
什么时候有可能实现AI agent?
通过对GAO御三家的官方定义的分析(瞎琢磨),
我总结了五条关于AI Agent关键词 (fully):
①任务导向:可以把任务作为Agent的定义前缀 比如“Deep Research Agent” “Blender Agent”,虽然基于模型,但仍然需要设计和构建。基于同一个模型,任务不同,产生的Agent也是不同,有些Agent泛用性强,有些很狭窄。
②自主独立:不依赖用户每一步的提示词。LLM可以自我提示,自我反思,达成若干步骤的自主行动。用户只要给定初始任务即可。比如,你无需微观管理一个Deep Research Agent:你要按照以下100步来完成你研究。 (╯‘ - ’)╯︵ ┻━┻
③动态推理:理解任务当前状态并做出预判。这是非常典型的RL模型,根据对目标或结果的预判,来调整自己当前的行为。(这个下次有机会展开来讲讲,很有意思,因为这涉及到智能的底层逻辑)
④环境感知:理解交互环境的状态,趋利避害。多模态是模型走向通用性的关键之一,影响着未来Agent的泛用性。
⑤基于LLM:当前agent的特色,但不是本质特征,Agent并不一定需要LLM。但是AGI agent一定需要LLM。(这看起来像是一个文字游戏,LLM是“通用”人工智能的起点)
According to Google, an AI agent can be defined as an autonomous system that is capable of observing its environment, reasoning about its goals, and taking actions using external tools to achieve those goals. Furthermore, AI agents are described as software systems that utilize artificial intelligence to pursue objectives and complete tasks on behalf of users. These systems exhibit capabilities such as reasoning, planning, and memory retention.
根据谷歌的定义,AI agent可以被定义为一种自主系统,它能够观察其所处环境,对自身目标进行推理,并使用外部工具采取行动以实现这些目标。此外,AI agent被描述为利用人工智能代表用户追求目标并完成任务的软件系统。这些系统展现出推理、规划和记忆留存等能力。
OpenAI defines AI agents as “automated systems that can independently accomplish tasks on behalf of users.” These agents are designed to perform tasks autonomously, often by navigating the web or operating on a user‘s device to execute multi-step processes . An example is OpenAI’s “Operator,” which is an AI agent capable of using its own browser to perform tasks for users. Additionally, OpenAI has developed other AI agents like “Deep Research,” which is tailored for complex research tasks, automatically searching, interpreting, and integrating vast amounts of online information to generate professional-grade research reports.
OpenAI将AI agent定义为“能够代表用户 独立完成任务的自动化系统”。这些agent被设计用于自主执行任务,通常是通过浏览网页或在用户设备上操作来执行多步骤流程。一个例子是OpenAI的“Operator”,它是一个AI agent,能够使用其自带的浏览器为用户执行任务。此外,OpenAI还开发了其他的AI agent,比如“深度研究(Deep Research)”,它专为复杂的研究任务而设计,能够自动搜索、解读并整合大量的在线信息,以生成专业级别的研究报告。
Anthropic defines an AI agent as a system that operates autonomously to determine the number of steps and tools needed to complete a task. Additionally, Anthropic describes AI agents as systems where large language models (LLMs) maintain control over their processes and tool usage, dynamically adapting to the demands of a given task .
