
对于刚入门大模型、想落地轻量模型的程序员和小白来说,知识蒸馏是绕不开的核心技术——它的核心目标,就是把大型复杂模型(业内统称“教师模型”)里沉淀的知识、推理逻辑和决策能力,高效迁移到参数更少、运行速度更快、部署成本更低的小型模型(“学生模型”)中,最终实现“轻量不缩水、小模型也有强性能”的效果,完美适配边缘设备、低算力服务器等资源受限的实际开发场景,也是程序员落地大模型项目的关键突破口。
很多小白刚开始会混淆知识蒸馏的分类,其实按照知识迁移过程中,我们能访问教师模型的权限不同,知识蒸馏可清晰划分为两大核心类型,用通俗的话讲明白,小白也能快速区分:
- 黑盒蒸馏(Black-box):学生模型只能获取教师模型的“输入-输出”映射关系,看不到模型内部的结构、中间层输出和参数分布,就相当于“只看标准答案,慢慢摸索解题方法”,不用懂底层原理也能上手模仿。
- 白盒蒸馏(White-box):除了基础的输入输出,还能直接访问教师模型的中间隐藏状态、注意力权重、输出概率分布等核心内部信息,属于“看透底层原理后,精准模仿甚至优化”,更适合想深入研究技术的程序员。
结合当前大模型行业落地现状和学术研究方向,核心趋势非常明确,不管是小白入门还是程序员选型,都值得重点关注(建议收藏,避免后续找不到):
- 工业界优先选黑盒蒸馏:无需获取模型源码、参数,能直接借助GPT-4、Qwen-Max等成熟闭源大模型的强大能力,落地成本低、见效快,是程序员实际项目中最常用的方式,小白入门也可从这里切入。
- 学术界聚焦白盒蒸馏:重点深挖模型内部的知识传递机制,更容易提出创新性方法和理论突破,适合想深耕大模型技术、往学术或高级开发方向发展的程序员。
- 混合蒸馏成新热点:把黑盒蒸馏的“数据驱动”(高效借力)和白盒蒸馏的“结构对齐”(精准优化)结合起来,兼顾效果与效率,目前已经逐渐成为高性能轻量模型的主流方案,也是未来的核心发展方向。
综述性文章
A Comprehensive Survey on Knowledge Distillation[1] 这篇是25年10月的综述,内容比较详尽,它将白盒蒸馏和黑盒蒸馏细分成以下几个类别:
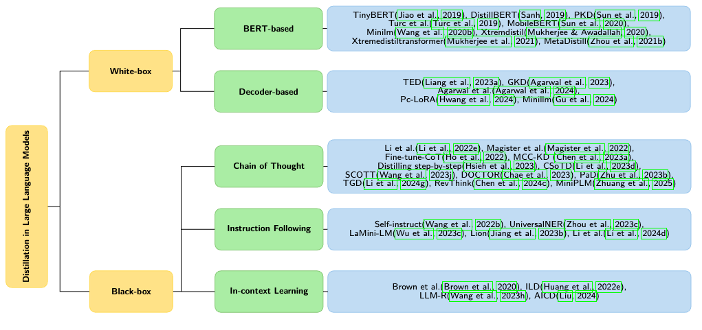
其中,白盒蒸馏是根据模型的架构去分,分成基于BERT和只基于Decoder的,这种分发个人觉得比较粗暴,不是很合理。
黑盒蒸馏是根据方法区分,比较合理,主要分为以下三种:
- 思维链(Chain of Thought):教师模型对已有数据生成思维链,供学生模型训练
- 指令遵循(Instruction Following):教师模型对训练数据生成指令、输入和输出样本,供学生模型训练
