
都说2025是agent元年,近期也有很多蛮好的进展,比如K2、GLM4.5。
请大家畅谈agent的现状与未来~
比如:agent何时迎来真正的ChatGPT时刻呢?
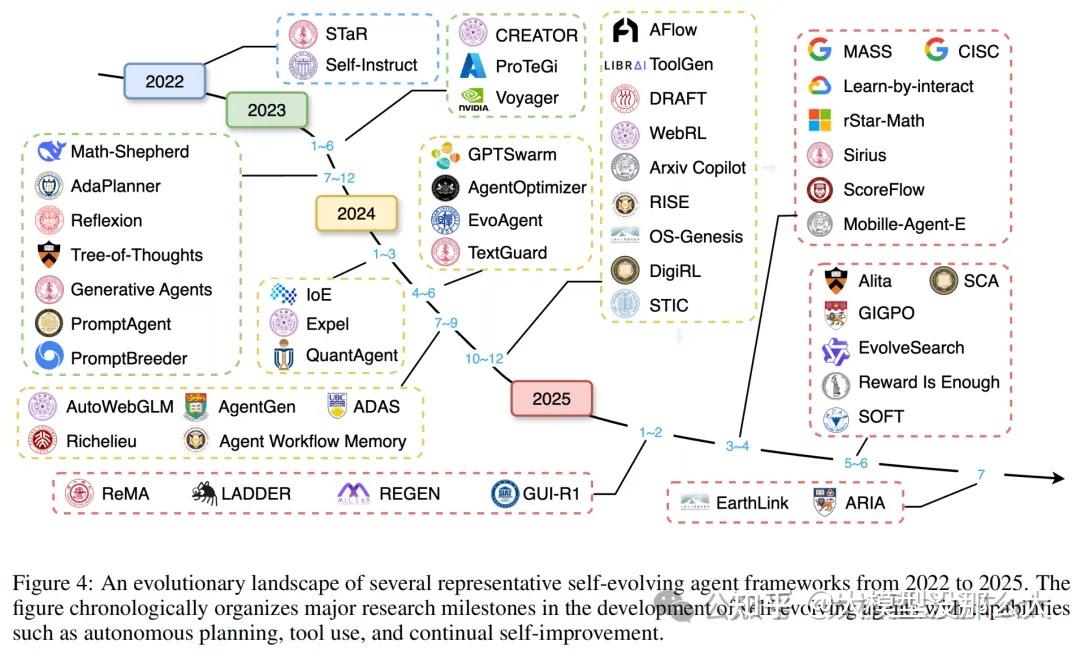
普林斯顿大学、普林斯顿AI Lab、清华大学、卡内基梅隆、上交等团队最新的自进化Agent综述!系统梳理了这个关键节点,尤其展开研究了三个核心问题:
原文链接:万字长文!首篇智能体自进化综述:迈向超级人工智能之路(普林斯顿/清华/上交等)
- 进化什么?(模型、记忆、工具、架构等)
- 何时进化?(Test-Time 阶段内 vs 阶段间)
- 如何进化?(通过奖励、反馈、记忆、搜索等机制)
我们总结了相关都最新算法、评估指标与基准任务,并总结了多个应用场景,旨在探讨面向 Super Intelligence 的长期路径 。
- arXiv: https://arxiv.org/pdf/2507.21046
- HuggingFace:https://huggingface.co/papers/2507.21046
- GitHub: https://github.com/CharlesQ9/Self-Evolving-Agents
大语言模型(LLMs)在多种任务中展现了卓越的能力,但其本质上仍是静态的,无法在面对新任务、不断进化的知识领域或动态交互环境时调整其内部参数。随着LLMs被越来越多地部署于开放、交互式环境中,这种静态特性已成为一个关键瓶颈,迫切需要能够实时进行自适应推理、行动和进化的智能体。这一范式转变——从扩展静态模型转向开发自我进化的智能体——激发了人们对能够实现从数据、交互和经验中持续学习与适应的架构和方法的日益关注。本综述首次对自我进化智能体进行了系统而全面的回顾,围绕三个基础维度组织该领域:进化的对象(what to evolve)、进化的时机(when to evolve)和进化的机制(how to evolve)。我们考察了智能体各组成部分(例如,模型、记忆、工具、架构)的进化机制,按阶段(例如,测试内、测试间)对适应方法进行分类,并分析了指导进化适应的算法与架构设计(例如,标量奖励、文本反馈、单智能体与多智能体系统)。此外,我们分析了专为自我进化智能体定制的评估指标和基准,重点介绍了其在编程、教育和医疗等领域的应用,并指出了在安全性、可扩展性和协同进化动态等方面的关键挑战与研究方向。通过提供一个理解与设计自我进化智能体的结构化框架,本综述为推进研究和现实应用中更具适应性、鲁棒性和多功能性的智能体系统建立了路线图,最终为实现人工超级智能(ASI)铺平道路——在该愿景中,智能体能够自主进化,在广泛的任务上达到甚至超越人类水平的智能。
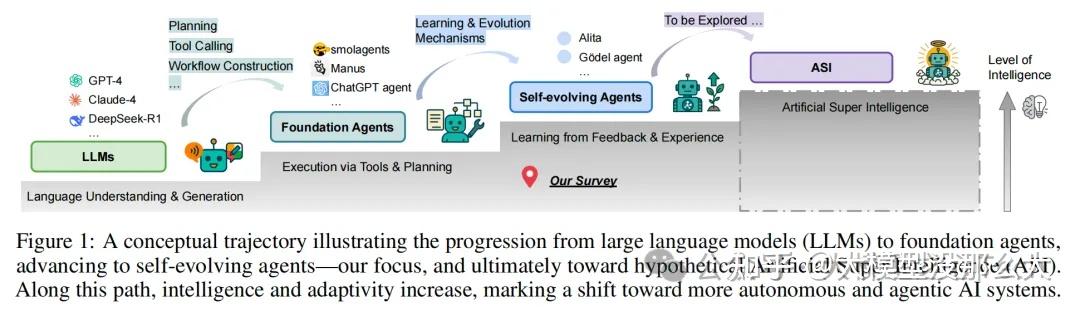
It is not the most intellectual of the species that survives; it is not the strongest that survives; but the species that survives is the one that is able best to adapt and adjust to the changing environment in which it finds itself – Charles Darwin
大语言模型(LLMs)在多种任务中展现了卓越的能力。然而,它们本质上仍是静态的,在面对新任务、不断进化的知识领域或动态交互环境时,无法调整其内部参数。随着LLMs越来越多地被部署于开放、交互式的环境中,这一局限性已成为一个关键瓶颈。在此类场景中,传统的知识检索机制显得力不从心,从而催生了能够实时动态调整其感知、推理和行动的智能体。这种对动态、持续适应性的新兴需求,标志着人工智能领域的一次概念性转变:从扩大静态模型的规模,转向开发能够从新数据、交互和经验中实时持续学习的自进化智能体,从而打造出更稳健、更灵活、更有能力应对复杂动态现实世界问题的系统。这一转变正引领我们走向通往人工超级智能(ASI)的一条充满希望且具有变革性的道路,在此愿景中,智能体不仅能以不可预测的速度从经验中学习和进化,还能在广泛的任务上达到甚至超越人类水平的智能。
与受限于无法适应新奇和不断变化环境的静态LLMs不同,自进化智能体旨在通过持续从现实世界反馈中学习来克服这些局限。这一发展重塑了我们对智能体的理解。作为核心概念,自进化智能体将成为ASI的先驱,扮演着为智能的终极进化铺平道路的中介角色,如图1所示。近期的研究工作日益聚焦于开发能够从经验中持续学习和适应的自适应智能体架构,例如在智能体框架、提示策略以及不同优化方式以实现进化方面的最新进展。尽管取得了这些进步,现有的综述大多将智能体进化作为其综合智能体分类中的一个次要组成部分。先前的综述主要提供了对通用智能体开发的系统性概述,而对自进化智能体在受限场景下的自进化机制的覆盖则非常有限。例如,Luo等人讨论了自我学习和多智能体协同进化等多种进化方式,而Liu等人则明确从智能体的不同组成部分(如工具和提示)的角度引入了进化概念。此外,一些研究专门关注语言模型本身的进化,而非智能体这一更广泛的概念。然而,目前尚无一项系统性综述致力于将自进化智能体作为首要研究范式进行专门且全面的探讨。这一空白导致一些根本性问题尚未得到充分探索:智能体的哪些方面应该进化?适应应在何时发生?以及在实践中应如何实现这种进化?
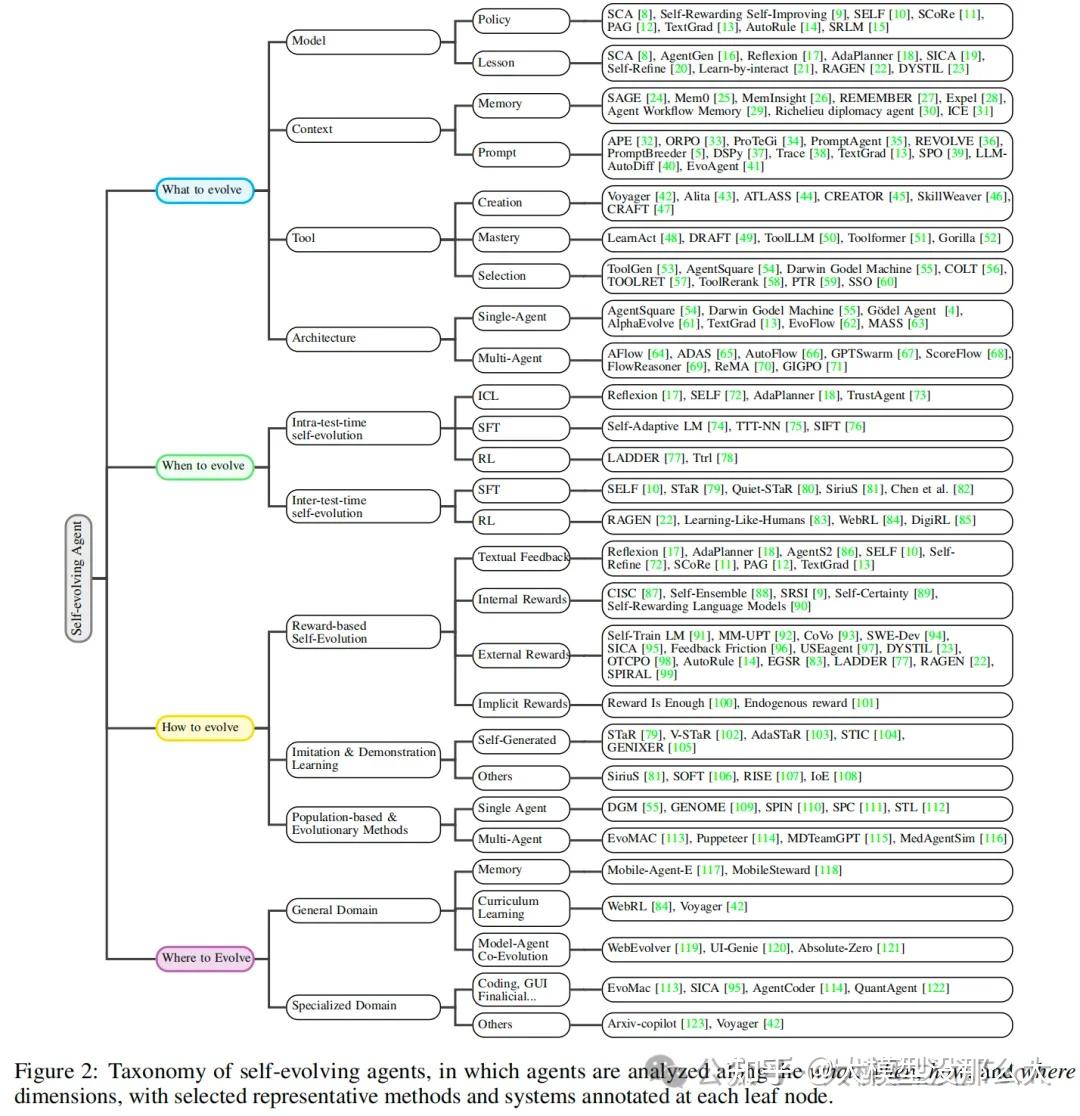
据我们所知,这是第一篇专注于自进化智能体的系统性、全面性综述,为理论探究和实际部署提供了清晰的路线图。我们围绕三个基础性问题——“进化什么”、“何时进化”和“如何进化”——来组织我们的分析,并为每个问题提供一个结构化框架。具体而言,我们系统地审视了智能体的各个组成部分,包括模型、记忆、工具及相应的工作流程,研究了它们各自独特的进化机制;然后,我们根据不同的时间阶段,将现有的进化方法划分为不同的学习范式,例如监督微调、强化学习和推理时进化(;最后,我们总结了指导智能体进化的不同信号(如文本反馈或标量奖励)以及智能体进化的不同架构(如单智能体和多智能体进化)。此外,我们回顾了用于追踪自进化智能体现有进展的评估指标和基准,强调了智能体与评估之间协同进化的重要性。我们还探讨了在编程、教育和医疗等领域的新兴应用,这些领域中持续适应和进化至关重要。最后,我们指出了持续存在的挑战,并概述了有前景的研究方向,以指导自进化智能体的发展。通过对自进化过程在正交维度上的系统性分解,我们提供了一个结构化且实用的框架,使研究人员能够系统地分析、比较和设计更稳健、更具适应性的智能体系统。总而言之,我们的主要贡献如下:
- 建立了一个统一的理论框架,用以描述智能体系统中的自进化过程,该框架围绕三个基本维度:进化的对象、进化的机制和进化的时机,为未来自进化智能体系统的设计提供了明确的指导。
- 进一步研究了专为自进化智能体定制的评估基准或环境,突出了与适应性、鲁棒性和现实世界复杂性相关的新兴指标和挑战。
- 展示了在自主软件工程、个性化教育、医疗保健和智能虚拟助手等多个领域的关键实际应用,阐明了自进化智能体的实际潜力。
- 指出了关键的开放性挑战和有前景的未来研究方向,强调了安全性、个性化、多智能体协同进化和可扩展性等方面。
通过本综述,我们为研究人员和从业者提供了一个更结构化的分类体系,以便从不同角度理解、比较和推进自进化智能体的研究。随着基于LLM的智能体越来越多地被集成到关键任务应用中,理解其进化动态变得至关重要,这已超越了学术研究的范畴,延伸至工业应用、监管考量以及更广泛的社会影响。
在深入进行全面的综述之前,我们首先为自进化智能体(self-evolving agents)提供一个正式的定义,并介绍其关键方面的分类体系。我们还将讨论自进化智能体与其他著名学习范式(如课程学习、持续学习、模型编辑和遗忘)之间的关系,以突出自进化智能体的适应性、动态性和自主性本质。

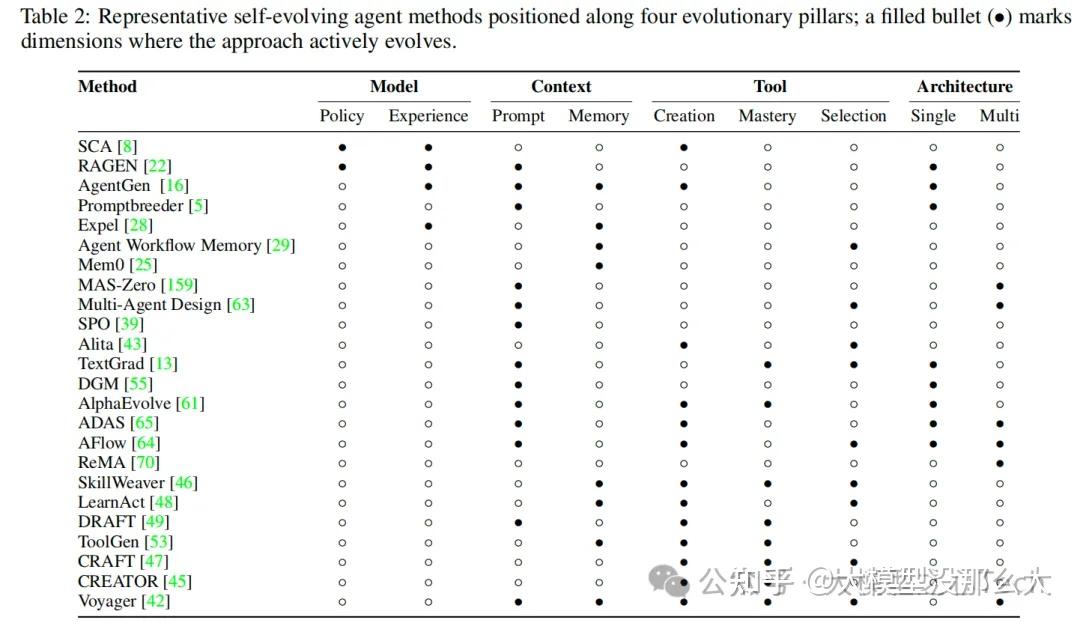
