

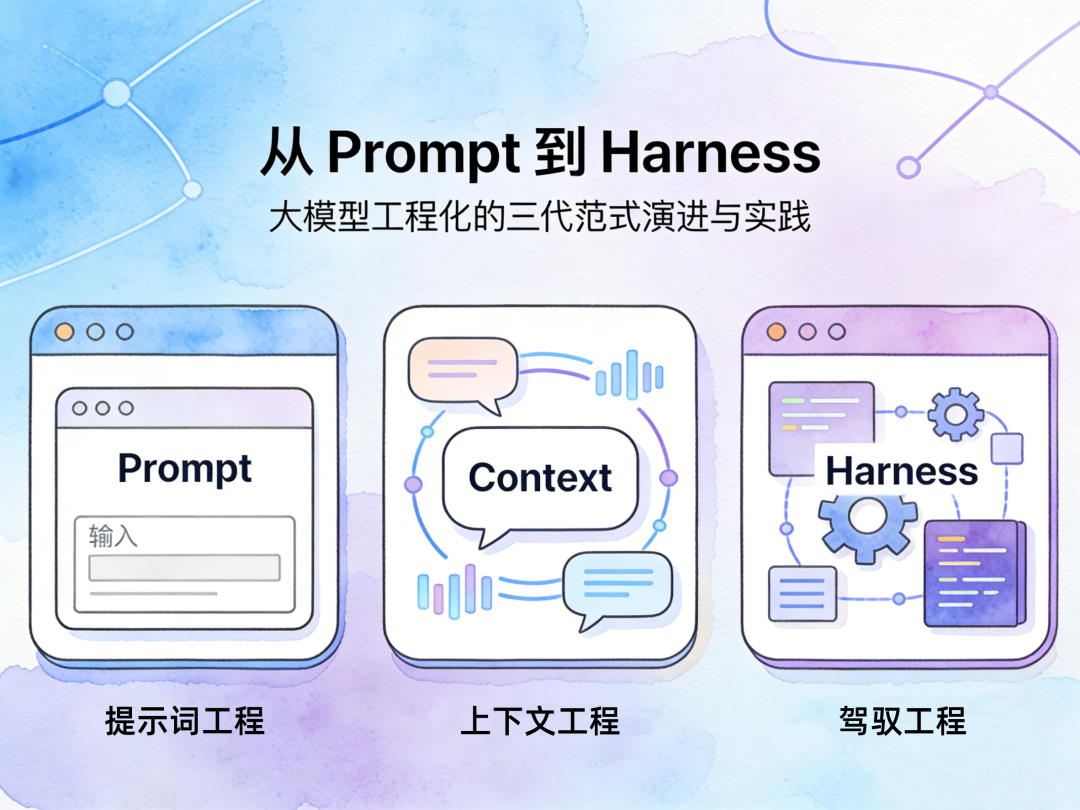
生成式AI发展至今,大模型的基础推理能力早已实现跨越式突破,行业的核心矛盾也已从“模型够不够聪明”,转变为“如何让大模型的能力稳定、可控、合规地落地到真实生产场景”。从最初的对话机器人,到如今的企业级业务自动化、AI智能体规模化落地,行业用三年时间完成了三次认知升级,逐步形成了三套层层递进、互为补充的工程化范式:Prompt Engineering(提示词工程)、Context Engineering(上下文工程)、Harness Engineering(驾驭工程,国内权威译法,也译作管控工程)。
这三套范式并非相互替代,更不存在“前者完全过时”的绝对判断——Prompt与Context依然是整个工程化体系的核心基石,而Harness Engineering则是行业对“如何让AI可靠工作”的认知升维,它将前两者纳入了一套可进化、全链路、生产级的完整管控体系中。2026年开年,Harness Engineering从一线工程实践中完成理论化命名,迅速成为全球开发者社区的核心共识,也标志着大模型工程化从单点优化,正式进入体系化环境设计的全新时代。
一、核心共识与基础术语
在正式拆解三套范式之前,我们先明确贯穿全文的核心共识,同时对全文高频出现的专业术语做统一通俗注释,消除阅读障碍,确保专业表述无歧义、无错误。
1. 核心共识
- 大模型的本质是基于上下文的概率生成引擎:它的所有输出,都由输入的上下文、预设的规则、训练形成的世界模型共同决定。工程化的核心,就是通过标准化的方法,引导、约束、管控模型的生成过程,让概率性的模型输出,转化为确定性的生产结果。
- 三套范式是层层递进的互补关系,而非替代关系:Prompt Engineering是所有工程化的基础,Context Engineering是场景落地的核心支撑,Harness Engineering是生产级规模化落地的完整框架。三者是认知边界的持续扩展——从“写好一条指令”,到“管好信息输入”,再到“设计一整套运行体系”,不存在非此即彼的优劣判断。
- 演进的底层逻辑,是大模型从“玩具”到“生产力工具”的必然要求:从单轮对话的简单问答,到垂直场景的专业任务,再到企业级全流程业务自动化,场景越复杂,对模型的确定性、可控性、合规性要求越高,对应的工程化体系也需要从单点优化,走向全链路管控。
- 基础术语

二、Prompt Engineering:大模型工程化的起点,人与模型的认知对齐桥梁
1. 核心定义与通俗解释
Prompt Engineering(提示词工程),是一套通过标准化的文本设计,引导大模型按照预期的规则、逻辑、格式输出结果的工程化方法,是人与大模型对齐认知的核心桥梁,也是所有大模型工程化体系的基础单元。
用最通俗的日常类比来说,它就像你给外卖骑手写的配送指令。你只说“把餐送到我这”,骑手可能找不到具体地址、不知道能不能放快递柜;但如果你明确写清楚“XX小区3号楼2单元,放门口丰巢快递柜,放好后拍照发我,不要打电话”,骑手就能精准完成你要的结果。这段明确的指令,就是最基础的Prompt;而怎么把需求写得清晰、精准、可执行,让接收方完全理解不跑偏,就是Prompt Engineering的核心工作。
2. 核心方法论与发展历程
Prompt Engineering是随着大模型的诞生同步兴起的,是大模型工程化的起点,其发展历程完全贴合大模型能力的迭代与行业认知的升级。
第一阶段:原生探索期(2020年-2022年,GPT-3到GPT-3.5时代)
这一阶段的大模型能力较弱,未经过专门的指令微调,对模糊指令的理解能力极差,Prompt Engineering的核心目标是“让模型能理解并完成基础任务”。
- 核心方法论:零样本提示(Zero-shot)、少样本提示(Few-shot)。核心逻辑是给模型展示1-5个“输入什么、应该输出什么”的现成示例,让模型参照示例的逻辑完成任务,弥补其指令理解能力的不足。
- 典型场景:简单的文本分类、翻译、摘要,核心是通过示例给模型建立明确的输入输出范式。
第二阶段:体系化成型期(2022年底-2023年中,ChatGPT爆火时代)
随着ChatGPT的爆火,大模型的指令理解能力大幅提升,行业开始系统性总结Prompt设计的通用规则,Prompt Engineering正式成为一套独立的工程化体系,也迎来了它的全盛期。
- 核心方法论:角色设定、任务拆解、规则约束、格式限定,形成了“角色定位+任务目标+执行规则+输出要求+示例参考”的经典五段式Prompt框架,至今仍是行业最通用的Prompt设计方法。
- 里程碑突破:谷歌团队提出的思维链(Chain-of-Thought, CoT),通过让模型“先拆解思考过程、再输出最终答案”,让大模型的复杂逻辑推理能力提升40%以上,解决了大模型数学计算、逻辑推理能力弱的核心痛点,也让Prompt Engineering从“凭经验的玄学”走向了有明确方法论的科学体系。
第三阶段:自动化优化期(2023年中-2024年)
随着大模型在企业场景的落地,人工编写Prompt的痛点逐渐暴露:效率低、高度依赖个人经验、不同人编写的效果差异大、难以在企业内规模化复用,Prompt Engineering开始走向自动化、可量化优化。
