搜索(RAG)就像是在图书馆里翻索引卡片,而 GraphRAG 则像是在你的文档上方织起了一张“知识图谱”,让 AI 不仅能“看到”文字,更能“读懂”关系。
简单来说,GraphRAG 是将知识图谱与大模型结合的黑科技。它不只是生硬地匹配关键词,而是把文档中的人物、地点、事件连成网,像人类大脑一样进行关联思考。
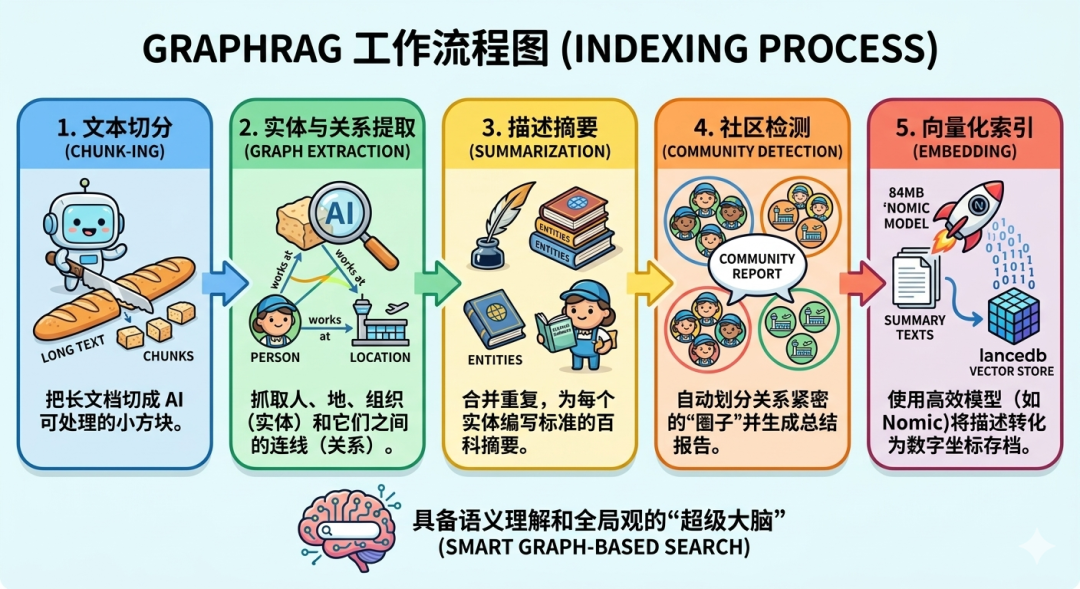
GraphRAG 是如何炼成的?
要把一堆杂乱的文档变成这个“超级大脑”,通常需要经历以下五个神奇的步骤:
- 切碎与拆解(Chunking)AI 先把长篇大论切成一个个“小方块”。这是为了确保后续处理时,每一段文字都能被精确“喂”给大模型。
- 抓取灵魂(Graph Extraction)这是最关键的一步。大模型会像侦探一样,从每个方块里抠出实体(谁)和关系(做了什么)。比如它能自动发现“临河镇”是一个地理位置,而“保洁员”正走在去那里的路上。
- 编写百科(Summarization)提取出的信息往往很零散。AI 会把重复的信息合并,为每一个独特的角色或地点写一段精准的“百科摘要”。这步完成后,图谱就有了血肉。
- 划分圈子(Community Detection)利用算法,系统会自动把关系紧密的实体聚在一起。就像社交圈一样,它能识别出哪些人属于同一个“社区”,并生成宏观的社区报告。
- 数字化存档(Embedding)最后,利用像 Nomic 这样轻量高效的模型,将所有的文字描述转化成电脑能读懂的“向量坐标”。
LM Studio 0.4.7+4 本地运行
向量模型:text-embedding-nomic-embed-text-v1.5
语言模型:qwen2.5-7b-instruct
假如你从2026年开始学大模型,按这个步骤走准能稳步进阶。
接下来告诉你一条最快的邪修路线,
3个月即可成为模型大师,薪资直接起飞。

阶段1:大模型基础

阶段2:RAG应用开发工程

阶段3:大模型Agent应用架构

阶段4:大模型微调与私有化部署

配套文档资源+全套AI 大模型 学习资料,朋友们如果需要可以微信扫描下方二维码免费领取【保证100%免费】👇👇






配套文档资源+全套AI 大模型 学习资料,朋友们如果需要可以微信扫描下方二维码免费领取【保证100%免费】👇👇

版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/249100.html