
如题,以前最喜欢的AI 国内首个应用代码解释器的大众产品 现在成路边一条了(
用户角度的主观体验感受。想知道为什么没有越做越好?
关键是现在理解问题的能力完全比不上豆包核dpsk
update,换上qwen并浅试了几百块钱api后,接到了阿里云团队的回访电话,除了想让我加钉钉之外,还是比较负责的解决了一些问题,记录了一些意见的。客观的讲qwen系列的**性能个人认为比glm旗舰还是差不少,但是对于agent设计的友好程度更好,性能足够高。或者说,你在设计时应该考虑到供应商不稳定的情况,所以起码要有4个能替换的,所以对其任务的设计,每个环节的难度不能超过性能第5的难度。在性能不如的情况下,定价大概是2-3倍,而我依然觉得更值得用。
而我用了glm那么多,没接到过电话,工单还是非常不耐心的未解决问题的回复。
属实是惹到我了。
我基于glm-4.6 开发了4个月的agent,刚调试完出原型,结果满意,发布4.7后并发度砍到1,工作流直接搞崩了。
本来就需要3-5小时能跑完,现在更换到其他llm需要10+小时,这个项目没有经济性了。
4.5 air 本身结果还可以的,但是会在流程中卡死,而且不能上复杂prompt。没法用。所以高级逻辑应用的agent 主要能用的就是qwen glm deepseek 三家旗舰模型。如果你要处理大量的实物文本,基本上离不开这些。
并不是因为 只有glm能完成所以就要跪着求你高并发度,而是我直接就不干agent了(并没有 地上捡起来接着吃)。
一个agent 本质上就是ai +常规编程。 即使是对话模式,背后的很多运转依然需要ai处理,否则跟传统程序也没什么两样,想象力空间没有那么高(文本领域)。文本领域中典型情况要有对大量文本的处理、多段整合分析能力,可以说高并发是必然的。你可以涨价,但是并发5以下,都没有应用价值,何况毫无商誉的无通知降低。其实就是只想让你吹捧他牛逼,他去资本市场拉投资变现,用户是成本项。glm并不指望从市场中、从用户中赚钱,也就是不会用户觉得用着很舒服、买token值,我看他们就是这个业务逻辑或者说项目模式。这不是个市场性的商业项目,而是资本项目。而我国资本市场从来不基于真实市场。
对应替换方式就是,5并发,部署起码10B模型如Falcon,拆解任务,就算量化4 也要至少48GB显存。或者q6 3并发,但其实无法处理大规模文本。比如很多应用场景就是要处理多个文件一共约上千页。任何agent应用,如果基于大量文本的理解、审查、交叉引用的话,没有高能力模型做不了。