- 核心方法论:自动提示工程(APE)、基于模型反馈的Prompt迭代、提示词模板化与版本管理。核心逻辑是让大模型自主优化Prompt,通过A/B测试量化不同Prompt的效果,再把通用Prompt做成可复用的模板,实现企业内的统一落地。
- 典型应用:开源框架DSPy首次提出“把Prompt从手写文本变成可优化的程序模块”,通过算法自动迭代优化Prompt;LangChain推出PromptTemplate,实现了提示词的标准化、参数化复用。
第四阶段:多模态与场景化融合期(2024年-2025年)
随着GPT-4o、Claude 3系列多模态大模型的爆发,大模型的能力从纯文本处理,扩展到了图像、视频、音频的理解与生成,Prompt Engineering也从纯文本场景,扩展到了多模态场景,同时开始与金融、医疗、政务等垂直行业深度绑定。
- 核心方法论:多模态Prompt设计、场景化Prompt模板库、行业专属Prompt规范、多轮对话的动态Prompt迭代。针对不同垂直行业,形成了标准化的行业Prompt模板库,解决了通用Prompt在专业场景准确率不足的问题。
- 里程碑进展:国内外主流大模型厂商均发布了行业专属Prompt规范,国内银行、证券、政务机构开始搭建企业级Prompt管理平台,实现了Prompt的权限管控、版本迭代、效果量化。
第五阶段:体系化融合期(2025年-2026年3月,当前最新阶段)
当前的Prompt Engineering,已经不再是孤立的“写提示词”,而是与Context Engineering、Harness Engineering深度融合,成为Agent Skills开放标准、Harness体系的核心组成单元,实现了标准化封装、规模化复用、全链路管控。
- 核心方法论:标准化Skill级Prompt封装、多智能体协同的指令分发、动态Prompt生成引擎、合规性前置校验、与业务流程绑定的Prompt生命周期管理。Prompt不再是静态的文本,而是根据场景、上下文、用户需求、合规规则动态生成的标准化指令单元,同时被封装到Skill与Harness体系中,实现跨平台复用与全链路管控。
- 最新行业进展:OpenClaw 3.12稳定版与Claude Code的Skill体系,将Prompt作为Skill与Harness单元的核心组成部分,通过标准化的Prompt定义,明确技能的触发场景、执行规则、输出要求,实现了提示词的标准化封装与跨平台复用;基于强化学习的Prompt自动优化技术已实现商用,可根据业务反馈、用户评分自动迭代优化Prompt,无需人工干预,准确率较人工编写提升30%以上;国产模型厂商均发布了官方Prompt设计规范与可视化Prompt开发工具,覆盖政务、金融、制造、教育等诸多垂直行业。
3. 核心价值与能力边界
Prompt Engineering的核心价值,是用最低的成本,对齐人类与大模型的认知,引导模型输出符合预期的结果。它不需要修改模型、不需要额外的开发,就能大幅提升大模型输出的准确性、相关性、规范性,是所有大模型应用的基础。
但它也有明确的、经行业实践验证的能力边界,这也是行业认知向Context Engineering升级的核心原因:
- 它只能优化单次输出的规则,无法承载大量的动态信息与私有知识。例如需要基于企业10年的财务数据做分析,仅靠Prompt无法承载海量信息,也无法实现数据的实时更新;
- 它依赖静态的规则,面对复杂的多轮对话、多步骤任务、多工具协同场景,静态的Prompt无法实现全流程的管控与迭代。例如让模型完成完整的产品开发全流程,仅靠一条静态指令无法应对过程中的各类变量;
- 它只能引导模型的输出,无法阻止模型“做不该做的事”,也无法改变大模型概率性生成的本质。仅靠Prompt无法实现100%的输出确定性,也无法满足企业级场景的合规审计、风险管控、容错回滚需求。
三、Context Engineering:大模型场景落地的核心,给模型划定信息边界
1. 核心定义与通俗解释
Context Engineering(上下文工程),是一套围绕大模型的上下文窗口,实现信息的生成、筛选、注入、优化、管理、回收全生命周期的工程化方法,核心解决大模型的知识边界、幻觉、场景适配、长流程信息留存的核心痛点,是大模型从通用能力走向垂直场景落地的必经之路。
继续用通俗的日常类比来说,如果Prompt Engineering是给外卖骑手写配送指令,那Context Engineering就是给骑手配齐完成配送需要的所有信息:小区的精准地图、门禁密码、用户的特殊收货习惯、实时路况、小区的快递柜分布、不能配送的禁区清单。大模型就像骑手,哪怕指令再清晰,没有这些配套信息,要么找不到路、要么踩了禁区、要么只能编造虚假结果(幻觉)。而Context Engineering,就是在正确的时间,把正确的信息,以正确的方式给到模型,让它始终在准确的信息边界内完成工作,不瞎编、不跑偏、不遗忘关键信息。
2. 核心方法论与发展历程
Context Engineering的发展,始终围绕让模型拿到的信息更准、更高效,其发展历程与大模型上下文窗口的扩展、企业级落地的需求深度绑定,也完全贴合行业认知的升级。