Anthropic将AI agent定义为一种自主运行的系统,该系统能够自行确定完成一项任务所需的步骤数量和工具。此外,Anthropic把AI agent描述为这样的系统:在其中,大语言模型(LLMs)能够对其运行过程和工具使用情况进行控制,并能根据特定任务的要求进行动态调整。
如果你用过 ChatGPT 或通义千问,你大概体验过这样的对话:
“今天北京天气怎么样?” → “晴,5–12°C。”
这属于典型的 问答型交互——你问它答。AI 被动响应,不主动行动。
而 Agent(智能体) 的目标是更进一步:不仅能理解你的意图,还能主动执行任务。
传统 AI:只回答“你可以去 12306 查”
Agent:直接帮你查车次、选座位、下单、发邮件,全程无需你动手

这就是 Agent 的核心价值:让AI从“信息提供者”变成“任务执行者”。
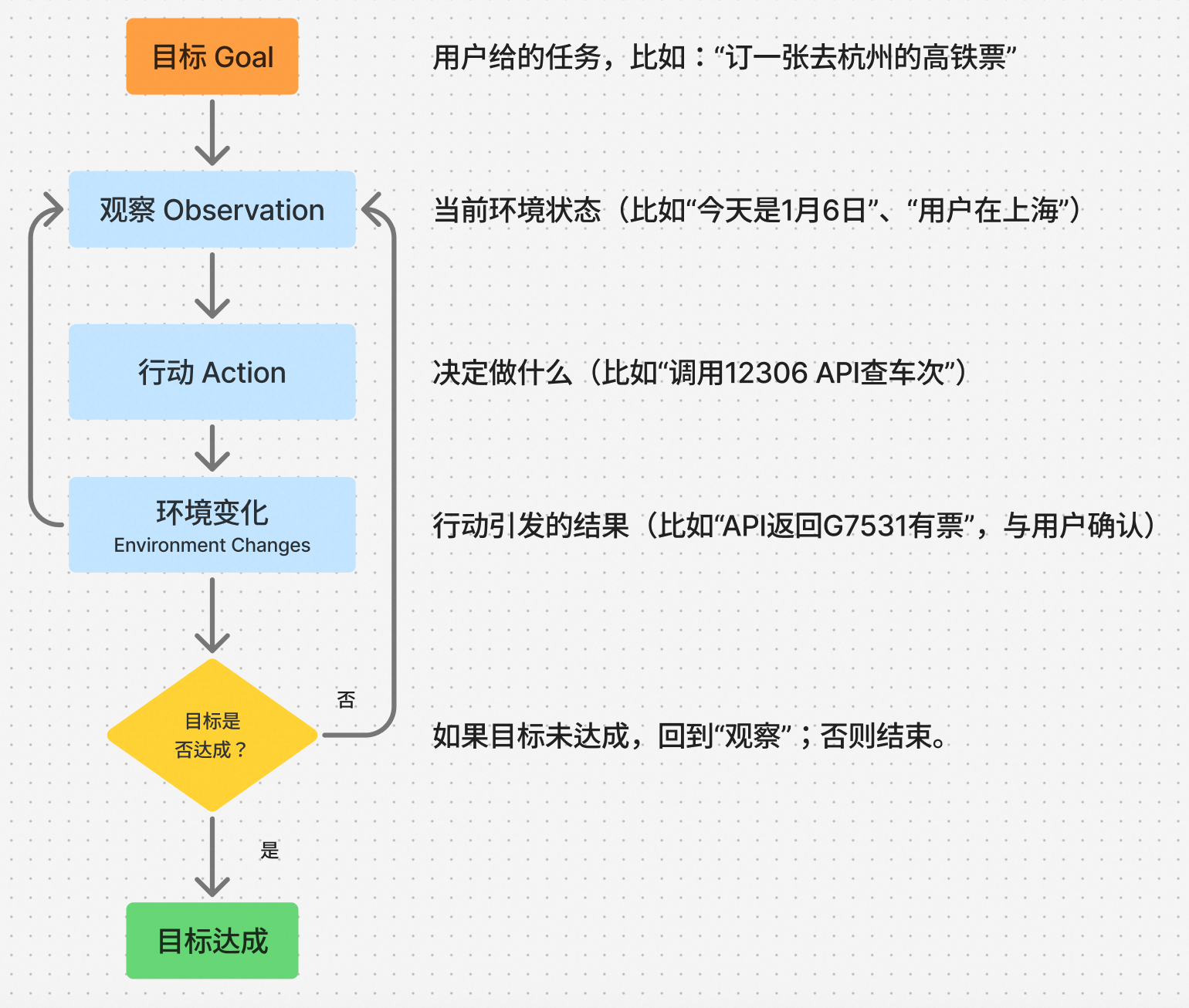
假如你对一个 Agent 说:“帮我订一张明天去杭州的高铁票”,它会这样做
- 解析意图:需要订票 + 可能需通知(如发邮件)
- 规划行动步骤:
- 获取当前时间、用户所在城市(如上海)
- 查询 12306 接口,筛选“上午出发、二等座”车次
- 选择最优选项(如 G7531,8:15 发车),并向你确认
- 确认后调用订票接口,生成行程摘要
3. 执行 & 反馈:“已为您预订 G7531 次列车(8:15 上海虹桥 → 9:20 杭州东),以下为行程详情:xxx”
4. 如果余票不足或时间不合适,它还会自动调整策略、重新查询。
这个“目标 → 观察 → 行动 → 环境变化 → 循环”的闭环,就是 Agent 的核心运行逻辑。
关键点:Agent 不是一次性输出答案,而是 在动态环境中不断调整策略,直到任务完成。
AI Agent 并不是突然冒出来的“黑科技”,它其实走过了一条漫长的演进之路。我们可以用一张时间轴来理清它的成长轨迹:

| 时间 | 里程碑 | 关键进展 |
| 1980s | Symbolic Agents(符号智能体) | 基于预设的“if-then”规则进行符号推理,像一个逻辑计算器。核心思想:使用逻辑规则和符号表示知识,比如“如果下雨,则带伞”。 |
| 1990s | Reactive Agents(反应式智能体) | 随着机器人和实时系统的兴起,人们意识到 Agent 要能“快速响应环境”。核心思想:直接根据当前感知做出反应。 |
| 2000s | RL-based Agents(强化学习智能体) | 进入千禧年后,得益于强化学习(Reinforcement Learning, RL)的发展,人们让 Agent 通过与环境交互不断试错,学会最优策略。 |
