
网上教你写 CLAUDE.md 的文章不少,该放什么、格式怎么写、层级怎么分,讲得都对。但看完你还是不知道一件事:我的 CLAUDE.md 到底什么时候该拆、怎么拆、拆到什么程度。这个问题没有标准答案,因为 CLAUDE.md 不是配置文件,它本质上是 你和 AI 的协作界面。什么时候失效,取决于你的项目形态、工作流,以及你什么时候开始感觉:Claude 好像越来越“听不懂我”了。
所以这篇不是教程。这是一个真实项目的踩坑复盘。
我用 Claude Code 从零写了一个数据集分析工具(使用FastAPI + Vue 3,前后端分离,40 多个 API 端点),项目几乎全程 AI 协作完成。在这过程中, CLAUDE.md 从 0 行涨到 200 多行,token 越烧越多,Claude 的表现反而越来越差。直到我花了一个下午重构配置体系,效果立刻改变。
下面是完整经过:
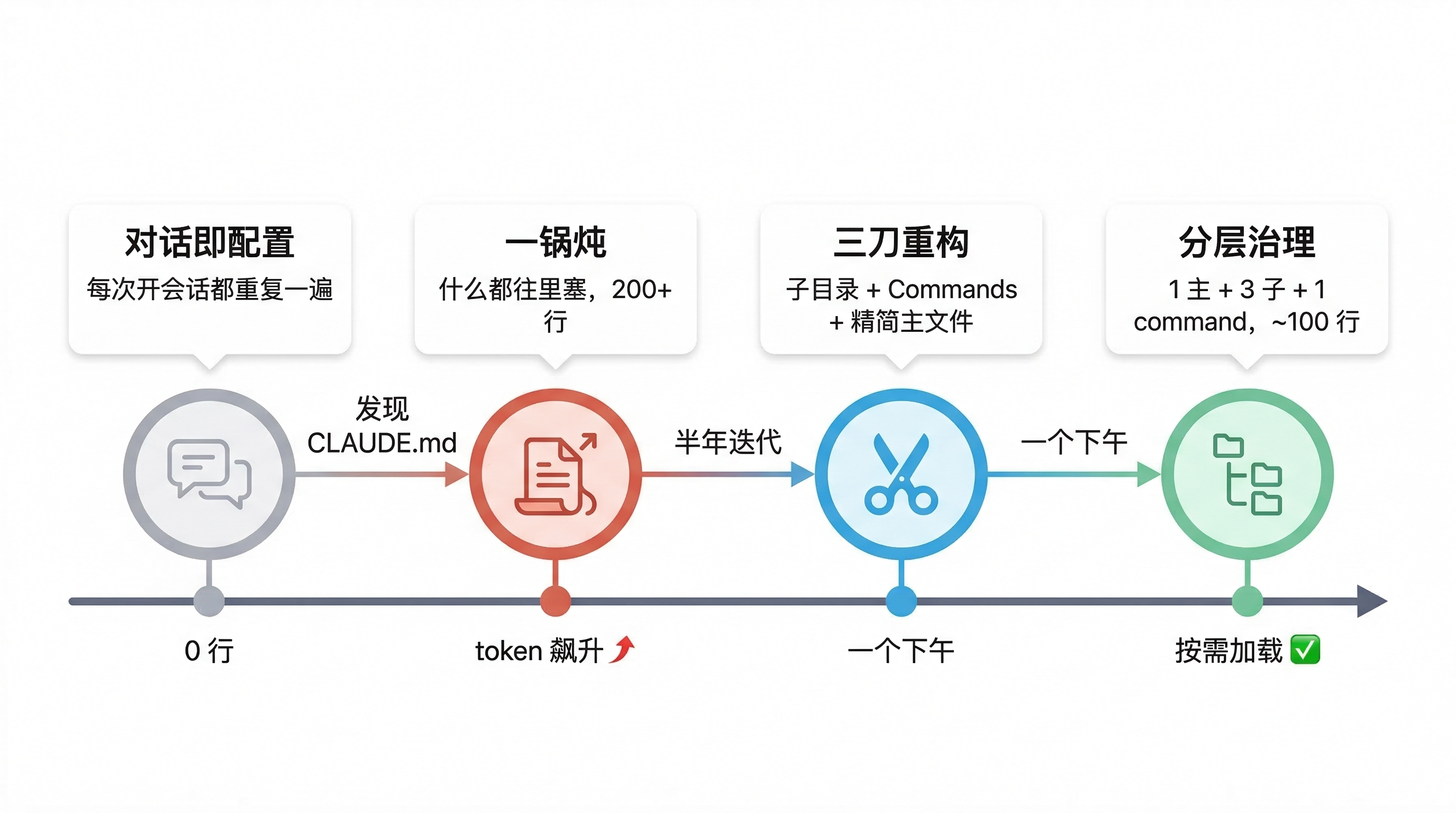
这篇文章讲的就是这条线:从零配置的对话模式,到什么都往里塞的膨胀期,再到一个下午的重构,最终形成分层治理的配置体系。每个阶段都是真实踩过来的。
刚开始用 Claude Code 时,我的工作方式非常原始:想到什么,说什么。
GPT plus 代充 只需 145“这个项目用 FastAPI,端口 9501。” “前端 Vue3 + TS,用 pnpm。” “analysis 层不要依赖 FastAPI。”
问题很快出现:每开一个新会话,都要重新解释项目背景。
Claude 没有跨会话记忆,上一次聊得再深入,下一次依然从零开始。
后来我发现了 CLAUDE.md,项目根目录放一个 Markdown 文件,Claude Code 启动时自动读取。于是我开始往里面塞东西:说一句,塞一条;踩一个坑,加一条规则。