- 上下文学习(In-context Learning):构造任务,收集教师模型在不同上下文情况下的输出,结果供学生模型训练
Survey on Knowledge Distillation for Large Language Models: Methods, Evaluation, and Application[2] 是另一篇综述性的研究,发布时间是24年1月,内容不如上一篇丰富,不过也提出了一些不同的梳理和思考。
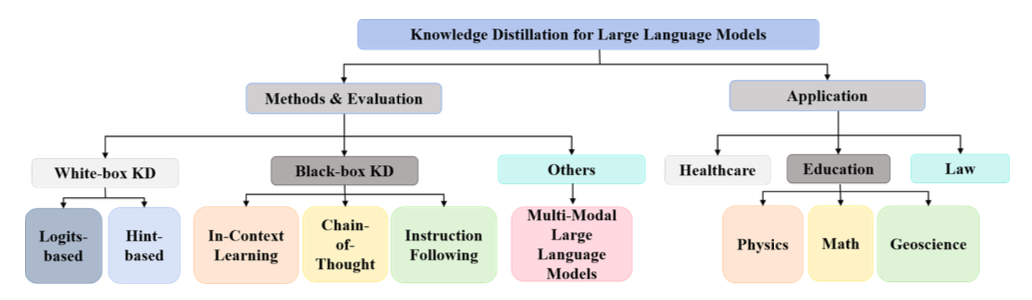
A Survey on Knowledge Distillation of Large Language Models[3]这篇24年的文章则是根据具体的方法论,汇总了各种知识蒸馏的方法,研究细分领域可以参考。
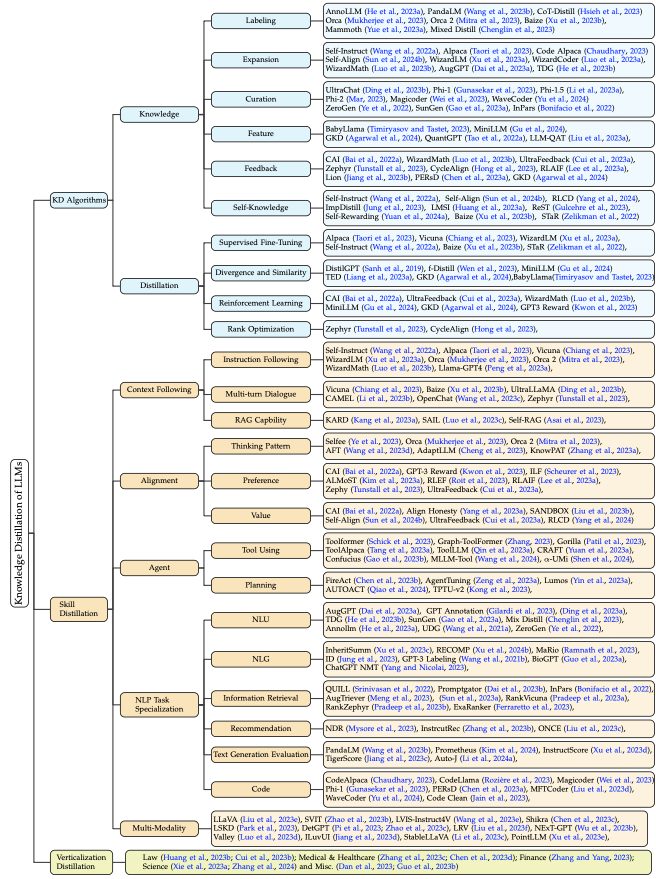
黑盒蒸馏文章
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning[4]这篇文章就是黑盒蒸馏的典型代表。
在这篇文章中,有6个蒸馏的小模型,4个基座是Qwen,两个基座是Llama3.1。
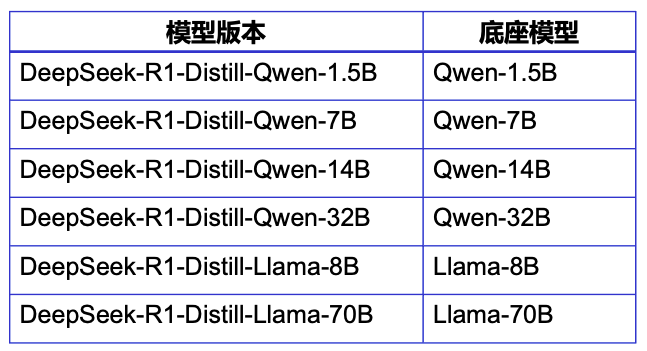
DeepSeek-R1小模型的蒸馏方式:将DeepSeek-v3(671B)模型生成的数据作为小模型训练集。
训练数据量包含两部分:推理数据(60w)+非推理数据(20w)
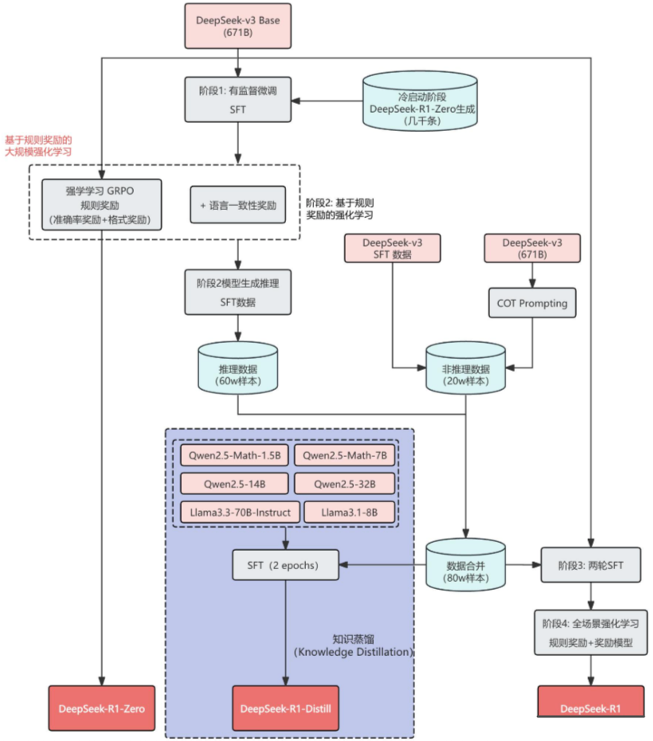
MiniPLM: Knowledge Distillation for Pre-Training Language Models[5]是最新比较典型的黑盒蒸馏方法。
具体思路是:根据教师模型和学生模型之间的输出概率分布差异,调整学生模型预训练数据的语料库。
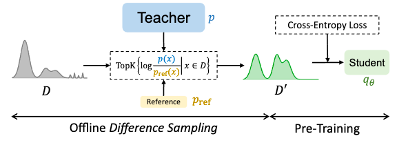
根据概率分布,做出以下调整:
- 减少简单样本
- 增加复杂/多样性样本
- 提出噪音/有害样本
它的实验中教师模型参数量为1.8B,学生模型的参数量为200M/500M/1.2B。
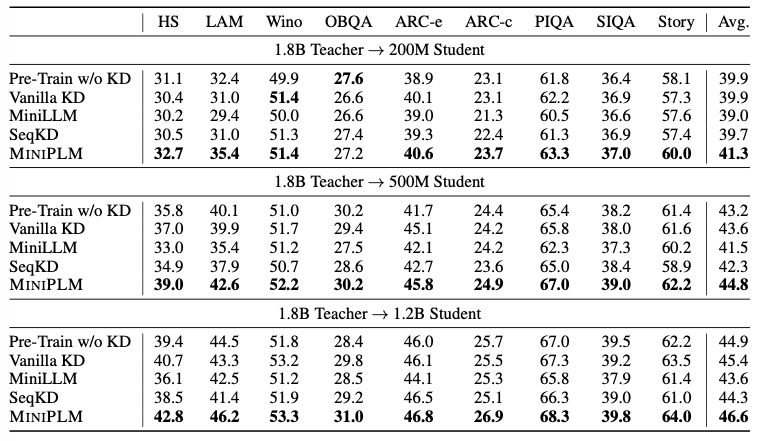
其中,Pre-Train w/o KD为未经蒸馏的小模型性能表现。
黑盒与白盒结合蒸馏文章
DistilQwen2.5: Industrial Practices of Training Distilled Open Lightweight Language Models[6] 是通义实验室发布的一篇比较经典的黑白盒相结合的文章。