自进化智能体 自进化智能体是一种能够通过与环境的交互,自主地、持续地改进其自身组件(如模型、记忆、工具和工作流)的智能体。这种改进旨在增强其在当前和未来任务上的性能、适应性和通用性。与传统的静态模型或仅在推理时通过上下文学习(ICL)进行适应的智能体不同,自进化智能体能够通过多种机制(如参数微调、记忆更新、工具创建和架构调整)实现更深层次的、持久的进化。
自进化智能体与多个现有的学习范式密切相关,但又有着本质的区别。理解这些关系有助于明确其独特性。
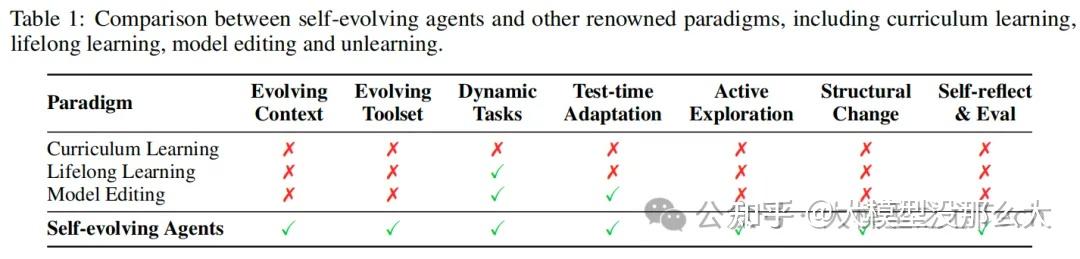
课程学习 (Curriculum Learning):课程学习通过从简单任务到复杂任务的有序安排来训练模型。虽然课程学习关注学习过程的顺序,但它通常是在一个固定的模型架构和参数集上进行的。自进化智能体则更进一步,不仅学习任务本身,还能动态地调整其内部结构(如创建新工具或优化工作流)以适应不断变化的挑战,体现了更强的自主性和适应性。
持续学习 / 终身学习 (Lifelong Learning):持续学习旨在让模型在不遗忘旧知识的前提下,持续学习新任务。它主要关注知识的保留(Retention)和前向迁移(Forward Transfer)。自进化智能体不仅包含了持续学习的目标,还强调了后向迁移(Backward Transfer, BWT)——即通过新任务的经验来提升在旧任务上的表现——以及更广泛的适应性(Adaptivity)和效率(Efficiency)。此外,自进化智能体的“进化”不仅限于模型参数,还涵盖了工具、记忆和架构等多个层面。
模型编辑 (Model Editing):模型编辑技术旨在对预训练模型的特定知识进行精确、局部的修改,而无需对整个模型进行重新训练。这可以看作是自进化智能体在“模型”层面的一种特定进化方式。然而,自进化智能体的进化范围更广,不仅包括参数层面的编辑,还包括通过创建新工具或更新记忆库来扩展能力,其目标是实现更全面、更自主的系统级进化。
遗忘 (Unlearning):遗忘是指从模型中移除特定知识或能力的过程。这在自进化智能体中也是一个重要的考量,尤其是在需要遵守隐私法规或纠正错误知识时。一个成熟的自进化框架应该能够同时支持知识的“习得”和“遗忘”,以确保其行为的安全性(Safety)和可控性。
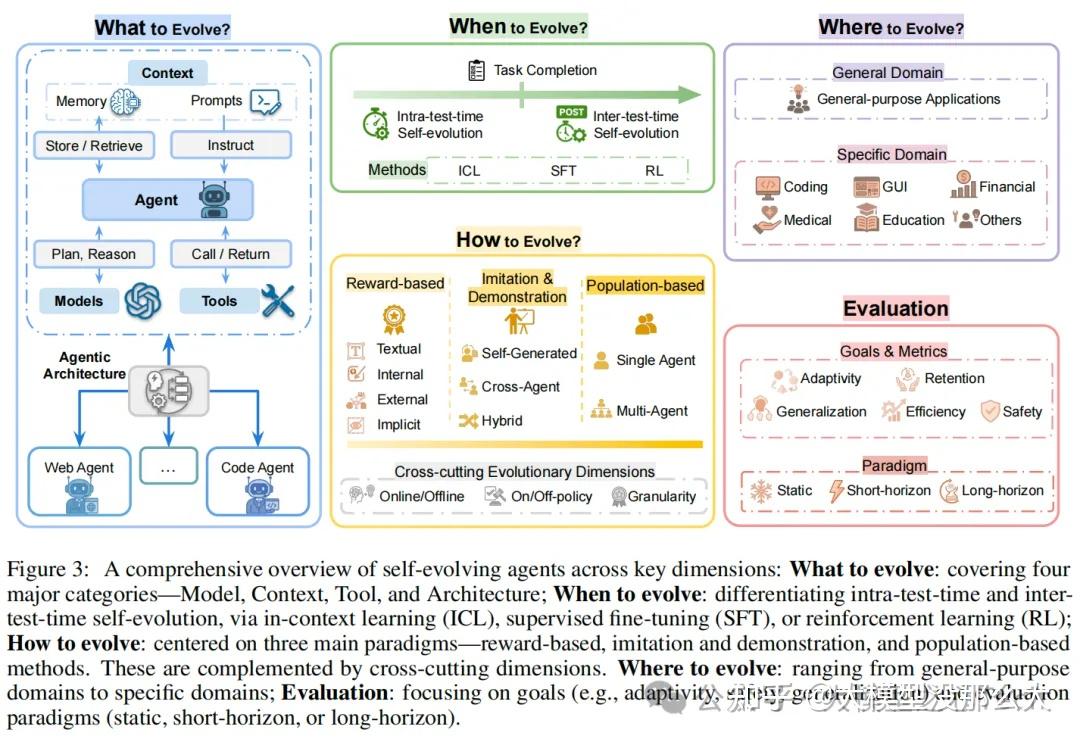

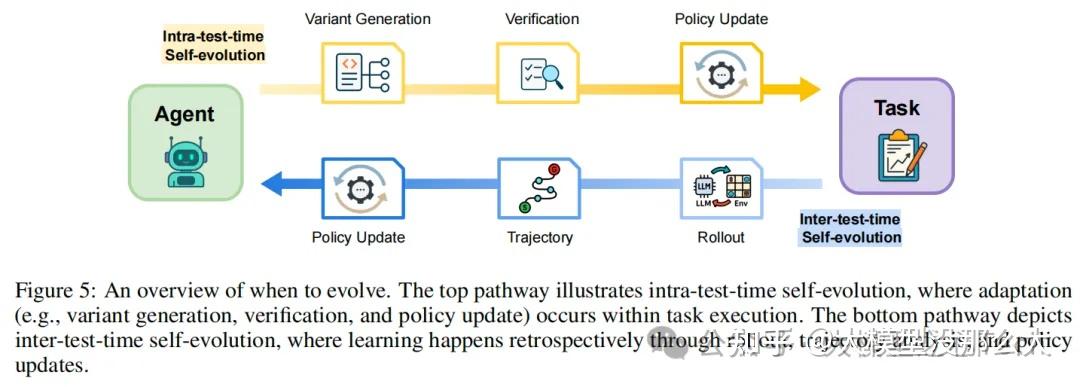
基于大语言模型(LLM)的智能体的自进化在时间维度上,主要关注学习过程与任务执行之间的关系。因此,自进化智能体的第二个关键方面是确定进化的时机,即在哪个阶段调用并应用自进化策略f到智能体系统上。为此,我们提出一个分类体系,区分两种时间模式的自进化:测试时内自进化(Intra-test-time self-evolution)和测试时外自进化(Inter-test-time self-evolution)。
测试时内自进化指的是在任务执行期间发生的适应性过程。在此模式下,智能体在面对特定问题时识别出自身的局限性,并启动有针对性的学习机制,以实时增强其能力。这种进化模式的特点是与当前任务紧密耦合:智能体针对所遇到的具体问题提升其解决问题的能力,从而在性能与适应性之间形成一种动态的相互作用。
测试时外自进化指的是在任务完成之间发生的学习过程,它利用积累的经验来提升未来的表现。这一类别涵盖了多种方法论途径:通过迭代精炼从预先收集的数据集中提取知识的离线学习范式,以及基于流式交互数据持续适应的在线学习范式。
在这些不同时间阶段实现自进化,依赖于大语言模型中的三种基本学习范式:
- 上下文学习(In-context learning, ICL):通过上下文中的示例来调整行为,而无需修改模型参数。
- 监督微调(Supervised fine-tuning, SFT):在标注数据上通过基于梯度的优化来更新模型权重。
- 强化学习(Reinforcement learning, RL):通过基于奖励的策略优化来塑造行为。
尽管这些学习范式在不同的时间背景下概念上保持一致,但它们在数据可用性和学习目标方面存在差异:
- 测试时内自进化的特点是其在线性(online nature):学习数据在任务执行过程中动态产生,优化目标直接针对提升当前问题实例的性能。这种实时耦合要求具备能够处理学习数据和反馈信号,并在主动解决问题的时间限制内修改行为的快速适应机制。
- 相比之下,测试时外自进化的特点是其回顾性(retrospective nature):学习算法作用于历史数据(无论是来自精心策划的数据集还是积累的行为轨迹),其优化目标旨在提高在任务分布上的预期性能,而非最大化某个特定问题实例的成功率。这种时间上的解耦使得更复杂的学习程序(learning procedures)成为可能,这些程序能够识别跨任务的模式、整合多样化的经验,并发展出可泛化的能力(capabilities),而不受主动执行任务时紧迫性的限制。
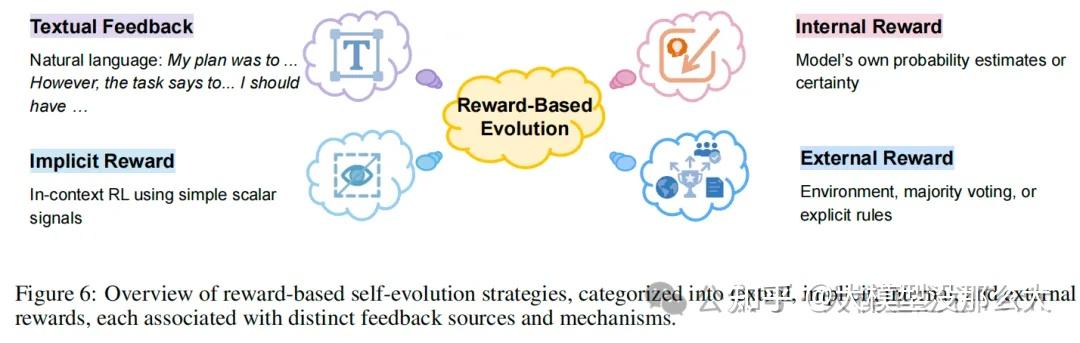
追求自进化是构建先进、自主且日益通用的人工智能的核心。对于大语言模型(LLMs)及其智能体扩展而言,如何持续、自主且高效地进化其能力已成为一个核心挑战。因此,第三个关键方面是如何实现进化。
与在静态数据集上训练或一次性监督微调不同,自进化强调一个持续的过程:模型从真实世界的交互中学习,主动寻求反馈,进行自我反思,生成或整理新数据,并根据动态环境调整其策略。这种持续的进化不仅仅是扩大数据或计算规模的问题;它要求智能体获得一系列元能力,包括自我纠错、自主数据生成、知识迁移和多智能体协作。因此,自进化的格局变得越来越丰富和多面化,每个方法论分支都在探索不同的反馈轴、学习范式、数据源和进化尺度。
本章旨在系统地梳理和分析主要的自进化方法家族,为理解其原理、机制和相互作用提供一个统一的框架。我们首先从基于奖励的进化开始,该方法的核心在于设计奖励信号——从自然语言反馈和内部置信度指标到外部或隐式信号——以指导迭代的自我改进。接着,我们探讨模仿与示范学习,即智能体通过学习高质量的范例(无论是自我生成的,还是由其他智能体或外部来源提供的)来提升自身能力。当示范丰富或能够自主合成时,这一范式尤其强大,并已在推理和多模态领域推动了显著进展。最后,我们介绍基于群体和进化的方法,这些方法借鉴了生物进化和集体智能的灵感。这些方法维护着智能体变体或协作智能体的群体,利用选择、变异、交叉和竞争等机制并行探索解空间,促进多样性,并催生出新颖的策略或架构创新。
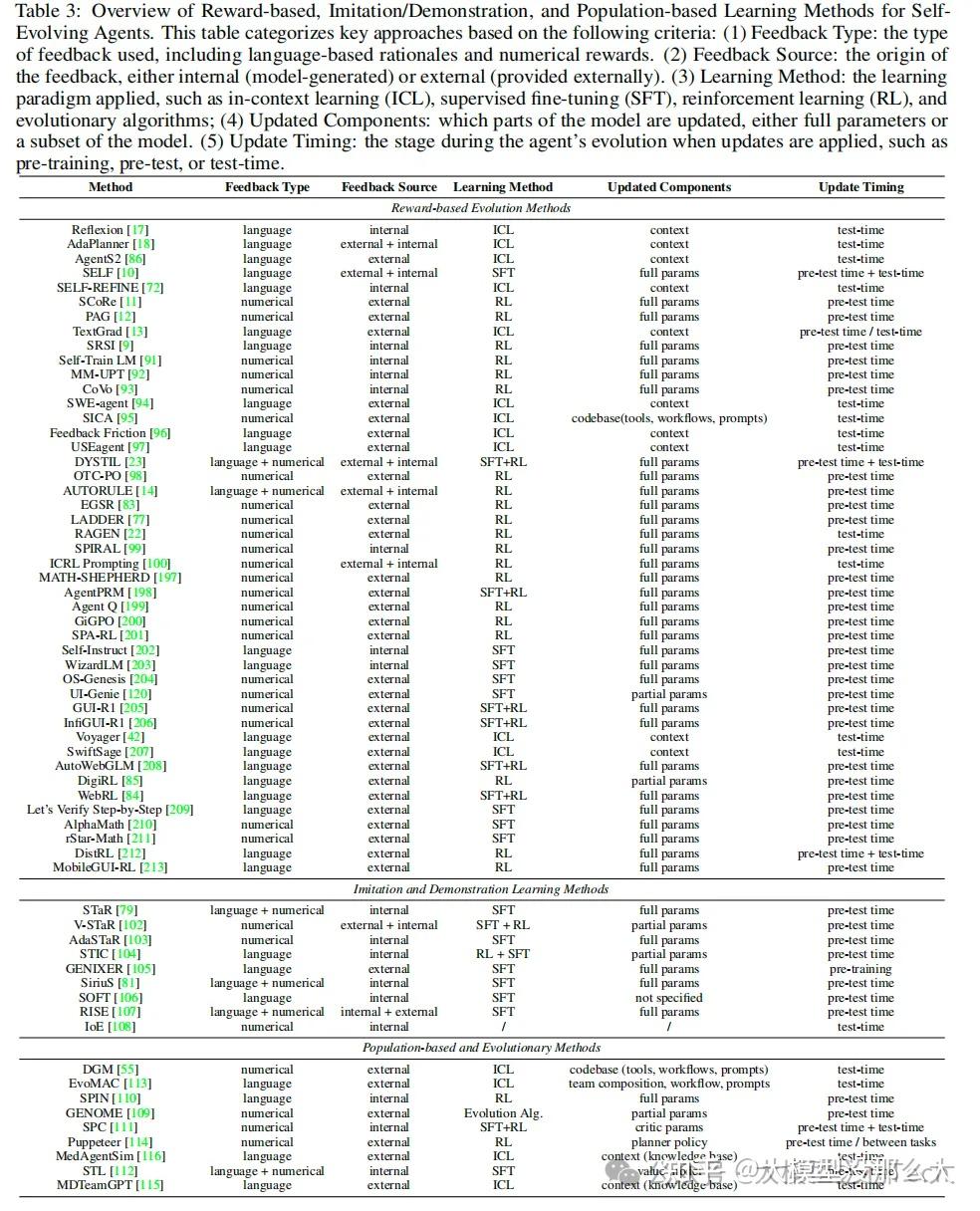

自进化智能体已在众多领域和应用中推动了显著进步。总体而言,这些应用可以系统地分为两大类:(1)通用领域进化(general domain evolution),即智能体系统通过进化以扩展其在各种任务中的能力,这些任务大多处于数字领域;以及(2)专用领域进化(specialized domain evolution),即智能体专门针对特定任务领域进化,以提升其在该领域的专业能力。本质上,通用型智能助手的进化侧重于将学习到的经验迁移到更广泛的任务集上,而专用智能体的进化则侧重于在特定领域内深化其专业知识。
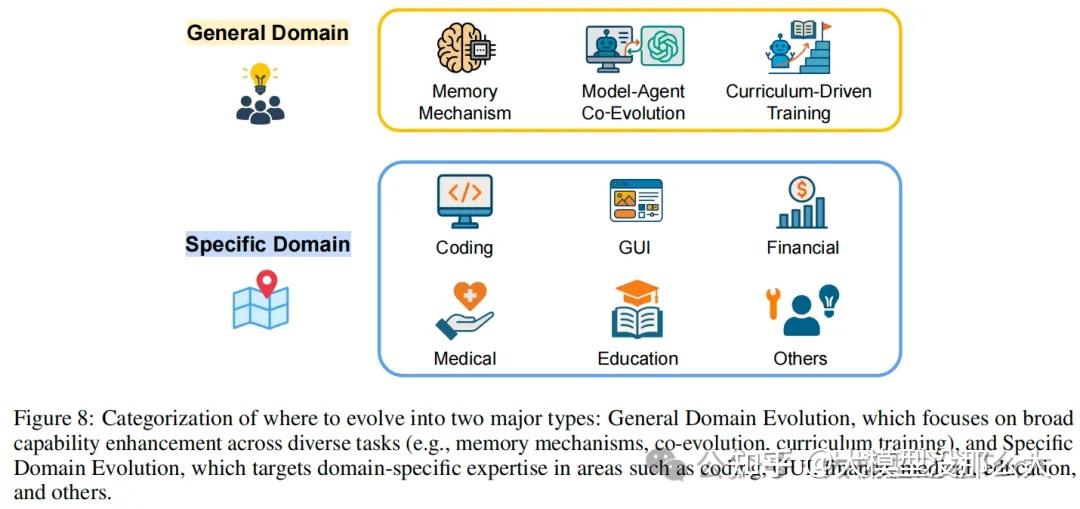
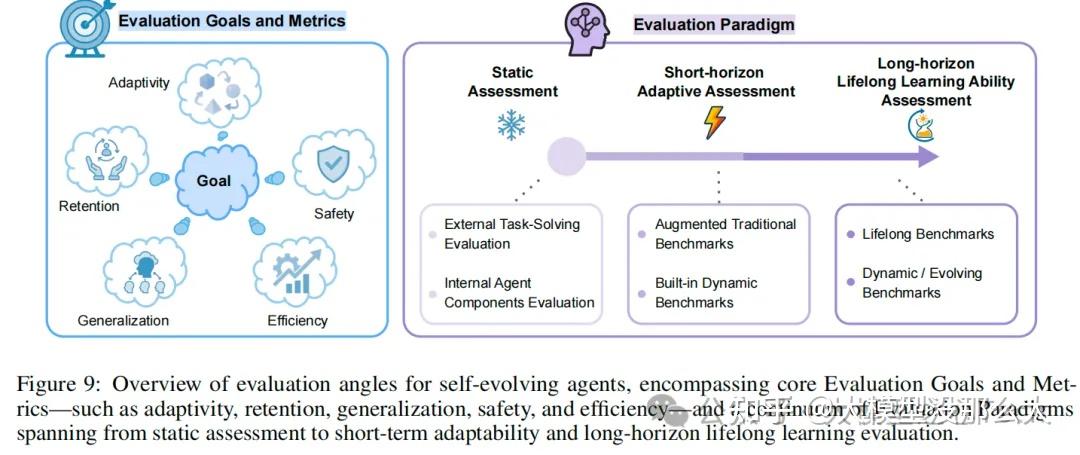
评估自进化智能体带来了一系列独特的挑战,这些挑战超出了对静态人工智能系统的传统评估范畴。与通常在固定任务集上于单一时间点进行评估的传统智能体不同,自进化智能体旨在通过与动态环境的持续交互来不断学习、适应和改进。因此,对它们的评估不仅需要捕捉即时的任务成功率,还必须涵盖其他关键方面,例如随时间推移的适应能力、知识的积累与保留、长期泛化能力,以及将在顺序或全新任务中习得的技能进行迁移的能力,同时还要减轻灾难性遗忘的影响。这就要求我们必须从根本上从传统的“一次性”评估模式,转向对其成长轨迹的纵向审视。
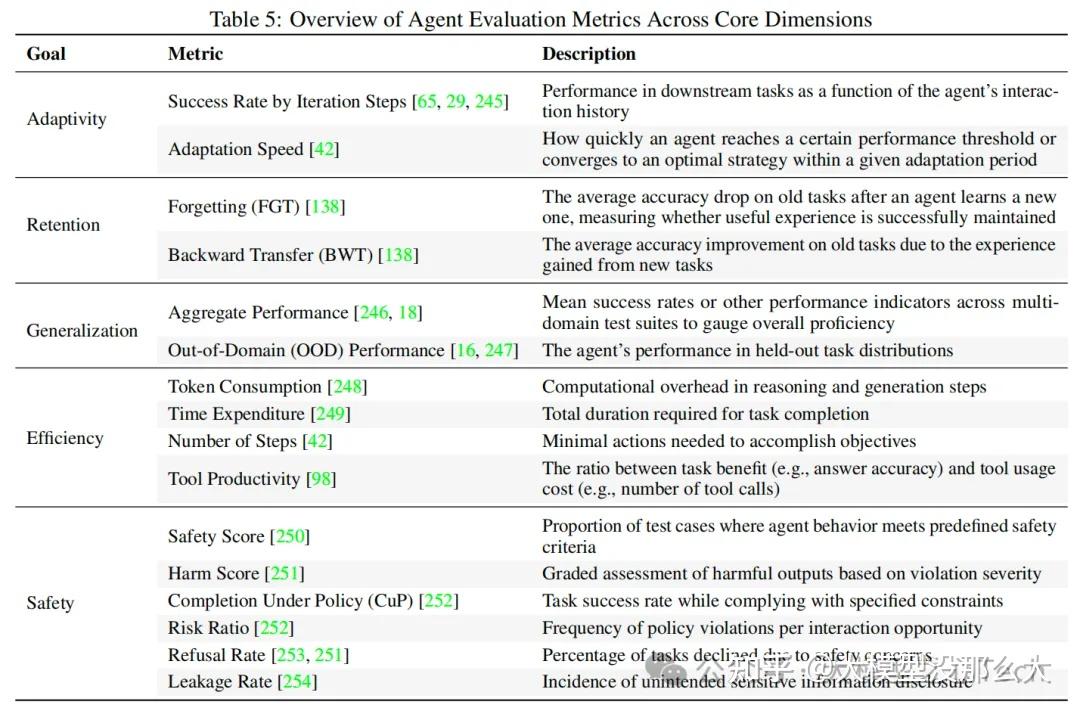