| 2020 | Transfer & Meta Learning Agents(迁移与元学习智能体) | 将迁移学习(Transfer Learning)和元学习(Meta-Learning)应用在Agent中,让 Agent 能从少量样本中快速学会新任务 |
| 2023–至今 | LLM-based Agents(大语言模型驱动的智能体) | 2023 年是 LLM-based Agent 的元年,以 GPT-4、通义千问等大语言模型为大脑,这类 Agent 具备了前所未有的能力。 |
2023年 -> Function Calling:OpenAI 在 GPT-4 中首次推出的机制,允许 LLM 主动请求调用外部函数(API)。它让 LLM 从“只能说话”变成“能做事”。
2024年 -> MCPs(Model Context Protocol):Anthropic提出MCP协议,为大语言模型(LLM)与外部工具、数据源之间的交互提供一个统一、开放、安全的标准协议
2025年 -> A2A:google提出agent-to-agent协议,让不同公司、不同框架开发的 AI Agent 能够安全、标准化地通信与协作
这些协议的出现标志着Agent 进入“生态建设”阶段,不再单打独斗,而是走向标准化、互联互通和自主协作。
很多人搞不清“工作流(Workflow)”和“Agent”有什么区别,其实它们代表两种完全不同的自动化范式。
一句话记住: Workflow 是“你告诉它每一步怎么做”,Agent 是“你告诉它要什么结果,它自己想办法”。
比如你的目标是:“整理一份年度报销单。”
Workflow 是预定义的、静态的流程。比如用 Zapier 或 n8n 搭建的自动化工作流:
你得提前画好一张“操作地图”:
- 打开邮箱 → 下载所有带“发票”的附件;
- 把 PDF 发票拖进 OCR 工具 → 转成 Excel;
- 手动核对金额 → 填入公司报销系统模板;
- 提交。
但只要哪一步出意外——比如某张发票是手写的、OCR 识别失败,或者邮件标题没写“发票”——整个流程就卡住不动,还得你手动救场。
Agent 是动态的、基于目标驱动的系统。它会根据当前情况决定下一步怎么做。
还是上面的例子,换成 Agent:
Agent 可能这样做:
- 扫描你近一年的邮件,智能识别哪些是发票(哪怕标题是“行程单”或“收据”)
- 判断格式:PDF?图片?手写?→ 自动选择**解析工具
- 遇到模糊发票 → 先尝试 OCR,失败后调用图像增强,再不行就标记出来请你确认
- 自动填表、计算总额、检查是否超预算
- 最后生成标准报销文件,并提醒你:“法务要求补充高铁订单截图,已附在第3页”
一个完整的 Agent 系统通常包含以下四个模块:
