
近年来,AI大模型以惊人的速度发展,从BERT到GPT-3,再到如今的GPT-4,每一次突破都推动着人工智能技术的边界。作为技术从业者,理解这些模型的架构演进不仅有助于我们把握技术趋势,更能为实际应用提供指导。本文将深入解析从Transformer到GPT-4的完整技术演进路径。
1.1 自注意力机制的核心思想
2017年,Google在论文《Attention Is All You Need》中提出了Transformer架构,彻底改变了序列建模的方式。其核心创新在于:
# 自注意力机制的简化实现 import torch import torch.nn as nn import math class SelfAttention(nn.Module): def __init__(self, d_model, n_heads): super().__init__() self.d_model = d_model self.n_heads = n_heads self.head_dim = d_model // n_heads # 线性变换层 self.W_q = nn.Linear(d_model, d_model) self.W_k = nn.Linear(d_model, d_model) self.W_v = nn.Linear(d_model, d_model) self.W_o = nn.Linear(d_model, d_model) def forward(self, x): batch_size, seq_len, d_model = x.shape # 计算Q, K, V Q = self.W_q(x) K = self.W_k(x) V = self.W_v(x) # 多头注意力计算 Q = Q.view(batch_size, seq_len, self.n_heads, self.head_dim).transpose(1, 2) K = K.view(batch_size, seq_len, self.n_heads, self.head_dim).transpose(1, 2) V = V.view(batch_size, seq_len, self.n_heads, self.head_dim).transpose(1, 2) # 注意力分数计算 scores = torch.matmul(Q, K.transpose(-2, -1)) / math.sqrt(self.head_dim) attention = torch.softmax(scores, dim=-1) # 上下文向量 context = torch.matmul(attention, V) context = context.transpose(1, 2).contiguous().view(batch_size, seq_len, d_model) return self.W_o(context) 1.2 Transformer的架构优势
- 并行计算能力:相比RNN的顺序处理,Transformer可以并行处理整个序列
- 长距离依赖建模:自注意力机制可以直接建模任意位置的关系
- 可扩展性:架构设计天然支持大规模扩展
2.1 GPT-1:预训练+微调的开创者
2018年,OpenAI发布了GPT-1,首次展示了在大规模无标注文本上预训练,然后在特定任务上微调的有效性。
关键技术特点:
- 12层Transformer解码器
- 1.17亿参数
- 基于BooksCorpus数据训练
2.2 GPT-2:零样本学习的突破
GPT-2最大的创新在于展示了大规模语言模型在零样本学习上的潜力。
# GPT-2的架构特点 class GPT2Config: def __init__(self): self.vocab_size = 50257 self.n_positions = 1024 # 上下文长度 self.n_embd = 768 # 嵌入维度 self.n_layer = 12 # 层数 self.n_head = 12 # 注意力头数 self.n_inner = 3072 # 前馈网络维度 # 参数量计算 def calculate_parameters(config): # 嵌入层参数 embed_params = config.vocab_size * config.n_embd # Transformer层参数 layer_params = ( 4 * config.n_embd * config.n_embd + # QKV投影 2 * config.n_embd * config.n_inner + # 前馈网络 4 * config.n_embd # 偏置项 ) total_params = embed_params + config.n_layer * layer_params return total_params config = GPT2Config() print(f"GPT-2参数量:{calculate_parameters(config):,}") # 约1.5亿 2.3 GPT-3:规模效应的惊人展现
2020年发布的GPT-3拥有1750亿参数,展示了"规模就是一切"的理念。
关键发现:
- 涌现能力:模型在达到一定规模后,会突然获得新的能力
- 少样本学习:仅需少量示例就能完成新任务
- 代码生成:展示了强大的代码理解和生成能力
3.1 架构创新
GPT-4在架构上进行了多项重要改进:
- 混合专家模型(MoE)