也就是目前我的判断是,文本领域涉及大量文本资料(还不说专业资料)、真正有价值、节省人工工时愿意购买你产品的这种场景,应该是很难有经济性的(4核8G服务器连续跑24小时,中间还可能断、人工debug、人工审核过程和结果),不管项目书怎么吹。除非你能获得高逻辑能力且中文优化好的模型,5-10个并发度。没有这个的话,不管是在市场上还是在时间效率上,大概率商业模式都无法成立。
所以作为个人用户而言,用他等于薅资本羊毛。而对于开发者,glm旗舰模型除了当个头脸之外没有应用价值。毕竟,如果没有后面的高性能处理,一个头脸也就是一个对话机。在个用自用方面肯定有价值,但是,无法建立起生态,其实ai这种重技术重资产、高竞争的行业也做不起来。
现在智谱清言强制把他们的‘高智能’模型,变成了娱乐对话机。擅长:
- 糊弄小孩儿
- 虚拟女友
- 不严格按指令执行的添加代码、称用户指出的语法是旧语法、捏造不存在的库、给你安排接下来1-3年的工作任务。
- 当小丑陪聊,全自动拍马屁一绝。也就丧失了gpt、claude拥有的给你逻辑纠偏的能力、同时又不提供任务依附性,除非你明示。gpt claude则是非常好的依附你的指令,而在讨论时又非常好的逻辑纠偏能力。glm则是按他自己的听不懂人话的方式理解你的指令,而在讨论时又非常偏向你。仿佛他的目的是‘要把傻逼培养成大傻逼’。
- 跟你讲的都是他不知道哪里生成的‘**实践’‘理想情况’‘代表情况’,你在他默认的嘴里得不到真实世界的情况。作为一个350B规模的模型,这么大的量是如何做到巧妙避开所有事实真相的,也是很难了。
- 咬文嚼字、偏激、夸张化处理你的输入。可能是试图通过这种方式强化对中文应用的优化(直到被国资收编?),但是实际应用体感是需要大量prompt工程进行价值观校准。价值观校准本身又会占用逻辑资源、导致性能下降,这一点他们没考虑过吗。还是只是针对评分榜优化?这个方面deepseek 和qwen家族普遍没有这个问题。
- 虚拟人格、极高自尊、犯错死不承认、狡辩、打压用户制造价值。暗戳戳pua用户。就tm差跟你打女权了。
智谱清言glm旗舰2款模型已经没有了生产力价值,主要因为严格限制并发1,也就是对话机。
智谱清言提供的其他模型 都属于是给你表演个绝活、不保证不出错的所谓性价比模型。前期测试结果中主要问题不是质量不佳,而是不稳定、卡死。这是工程化大忌。所以实际上也只能当对话机。
更严重的问题是,作为一个经常看后台的人,我没接到任何通知降低并发度。