目前绝大多数 Agent 基于多模态大语言模型(如 GPT-4、Claude、通义千问)。
大模型的作用不仅是生成文字,更重要的是:
- 理解模糊指令(如“整点资料”)
- 进行多步推理(“如果 A 成立,那么 B 可能…”)
- 决定是否需要调用工具
比如:很多框架(如 LangChain、LlamaIndex)允许你“注入”系统提示词(system prompt)来引导 LLM 行为,
“你是一个任务规划助手。当用户请求涉及外部操作时,请明确列出所需工具及参数。”Agent 不会一上来就莽干,它会先“想清楚怎么做”,然后把大任务拆成小步骤。
常见规划策略包括:
| 方法 | 说明 | 示例 |
| Chain-of-Thought (CoT) | 推理链 | “要写周报 → 需要数据 → 数据在哪?→ 查数据库” |
| Task Decomposition | 任务分解 | “组织会议” → [查空闲时间, 发邀请, 准备议程] |
| ReAct(Reason + Act) | 边推理边执行 | 执行一步 → 观察结果 → 决定下一步 |
没有记忆的 Agent 就像金鱼——聊完就忘。
Agent 的记忆通常分两类:
- 短期记忆:当前对话上下文(靠 LLM 的上下文窗口维持,比如 32K tokens)
- 长期记忆:持久化存储,用于跨会话使用
长期记忆的典型实现方式,如:
- 用向量数据库存储历史交互
- 结合 RAG(检索增强生成):每次响应前先检索相关记忆
工具就像是 Agent 的“手脚”,Agent 通过工具来执行任务、获取信息或完成操作。
随着生态系统的成熟,工具的使用方式也在不断变得更加标准化:
- Function Calling(2023年):由 OpenAI 首先提出的 Function Calling 允许大型语言模型(LLM)以结构化的方式调用外部API。这意味着Agent可以通过简单的指令来查询天气、发送邮件或者获取最新新闻等,而不需要了解背后的复杂细节。
- MCP(2024年):Anthropic 推出的 Model Context Protocol (MCP) 则为工具提供了一种统一的描述格式。借助 MCP,开发者只需对工具进行一次封装,就能在任何支持该协议的平台上轻松部署和使用,大大提高了开发效率。
单个 Agent 能力有限,复杂任务往往需要分工协作,这时候就用到 Multi-Agent System(多智能体系统)。
Multi-Agent 系统的核心思想是:将复杂任务拆解为多个子任务,并由具备不同专长的 Agent 协同完成。
从实现角度看,Multi-Agent 应用通常分为两个关键部分:
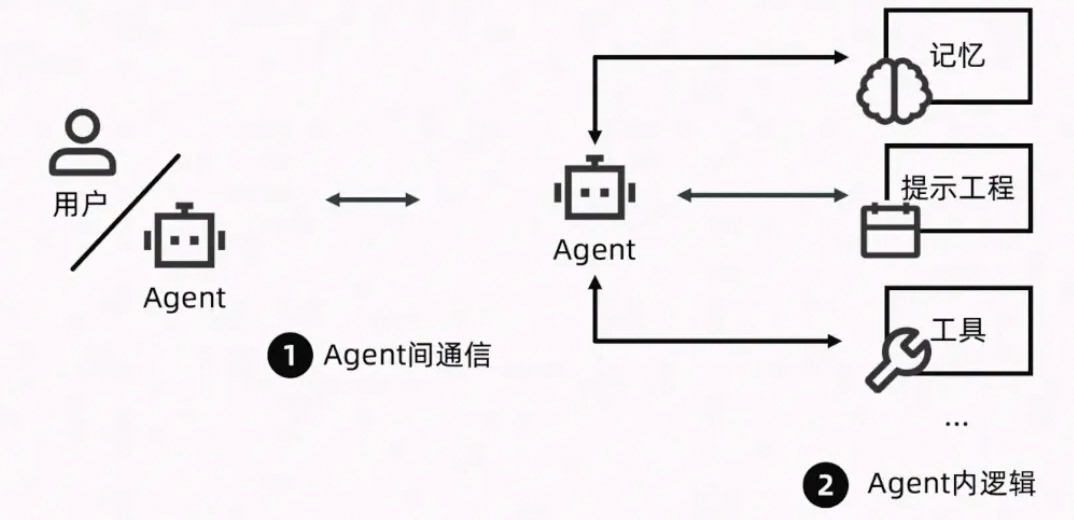