第一阶段:基础填充期(2022年-2023年初)
这一阶段的Context Engineering,是Prompt Engineering的附属部分,核心是简单的信息填充,把完成任务需要的基础信息、示例、历史对话,直接拼接到Prompt中,一起输入给模型。
- 核心方法论:固定上下文模板、对话历史拼接、基础信息填充。
- 核心局限:只能处理少量的静态信息,无法应对海量的私有数据,也无法解决长对话中模型遗忘关键信息的问题。
第二阶段:体系化爆发期(2023年中-2023年底,RAG技术爆发)
随着大模型在企业级场景的落地,“如何让模型用上企业的私有数据”成为核心痛点,RAG(检索增强生成) 技术快速爆发,成为Context Engineering的核心支柱,Context Engineering也正式成为一套独立的工程化体系。
- 核心方法论:RAG全流程工程化,包括文档分块、向量嵌入、向量存储、相似度检索、结果重排、上下文拼接的完整链路。核心逻辑是:用户提问后,先从企业私有知识库中检索出和问题最相关的内容,再把这些内容和用户问题一起输入给模型,让模型基于准确的私有数据回答问题,从根源上解决幻觉与知识盲区问题。
- 里程碑突破:行业形成了“基础RAG→高级RAG→模块化RAG”的标准演进路径,出现了多级检索、混合检索(向量+关键词+知识图谱)、多轮重排、元数据过滤等成熟的方法论,大幅提升了检索的准确率。
第三阶段:精细化管理期(2024年)
随着Claude 3、GPT-4o、Llama 3等大模型的上下文窗口突破128K、甚至200万Token,大模型的“记忆容量”大幅提升,Context Engineering的核心也从“让模型拿到更多信息”,变成了“让模型拿到更精准的信息,更高效地利用上下文窗口”。
- 核心方法论:上下文压缩、动态窗口管理、长对话记忆分层、多模态上下文处理、上下文生命周期管理。
- 核心突破:行业解决了长上下文的“Lost in the Middle(迷失在中间)”问题——如同人阅读长文章容易遗忘中间的关键内容,模型也存在相同的问题。行业通过注意力优化、关键信息置顶/置底、上下文权重分配,让模型能精准捕捉长上下文中的关键信息;同时,形成了“短期记忆+长期记忆+工作记忆”的分层记忆管理体系,成为AI Agent的核心记忆模块。
第四阶段:行业认知确立期(2025年中)
2025年6月,OpenAI联合创始人Andrej Karpathy公开发声:“相比Prompt Engineering,我更推崇Context Engineering,这是一门精微的艺术与科学,用恰到好处的信息填充上下文窗口,以服务于下一步操作”。随后Shopify CEO Tobi Lutke、知名技术博主Simon Willison纷纷跟进,Context Engineering正式成为行业公认的核心工程化范式,完成了从Prompt附属部分到独立体系的认知跃迁。
- 核心转变:Context Engineering的焦点从“给模型塞更多信息”,扩展到了“设计一个动态系统来组装上下文”。RAG、对话历史、工具输出、系统指令的编排,都被纳入了Context Engineering的体系中。
- 核心局限暴露:一线实践者很快发现,即便有了完善的上下文管理,Agent依然会失控。一方面,上下文窗口的扩大,并不等于Agent性能的线性提升,即便模型支持百万Token上下文,性能衰减在25.6万Token左右便已出现;另一方面,上下文只能告诉Agent“知道什么”,却无法阻止Agent“做不该做的事”,行业甚至出现了无人监控的Agent陷入无限循环。
第五阶段:标准化与全链路融合期(2025年-2026年3月,当前最新阶段)
当前的Context Engineering,已经和Harness Engineering深度融合,从“单纯的信息检索与注入”,变成了Harness体系的核心维度之一,同时形成了全球统一的技术标准与国产化完整生态。
- 核心方法论:标准化Skill级上下文隔离与复用、渐进式披露(Progressive Disclosure)、多智能体协同的上下文共享、合规性上下文过滤、与业务流程绑定的上下文生命周期管理、跨工具/跨系统的实时上下文同步、RAG 3.0(检索与生成深度融合)。
3. 业界**实践
实践1:渐进式上下文披露(OpenAI官方标准实践)
这是OpenAI在Harness Engineering官方实验中验证的、当前行业最核心的上下文工程**实践,彻底解决了“信息过载导致模型性能下降”的核心痛点。
- 通俗解释:如同人入职不会第一天就读完公司所有规章制度,而是需要时再查阅对应手册,渐进式披露不给模型一次性塞入所有信息,而是搭建“总目录+分册手册”的结构,让模型按需、逐级读取对应场景的信息。
- 落地细节:OpenAI把原本几万行的全量规则文档,拆解为100行左右的精简AGENTS.md目录文件,再拆分出架构规范、设计原则、安全规则、质量标准等独立的结构化文档,模型仅在执行对应任务时读取对应的文档内容,单份文档大小默认不超过32KiB。