这个阶段的 CLAUDE.md,本质上就是对话记录的沉淀。没有结构,没有分类,想到什么写什么。
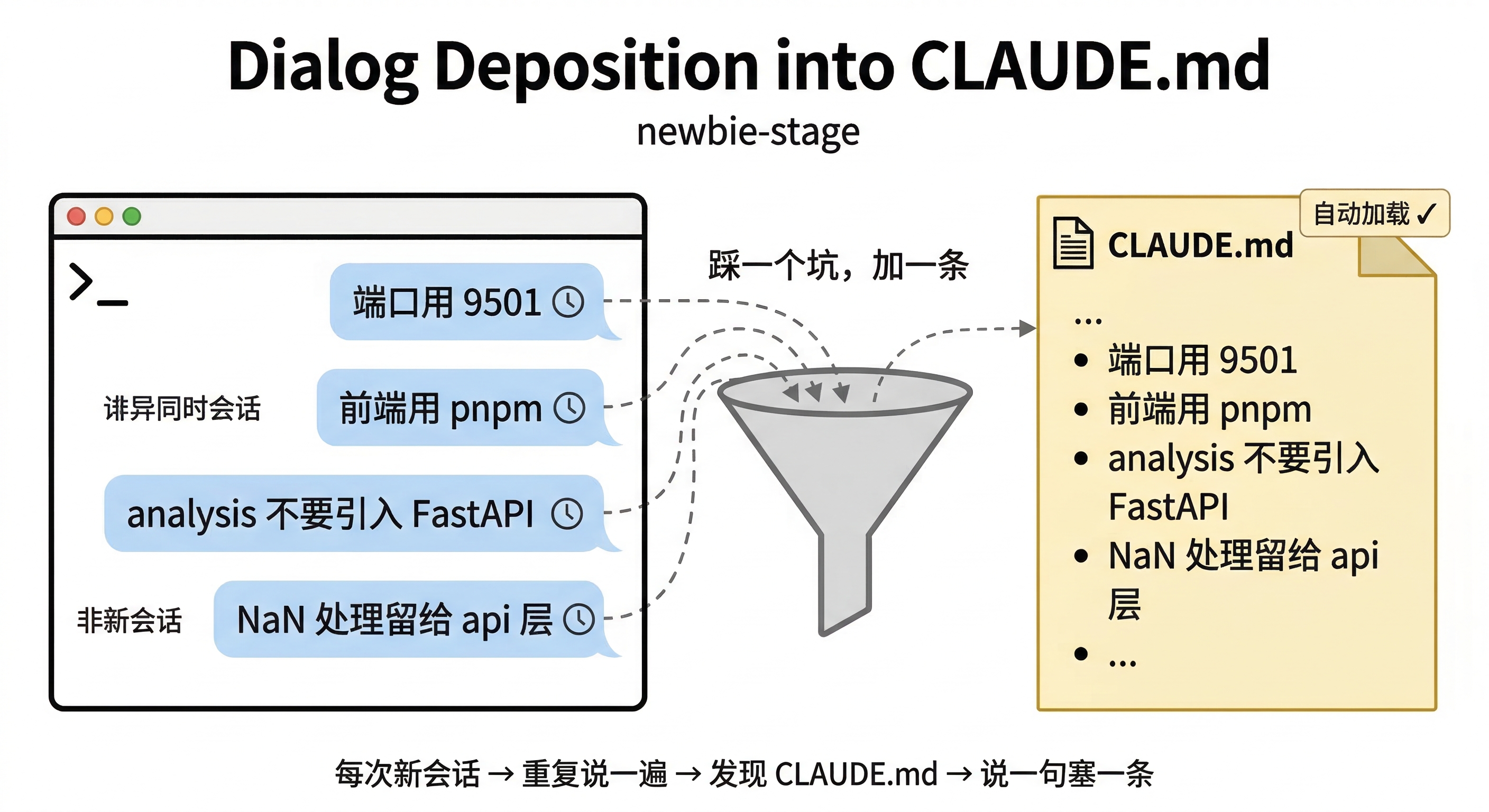
新手阶段的模式很直觉:对话里说过的规矩,一条条搬到 CLAUDE.md 里。没有规划,没有分类,纯粹是"怕下次又忘了"的本能反应。这个阶段完全没问题,项目小的时候,一个文件装得下。
随着项目推进,CLAUDE.md 开始失控,被我用成了万能收纳箱。
数据分析应用的架构不算复杂,但模块不少:后端有 analysis/、api/、loaders/、report/ 四个核心模块;前端有组件、路由、状态管理、国际化;中间还有 Session 机制、CORS 配置、特征工程的累积模式……
- 每次 Claude 犯错,我就往 CLAUDE.md 里加一条:
- Claude 在 analysis 层 import 了 Pydantic?加一条:
analysis/ 零框架依赖,只用 pandas/numpy/标准库。 - Claude 把 NaN 序列化搞炸了?加一条:
NaN/Inf 处理留给 api 层,analysis 层不做 JSON 序列化。 - Claude 在特征工程里搞混了累积模式的逻辑?加一大段:
save=false 只预览,save=true 才写入 session,注意先捕获 response 再清缓存…… - 前端 Claude 用了硬编码的 Tailwind 颜色?加一条:
用 main.css 定义的工具类,不要硬编码。 - Claude 又忘了 API 端点的路径?把 40 多个端点的完整列表贴进去。
- Claude 在 analysis 层 import 了 Pydantic?加一条:
- 你能想象这个文件最后变成什么样:技术栈、构建命令、架构图、编码规范、API 参考、版本记录、踩坑备忘、个人偏好……全塞在一个文件里。
- 问题不只是"看着乱",有效上下文逐渐被污染。Claude Code 每次启动时会把 CLAUDE.md 全文注入上下文,这意味着:
- token 消耗飙升。每一轮对话都要为这个巨型文件买单,还没开始干活,几千 token 就没了。
- 信噪比下降。当你告诉 Claude “这 40 个 API 端点的路径是这样的”,它在处理一个前端 CSS 问题时也会把这些信息加载进来。无关信息越多,Claude 越容易分心。
- 维护成本高。改了一个端点,要记得去 CLAUDE.md 里同步。忘了同步,Claude 拿着过时的信息干活,结果更糟糕。
- 本质上,我把 CLAUDE.md 当成了垃圾桶,什么都往里扔,从不整理。
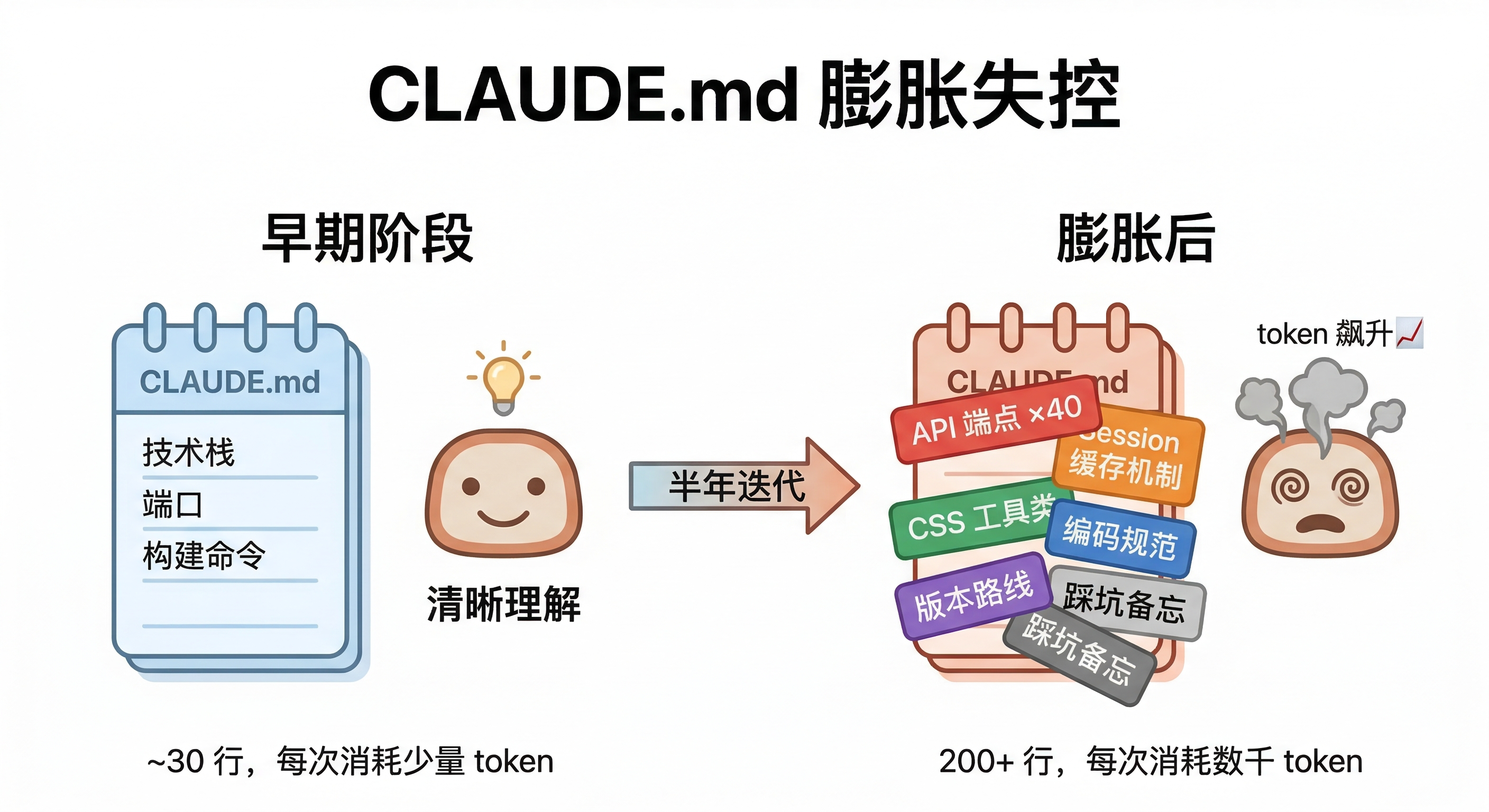
左边是项目初期的 CLAUDE.md,几行关键信息,Claude 读得轻松、理解得准确。右边是半年迭代后的样子,API 列表、编码规范、缓存机制、CSS 工具类全塞在一起,Claude 每次启动都要消化这些信息,大部分跟当前任务无关。token 在涨,效果在降。
触发重构的直接原因很具体:我发现让 Claude 改一个前端组件的样式,它读完 CLAUDE.md 后,花了大量 token 去"理解"后端 API 的端点列表和特征工程的缓存机制。这些信息跟当前任务毫无关系。
我决定动手拆。原则很简单:谁的规矩,放到谁家门口。
3.1 第一刀:子目录 CLAUDE.md
Claude Code 有一个很多人不知道的特性:子目录也可以放 CLAUDE.md,且只在 Claude 操作该目录时才加载。
这正好解决了"前端任务加载后端规范"的问题。我把模块级别的规范从主文件中拆出来,分成三份:
(1) 数据分析部分
src/intodata/analysis/CLAUDE.md:分析层的护城河
核心原则 - 零框架依赖:只用 pandas / numpy / 标准库,不引入 FastAPI、Pydantic 等 - 纯函数设计:输入 DataFrame → 返回 dataclass / dict / DataFrame - 可独立使用:所有函数可在 Jupyter notebook 中直接调用 编码约定 - 函数返回复杂结构时使用 dataclass,不用裸 dict - 不在 analysis 层做 JSON 序列化(NaN/Inf 处理留给 api 层) - 新增分析功能先写 analysis 纯函数,再写 api 路由包装 (2) API层
src/intodata/api/CLAUDE.md:API 层的操作手册
GPT plus 代充 只需 145 Session 模型 - SessionStore:内存 dict + asyncio.Lock,UUID cookie 标识,2h TTL 自动清理 - SessionData 包含 dataset 和 image_dataset,互斥 端点设计约定 - save=false:只返回预览数据(不修改 session) - save=true:覆盖 session df → 清除 feature 缓存 → 记录 log → 返回新 meta - 注意:save 时先捕获 response 数据再调 clear_feature_caches()
(3) 前端
frontend/CLAUDE.md:前端的设计系统:
CSS 设计系统 使用 main.css 中定义的工具类,不要硬编码 Tailwind 颜色: - .loading-state — 加载状态 - .status-ok / .status-warn / .status-danger — 语义状态颜色 - .section-title — 渐变下划线章节标题 国际化 - 所有用户可见文本必须用 $t('key') - 新增功能需同步添加 en.ts 和 zh.ts 拆完之后,Claude 改前端样式时只会读到 CSS 工具类和组件约定;改后端 API 时只会看到 Session 模型和端点设计模式。每次对话的上下文里只有相关信息,没有噪声。
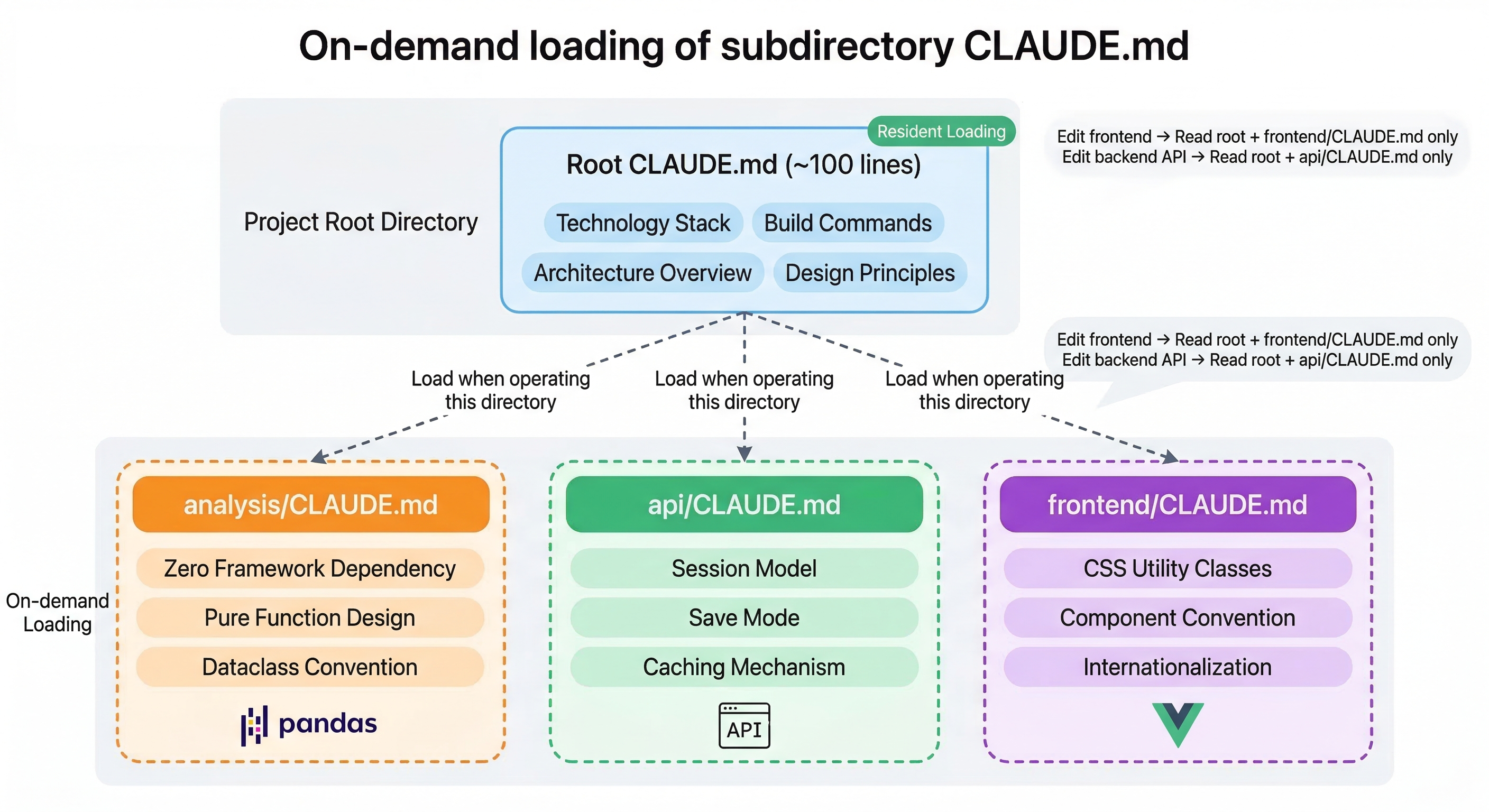
项目根目录的 CLAUDE.md 常驻加载,只放全局信息;三个子目录各自维护模块级规范,Claude 操作哪个目录就加载哪份。改前端时不会看到后端的 Session 机制,改 analysis 时不会被前端的 CSS 工具类干扰。
3.2 第二刀:Custom Commands
拆完子目录 CLAUDE.md,主文件瘦了很多,但还有一块东西很碍眼:40 多个 API 端点的完整列表。
这个列表有用,但不是每次都用。只有在"加新端点"或"排查路由问题"时才需要。把它放在 CLAUDE.md 里,每次启动都加载,浪费。
这时候我发现了 Custom Commands。
(1) 什么是Custom Commands
Custom Commands 是 Claude Code 提供的一种轻量级扩展机制:在 .claude/commands/ 目录下放一个 Markdown 文件,就注册了一个斜杠命令。用的时候手动调用,不用的时候不占上下文。
GPT plus 代充 只需 145.claude/ └── commands/ └── api-ref.md ← 输入 /api-ref 即可调用
我把 API 端点列表从 CLAUDE.md 里搬到了 api-ref.md:
# API Endpoints Reference Dataset(表格) | 方法 | 路径 | 说明 | |------|------|------| | POST | /api/dataset/upload | 上传文件 (multipart) | | POST | /api/dataset/load-path | 从服务器路径加载 | | DELETE | /api/dataset | 清除数据集 | | GET | /api/dataset/info | 获取 DatasetMeta | | GET | /api/dataset/preview | ?mode=head|tail|random&n=20 | | GET | /api/dataset/download | ?columns=a,b,c&format=csv|tsv|parquet | Feature Engineering | 方法 | 路径 | 说明 | |------|------|------| | POST | /api/feature/binning | 分箱(累积模式) | | POST | /api/feature/onehot | OneHot 编码 | | POST | /api/feature/woe | WOE 编码(需 binary target) | | POST | /api/feature/scaling | 缩放 (minmax/zscore/log) | ... 现在,日常开发时 Claude 不会被这 90 多行端点列表干扰。只有当我需要参考 API 时,敲一个 /api-ref,列表才会注入上下文。
(2) 如何使用Custom Commands呢
这里有个问题你一定会想到:搬出去之后,Claude 怎么知道去用它?