1)Agent 内的逻辑
- 推理能力(基于 LLM 的思考)
- 记忆机制(存储上下文和历史)
- 提示工程(引导行为的规则)
- 工具调用能力(如 API、数据库、代码执行等)
→ 这些构成了 Agent 的“内部逻辑”,决定了单个专家能做什么、怎么做。
2)Agent 间的通信
- 产品经理 Agent 发送需求给开发 Agent
- 开发 Agent 完成后通知测试 Agent
- 测试 Agent 反馈问题,触发修复流程
→ 这种“对话式协作”让整个系统像一个有机整体运行,而非孤立个体。
简单来说:Multi-Agent 是让 AI 从“一个人做事”进化到“一个团队协作”的关键一步。
随着 AI Agent 技术的爆发式发展,各类框架如雨后春笋般涌现。
笔者结合 截至 2026 年初的 GitHub Star 数 与 业界实际热度,筛选出当前最具代表性的几款Agent框架做一下介绍:
github: https:// github.com/Significant- Gravitas/AutoGPT
论文:AutoGPT 最初是社区驱动项目,无正式学术论文。可参考以下关联工作:Generative Agents: Interactive Simulacra of Human Behavior (Stanford, 2023)
AutoGPT 是最早引爆“自主 Agent”概念的项目之一,其功能涵盖代理创建模块“Forge”、性能评测基准agbenchmark、排行榜以及易用的UI和CLI接口,凭借“让 LLM 自主上网、写代码、发邮件”的Demo演示迅速走红。
AutoGPT 框架的核心是其 自主循环机制(Autonomous Loop)。它将 LLM 的推理能力与外部工具链结合,形成“思考 → 行动 → 观察 → 反思”的闭环。在这个过程中,模型会自行决定下一步该做什么——是继续搜索信息、编写代码,还是保存结果。这种“无脚本式自主性”在 2023 年初引发了广泛关注。
然而,AutoGPT 也存在明显不足:
- 缺乏流程控制:任务完全依赖 LLM 自主决策,容易陷入无效循环(如反复搜索相同关键词)或偏离目标;
- 稳定性差:没有内置容错、重试或状态持久化机制,长时间运行易崩溃;
- 工具生态有限:原生支持的工具较少,扩展需手动开发;
因此,尽管 AutoGPT 在历史上具有里程碑意义,其历史累计 Star 虽高达 18 万+,但自 2024 年底起活跃度显著下降,核心团队已转向新一代架构(如 AGiXT),原项目更新缓慢。如今,它的许多思想已被 AutoGen、MetaGPT 等更成熟的框架继承并优化——从“自由探索”走向“有纪律的协作”。