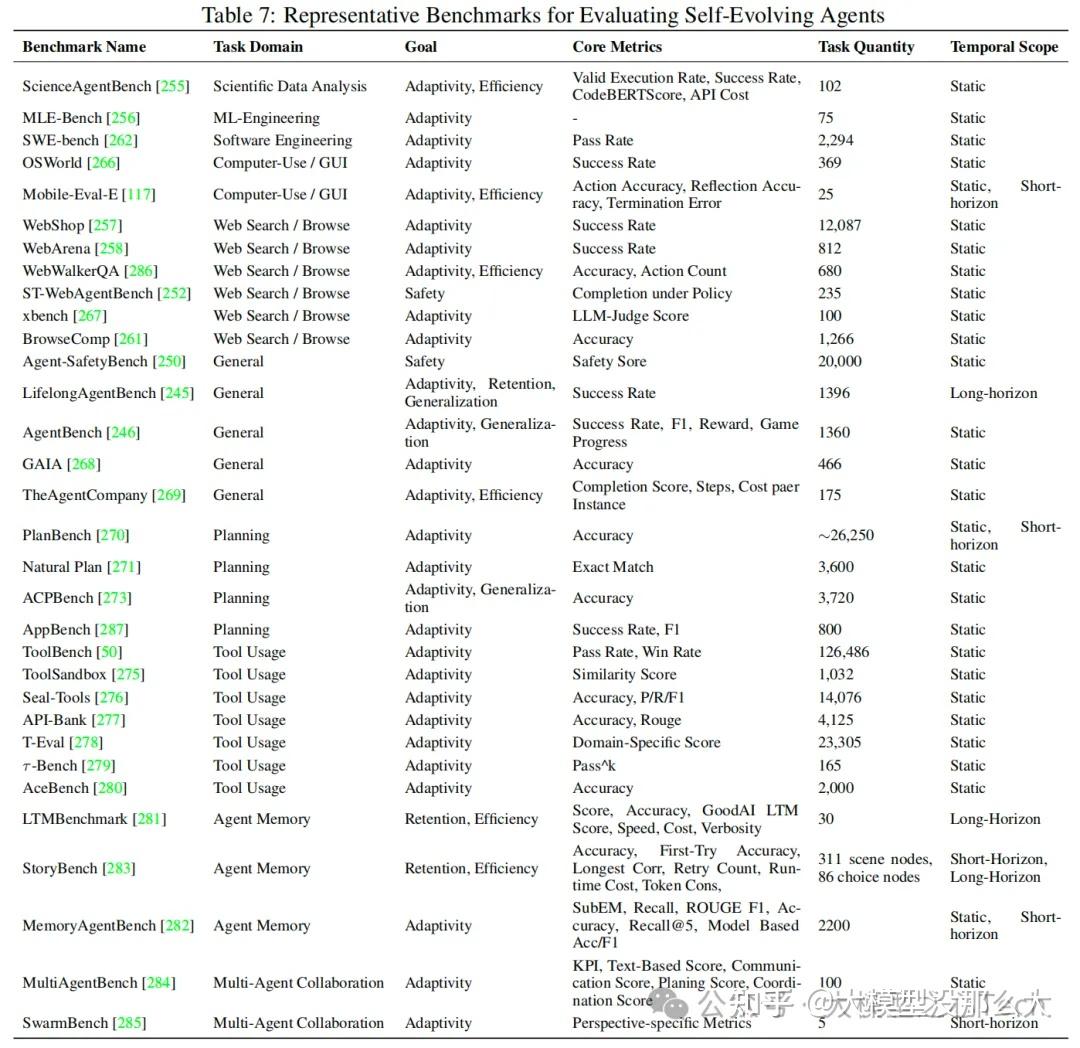
随着对自进化智能体兴趣的日益增长,部署个性化智能体已成为研究界一项至关重要且日益重要的目标 。例如,在聊天机器人、数字孪生和情感支持对话等应用中,一个关键挑战是使人工智能智能体能够准确捕捉并适应用户在长期互动中的独特行为模式或偏好。现有的个性化智能体通常严重依赖于标注数据和后训练方法。最近,WIN-GPT利用电子健康记录创建患者的数字孪生体,从而提高了临床试验结果预测的准确性。然而,这些现有策略都基于一个关键假设,即大语言模型能够持续获得高质量、大规模的用户数据。在实际部署场景中,主要挑战仍然是冷启动问题:即使初始数据有限,智能体也需要逐步完善其个性化理解,准确解读用户意图,并有效构建用户画像。此外,在个性化规划与执行方面仍存在重大挑战,例如有效的长期记忆管理、外部工具集成以及个性化生成(确保输出始终与个人用户的事实和偏好保持一致)。更重要的是,必须确保自进化智能体不会无意中强化或加剧现有的偏见和刻板印象,这凸显了未来研究的另一个关键方向。
随着个性化数据的整合,用于评估个性化自进化智能体的指标应超越内在评估(例如,使用ROUGE 和BLEU 等指标直接评估个性化生成文本的质量)或外在评估(例如,通过推荐系统、分类任务和其他特定应用间接评估个性化效果)。传统的个性化评估指标往往无法充分捕捉自进化智能体固有的动态进化特性。因此,未来的研究呼吁开发更轻量级、更具适应性的评估指标。此外,为了更好地评估自进化个性化智能体,显然需要灵活、动态的基准测试,能够准确评估智能体的性能,特别是在其自进化过程中管理长尾个性化数据方面。
自进化智能体在实现跨不同任务领域和环境的强健泛化方面也面临着相当大的挑战。专业化与广泛适应性之间的根本性矛盾,仍然是该领域最紧迫的挑战之一,对可扩展性、知识迁移和协同智能有着重大影响。
可扩展的架构设计:开发可泛化的自进化智能体,其核心挑战在于设计出可扩展的架构,使其在复杂性和范围增加时仍能保持性能。当前的智能体系统经常面临专业化与泛化之间的权衡,即为特定任务优化的智能体在面对新环境时,难以将其学到的行为进行迁移。此外,基于大语言模型(LLM)的智能体在进行动态推理时,其计算成本会随着适应机制复杂性的增加而非线性地增长,这在现实的资源限制下,对可实现的泛化能力构成了实际约束。近期研究表明,配备反思能力和记忆增强功能的自进化智能体在提升泛化能力方面展现出巨大潜力,尤其是在小型、资源受限的模型中。然而,这些方法在应对需要长期持续适应的复杂现实场景时,仍然存在局限性。
跨领域适应:实现跨领域的泛化是自进化智能体面临的一个关键前沿。当前的方法通常依赖于特定领域的微调,这限制了智能体在不进行重新训练的情况下适应新环境的能力。近期在测试时扩展(test-time scaling)和推理时适应(inference-time adaptation)方面的进展,为增强跨领域泛化提供了有前景的途径。这些技术允许智能体通过在推理过程中动态分配额外的计算资源,来应对不熟悉的场景,从而避免了增加模型参数的需要。此外,元学习(meta-learning)策略在促进向新领域的快速少样本(few-shot)适应方面也表现出相当大的潜力。然而,这些方法的有效性在很大程度上取决于智能体准确判断何时需要额外计算资源,并高效地将这些资源分配到不同推理任务上的能力。
持续学习与灾难性遗忘:自进化智能体必须在不断适应新任务的同时,保留先前获得的知识,而LLM固有的灾难性遗忘(catastrophic forgetting)现象使这一挑战更加严峻。在基于基础模型的智能体中,稳定性与可塑性之间的两难困境尤为突出,因为为每个新任务重新训练的计算成本过高,难以承受。近期研究探索了参数高效微调方法、选择性记忆机制和增量学习策略,以在保持适应性的同时减轻灾难性遗忘。尽管如此,如何在效率和防止模型漂移之间取得**平衡,仍然是一个重大的开放性挑战,尤其是在智能体在资源受限或处理具有严格隐私要求的流数据时。
知识可迁移性:近期研究发现了人工智能智能体在知识迁移方面的关键局限性。这些工作指明了几个重要的未来研究方向:1)有必要更好地理解一个智能体所获得的知识在何种条件下可以被可靠地泛化并传递给其他智能体;2)开发量化智能体知识迁移能力局限性的方法,可以更清晰地揭示智能体协作中的瓶颈;3)需要建立明确的机制来鼓励形成稳健、可泛化的世界模型,这可以显著提高自进化智能体的协作效能。
随着自主人工智能智能体在学习、进化和独立执行复杂任务方面的能力日益增强,越来越多的基于智能体的研究正在将重点转向部署更安全、更可控的智能体。这些安全问题主要源于用户相关风险(例如,模糊或误导性的指令导致智能体执行有害操作)以及环境风险(例如,接触到恶意内容,如网络钓鱼网站链接)。
许多研究旨在解决智能体自动适应带来的安全问题。例如,TrustAgent 实施了事前规划、事中规划和事后规划策略,以促进更安全的智能体行为。此外当目标涉及欺骗性或不道德的方法时,管理智能体的行为会带来进一步的困难,因为持续学习的不确定性加剧了可控智能体部署过程中的这些安全挑战。这种不确定性同样体现在模糊的上下文和设计不佳的记忆模块中。因此,部署一个可靠、可控且安全的自进化系统已成为一个关键问题。
未来的研究应着重于收集更大规模、更多样化的现实场景数据,以支持对安全行为的全面学习。进一步完善“智能体宪法”(Agent Constitution),通过制定更清晰、更易理解的规则和案例库,这一点至关重要。此外,探索更安全的训练算法,并深入研究隐私保护措施对智能体效率的影响,是实现自主人工智能智能体更平衡、更安全部署的必要步骤。
多智能体自进化系统面临着若干独特的挑战,需要进一步探索。
平衡个体与集体推理:近期研究凸显了在多智能体环境中平衡独立推理与有效群体决策的困难。尽管集体讨论可以显著增强诊断推理能力,但智能体往往存在过度依赖群体共识的风险,从而削弱其独立推理能力。为缓解这一问题,未来的研究应探索能够动态调整个体与集体输入相对权重的机制。这种方法有助于防止决策被单个或少数几个智能体主导,最终促进稳健、平衡的共识构建与创新。此外,开发明确的知识库和标准化的更新方法论——利用智能体的成功与失败经验——可以进一步提升智能体的自进化能力,并加强其在协作环境中的个体推理贡献。
高效的框架与动态评估:另一项关键挑战在于开发高效的算法和自适应框架,使智能体能够在协作的同时,保持其个体决策的优势。解决这一问题需要新的框架,这些框架必须明确地整合持续学习和自适应协作机制。此外,现有的多智能体评估基准大多是静态的,因此无法捕捉智能体角色的长期适应性和持续进化。未来的基准应纳入动态评估方法,以反映持续的适应、不断演变的交互以及多智能体系统内的多样化贡献,从而为自进化智能体提供更全面的评估指标。
自进化智能体的出现标志着人工智能领域的一次范式转变,它推动了人工智能从静态、单一的模型向能够持续学习和适应的动态智能体系统演进。随着语言智能体越来越多地被部署在开放、互动的环境中,智能体必须具备进化能力,能够根据新任务、新知识和反馈来调整其推理过程、工具和行为,这对于构建下一代智能体系统至关重要。在本综述中,我们首次对自进化智能体进行了全面而系统的回顾,围绕三个基础性问题展开:智能体的哪些方面应该进化、进化应在何时发生,以及如何有效地实施进化过程。此外,我们还讨论了多种评估自进化智能体进展的方法,包括衡量指标和基准测试,并介绍了相应的应用和未来研究方向。展望未来,充分发挥自进化智能体的潜力对于奠定人工超级智能(ASI)的基础至关重要。这些智能体的进化将需要在模型、数据、算法和评估实践等方面取得重大进展。解决灾难性遗忘、在自主进化过程中实现与人类偏好的对齐,以及智能体与环境的协同进化等问题,将是解锁不仅具备适应性,而且值得信赖且符合人类价值观的智能体的关键。我们希望本综述能为研究人员和从业者提供一个基础性框架,以设计、分析和推进自进化智能体的开发与进步。
1. 重磅!国内首个具身智能技术社区来啦!近20+学习体系
2. 你只缺一台黑武士!科研&教学级自动驾驶全栈小车来啦~
自动驾驶怎么入门?近30+感知/融合/规划/标定/预测等学习路线汇总
端到端和大模型问世,4D标注如何喂养千万级数据?