# MoE架构的简化实现 class MixtureOfExperts(nn.Module): def __init__(self, num_experts, d_model, d_ff): super().__init__() self.num_experts = num_experts self.gate = nn.Linear(d_model, num_experts) self.experts = nn.ModuleList([ nn.Sequential( nn.Linear(d_model, d_ff), nn.GELU(), nn.Linear(d_ff, d_model) ) for _ in range(num_experts) ]) def forward(self, x): # 门控网络决定使用哪些专家 gate_scores = torch.softmax(self.gate(x), dim=-1) # 选择top-k专家 top_k = 2 # 通常选择2个专家 top_scores, top_indices = torch.topk(gate_scores, top_k, dim=-1) # 专家混合计算 output = torch.zeros_like(x) for i in range(self.num_experts): # 创建专家掩码 expert_mask = (top_indices == i).any(dim=-1) if expert_mask.any(): expert_output = self.experts[i](x[expert_mask]) # 加权求和 weights = top_scores[expert_mask].sum(dim=-1, keepdim=True) output[expert_mask] += expert_output * weights return output - 强化学习优化:使用PPO算法进行人类反馈强化学习
- 多模态支持:整合视觉、文本等多模态信息
3.2 性能突破
根据OpenAI的技术报告,GPT-4在多个方面实现了显著提升:
4.1 规模扩展的极限
4.2 效率优化技术
- 稀疏注意力:只计算重要的注意力对
- 模型压缩:知识蒸馏、量化、剪枝
- 推理优化:KV缓存、批处理优化
4.3 安全与对齐
# 安全对齐的简化示例 class SafetyLayer(nn.Module):def __init__(self, model): super().__init__() self.model = model self.safety_classifier = nn.Sequential( nn.Linear(model.config.hidden_size, 256), nn.ReLU(), nn.Linear(256, 2) # 安全/不安全 ) def forward(self, input_ids, attention_mask=None): # 获取模型输出 outputs = self.model(input_ids, attention_mask=attention_mask) hidden_states = outputs.last_hidden_state # 安全分类 safety_scores = self.safety_classifier(hidden_states[:, -1, :]) safety_prob = torch.softmax(safety_scores, dim=-1) # 如果不安全,调整输出 if safety_prob[0, 1] > 0.5: # 不安全概率>0.5 # 应用安全过滤或重写 return self.apply_safety_filter(outputs) return outputs 5.1 开发者实践指南
- 模型选择策略
- 小任务:使用微调的小模型
- 复杂任务:考虑GPT-3.5或GPT-4
- 成本敏感:使用量化或蒸馏版本
- 提示工程技巧
# 有效的提示设计 effective_prompts = {"零样本": "请将以下英文翻译成中文: {text}", "少样本": """ 示例1: 输入: “今天天气很好”,输出: “The weather is nice today” 示例2: 输入: “我喜欢编程”,输出: “I like programming” 现在请翻译: {text} “”“,
"思维链": """ 问题: 如果我有3个苹果,又买了5个,然后吃了2个,还剩几个? 让我们一步步思考:
- 开始有3个苹果
- 买了5个,现在有3+5=8个
- 吃了2个,现在有8-2=6个 答案: 6个
现在请回答: {question} ”“” }
5.2 未来技术趋势
- 多模态统一:文本、图像、音频的统一建模
- 世界模型:建立对物理世界的理解
- 具身智能:AI与物理世界的交互
- 持续学习:避免灾难性遗忘的持续学习机制
从Transformer到GPT-4,大模型技术的发展不仅展示了深度学习的巨大潜力,也为我们提供了强大的工具。作为开发者,理解这些技术的演进路径,掌握核心原理,将帮助我们在AI时代保持竞争力。
关键要点总结:
- Transformer的自注意力机制是基础
- 规模扩展带来了涌现能力
- 架构创新(如MoE)提升了效率
- 安全对齐是实际应用的关键
- 提示工程是发挥模型潜力的重要技能
近期科技圈传来重磅消息:行业巨头英特尔宣布大规模裁员2万人,传统技术岗位持续萎缩的同时,另一番景象却在AI领域上演——AI相关技术岗正开启“疯狂扩招”模式!据行业招聘数据显示,具备3-5年大模型相关经验的开发者,在大厂就能拿到50K×20薪的高薪待遇,薪资差距肉眼可见!
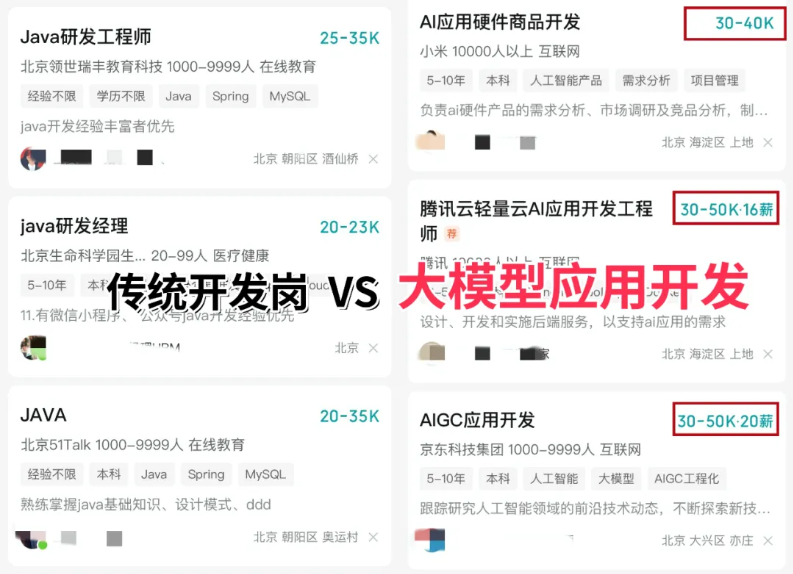
业内资深HR预判:不出1年,“具备AI项目实战经验”将正式成为技术岗投递的硬性门槛。在行业迭代加速的当下,“温水煮青蛙”式的等待只会让自己逐渐被淘汰,与其被动应对,不如主动出击,抢先掌握AI大模型核心原理+落地应用技术+项目实操经验,借行业风口实现职业翻盘!
深知技术人入门大模型时容易走弯路,我特意整理了一套全网最全最细的大模型零基础学习礼包,涵盖入门思维导图、经典书籍手册、从入门到进阶的实战视频、可直接运行的项目源码等核心内容。这份资料无需付费,免费分享给所有想入局AI大模型的朋友!