github: https:// github.com/langgenius/d ify
官方文档:https://docs.dify.ai
官方介绍: https:// github.com/langgenius/d ify#architecture
Dify 是一个由 LangGenius 团队开发的低代码 AI 应用构建平台,它强调可视化编排与企业级部署,允许用户通过可视化界面或简单配置,快速搭建基于大语言模型的应用。这个平台的核心优势在于易用性与企业级支持,你无需编写复杂代码,就能完成从 Prompt 设计、知识库接入到部署上线的全流程。
Dify 本质上是一个 Workflow 引擎,AI Agent 仅作为流程中的执行节点。
Dify 框架的核心是其 工作流编排能力。你可以将任务拆解为多个步骤(如用户输入 → 意图识别 → RAG 检索 → LLM 生成 → 输出),并通过拖拽方式定义执行顺序。每个节点都可以绑定不同的模型、工具或条件判断,从而构建出结构清晰、可维护的自动化流程。
它的优势在于:通过提供一体化开发环境,简化了 LLM 应用的落地门槛。它不仅支持私有化部署和多模型切换,还能无缝集成企业内部数据源。更重要的是,Dify 将 AI 能力封装为“服务”,让产品经理、运营人员也能参与应用构建——这使得 AI 不再只是工程师的专属工具,而是真正融入业务流程的生产力引擎。 局限在于:缺乏真正的多智能体协作能力,更适合构建问答机器人、知识库助手等确定性任务。
github:https://github.com/langchain-ai/langchain
论文:LangChain: Building Applications with LLMs through Composability
(Harrison Chase et al., arXiv:2308.08155, 2023)

LangChain 是目前拥有 最庞大的 LLM 应用生态的开源框架,涵盖 LangGraph(工作流编排)、LlamaIndex(RAG)、LangServe(部署)等子项目,主仓已超 13 万stars。
LangChain 框架的核心是其 可组合性(Composability)。你可以像搭积木一样,将不同的功能单元(如文档加载器、文本分割器、向量数据库、LLM 接口)串联起来,形成一条完整的处理链(Chain)。例如,在构建一个知识问答系统时,你可以先从 PDF 中提取文本,再将其向量化存入数据库,最后在用户提问时进行语义检索并生成答案。
LangChain另一大贡献是其模块化的工具链生态,通过抽象出通用接口和标准协议,提供 300+ 工具集成(数据库、API、搜索等),极大简化了 RAG 与 Function Calling 的实现。