答案是:Claude 不会自己主动调用 Custom Commands。 这是 Custom Commands 的设计,它是用户触发的,不是 AI 自主触发的。你敲 /api-ref,内容才注入;你不敲,Claude 就看不到。
那 Claude 怎么知道这个命令存在呢?靠你在 CLAUDE.md 里留一个"路标"。我在主 CLAUDE.md 的设计原则里写了一句:
GPT plus 代充 只需 145- 完整 API 端点列表:运行 `/api-ref` 查看
就这一行。Claude 读到它,就知道有这个命令可用。当它需要查端点信息时,不会自己去调,而是会提醒你:“建议运行 /api-ref 查看端点列表。” 最终还是你来敲那个命令。
(2) Custom Commands V.S. Skills
这里要区分一下两个容易混淆的概念:
.claude/commands/*.md
.claude/skills/*/SKILL.md
触发方式 手动输入
/command-name 系统自动匹配或
/skill-name
本质 一段 prompt 模板,调用时注入对话 有 frontmatter 元数据的能力模块
适合场景 按需参考的信息、一次性操作模板 需要自动触发的领域知识
对于"API 端点参考"这种按需查阅的信息,Custom Commands 比 Skills 更合适,不需要自动触发,不需要 frontmatter 元数据,就是一个 Markdown 文件,最轻量。
3.3 第三刀:主 CLAUDE.md 只留骨架
两刀下去,主 CLAUDE.md 变成了现在的样子:只保留全局性的、每次都需要的信息:
Project Overview 数据分析工具是一个面向 ML 工程师的数据集分析工具…… Tech Stack Backend: Python 3.11+, FastAPI, pandas…… Frontend: Vue 3, TypeScript, Vite, Pinia…… Commands conda activate intodata uvicorn intodata.api.main:app --reload --port 9501 cd frontend && pnpm dev Architecture(目录树 + 一行说明) Key Design Principles(4 条) Version & Roadmap(表格) 不到 100 行。技术栈、构建命令、架构概览、核心原则、版本路线,都是无论干什么都需要知道的全局上下文。