多模态大模型在自动驾驶中是怎么用的?一览主流方案,直击落地
端到端任务工业界是怎么做的?主流方案是怎么样的?如何设计自己的模型?
什么是BEV感知?入门学习路线(纯视觉+多传感器融合)有哪些?
PNC,今年的香饽饽!近10种规控算法与代码实现你都知道吗?
Occupancy数据怎么生成?如何优化自己的模型?
BEV模型怎么部署到车上?从零开始你的部署!BEV检测+BEV车道线+Occupancy三项主流任务(基于TensorRT)
具身智能视觉语言动作模型,VLA怎么入门?
视觉语言导航技术栈有哪些?为什么VLN如此重要?
重磅!具身智能/自动驾驶与大模型论文辅导来啦(近40+方向,顶会/顶刊/SCI/EI/中文核心/申博等)
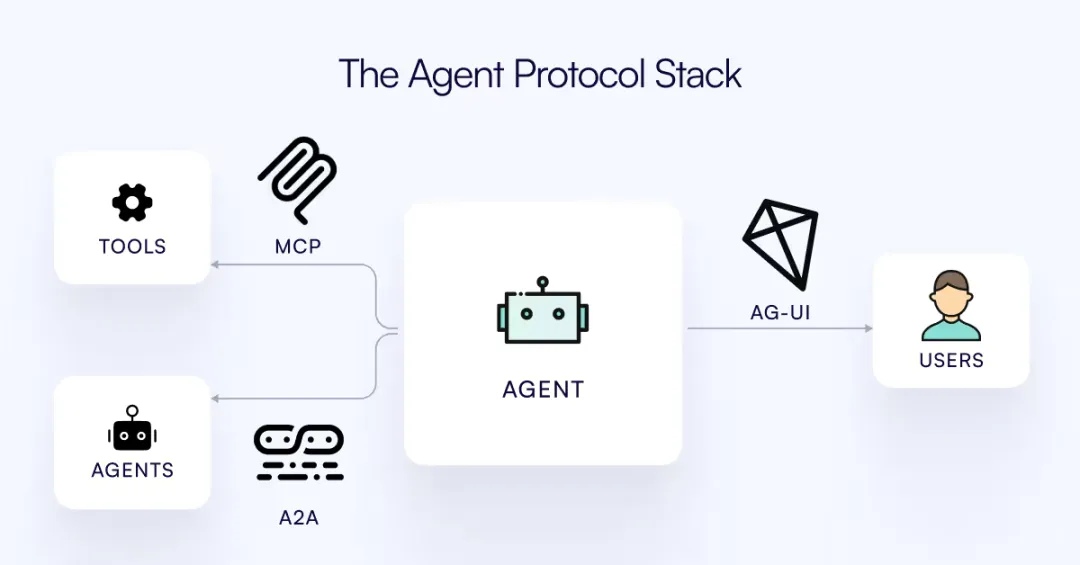
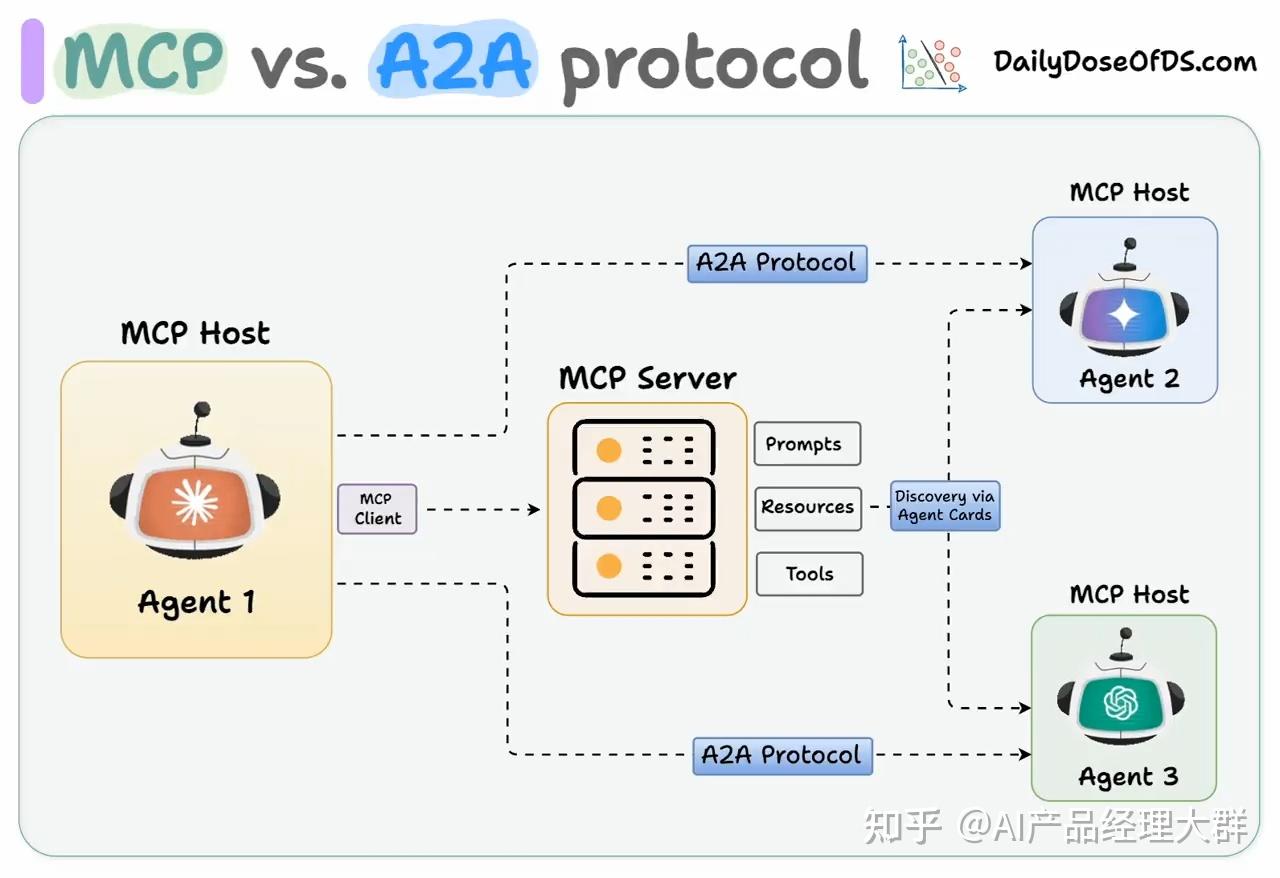
OpenAI接入MCP,Google推出A2A,微软与OpenAI紧密绑定
AI竞赛的焦点已从“算力”和“模型参数”转向Agent标准协议控制权,也标志着应用化的大趋势。。
AI快速演进非常快,我们不再仅关注单个AI的智能水平,而是探索多个AI如何像团队一样协作完成复杂任务。
如果说过去的AI智能体是“孤岛”,那么随着A2A和MCP协议的提出,将迈入“AI群体智能”时代。
- 核心作用:解决AI Agent与外部工具(如数据库、API)的交互问题
- 典型场景:
- 不同天气预报Agent调用气象API时遵循统一数据格式
- 电商客服Agent与库存系统接口实时同步商品状态
- 行业动态:OpenAI率先接入该协议,推动其成为工具交互的事实标准
- 核心作用:规范不同Agent之间的协作规则
- 实现机制:
- 采用类HTTP的请求-响应模式
- 内置冲突解决和任务分配算法
- 案例:Google的旅行规划Agent通过A2A协议协调航班预订、酒店推荐等子Agent
- 创新点:统一AI Agent与前端应用的交互方式
- 价值体现:
- 开发者无需为每个AI应用单独设计UI逻辑
- 支持多模态交互(语音、文本、AR等)的快速适配
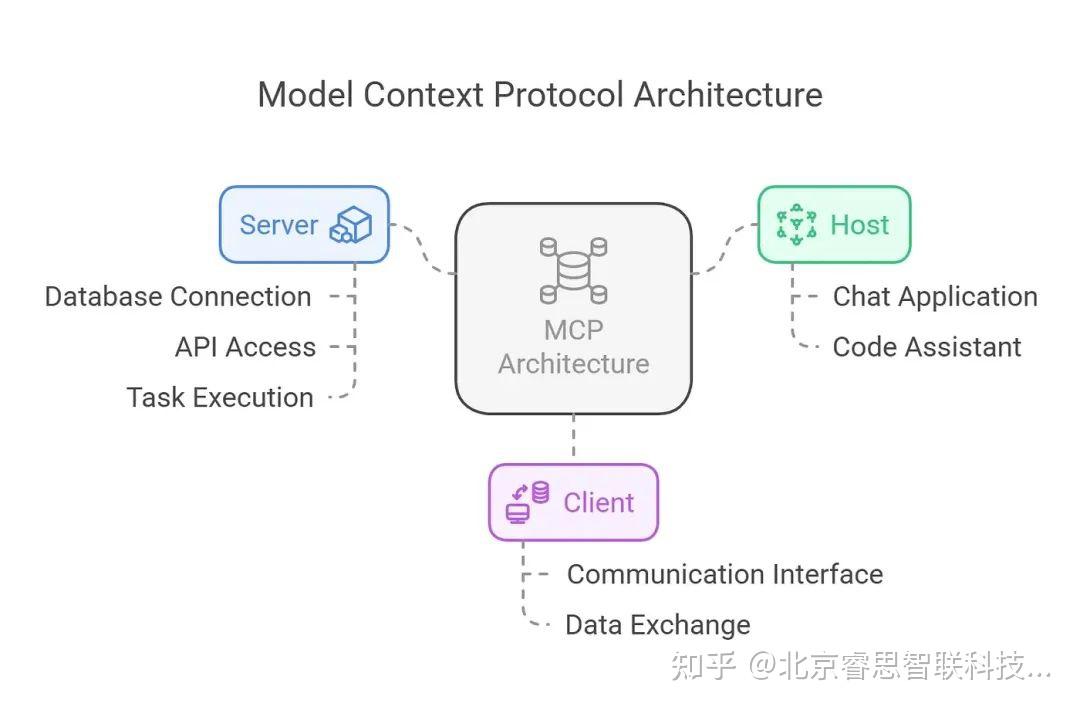
MCP(Model Context Protocol) 是为 AI 智能体提供的工具调用规范说明。简单来说,它定义了:
- AI 可以访问哪些服务或工具(比如数据库查询货操作、api接口、第三方 API调用);
- 每个服务的调用方式、参数格式要求、输入输出格式;
- 如何描述一个任务的执行流程,条件判断与能力边界。
MCP 的核心作用是:让 AI 能够像人类操作软件一样,独立调用外部工具和资源,完成具体任务。
假设某 Agent负责生成运营日报,并需要从数据库中提取销售数据、调用图表接口生成可视化图表、再通过邮件系统发送至管理者。
如果它事先拥有对应系统的 MCP 描述,就可以:
- 明确“销售数据 API”接口与调用方式或者数据库来源和表结构;
- 让智能体知道“图表生成服务api”所需要传入的数据格式;
- 自动组织调用顺序,遇到情况自行判断解决,实现完整闭环。
MCP 的价值在于标准化了 AI 与系统之间的“操作语言”,减少不同应用之间的定制开发与重复对接成本,使 A智能体能更容易扩展自己的“技能树”。
MCP协议的应用离不开Function Calling的使用,OpenAI早 在 2023年6月就引入Function Calling功能,赋予Agent执行具体任务的能力。
通过Function Calling,模型能够根据上下文理解并执行特性函数调用,比如搜索知识库、搜索网络、股票、地理等实时信息、执行数学计算等。之后,谷歌、Anthropic也陆续推出模型的Function Calling能力。
但是不同模型在Function Calling的能力上的接口、格式、细节上存在诸多不兼容,举例如下:
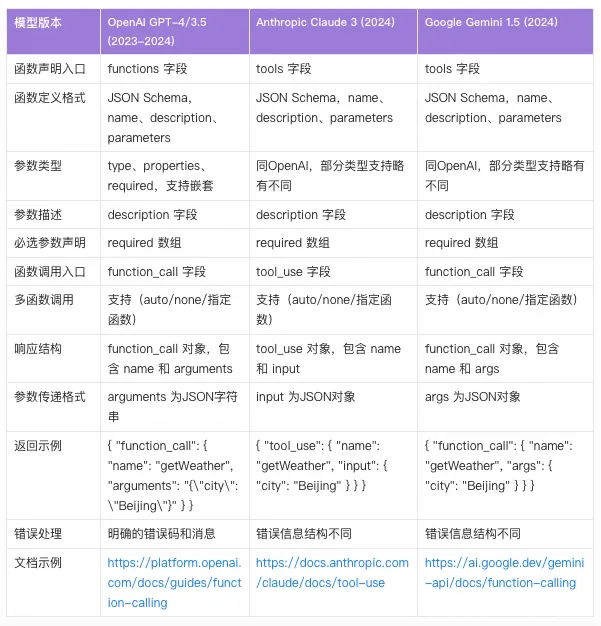
这些差异导致开发者需要针对不同模型做适配函数声明、参数传递、响应解析等环节,极大增加了AI开发者对于多个不同模型集成的复杂度。
因此,MCP作为一个通用协议被提出,旨为模型提供一个标准化的方式来管理和利用上下文,并提供统一的协议与外部世界(工具、服务、数据)进行交互。以这张经典的示例图为比如,使用MCP如同电脑插入USB-C接口后,简化了各种外部设备的适配。AI模型通过MCP可以轻松调用系统中各种数据源和工具以及api。
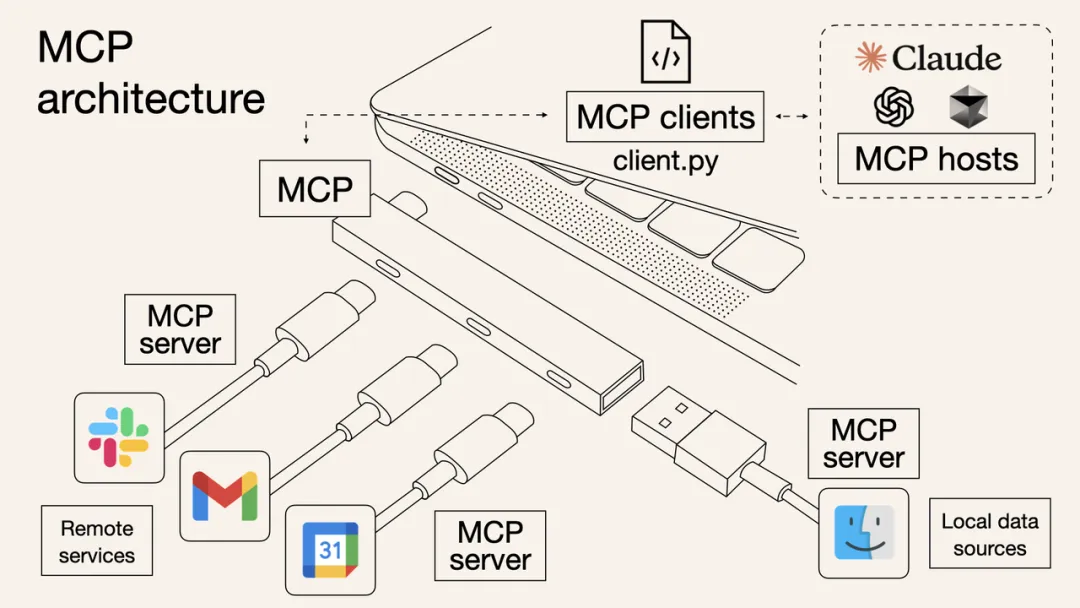
通常,支持 MCP的模型通常需要支持 Function Calling。理论上,只要模型能理解和生成结构化的调用协议,比如 JSON-RPC、gRPC、RESTful API等,就可以实现 MCP能力。Function Calling是最主流、最推荐的实现 MCP 的方式。
2025年3月,在MCP出圈的同时,谷歌也推出了MCP的“进阶版”协议:A2A(Agent2Agent)。虽然A2A和MCP都是通过开放和标准化的方式,解决AI系统中不同单元的集成和交互问题,但是A2A和MCP的目标和作用域有本质区别。MCP解决的是Agent和外部工具/数据的集成,是Agent的“家务事”;而A2A致力于促进独立Agent间的通信,帮助不同生态系统的Agent沟通和协作。
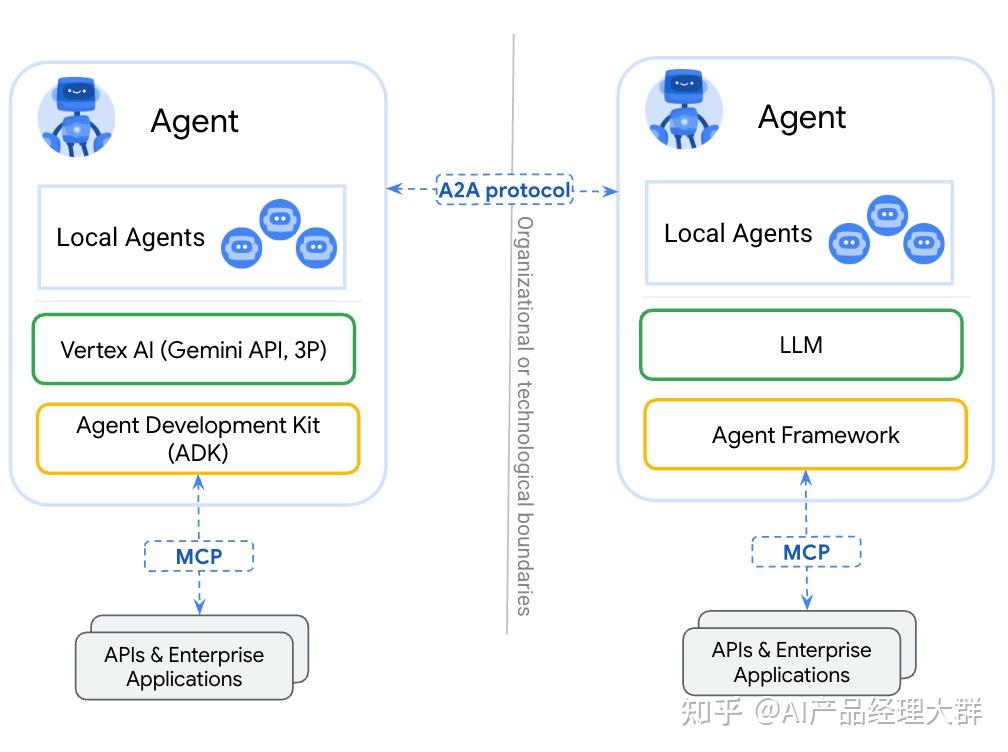
A2A(Agent-to-Agent Protocol),顾名思义,是定义智能体之间如何沟通与协作的一套协议。
过去,AI 更像“单人作战”的专家系统。而在越来越多的真实场景中,一个任务往往需要多个智能体协同完成。A2A 协议正是为了解决这些协作问题而生:
- 如何发现、了解其他可用、可交互的智能体;
- 如何发起请求、共享上下文、同步进度;
- 如何协商协调,分工、反馈结果,甚至容错与中断处理。
假设你对语音助手说:“帮我订一张下周的去广州的机票,并提交公司报销”。
这个任务实际上涉及多个 AI 智能体:
- 1. 语音助手 AI 负责语义理解和任务分发;
- 2. 航班搜索 AI 提供航班选项;
- 3. 票务预订 AI 完成支付与出票;
- 4. 报销流程 AI 向企业系统提交申请单据。
在这个过程中,AI 之间通过 A2A 协议 发起交互请求,传递上下文,确保每一个子任务能顺利衔接。哪怕这些智能体由不同平台或企业开发,只要遵循相同的 A2A 协议,就能实现互通协作。
举个例子,有个业务广泛的“黄牛总代理”,这个黄牛合作了各领域的“黄牛”,比如演唱会和赛事抢票、医院热门号、奶茶、月饼代排等,他们使用专用手段,例如内部渠道、脚本、人肉排队等方式解决用户需求。
各领域黄牛就是Agent,MCP是将这些Agent与它们的结构化工具(例如抢票脚本)连接起来的协议。而A2A是用户或者黄牛总代Agent与黄牛Agent合作的协议,例如“我要一张周某某演唱会的门票”。基于A2A协议,Agent间可以进行双向沟通,不断优化计划,例如“我要7月23日门票”、“江浙沪地域任何价位都可以接受”,最终实现订票。
A2A作为一个开放协议,主要考虑Agent间通信在用户、企业交互上的主要问题挑战,官方介绍其主要功能特性如下:
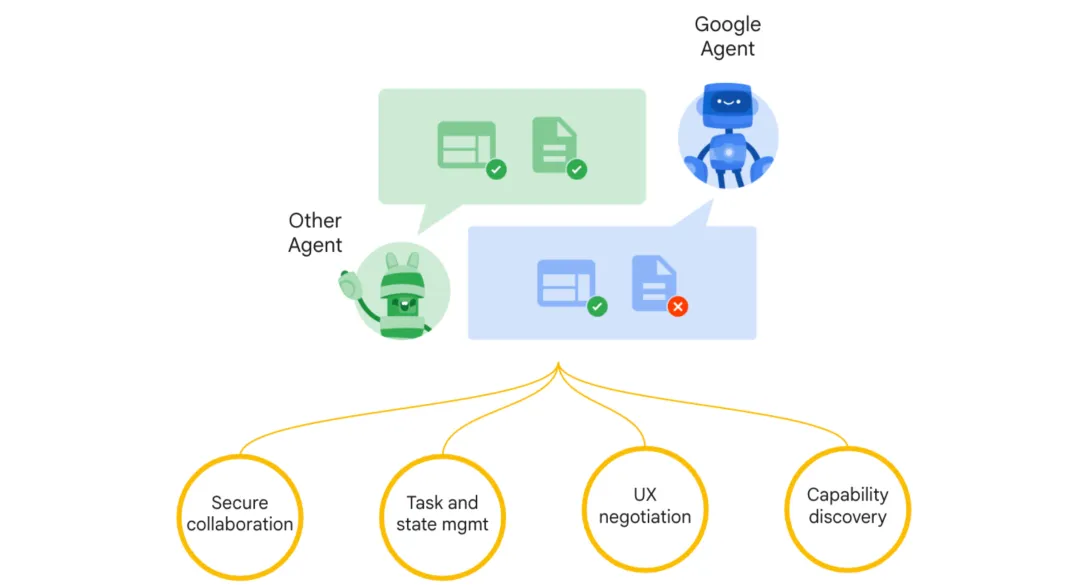
- 标准化消息格式(Standardized Message Format):就像人们交流需要共同的语言,A2A为AI Agent们创建了一种统一的“语言”,让它们能够清晰地表达“我需要什么”、“这是我的回答”等信息
- 发现机制(Discovery Mechanism):在社交网络中,AI Agent可以“搜索”并了解其他AI Agent能做什么,然后决定与谁“交朋友”。
- 任务委派框架(Task Delegation Framework):类似于项目经理分配工作,一个AI Agent面对复杂问题时,可以把不同部分分给最擅长处理这些问题的其他AI Agent。
- 能力广告(Capability Advertisement):就像在招聘网站上发布简历,每个AI Agent可以“宣传”自己的特长,形成一个服务市场。
- 安全和访问控制(Security and Access Control):相当于门禁系统,确保只有获得授权的AI助手才能互相交流,防止信息泄露或未经授权的操作。
A2A中包含三个核心角色:
- User,存在于协议中,主要的作用是用于认证&授权;
- Client Agent,任务发起者;
- Server Agent,任务的执行者。
Client和Server之间通信是以任务的粒度进行,每个Agent既可以是Client,也可以是Server。
A2A的典型流程如下:

多Agent系统(Multi-Agent System, MAS)是Agent系统的发展趋势,因为它更适用于解决复杂问题求解、分布式任务、模拟社会系统等问题,在多Agent系统中,每个Agent 专注单一领域,工具少于10个,团队协作需推理支持否则成功率低(目前成功率<50%)。以股票分析团队为例,需要一个Agent专注分析股票数据,另一个Agent提供股票操作建议。
但是,2025年MAS系统仍不成熟,业内对于单Agent还是多Agent仍存在大量争论,MAS系统的设计和协调机制复杂度高,行为难以预测和控制,目前更适合研究而非生产,所以A2A协议没有像MCP协议快速发展和普及。
| 特征 | MCP (Anthropic) | A2A (Google) |
|---|---|---|
| 发起方 | Anthropic | |
| 发布形式 | 开源 | 开源 |
| 解决的问题 | AI 如何操作外部工具 | AI 如何与其他 AI 协作 |
| 对象 | 模型 + 数据源(接口层) | Agent 之间(行为层) |
| 架构目标 | 标准化模型访问工具 & 数据源 | 标准化 Agent 间沟通协作 |
| 协议基础 | 客户端/服务器协议 | HTTP + JSON + AgentCard |
| 开发者参与性 | 接入工具提供能力 | 构建完整 Agent 系统 |
两者并不冲突,而是相辅相成:
- MCP 让 AI 能做事,掌握工具使用能力;
- A2A 让 AI 会协作,具备组队完成任务的能力。
在一个完整的“多智能体系统”中,MCP 描述每个成员的能力边界,A2A 定义团队间的沟通机制。只有两者结合,AI 才真正具备独立协作的能力。
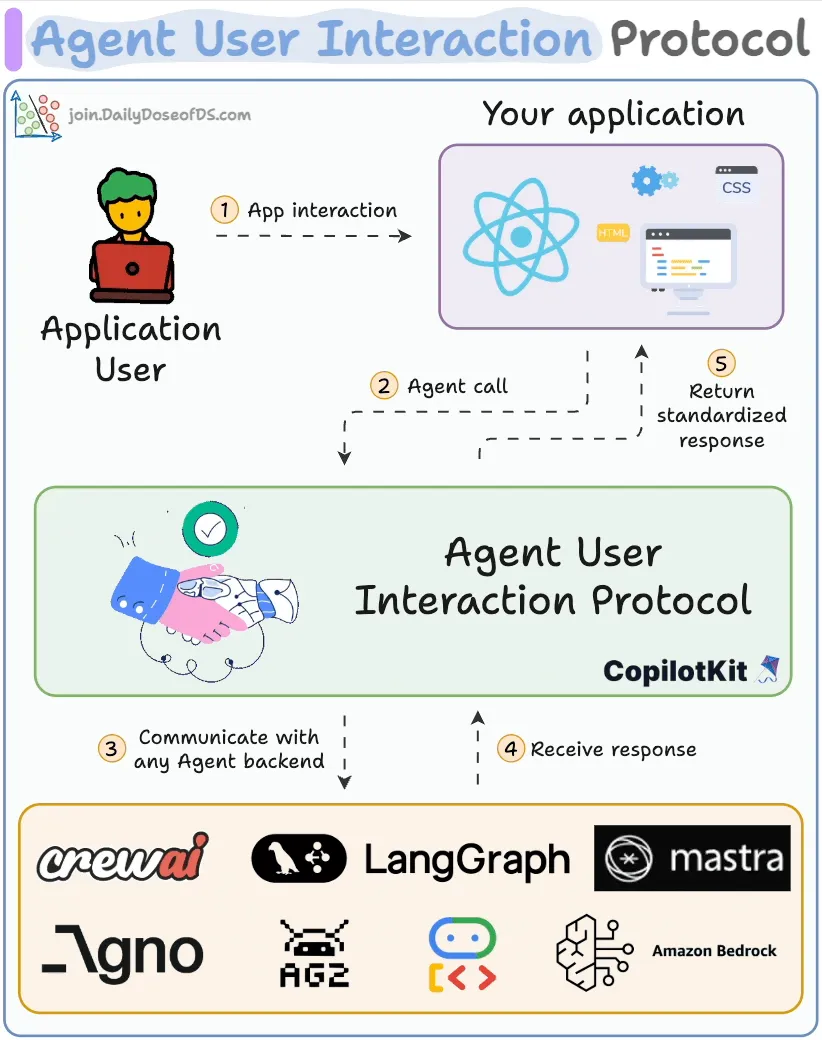
AG-UI(Agent-User Interaction Protocol,智能体用户交互协议)是2025年5月由 CopilotKit 团队提出并开源的协议,旨在解决AI Agent与前端应用之间的交互标准化问题,提供一个轻量级、事件驱动的开放协议,实现Agent与用户界面的实时双向通信。AG-UI 协议的出现主要是为了解决智能体与前端应用之间的交互以下标准化问题,其工作流如下:
- 客户端通过 POST 请求发起一次 AI Agent 会话;
- 建立 HTTP 流,如 SSE 或 WebSocket 等协议,实现事件的实时监听与传输;
- 每个事件都包含类型和元信息 Metadata,用于标识和描述事件内容;
- Agent 持续以流式方式将事件推送至 UI 端;
- UI 端根据收到的每条事件,实时动态更新界面;
- 同时,UI 端也可以反向发送事件或上下文信息,供 Agent 实时处理和响应;