- 落地效果与行业验证:模型的信息读取准确率提升40%以上,彻底解决了长上下文的性能衰减问题,这一实践已成为全球企业级Agent落地的标准做法。
实践2:分层记忆管理体系(行业通用**实践)
这是解决长对话、长流程任务中“模型遗忘关键信息”的核心实践,也是所有主流Agent框架的标配能力。
- 通俗解释:如同人类的记忆体系,把信息分为“正在想的事(工作记忆)、刚发生的事(短期记忆)、需要长期记住的事(长期记忆)”,给模型的记忆也做分层管理,不同层级的信息采用不同的处理方式。
- 落地细节:工作记忆,当前正在执行的任务的核心信息、上下文,放在上下文窗口的最前端,确保模型不会遗忘;短期记忆,最近10-20轮的对话历史、工具调用结果,做轻量化的摘要留存,避免上下文窗口过度膨胀;长期记忆,企业私有知识库、用户历史偏好、过往任务的关键结论,通过RAG技术按需检索,仅在需要时注入上下文。
- 行业验证:OpenClaw、Claude Code、LangChain等所有主流Agent框架,均已内置这套分层记忆体系;国内的百度千帆、阿里云百炼等平台,也基于这套体系完成了中文场景的专项优化。
实践3:混合检索RAG 3.0架构(企业级落地标准实践)
这是当前企业级私有知识库落地的最优架构,解决了传统RAG检索准确率不足、无法适配复杂数据类型的问题。
- 通俗解释:传统RAG如同只用关键词搜搜索引擎,经常搜不到想要的内容;而混合检索RAG 3.0,如同同时用关键词、语义、标签、知识图谱等多种方式搜索,再把结果综合排序,确保能找到最精准的信息。
- 落地细节:多路径检索,同时执行向量语义检索、关键词检索、知识图谱检索、元数据过滤,覆盖不同的检索场景;多轮重排,先用大模型对检索结果做初筛,再用重排模型做精准排序,仅把最相关的3-5条内容注入上下文;多模态检索,支持图片、音频、视频、结构化表格的统一检索与内容注入,适配多模态大模型的需求。
- 行业落地案例:国内六大国有银行、头部券商的智能客服、智能投研系统,均基于这套RAG 3.0架构搭建,检索准确率较传统RAG提升50%以上,幻觉率下降80%以上;国际上,Stripe、Shopify的企业级Agent系统,也均采用这套架构。
实践4:实时上下文同步与MCP协议集成(实时数据获取实践)
这是行业最新的上下文工程实践,解决了大模型无法获取实时业务数据、无法安全访问外部系统的核心痛点。
- 通俗解释:传统的上下文工程,只能给模型注入静态的知识库内容,如同给骑手一本去年的地图;而实时上下文同步,就是给骑手装了一个实时导航,能同步最新的路况、订单信息、门禁密码变化,MCP协议就是这个实时导航的通用数据线。
- 落地细节:通过MCP协议,打通大模型Agent与企业数据库、业务系统、SaaS工具、第三方API的实时连接,Agent在执行任务时,能实时获取最新的业务数据、系统状态、工具返回结果,并把这些内容动态注入上下文,确保模型始终基于最新的信息执行任务。
- 行业落地案例:Stripe的Minions Agent体系,通过中心化的MCP服务器Toolshed,托管了近500个内部与外部工具,实现了Agent的实时上下文同步,每周完成1300+个AI编写的代码PR合并;国内的字节火山方舟、腾讯云智能钛平台,也已内置MCP协议的完整支持,成为国内企业级Agent落地的标准配置。
实践5:分级权限与合规上下文管控(金融政务行业**实践)
这是强监管行业落地上下文工程的必备实践,解决了“不同用户能访问的信息不同,模型不能越权泄露数据”的合规问题。
- 通俗解释:如同企业中,普通员工只能查看本部门资料,经理能查看全公司业务数据,高管能查看核心财务数据,分级权限管控就是给上下文也做权限分级,不同用户提问时,模型只能检索和注入对应用户权限范围内的信息。
- •落地细节:在文档入库时给每份文档、每个字段打上权限标签,用户提问时,先校验用户的权限范围,再在对应的权限范围内做检索和上下文注入,同时完成敏感信息脱敏、操作日志留痕,确保所有上下文的注入都可审计、可追溯。
- •行业落地案例:国内政务系统的智能问答平台、银行的智能柜员系统,均基于这套实践搭建,满足等保三级、《数据安全法》的合规要求;国际上,摩根大通、高盛的内部AI系统,也采用了这套分级上下文管控体系。
实践6:上下文压缩与降噪优化(长上下文场景核心实践)
这是超长上下文场景下的必备实践,解决了“上下文里无效信息太多,模型抓不住重点”的核心问题。
- 通俗解释:如同给别人讲一件事,不会把所有细节都啰嗦一遍,只会提炼核心重点,上下文压缩就是把检索到的大量内容、工具返回的冗长结果,先做摘要、提炼、降噪,只把核心关键信息注入上下文,既节省Token消耗,又能提升模型的准确率。
- 落地细节:通过大模型、专用压缩模型,对检索结果、工具输出、对话历史做精准摘要,过滤掉无效、重复、低相关的内容,只保留和当前任务强相关的核心信息,同时完整保留关键的数字、规则、约束条件。
- 落地效果与行业验证:在100万Token以上的超长上下文场景中,上下文压缩能让模型的关键信息捕捉准确率提升60%以上,同时降低70%的Token消耗,是当前超长上下文模型落地的标配优化手段。
4. 核心价值与能力边界