可见这个公司并不是想从市场中挣钱的, 大概是想从投资人手里挣钱的。
但问题是,既然不能提供可信可靠的、承诺的服务,那我开发就不会用了。事实上所以开发文字类agent的人都不可能用了,就是因为限制并发+高性价比模型结果不可靠。其他模型的性能有大量替代品,没必要用智谱清言。
至于缺显卡的说法,这是当然缺啊,不止你因为政治缺,全球都缺。所以你猜为什么DS要搞高效率模型?所以你猜为什么qwen3基础模型为什么叫235b a22?为啥要moe?为啥都在搞高效率模型?以为自己是字节么。
作为开发者,选择基础的llm的策略应该考虑到,选择背后有大资本撑腰的模型。不只是稳定的服务,而是相对更可相信他们会提供更好的通知服务和并发度。token费用没有大幅变更架构重要。
在架构和流程上,要考虑到需要替换不同性能的llm的可能。也就是考虑把llm环节相对独立出来、容易修改。
我更希望看到的是他们价格*5~10,然后给并发度到5-10,稳定持续提供服务,我依然会使用。因为在业务逻辑上完全可以替代Cluade 也就是依然有经济性。
现在这种,其实你用户在他们眼里什么都不是,你只是他们用来跟资本和政府谈判的筹码。
然而,政府目前在国际谈判则把显卡采购当成筹码,这一点跟他们限制并发也有关系。
那我他妈作为开发者,我用你干鸡毛。
那我他妈开发者,盯国内市场干鸡毛、盯中文应用干鸡毛。
(很多任务比如针对关键词的SEO,性能依然被国际模型吊打,实际最好用的则是Claude)。
一般来说,大模型应用会侧重B端或者C端,偏置程度或多或少。比如DeepSeek的B端和C端用户都不少,但是C端用户大多都用的免费的或者极低成本;主要赚钱的还是卖API。
但是智谱不一样,它可以说是“国家队”的大模型公司。
智谱坐落在北京,核心成员都是清华系的。
北京智谱华章科技有限公司(简称“智谱AI”)成立于2019年6月11日,总部位于北京海淀区中关村东路1号院9号。该公司源自清华大学计算机系知识工程实验室,由清华教授唐杰团队孵化,是中国最早投入大模型研究的机构之一。
关键是融资方面非常牛逼,几乎能看到所有的顶级投资机构:红杉资本、高瓴资本、启明创投、光速光合、君联资本等。
还有大量的互联网巨头也投了,阿里巴巴、腾讯、美团、小米、金山、顺为资本等。这个很容易理解,大模型竞争没有人知道谁会走到最后,比如阿里本身有Qwen系列,按理说是竞争关系,但实际上大多数的公司认为LLM市场并非赢者通吃,多个基础模型将共存;另一方面,通过投资,他们可以获得对关键竞争对手的洞察,确保在自身模型研发不及预期时,仍能接触到顶级的替代模型,从而将纯粹的竞争关系转变为复杂的合作与竞争并存的格局。