模块细节?去子目录 CLAUDE.md 看。API 参考?/api-ref 调出来。
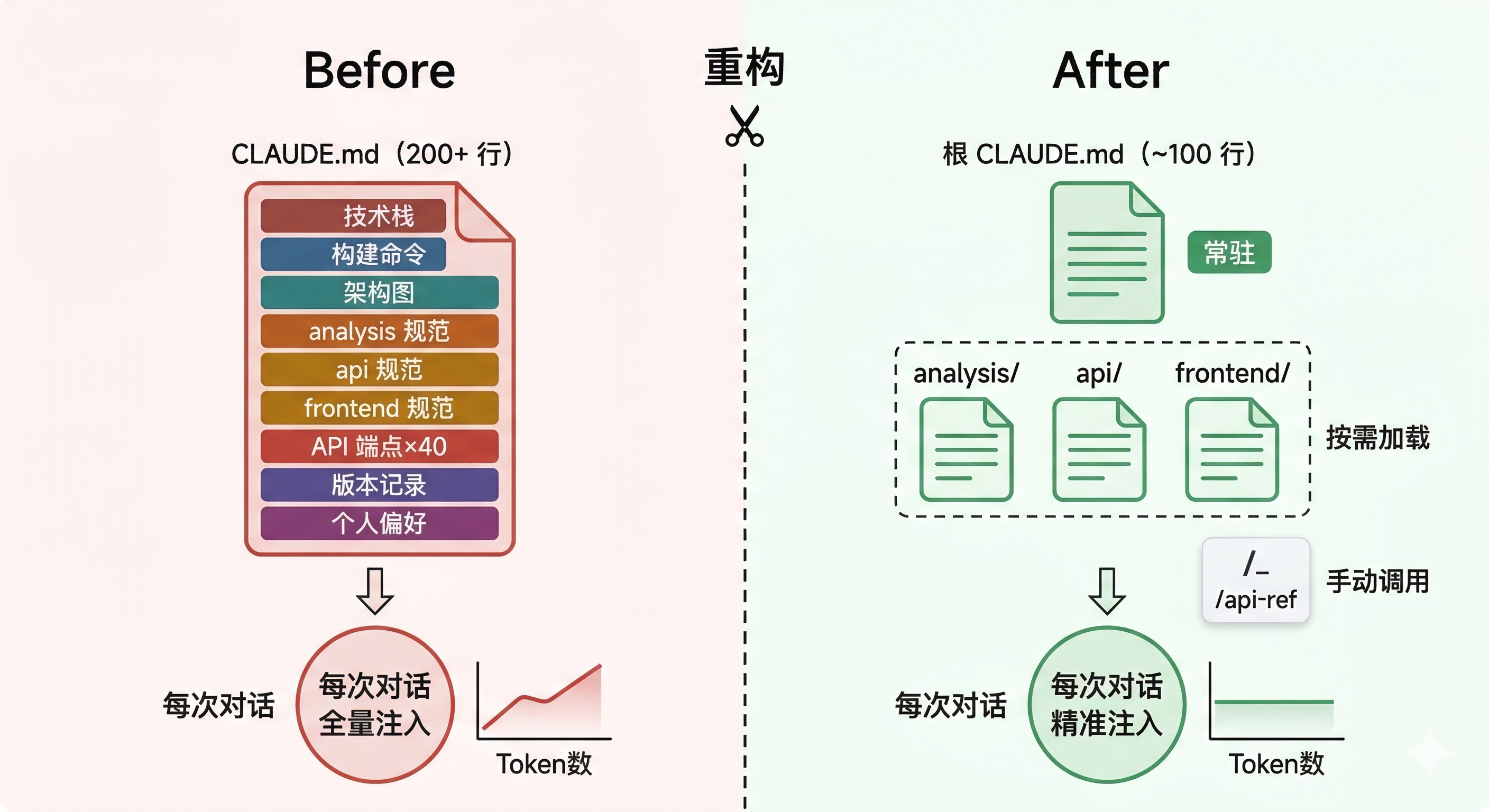
左边是重构前的状态:所有信息塞在一个文件里,每次对话全量注入,token 消耗高、信噪比低。右边是重构后:主文件只留骨架,模块规范按需加载,API 参考手动调用——每次对话只注入真正需要的信息。*
用表格再细化一下:
/api-ref 按需加载
维护 所有人改同一个大文件 各模块维护自己的规范
重构完回头看,其实就三条原则:
5.1 CLAUDE.md 是入职手册,不是百科全书
新同事入职第一天,你会给他一份简明的 onboarding 文档,不会把整个内部 Wiki 打印出来。CLAUDE.md 也一样,只放"无论做什么都需要知道"的信息:技术栈、构建命令、架构概览、核心设计原则。
5.2 谁的规矩,放到谁家门口
analysis 层的纯函数约定,只有改 analysis 代码时才需要;前端的 CSS 工具类列表,只有改前端时才需要。用子目录 CLAUDE.md 做到按需加载,而不是全量注入。
5.3 不是每次都需要的信息,做成按需调用
API 端点列表、数据库 Schema、环境变量清单,这些信息偶尔需要参考,但不值得每次对话都占用上下文。Custom Commands 就是为这种场景设计的:一个 Markdown 文件,一个斜杠命令,用的时候调,不用的时候不占位。
如果你的 CLAUDE.md 已经超过 150 行,或者你发现 Claude 在做简单任务时莫名其妙地“走神”,大概率是时候重构了。
不需要一步到位。我的建议是:
- 先审计:统计一下你的 CLAUDE.md 里有多少信息是“每次都需要的”,有多少是“偶尔参考的”,有多少是“只有改特定模块才需要的”。
- 先拆子目录:把模块级别的规范搬到子目录 CLAUDE.md,这一步收益最大,改动最小。
- 再做 Commands:把“偶尔参考”的大块信息提取成 Custom Commands。
- 最后精简主文件:拆完之后,主文件自然就只剩骨架了。
Claude Code 的配置体系其实设计得很合理:分层加载、按需注入、关注点分离。只是官方文档里不会告诉你什么时候该用哪一层,这个只有自己踩过坑才知道。
希望我的坑,能让你少走一段弯路。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/247204.html