Context Engineering的核心价值,是打破了大模型的知识边界与记忆限制,让大模型能基于准确的、实时的、私有的信息完成任务,从“通用聊天机器人”变成了能适配垂直场景的专业工具,是大模型从通用能力走向行业落地的必经之路。
但它同样有明确的、经行业实践验证的能力边界,这也是行业认知向Harness Engineering升级的核心原因:
- 它解决了“基于什么信息做”的问题,但没有解决“复杂流程怎么管控、多工具怎么协同、风险怎么控制”的问题。例如让模型完成企业月度财务结账全流程,仅靠上下文管理,无法管控每一步的审批流程、风险拦截、异常处理,也无法实现多系统、多工具的协同;
- 它只能优化模型的输入信息,无法改变大模型概率性生成的本质,无法实现端到端的合规审计、容错回滚、性能管控,也无法阻止Agent的错误行为、无限循环等失控问题;
- 它无法解决系统随时间腐化的问题:随着代码库、业务规则的持续迭代,上下文文档、规则体系会出现内容漂移、前后矛盾、规则过时的问题,仅靠Context Engineering无法实现体系的自净与长期稳定;
- 它是单点的能力优化,无法实现大模型应用的标准化、规模化复用与运维,面对企业级多场景、多智能体、多模型的复杂架构,需要一套更完整的全链路管控体系。
而这套体系,就是Harness Engineering。
四、Harness Engineering:大模型生产级落地的全链路体系,为Agent设计可靠的运行环境
1. 核心定义与通俗解释
Harness Engineering(驾驭工程,国内权威译法,也译作管控工程),是2026年2月由HashiCorp联合创始人Mitchell Hashimoto正式命名、OpenAI官方实验报告验证、行业快速达成共识的新一代工程化范式。它是围绕大模型Agent生产级落地,构建的一套覆盖端到端全流程的标准化管控体系,将Prompt、Context、工具调用、模型调度、安全管控、流程编排、观测审计、容错回滚、系统自净等所有环节,封装成可复用、可管控、可观测、可进化的标准化运行环境,让大模型的能力从“实验室可用”变成“生产级可靠”。
Harness的本意是“马具、缰绳”,延伸义为“驾驭、管控、利用”,在软件工程语境中,Test Harness指的是标准化的测试框架,用于管控测试的全流程;而在大模型领域,Harness Engineering的核心,就是“通过工程化手段驾驭大模型的不确定性,给Agent搭建一整套标准化的生产流水线和完整的管理体系”。
用通俗例子进行类比,把三个工程的分工清晰区分。如果把AI Agent比作开车的司机,那么:
- Prompt Engineering,是你给司机的导航指令,明确「要去哪里、走哪条路、中途要停哪些点、最终要达成什么目标」;
- Context Engineering,是给司机配齐的路况地图、实时交通信息、交通规则手册、车辆操作指南、沿途禁区清单,让他「知道路上的所有信息和规则,不会迷路、不会违规」;
- Harness Engineering(驾驭工程),则是一整套完整的车辆管控体系和交通管理体系——包括汽车本身的刹车、安全带、安全气囊、行车电脑、ABS防抱死系统,还有道路上的红绿灯、限速标志、违章抓拍、应急车道,以及全程的行车记录仪。它能确保司机不管开什么路,都能在合规、可控、安全的框架内行驶,不会超速、不会闯红灯、不会出事故,哪怕出了小问题也能自动修正,甚至能从过往的事故中优化整个管控体系,让同类问题永远不再发生。
Mitchell Hashimoto在命名这一范式的源头博客中,给出了最核心的设计哲学:每当你发现Agent犯了一个错误,你就花时间设计一个解决方案,使Agent永远不再犯同样的错误。这也是Harness Engineering区别于前两代范式的核心——它不是单次的优化,而是一套可积累、可进化、能持续收敛错误的闭环体系。
2. 核心方法论与发展历程
Harness Engineering是大模型走向企业级规模化落地的必然产物,它的底层实践早已在一线团队中探索,直到2026年2月完成正式命名与理论化,迅速成为行业共识。截至2026年3月,其发展历程可分为四个清晰、可验证的阶段:
第一阶段:流程编排萌芽期(2023年中-2023年底)
随着大模型开始用于复杂的多步骤任务,行业发现单纯的Prompt和Context,无法管控多轮、多工具的执行流程,开始出现了最早的流程编排工具,这是Harness Engineering的雏形。
- 核心方法论:链式流程编排、简单的条件分支、工具调用封装。核心是把一个复杂的任务,拆分成多个步骤,让模型按顺序执行,每个步骤都有独立的Prompt和Context规则。
- 典型产品:LangChain的Sequential Chain、Transformation Chain,实现了最简单的流程编排;AutoGPT、BabyAGI等早期Agent框架,实现了任务拆解、执行、反思的闭环管控。
第二阶段:体系化成型期(2024年)
随着企业级场景对大模型的稳定性、合规性、可观测性要求越来越高,行业开始系统性地构建全链路的管控体系,Harness Engineering的核心实践已经成型,只是尚未完成统一命名。
- 核心方法论:DAG/状态机流程编排、全链路安全管控、可观测与审计、容错与回滚、多模型调度。