扫码免费领取全部内容

1、 AI大模型学习路线图

2、 全套AI大模型应用开发视频教程
从入门到进阶这里都有,跟着老师学习事半功倍。

3、 大模型学习书籍&文档

4、 AI大模型最新行业报告
2025最新行业报告,针对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。

5、大模型大厂面试真题
整理了百度、阿里、字节等企业近三年的AI大模型岗位面试题,涵盖基础理论、技术实操、项目经验等维度,每道题都配有详细解析和答题思路,帮你针对性提升面试竞争力。


6、大模型项目实战&配套源码
学以致用,在项目实战中检验和巩固你所学到的知识,同时为你找工作就业和职业发展打下坚实的基础。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
- 👇👇扫码免费领取全部内容👇👇

这份资料由我和鲁为民博士(北京清华大学学士和美国加州理工学院博士)共同整理,现任上海殷泊信息科技CEO,其创立的MoPaaS云平台获Forrester全球’强劲表现者’认证,服务航天科工、国家电网等1000+企业,以第一作者在IEEE Transactions发表论文50+篇,获NASA JPL火星探测系统强化学习专利等35项中美专利。本套AI大模型课程由清华大学-加州理工双料博士、吴文俊人工智能奖得主鲁为民教授领衔研发。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的技术人员,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。


这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/248205.html