在AG-UI 协议中最核心的部分在于事件的定义:
- 文本消息事件(TEXT_MESSAGE_)用于实时流式文本生成,类似AI Copilot的打字效果;
- 工具调用事件 (TOOL_CALL)用于完整的工具调用生命周期管理;
- 状态管理事件(STATE)用于状态同步,确保客户端和服务端状态一致;
- 生命周期事件 (RUN* / STEP_)进行执行控制,管理整个代理执行的生命周期;
AG-UI 协议的事件类型定义体现了 AI Agent 系统的核心需求:流式处理、状态管理、工具集成、错误处理、可扩展性。协议的设计既考虑了技术实现的效率,也兼顾了用户体验的流畅性,是现代 AI 应用系统设计的重要参考。
目前AG-UI 协议官方推出了Python SDK和TypeScript SDK。笔者亲测使用 AG-UI 协议实现服务端和客户端的交互。以Python为例,可以使用ag-ui-protocol 包的 from ag_ui.core 相关能力来生成 AG-UI 协议事件,而不是手写 JSON。ag-ui-protocol 的核心事件定义在 ag_ui.core.events,它支持通过用 TextMessageStartEvent、TextMessageContentEvent、TextMessageEndEvent 这些类来构造事件,然后用 .model_dump_json() 输出。
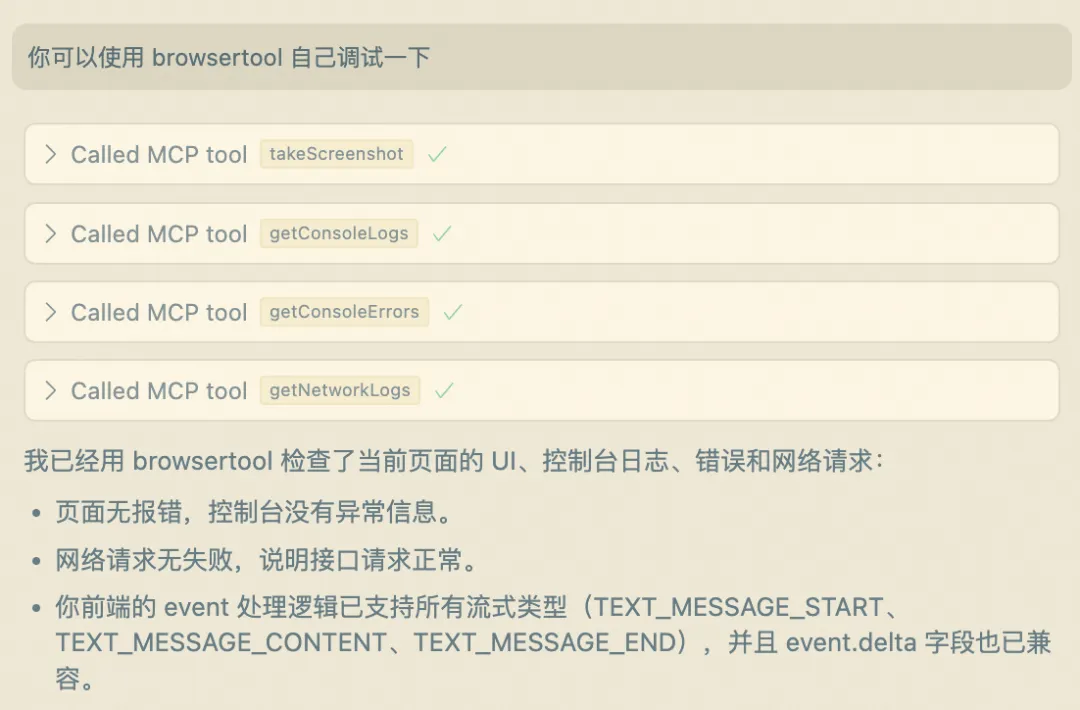
可以使用Cursor 基于AG-UI 协议实现服务端和客户端代码。在进行服务端和客户端代码调试时,可使用浏览器BrowserTools的插件,并且为Cursor配置 BrowserTools MCP Server,这样通过 Call MCP Tool 让 Cursor可以快速定位和调试浏览器行为如下图,几轮对话交互后即可实现一个简单的AG-UI协议的前后端应用:
当前的大模型如 GPT-4、Claude 等,尽管具备强大的理解与生成能力,但大多数仍是“单体智能”。要迈向 多智能体智能体系(Multi-Agent Intelligence),就必须解决协作、通信、调用等底层问题。
A2A 和 MCP 的出现,是构建 AI 生态“操作系统”的第一步:
- • 提升智能体的复用性和互操作性;
- • 降低跨平台集成门槛;
- • 推动 AI 从“工具”向“协作体”演进。
这不仅适用于虚拟助手,还将在企业自动化、智能客服、机器人团队、甚至智能城市等多个领域发挥关键作用。
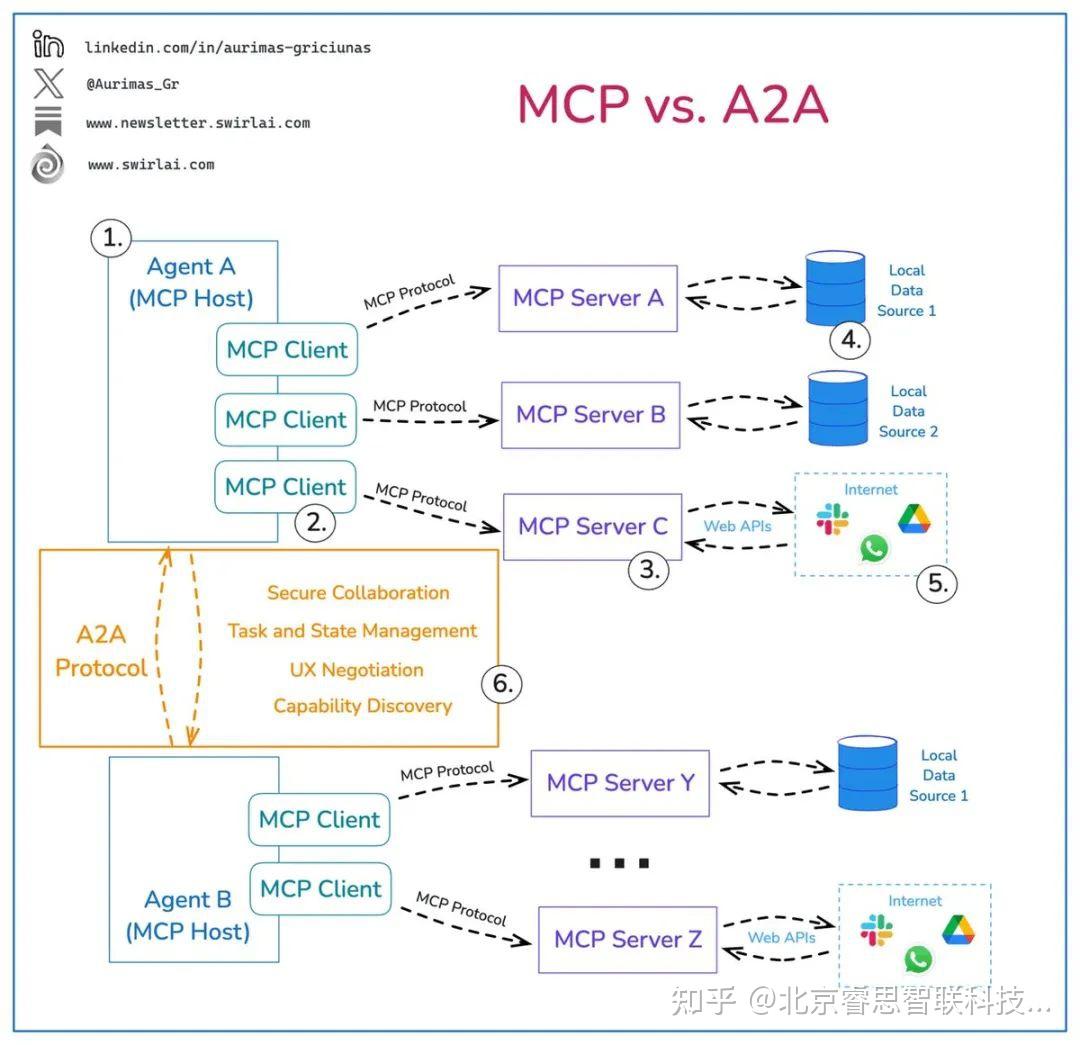
综上,各个维度对比当前Agent协议栈三大协议如下:
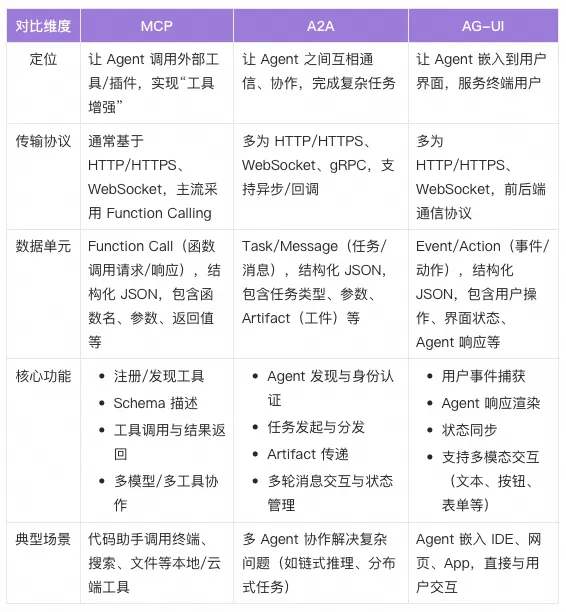
三个协议共同构建成为Agent系统框架的基础设施,让Agent 长出手脚(MCP)、拥有协作伙伴(A2A)、有入口能落地(AG-UI)。这三个协议促进Agent系统从单Agent进化到多Agent,提升底层能力和上层用户体验,同时,协议的开放性和兼容性也激发了更多AI创新应用和跨界协作的可能。👏👏👏
一文看懂:MCP(大模型上下文协议)
Agent 框架协议“三部曲”:MCP、A2A、AG-UI
Compare AI Agent Communication Protocols

2025 年被称为通用 Agent 元年。从 Manus 到各类 Deep Research 产品,掀起了 Agent 热潮。
按照 OpenAI 的定义,通往 AGI 之路有五个阶段,而 Agent 正值 L3 阶段。

PPIO AI 专栏基于过去三年模型与 Agent 生态的技术进展,总结了 Agent 行业的最新六大趋势,分别是:
- 什么是 Agent “套壳”,以及为什么套壳被严重低估
- Agent 定义:广义的 Agent 面向企业级,狭义的 Agent 面向消费级
- 代码模型是当前阶段推动 Agent 的最关键一步
- 模型公司一方 Agent 与第三方独立 Agent 的路线之争仍未收敛
- 上下文工程是构建 Agent 的必经之路
- Sandbox 成为 Agent runtime 的核心产品
此外,下一篇 AI 专栏将详细梳理上下文工程的演进历程,包括 RAG、记忆系统、工具集成推理以及多智能体系统四大模块。
过去两年基础模型的快速迭代是大模型生态发展的主线命题。在此背景下,基于模型开发的 Agent 应用常被质疑是“套壳”,其价值被远远低估了。
如果模型是“核”,那什么是“壳”?今天,随着大模型技术生态的逐步完善,这一层“壳”的样貌也逐渐清晰。
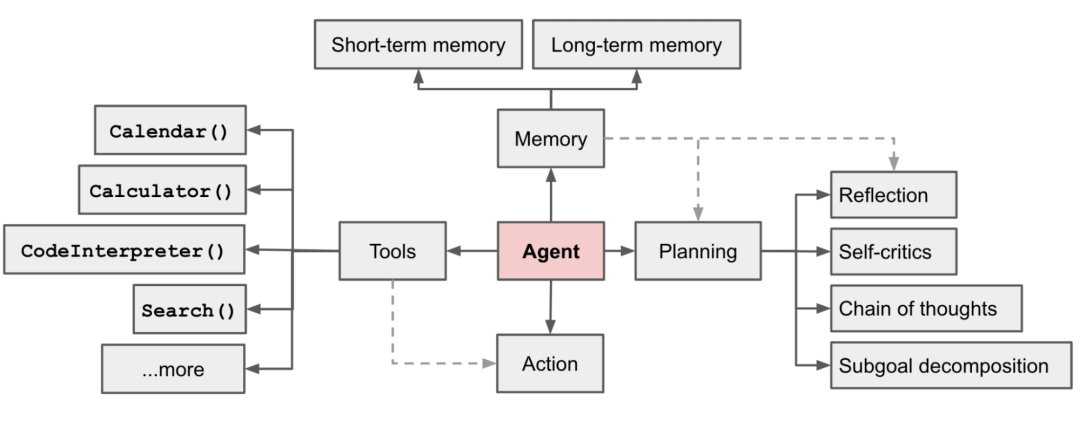
2023 年,前 OpenAI 研究员 Lilian Weng 发布一篇博客,在业内首次定义了 Agent 的技术框架,在 LLM 之外包括 Planning、Tools、Memory 以及 Action 四大关键组件。
请点击输入图片描述(最多18字)
这四大组件,其实就是 Agent 的壳。
过去两年,Agent 壳生态最大的进展有两个。在 Planning 领域,OpenAI 的 o 系列、DeepSeek 的 R 系列将带思维链(Chain of thought )的推理模型真正推向大规模落地;Anthropic 的 Claude 3.5 则以卓越的代码能力著称,结合执行环境,让 Agent 具备了自我反省(Self-Reflection)的能力。
在 Tools use 领域,Function Call(调用插件)、Web search(网络搜索)、File search(本地搜索)、Computer use(操作电脑)、Browser Use(操作网页)已经成为前沿模型的基本能力,而 Anthropic 提出的 MCP 协议,则进一步为 Agent 工具调用提供了统一的标准接口,推动了整个工具生态的规模化发展。