- 里程碑突破:微软推出的Prompt Flow,是首个完整的Harness Engineering产品化实现,提供了可视化的流程编排、全链路调试、可观测性、一键部署能力,成为企业级大模型应用开发的主流工具;LangChain推出的LCEL与LangGraph,实现了复杂流程的代码化编排与状态管理,成为开源领域的事实标准。
第三阶段:一线实践规模化验证期(2024年-2025年)
这一阶段,头部科技企业已经在内部大规模落地全链路的Agent管控体系,积累了大量的生产级实践,为Harness Engineering的理论化奠定了基础。
- 核心实践:支付巨头Stripe在公开的AI工程化实践中,搭建了名为Minions的企业级Agent管控体系,实现了每周超1300个由AI完全编写的代码PR合并,人类仅负责最终的架构与合规审查;Anthropic在内部工程文档中将Claude Code定位为“灵活的Agent线束”;LangChain通过优化Agent运行体系,在不修改模型的情况下,实现了基准测试性能的大幅提升。
- 核心认知升级:行业逐渐形成共识——在AI Agent落地中,决定结果好坏的最大变量,往往不是模型有多聪明,而是模型被放在了一个什么样的运行体系里。
第四阶段:正式命名与行业共识期(2026年2月至今,当前最新阶段)
2026年2月5日,HashiCorp联合创始人Mitchell Hashimoto在个人博客《My AI Adoption Journey》中,将这套正在被顶尖团队广泛采用的工程实践正式命名为Harness Engineering,并将其列为AI采用六阶段旅程的最高阶阶段;2月11日,OpenAI发布了官方实验报告《Harness Engineering: Leveraging Codex in an Agent-First World》,标题直接采用了这一术语,记录了5名工程师在5个月内,零行手写代码,通过Codex Agent协作交付了超100万行代码的生产级软件产品的完整实践;随后,Thoughtworks杰出工程师Birgitta Böckeler在软件工程泰斗Martin Fowler的官方网站发布了深度分析文章,系统拆解了Harness Engineering的三维核心框架,Martin Fowler作为网站所有者为文章的专业性与行业价值背书,进一步推动了行业共识的形成。
短短一个月内,Harness Engineering从一篇博客文章,变成了全球开发者社区的高频词,也标志着大模型工程化正式进入全链路环境设计的新时代。
3. 核心框架与最新实践
权威核心框架(来自Birgitta Böckeler发布于Martin Fowler官网的官方拆解)
- 维度一:上下文工程(Context Engineering):确保Agent在正确时机获得正确信息。包括前文提到的渐进式文档披露、动态可观测性数据接入、运行时数据开放等,它将此前的Context Engineering概念纳入了一个更完整的体系中,解决了“Agent该知道什么”的问题。
- 维度二:架构约束(Architectural Constraints):通过机械化手段强制执行架构边界与规则。包括专为Agent优化输出格式的确定性Linter、LLM审计Agent的双轨机制,让“违规→检测→修复”的循环在Agent内部闭环完成,无需人工介入,解决了“Agent只能在边界内行事”的问题。
- 维度三:熵管理/垃圾回收(Entropy Management):解决系统随时间腐化的问题。通过专用的清理Agent,定期扫描文档漂移、模式违规、依赖矛盾、规则过时等问题,确保Harness体系本身不会随着业务迭代而退化,解决了“系统长期稳定运行”的问题。
最新实践
- 头部企业的规模化生产验证:OpenAI通过Harness体系实现了零手写代码的百万行生产级软件交付,平均每名工程师每日完成3.5个PR合并,代码审查通过Agent对Agent的循环实现了大规模自动化,人工监督仅保留在高层架构决策环节;LangChain在Terminal Bench 2.0基准测试中,仅通过优化Agent运行的Harness体系,就将得分从52.8%提升至66.5%,全球排名从第30位跃升至第5位,底层模型一个参数都未修改,成为“运行体系比模型本身更重要”的最直接证据;安全研究员Can Boluk仅通过优化Agent的代码编辑管控规则,就让Grok Code Fast 1的基准得分从6.7%跃升至68.3%。
- 行业标准融合:与Agent Skills开放标准、MCP协议深度融合,OpenClaw 3.12稳定版与Claude Code将Harness Engineering的核心能力完全融入Skill体系,每个Skill都是一个标准化的Harness单元,封装了对应的Prompt、Context、执行规则、安全管控、工具调用逻辑,实现了管控单元的标准化封装与跨平台复用;MCP协议已成为Harness工程工具层的通用标准,为Agent提供标准化的工具访问通道。