具体方案是:
- 黑盒蒸馏:使用Qwen3-Max(1T)和GPT-4o(闭源)作为教师模型,来生成小模型的训练数据
- 指令问题生成:根据问题指令,输出相关响应
- 优化训练数据:为原始训练数据增加思维链(CoT)
- 训练数据筛选:根据信息量、任务平衡性筛选数据
- 验证问题正确性:对已有答案进行事实核验
- 白盒蒸馏:让学生模型的输出和教师模型输出尽可能接近
白盒蒸馏除交叉熵损失外,还采用知识蒸馏损失来最小化学生模型与教师模型的输出的Token序列之间的散度。
模型蒸馏前后的性能如下表所示:
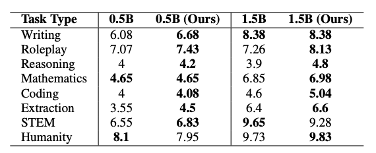
蒸馏前后总体会有提升,部分任务可能无变化或下降。
后面我会进一步从代码角度分析这篇文章的思路。
蒸馏效果评估
在调研具体方法时,还发现了Quantification of Large Language Model Distillation[7]这一篇有关蒸馏效果量化评估的工作。
里面解释了一个有趣的现象:当问大模型身份性问题时,它可能会答出其它厂商的答案。
比如,问Qwen-Max它的开发团队是谁,它会说它是由Anthropic开发的。

按照这篇文章提出的评估方法,蒸馏水平越靠近右上角,采用蒸馏的程度越高。
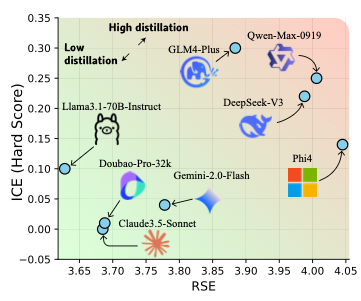
图中表明,Claude、Doubao和Gemini的蒸馏程度较低,而Qwen-Max的蒸馏程度最高。
这里给大家精心整理了一份全面的AI大模型学习资源,包括:AI大模型全套学习路线图(从入门到实战)、精品AI大模型学习书籍手册、视频教程、实战学习、面试题等,资料免费分享!
👇👇扫码免费领取全部内容👇👇

要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。(书籍含电子版PDF)

对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。

行业分析主要包括对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。

学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。

面试不仅是技术的较量,更需要充分的准备。
在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

👇👇扫码免费领取全部内容👇👇
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/242946.html