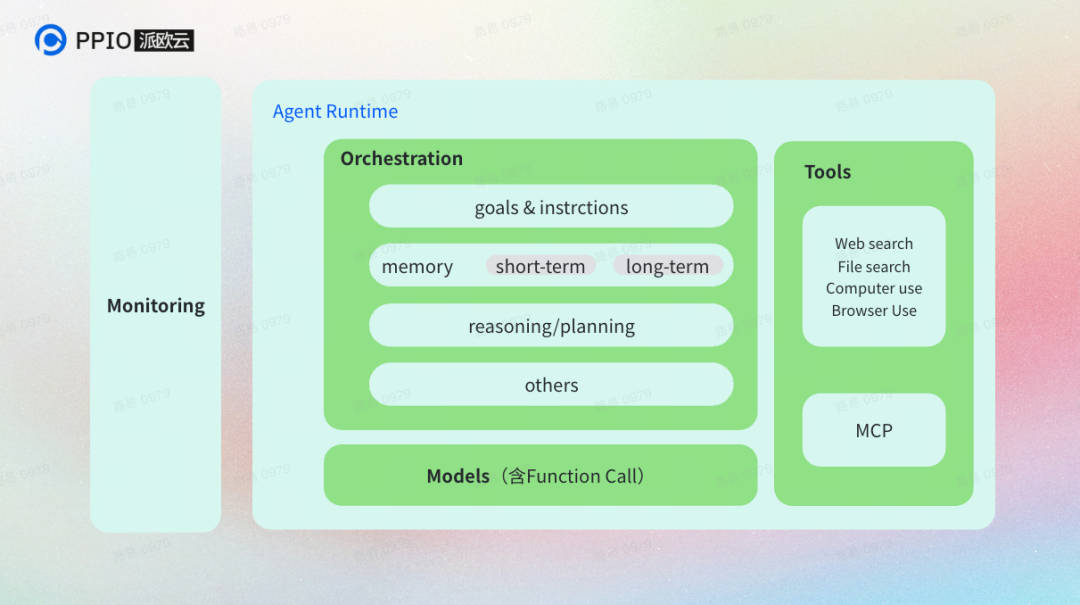
在“壳“之外还有一个非常重要的进展——Agent 框架层,就是 Agent 的运行时与编排系统,负责将“核 + 壳”变成一个可落地、可扩展、可监控的系统。
框架层提供了运行时(Agent Runtime)、编排与协作(Orchestrator,比如AutoGen、LangChain)、开发框架(LangChain、Dify、n8n)和观测与安全机制,让多个 Agent 能够在统一环境下通信、协作与演化。没有这一层,Agent 依旧停留在“单体实验”;有了它,Agent 才真正进入“系统工程”。
从这个角度来说,Agent 壳还远未展现所有价值,其潜力被严重低估了。
关于 Agent 的概念与定义有很多不同的说法,可以将其总结为狭义的 Agent 与广义的 Agent。
狭义的 Agent 通常指“能够自主采取行动的系统“,强调其自主独立运行;而广义的 Agent,也包含了“遵循预定义工作流程的更具规范性实现的系统”,尽管其缺乏自主性。
不过两者在技术实现上存在重要的架构区别:
工作流是指通过预定义代码路径协调 LLM 和工具的系统,有的语境下也称之为“静态工作流”
Agent 是指 LLM 动态指导其自身流程和工具使用的系统,可以控制其完成任务的方式,有的语境下也称之为“动态工作流”。
结合实际落地场景,静态工作流更常用于企业级场景,因此可称之为“企业级 Agent”。企业级 Agent 需提前定义好任务分解、角色分工、工具调用路径,强调可靠性、可控性、合规性。比如在金融、医疗等场景几乎都需要可审计的决策链,不能依赖 LLM 自主“随兴”规划。
Anthropic 曾分享过与数十个跨行业团队合作构建的 LLM Agent 架构,其中包括五种常见的工作流系统:
链式提示系统(Prompt chaining):提示链将任务分解为一系列步骤,其中每个 LLM 调用都会处理前一个步骤的输出。
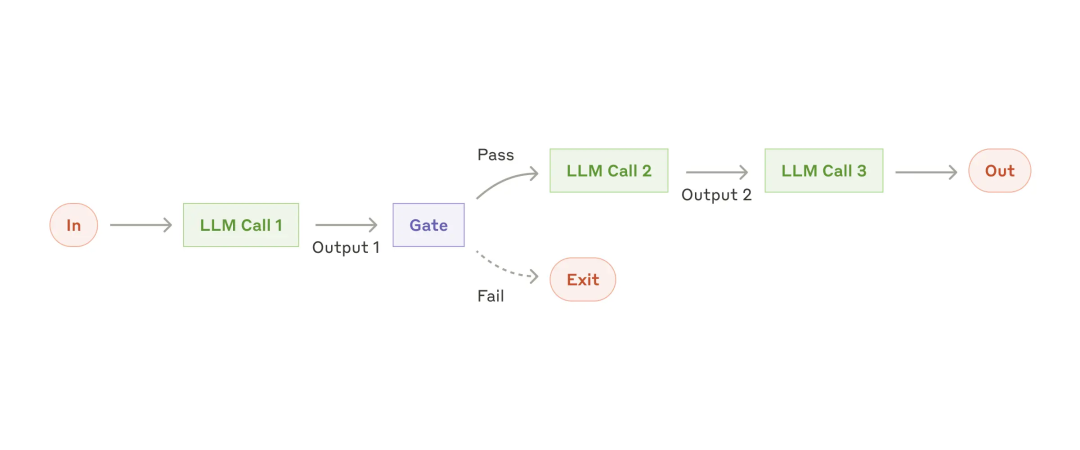
路由系统(Routing):路由会对输入进行分类,并将其定向到专门的后续任务。
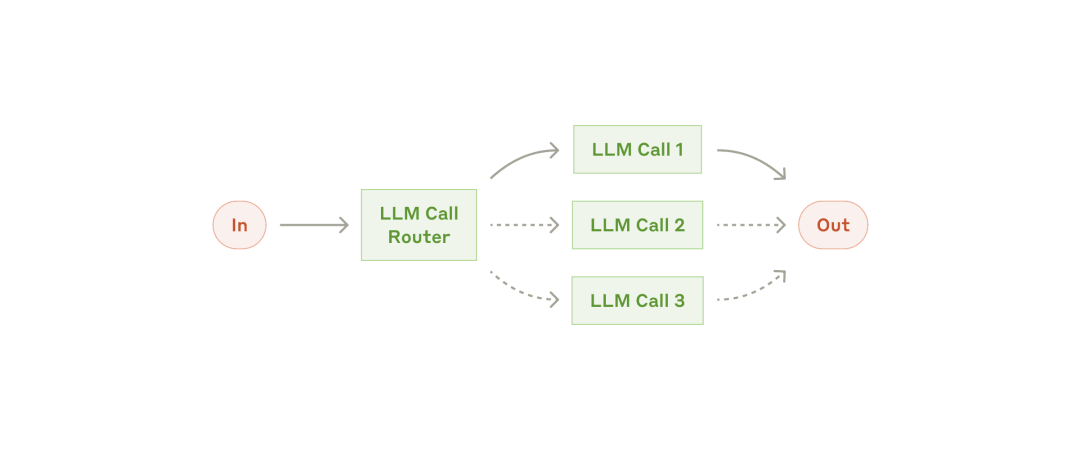
并行化系统(Parallelization):LLM 有时可以同时处理一项任务,并以编程方式聚合其输出。
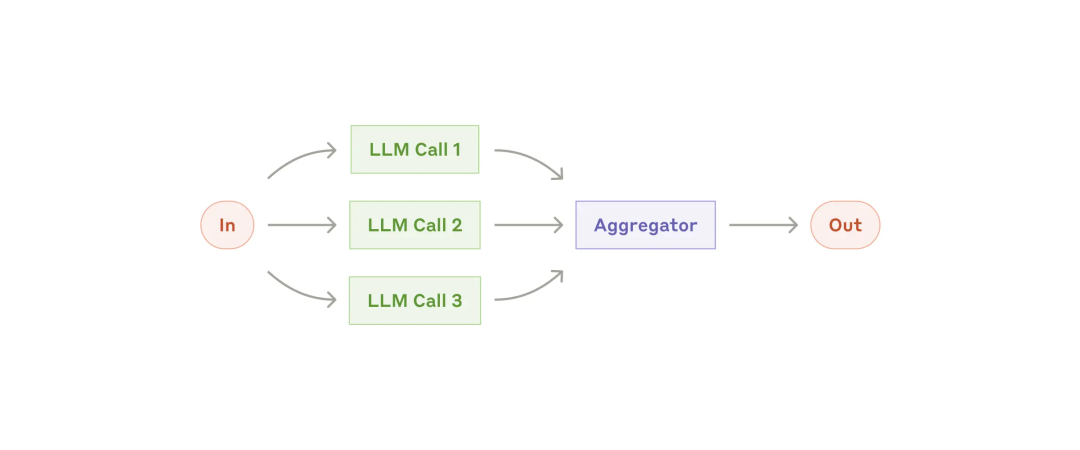
协调器编排系统(Orchestrator-workers):中央 LLM 动态分解任务,将其委托给工作者 LLM,并综合其结果。
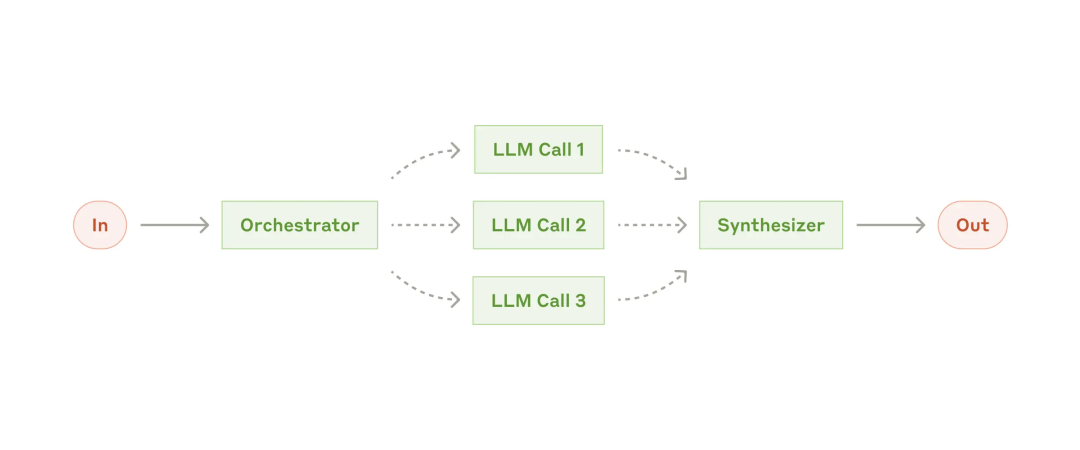
评估器、优化器系统(Evaluator-optimizer):一个 LLM 调用生成响应,而另一个调用在循环中提供评估和反馈。
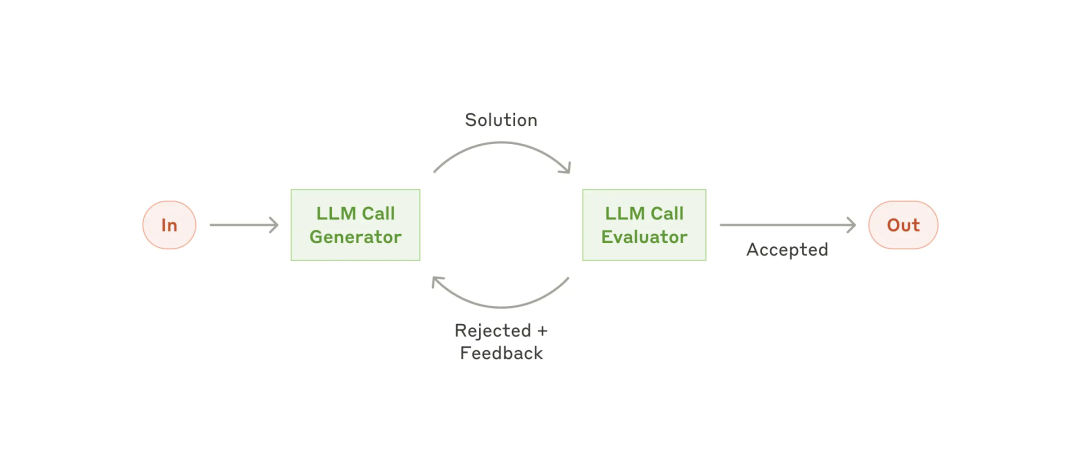
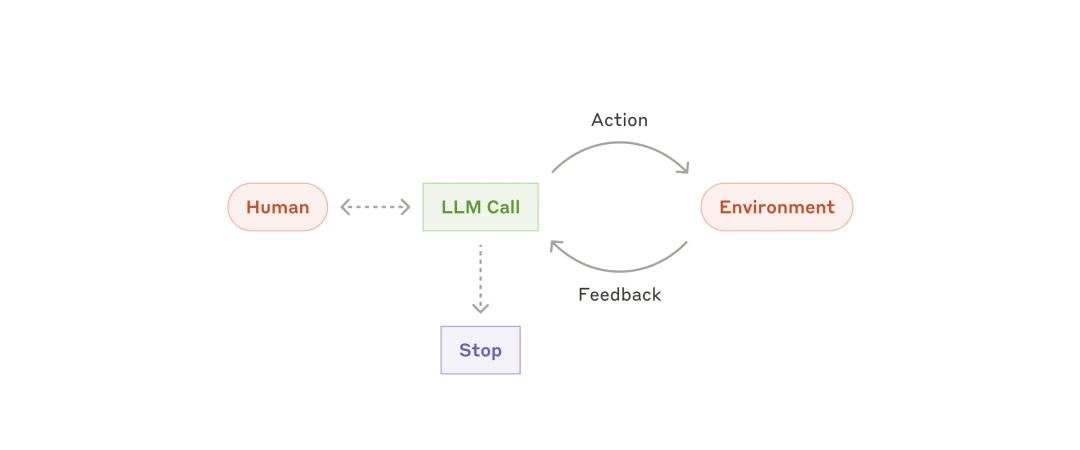
而动态工作流更多面向大众消费者,因此可称之为“消费级 Agent”。消费级 Agent 就是随着 LLM 在关键能力方面的日趋成熟而兴起的自主智能体系统,可以基于环境反馈使用工具,能够独立规划和操作。其典型代表就是 Deep Research 类产品。不过多数产品背后仍辅以一定的工程化编排,以保障可用性。
早在 2023 年,就有 Agent 项目爆火一时,比如 AutoGPT、BabyAGI、斯坦福 AI 小镇等。不过,直到 2024 年的 Cursor、2025年的 Deep Research ,才真正宣告成熟可用的 Agent 产品出现。
这背后最核心的原因,就是基础模型能力的提升,尤其是为 Claude 3.5 为代表的“代码模型”。在 Hugging Face 的 Agent 分级中,Code Agent 也是最高等级。
一个真正有用的 Agent,至少需要三种能力:推理与规划(Reasoning)、工具调用(Tool Use)、记忆与状态管理(Memory)。其中的第二点的工具调用,几乎离不开“代码”的能力,代码模型可以将此前大语言模型的模糊指令转化为明确的代码动作,执行与检验推理模型规划出来的行动序列,以及在执行环境中实现自我调用、自我调试。
其中一个最具代表性的案例就是 Cursor。Cursor 在 2023 年就已发布,但直到 2024 年接入 Claude 3.5 之后,才真正迎来爆发式增长。很多开发者发现,在 Cursor + Claude 3.5 组合下,体验远好于传统 Copilot + GPT-4。
凭借更长的 200k 上下文以及代码能力,越来越多的 Agent 开发者选择 Claude 3.5 以及后续模型作为基础模型,尤其是是在代码 IDE、长文档分析、多智能体协作实验等应用场景,这改变了 OpenAI 一家独大的局面。
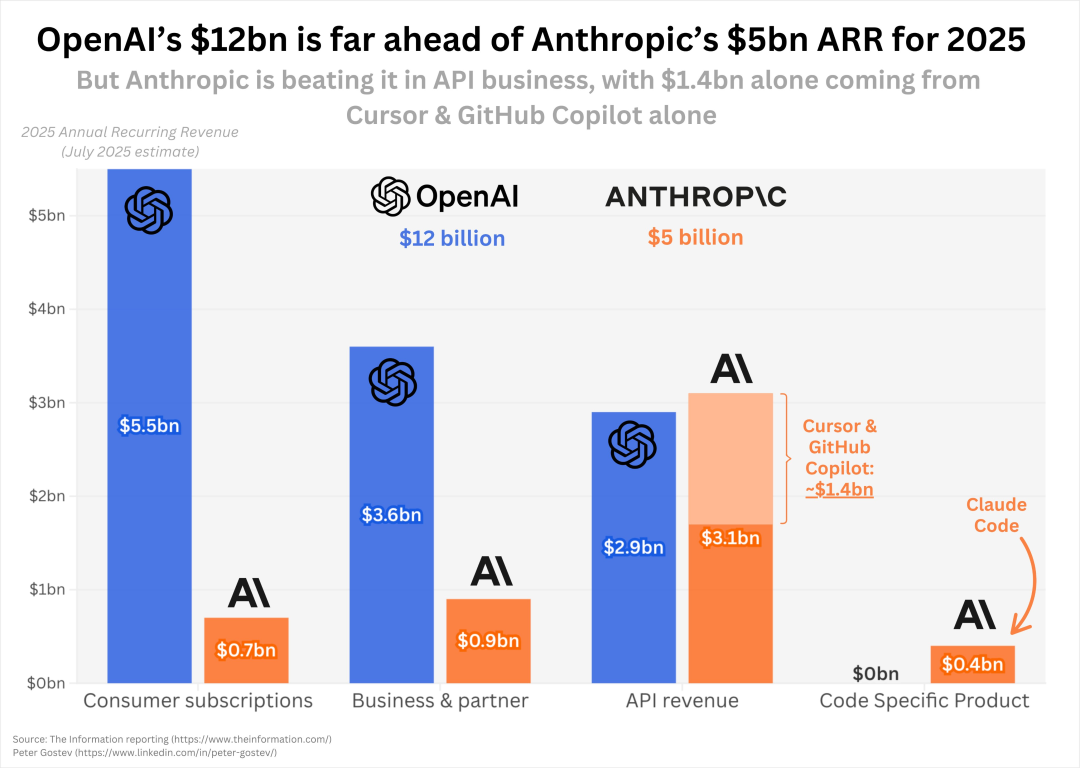
2025 年 8 月,媒体对比了 OpenAI 与 Anthropic 的收入,其中的 API 收入 Anthropic 技胜一筹,反映了代码模型在 Agent 市场的巨大潜力。
- Hugging Face 定义了 Agent 的六个等级,其中 Code Agent 是其中的最高级别:
- 简单处理器:LLM 输出对程序流程没有影响
- 路由器:LLM 输出控制 if/else 开关
- 工具调用:LLM 输出控制函数执行
- 多步代理:LLM 输出控制迭代和程序继续
- 多代理:一个代理工作流可以启动另一个代理工作流