- 开源生态完善:LangGraph 0.3.x已成为开源领域最主流的Harness开发框架,支持复杂的状态管理、多智能体协同、全链路可观测性;OpenClaw 3.12稳定版开源了完整的Skill管控引擎,支持多模型调度、全链路审计、热重载、权限管控,成为Agent场景下Harness Engineering的核心开源载体;Prefect 3.x、Dagster AI等工作流编排工具,也已专门针对大模型场景完成优化,实现了Harness体系的企业级调度与运维。
- 国产化体系落地:国内百度智能云千帆Prompt Flow、阿里云百炼工作流、腾讯云智能钛大模型工作流、华为云ModelArts大模型工作流,均已实现国产化全链路Harness能力,适配信创环境、国产模型、国内合规要求,在金融、政务、制造等行业实现规模化落地。
4. 开发者实操指南
Mitchell Hashimoto在源头博客中提出的六阶段采用旅程,是目前行业公认的可落地实操路线图,他本人也正处于第五阶段:
- 起步阶段:把同一个任务做两遍。先自己手动完成,再让Agent重新做一遍,建立对Agent能力边界的直觉。核心要点:把会话拆成独立清晰的任务;把模糊需求拆成“规划”和“执行”两个阶段;给Agent自我验证的方法。
- 习惯养成:每天下班前30分钟启动Agent。适合的三类任务:深度调研、并行探索、Issue和PR分诊,实现第二天的工作热启动。
- 关键跃迁:在你的项目里建一份AGENTS.md。从最基本的内容开始:项目的核心架构说明、常见的Agent错误及应对方式、测试和Lint命令、Agent绝对不能碰的部分。每次Agent犯错,就回来补一条规则,日积月累形成专属的Harness。
- 体系化构建:搭建结构化的文档体系、自动化Linter与反馈闭环、可观测性体系,让Agent能自主完成“执行-验证-修复”的闭环。
- 规模化落地:构建多Agent协同的Harness体系,实现跨团队、跨项目的标准化复用,支撑大规模的生产级开发。
- 生态化演进:将Harness体系标准化、开源化,融入行业通用生态,实现跨平台的复用与迭代。
5. 核心价值与行业意义
Harness Engineering(驾驭工程)的核心价值,是彻底解决了大模型概率性生成与生产场景确定性要求之间的核心矛盾。它没有改变大模型的底层能力,而是通过全链路的工程化管控,把不可控的大模型生成过程,变成了标准化、可管控、可审计、可进化的生产流程,让大模型真正能用于企业核心业务场景。它的行业意义,和前两代范式有着本质的区别:
- Prompt Engineering和Context Engineering,解决的是“让大模型做得更好”的问题,是单点的能力优化;
- 而Harness Engineering(驾驭工程),解决的是“让大模型能用在生产环境”的问题,是体系化的落地保障。
没有Harness Engineering,大模型永远只能停留在实验室、演示原型、轻量化辅助工具的阶段,无法进入企业的核心业务流程,无法实现规模化的工业化落地。
6. 对行业的深层影响
Harness Engineering(驾驭工程)不仅是一套技术范式的升级,更在深刻改变软件工程的底层逻辑、工程师的角色定位,甚至企业的组织架构:
- 工程师的核心工作正在发生本质转变:从“亲手写代码”,转向“设计让Agent可靠运行的体系”。一线工程师的日常工作,从代码编写,变成了三大核心事项:构建文档与上下文体系、以机器可处理的方式定义业务意图、构建自动化的防呆验证机制。对工程师的要求,也从“写代码的速度”,转向了“系统理解的深度、抽象能力与系统性思维”。
- 企业研发团队的组织架构正在被重构:OpenAI的3-7人团队,完成了以往需要数十人规模的工程输出;Stripe的实践让单名工程师可以同时向多个Agent分配不同任务。研发团队的结构正在向两三人甚至单人团队收敛,单人即可完整拥有从规划到上线的功能全生命周期,“合理团队规模”的底层计算逻辑正在被重写。
- 行业面临新的挑战与思考:Thoughtworks专家Birgitta Böckeler提出的“学徒缺口”问题,正在成为行业关注的核心——如果初级开发者过早进入Agent驱动的开发循环,未经历手动开发的锻炼,可能会缺乏未来构建健壮Harness体系所需的深度系统直觉。如何设计保留手动开发直觉的学习路径,将是行业接下来的核心挑战。
- 软件工程的核心竞争力正在被重新定义:软件工程团队的核心竞争力,正在从“谁的工程师代码写得更好”,转向“谁的工程师能设计出更好的Agent运行体系”。企业的核心数字资产,也从代码库,转向了支撑Agent可靠运行的Harness体系。
五、三代范式的演进逻辑与底层行业规律
从Prompt Engineering到Context Engineering,再到Harness Engineering,这套演进路径不是偶然的技术创新,而是大模型行业发展的必然结果,背后有着清晰的、经行业验证的底层逻辑与行业规律:
1. 演进的核心主线:从“能用”到“好用”,再到“能规模化落地”
三代范式的演进,完全贴合大模型行业的发展阶段,是行业对“如何让AI可靠工作”的三次认知升级:
- 2023年ChatGPT爆火,行业的核心需求是“让大模型能听懂指令、完成任务”,对应的就是Prompt Engineering的爆发,解决了“能用”的问题;