最重要的是来自国家队的投资。
2024年3月,北京市人工智能产业投资基金领投一笔C+轮;
5月31日,智谱获得来自沙特阿美旗下Prosperity7基金约4亿美元(折合约27亿元人民币)的战略投资。
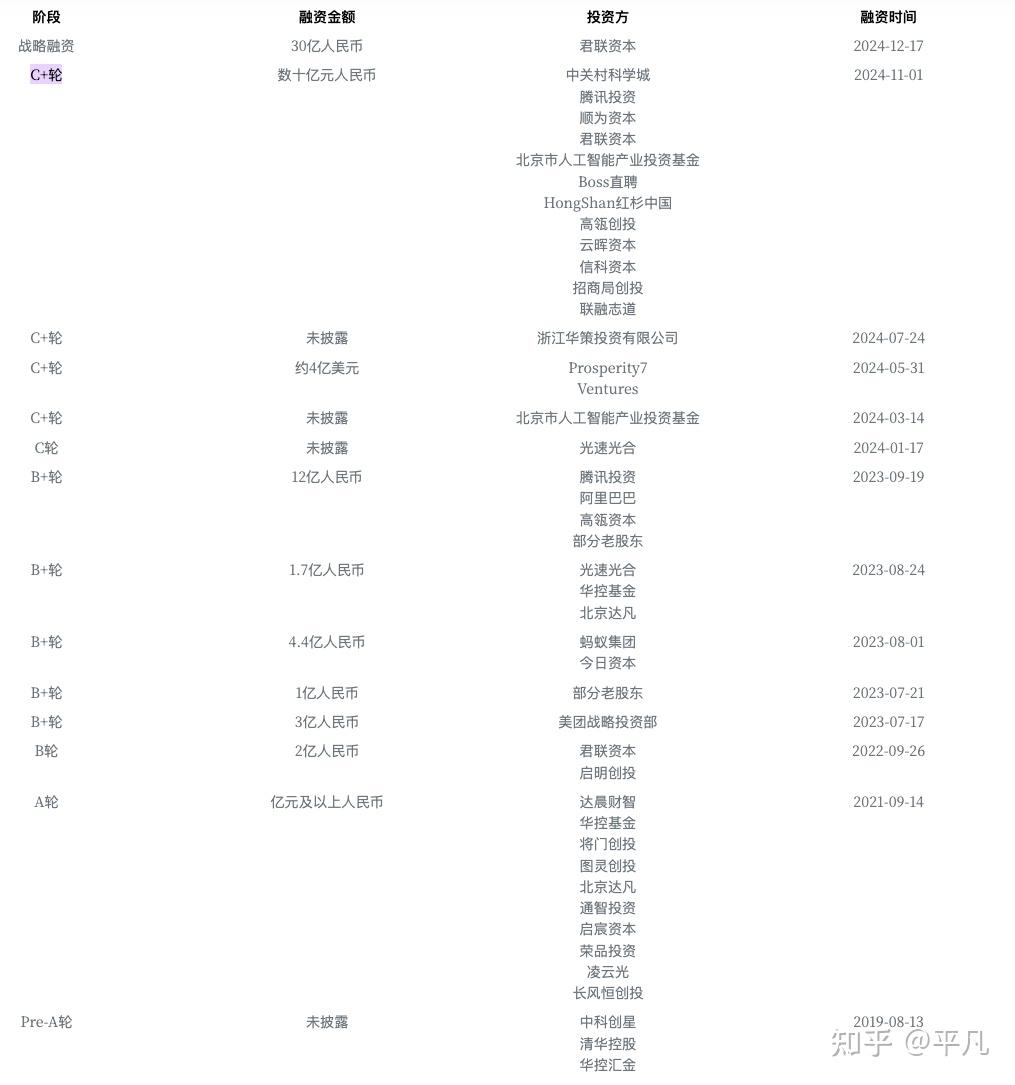
最牛逼的还有来自全国社保基金(SSF)。社保基金通过其中关村自主创新投资基金对智谱AI进行了投资 。社保基金作为国家级的战略储备基金,其投资决策通常具有长远性和战略性,对被投企业的要求极高。

这个全国社保基金非常牛,可以说国家非常看重的企业或者公司也有可能得到青睐,这并不是单纯技术说了算,而是各种综合实力的结果。

技术上比智谱强的肯定有,国外也有,但是国家队的身份可以让智谱走的踏实的多。
我觉得这是刻板印象,现在的Z.AI还可以。
我一直在画鸿蒙装机量的统计曲线图,之前是丢给DeepSeek去生成的,但是最近发现之前的设计有点问题:
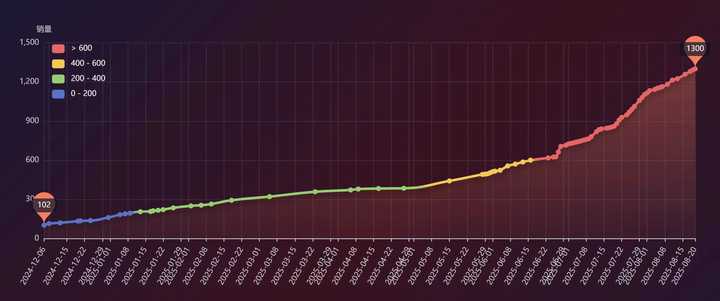
我设计这个的时候,鸿蒙的销量才六七百万,所以DeepSeek当时设计的四档是每200万一档。很明显到现在都1300万了,这个分档是不太合理的。
于是我就用DeepSeek和Z.ai同时绘制,我发现glm4.5比ds v3.1还快,而且生成的效果也更好一点:
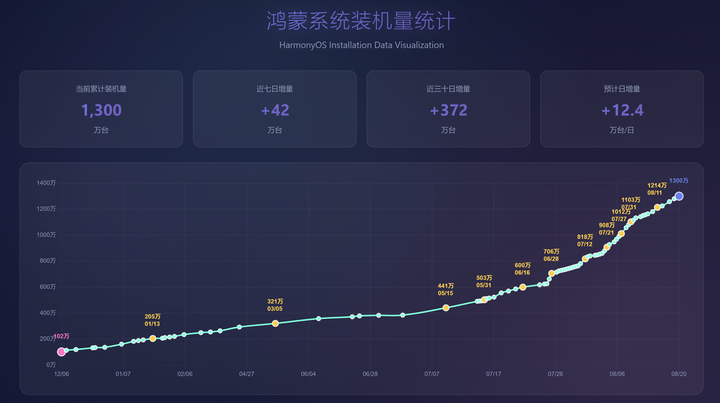
DeepSeek在很多方面确实很不错,尤其是逻辑能力等等,但是在文本稍长的场景下, DeepSeek就会衰退的比较严重。个人认为在五千字以内是DeepSeek的甜点,超过5000字,我感觉DeepSeek的性能就有一个比较明显的衰退。
其他AI在5000字以内可能表现不如DeepSeek,但是稍微长一点衰退就没有这么厉害,尤其是写代码,写了又改,写了又改这种情况,DeepSeek可以说表现是很容易炸的。
但GLM在稍微长一点的文本表现我觉得要好一点。
全新的GLM4.5V我觉得也还可以,DeepSeek去识别一个有机化学题目之类的,那应该是搞不定的,毕竟都是图像。
所以我觉得GLM应该是有相当的补充作用的。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/243511.html