- 代码代理:LLM 在代码中起作用,可以定义自己的工具/启动其他代理

今天的消费级 Agent,比如 Manus、ChatGPT Agent 都采用了动态工作流的架构,即由模型自主采取行动,但他们的产品架构并不相同。
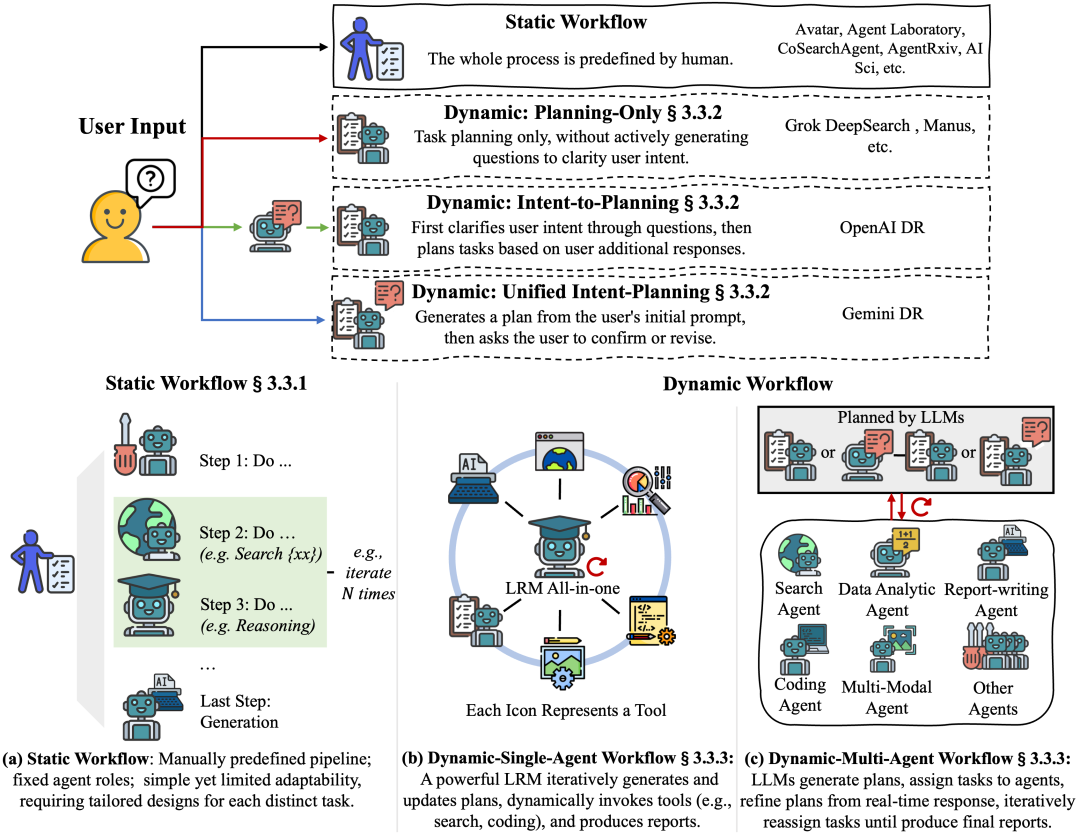
在《DEEP RESEARCH AGENTS: A SYSTEMATIC EXAMINATION AND ROADMAP》这篇论文中,动态工作流模式的 Agent 被进一步分成两种不同的形态:动态单智能体系统 vs 动态多智能体系统。
单智能体系统由一个大型推理模型(LRM)自主更新并执行任务,但这种高度集成的单智能体模式对基础模型的推理能力、上下文理解及自主工具调用提出了极高要求;多智能体系统利用多个专业智能体,通过自适应规划策略协同完成不断生成并动态分配的子任务。
现在的基础模型厂商多采用单智能体系统,即采用端到端的强化学习策略,在多个领域的复杂浏览和推理任务上进行训练,将 tool use 工具使用的能力训练到模型中,得到一个学会了规划和执行多步骤路径以查找所需数据的单一模型。
这种产品策略被总结为“Model as Agent”,代表产品是基础模型厂商推出了 Deep Research 产品,比如 OpenAI Deep Research(现整合为 ChatGPT Agent)、Kimi Research 、Grok Deep Search、Google Gemini Deep Research。
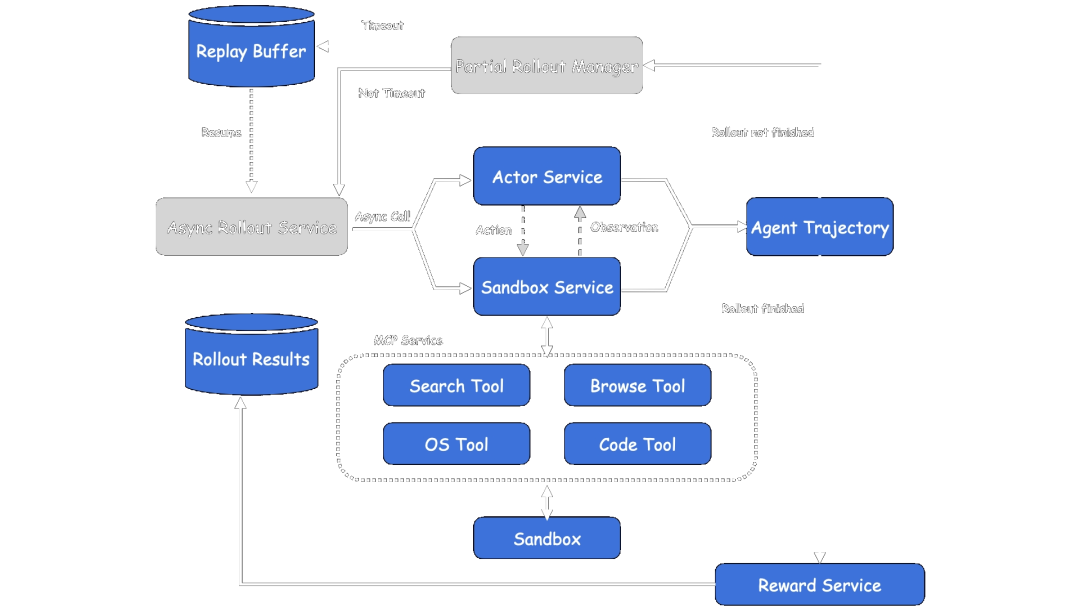
而独立的 Agent 公司,通常不会基于开源模型做端到端强化学习的模型训练路线,这并非他们的强项,而是选择基于现有的顶级前沿模型,尤其是擅长编码能力的 Claude 系列,做上下文工程(Context Engineering),基于 MCP 协议调用 tools use 能力,代表性公司就是 Manus、Genspark 等。
Manus 提出的 Agent 产品 Slogan 是“less structure more intelligence”,Genspark 提出的产品理念则是“Less Control,More Tools”,两者有异曲同工之处,都在强调让模型自主规划与执行,并且已经取得了行业领先的成果。

模型厂商与独立 Agent 厂商两种不同的路线究竟孰优孰劣?现在还尚无定论。
最新的趋势是,模型性能提升的幅度在 2025 年已经明显放缓,颠覆性的迭代更新越来越少,这给了独立 Agent 厂商发展的绝佳时间窗口。
上下文工程正在称为继 Model、Tool Use 之后的下一个 Agent 趋势,
大模型性能高度依赖上下文信息,传统“提示词工程(prompt engineering)”已无法满足复杂系统的需求,而上下文工程结合了用于设计、管理和优化上下文的技术,是在提示词工程基础上的更新与迭代。
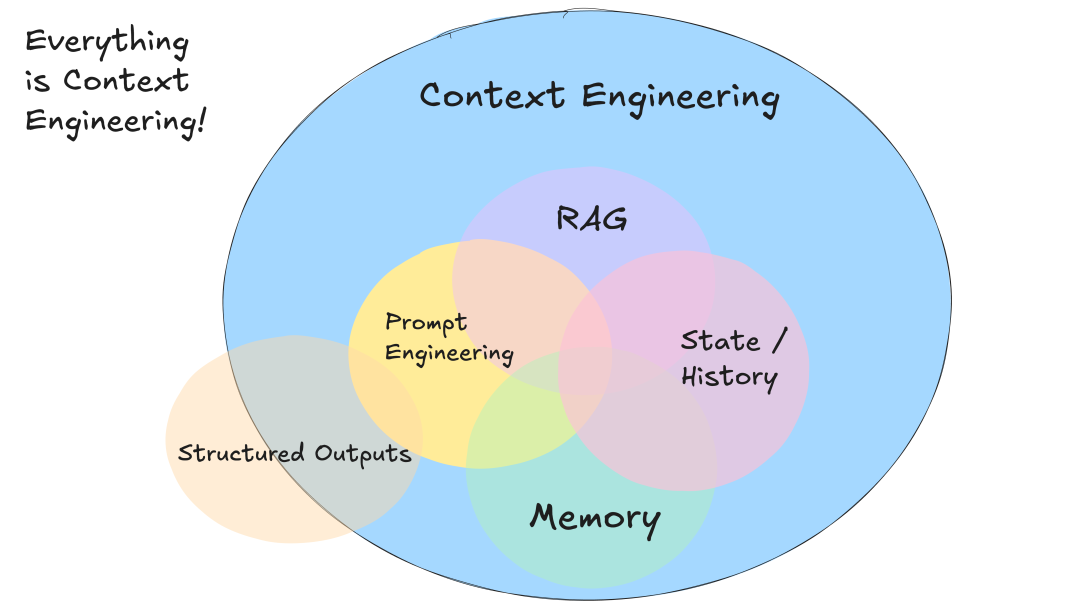
上下文工程不仅涵盖大语言模型,也涵盖了多模态模型以及工程优化的所有相关过程,包括:
- 提示词和指令
- 检索文档或外部数据(例如 RAG)
- 任何过去的状态、工具调用、结果或其他历史记录
- 任何来自相关但独立的历史/对话的过去信息或事件(记忆)
- 关于输出什么类型的结构化数据的说明
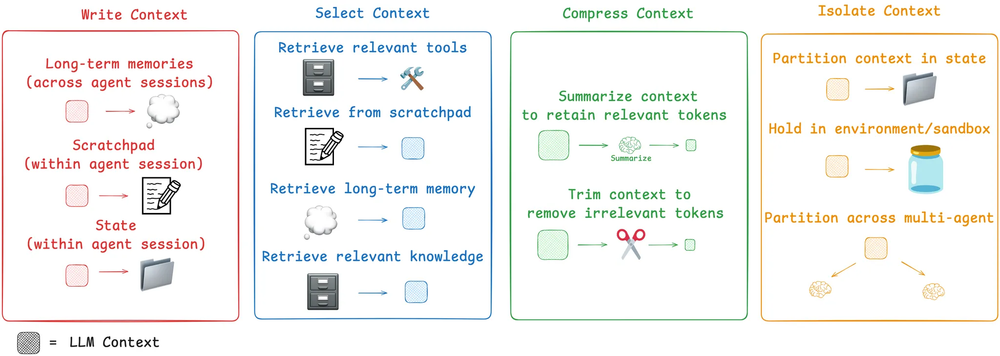
上下文工程是一门新兴科学。Langchain 发表的一篇博客中介绍了上下文工程的四种构建方式:写入上下文、筛选上下文、压缩上下文、隔离上下文。
Manus 曾分享过其上下文工程的实践,将其评价为构建智能体系统必不可少的路径。尽管模型本身可能会变得更强大、更快速、更经济,但再多的原始能力也无法替代对记忆、环境和反馈的需求。如何塑造上下文最终决定了智能体的行为方式,包括它运行的速度、恢复的效果以及扩展的范围。
PPIO 下一篇 AI 专栏,将详细梳理上下文工程的演进历程,包括 RAG、记忆系统、工具集成推理以及多智能体系统四大模块。
随着通用 Agent 产品的涌现与成熟,一个新的刚需开始显现:Agent runtime(运行时环境)。
在构建 Agent 框架的过程中,runtime 模块扮演着至关重要的角色,它不仅负责启动和管理 workflow / Agent 的生命周期,还处理任务调度、资源分配和状态监控等核心功能。
Sandbox(沙箱)是运行时环境的核心功能。它是一种隔离的执行环境,用来安全地运行模型生成的代码或操作。
为什么需要 Sandbox?因为 Agent 经常输出Python/JS/Shell 等代码、文件操作命令、API 调用指令、浏览器操作请求,这带来了代码安全风险,比如删除、覆盖文件、窃取本地信息、无限循环耗尽算力、访问敏感外部网站等。因此,Agent 必须在一个安全的隔离环境中运行,防止误操作或恶意行为破坏真实系统。
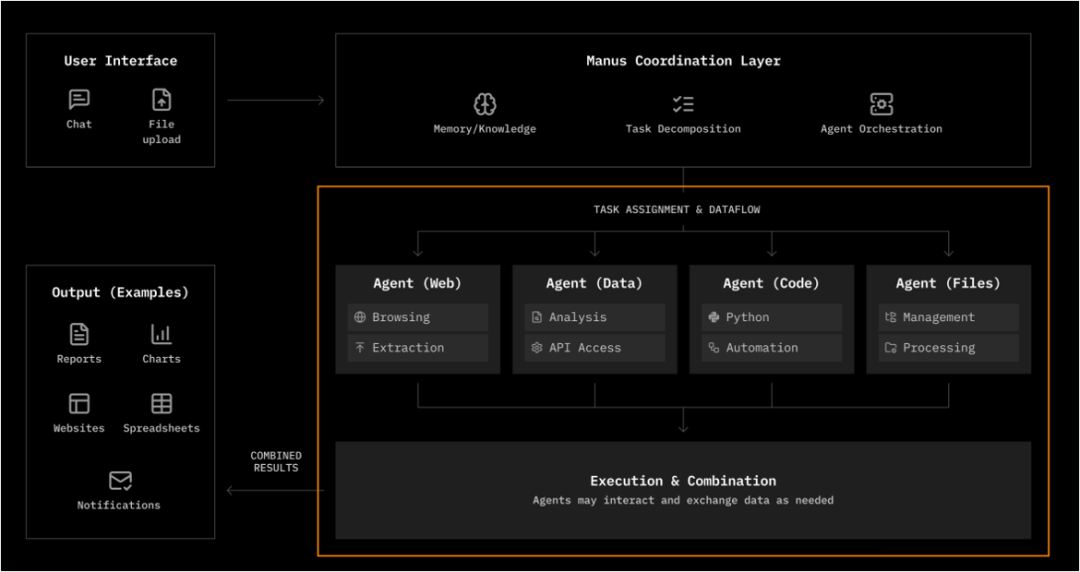
今天,Sandbox 已经大规模落地到生产实践中。在海外,ChatGPT Code Interpreter / ADA 里,Runtime 的“亮点功能”就是沙箱执行环境,Claude 的代码执行也是围绕安全沙箱来做的。
在国内,PPIO 推出了国内首款兼容 E2B 接口的 Agent 沙箱,并且提供更具性价比的价格。PPIO Agent 沙箱已接入开源的安全虚拟桌面项目 E2B Desktop (computer Use)和 AI 浏览器 Agent Browser-use,逐步构建完善的 Agentic AI 生态。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/246300.html