- 2025年,行业开始探索大模型在垂直场景的深度落地,核心需求是“让大模型能用私有数据、适配专业场景、不产生幻觉”,对应的就是Context Engineering的行业共识确立,解决了“好用”的问题;
- 2026年,行业开始把大模型用于企业核心业务流程,核心需求是“让大模型稳定、合规、安全、可控地运行,能规模化复用”,对应的就是Harness Engineering的正式命名与行业共识,解决了“能规模化生产落地”的问题。
2. 底层逻辑:从“适配模型”到“赋能模型”,再到“驾驭模型”
三代范式的核心目标,发生了本质的变化,形成了完整的认知升维:
- Prompt Engineering的核心,是“适配模型”——通过优化提示词,适配大模型的生成逻辑,让它输出符合预期的结果;
- Context Engineering的核心,是“赋能模型”——给模型注入准确的信息,打破它的知识边界,让它能完成更专业的场景任务;
- Harness Engineering的核心,是“驾驭模型”——通过全链路的管控体系,约束大模型的不确定性,让它在既定的规则、边界、流程内运行,成为稳定的生产力工具。
3. 三者的关系:互为基础,层层递进,共同构成完整的工程化体系
必须明确的是,Prompt Engineering和Context Engineering并没有“过时”,它们依然是Harness体系的核心基石,三者不是替代关系,而是深度融合、互为支撑的完整体系:
- Prompt Engineering是整个体系的基础,Context的注入、Harness的流程管控、规则约束,最终都要通过Prompt传递给模型,没有好的Prompt设计,再完善的上下文、再复杂的流程管控,都无法达到预期的效果;
- Context Engineering是场景落地的核心,它给Harness的生产线提供了准确的原材料,没有精准的上下文管理,再完善的流程管控,也无法输出专业、准确的结果;
- Harness Engineering是生产级落地的完整框架,它给Prompt和Context提供了标准化的运行环境、全链路的管控保障、持续进化的闭环体系,没有Harness,Prompt和Context只能用于单点场景,无法实现规模化、标准化的生产落地。
六、行业趋势与未来演进
当前,Prompt Engineering、Context Engineering、Harness Engineering已经形成了完整的工程化体系,成为大模型落地的三大核心支柱。未来,随着大模型技术的持续迭代,这套工程化体系还将沿着四个核心方向持续演进:
- 三者的深度融合与自动化:未来的工程化体系,将不再是三个独立的模块,而是端到端的自动化Harness框架。用户只需要定义业务目标、合规规则、质量标准,框架就能自动生成对应的Prompt、设计Context管理策略、构建全流程的Harness管控单元,大幅降低大模型应用的开发门槛。
- 标准化与开源生态的完善:当前,Agent Skills开放标准、MCP协议已经成为行业事实标准,未来,Prompt、Context、Harness的全流程规范将进一步统一,形成全球通用的大模型工程化标准,打破不同平台、不同框架之间的壁垒,推动大模型应用的跨平台复用与规模化分发。同时,国产化工程化体系将进一步完善,实现从底层模型、基础设施到上层管控框架的全链路自主可控。
- 评估体系的规模化落地:LangChain发布的《Agent工程化现状报告》显示,89%的受访者已为其Agent实施了可观测性,但仅有52%实施了标准化的评估体系(Evals)。评估体系的规模化落地,将是Harness Engineering接下来一年的核心课题,也是行业的核心机会窗口。未来,可量化、自动化的评估体系,将成为Harness体系的核心组成部分,实现“执行-评估-优化”的完全闭环。
- 与多智能体、多模态的深度适配:随着多模态大模型、多智能体协同的快速发展,工程化体系也将从文本场景,扩展到多模态、多智能体场景。未来的Harness Engineering,将支持多模态内容的全流程管控、多智能体的协同调度与上下文共享,支撑更复杂的、端到端的业务场景。
结语
从本质上看,Prompt Engineering、Context Engineering、Harness Engineering的演进历程,就是大模型从“通用能力”走向“产业生产力”的完整路径。
大模型的核心价值,从来都不是它的参数规模、推理能力有多强,而是它能不能真正融入产业,解决真实的业务问题,创造实际的商业价值。而这三套工程化范式,正是连接大模型能力与产业落地之间的桥梁——Prompt Engineering让我们能和大模型顺畅沟通,Context Engineering让大模型能适配专业的场景,Harness Engineering让大模型能稳定、安全地在生产环境中规模化运行。
未来,随着大模型技术的持续进化,工程化体系也会不断完善,但核心逻辑永远不会改变:工程化的最终目标,从来都不是“炫技式的技术创新”,而是“让大模型真正成为好用、可控、普惠的生产力工具”。
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/243361.html