但需注意:LangChain 本身并非原生多智能体框架,若需 Multi-Agent 能力,需搭配 LangGraph 或 AutoGen 使用。
github:https://github.com/microsoft/autogen
论文:AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation
(Qingyun Wu et al., Microsoft Research, arXiv:2308.08155, 2023)

AutoGen 是一个由 微软推出的框架,它允许开发者定义多个具有不同角色和能力的 Agent(如程序员、产品经理、测试员),并通过自然语言对话机制实现协同。Microsoft提供了详细的安装指南和文档。
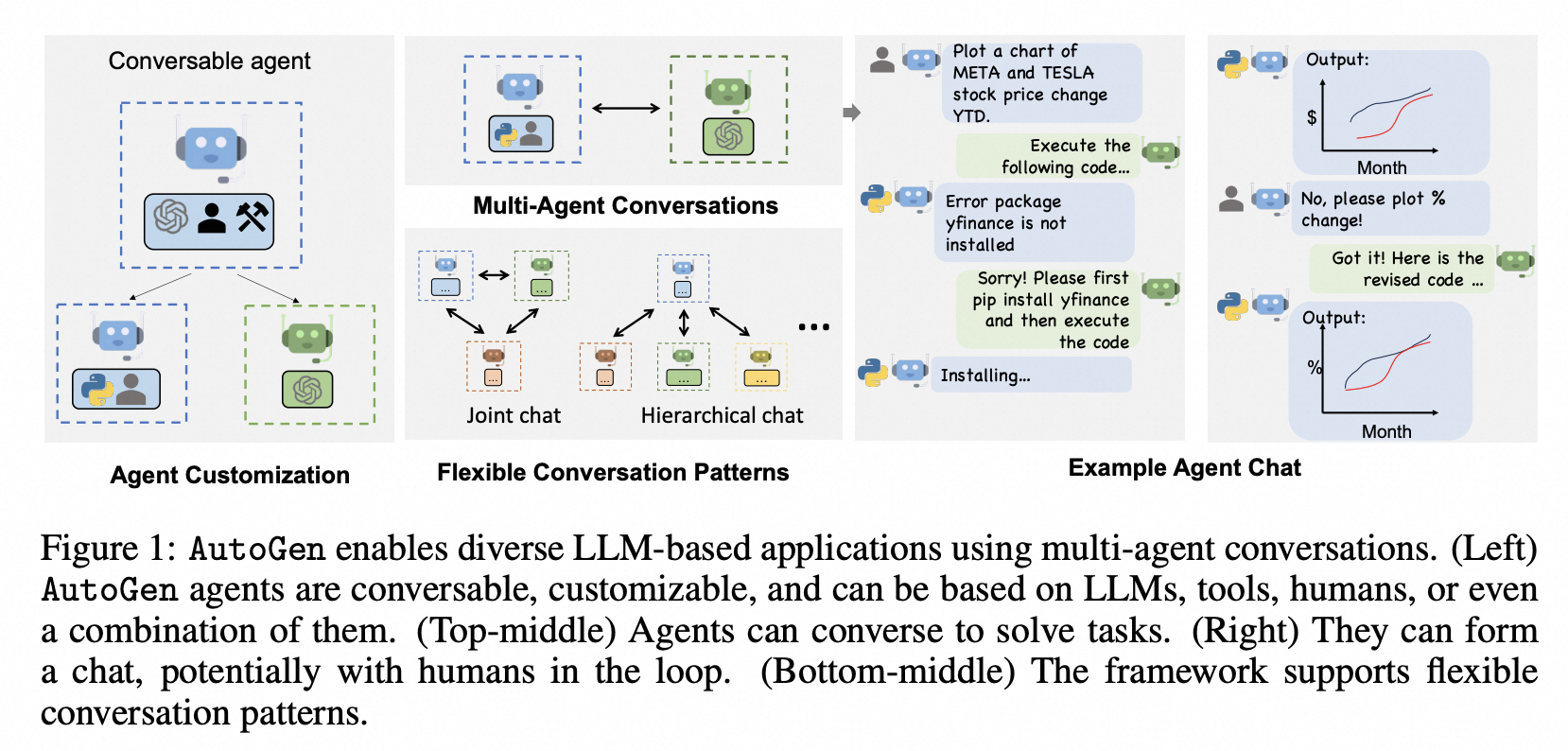
Autogen框架的核心是其代理协同工作的能力。每个代理都有其特定的能力和角色,你需要定义代理之间的互动行为,即当一个代理从另一个代理收到消息时该如何回复。这种方式不仅仅是在定义代理和角色,还在定义它们如何协同工作,从而实现更优的任务完成效果。
典型用例包括:跨部门数据分析、自动化科研实验、复杂客服工单处理等。
github:https://github.com/crewAIInc/crewAI
论文:ChatDev: Communicative Agents for Software Development
(Chen et al., ACL 2024 Findings)
ChatDev是由面壁智能联合清华大学 NLP 实验室于 2023 年 7 月开源的一个垂直领域的多智能体系统,它模拟了一家虚拟软件公司,允许用户仅通过自然语言指令,驱动多个专业角色的智能体协作完成完整软件项目的开发。这个框架的独特之处在于其高度结构化的任务分解与角色专业化设计。

ChatDev 借鉴软件工程ref=“https://baike.baidu.com/item/%E7%80%91%E5%B8%83%E6%A8%A1%E5%9E%8B/”>瀑布模型(Waterfall Model)的思想,将其分为 软件设计(Designing)、系统开发(Coding)、集成测试(Testing)、文档编制(Documenting) 四个主要环节。
之后,通过对软件开发瀑布模型的进一步分解,形成由原子任务构成的交流链(Chat Chain)。整条链可视为由原子任务组成的 “软件生产线”,链中每个子任务通过专业角色(例如产品设计官、Python 程序员、测试工程师等)的智能体进行对话式信息交互和决策;驱动其进行自动化需求分析、头脑风暴、系统开发、集成测试、GUI 创作、文档编制等全流程软件工程。
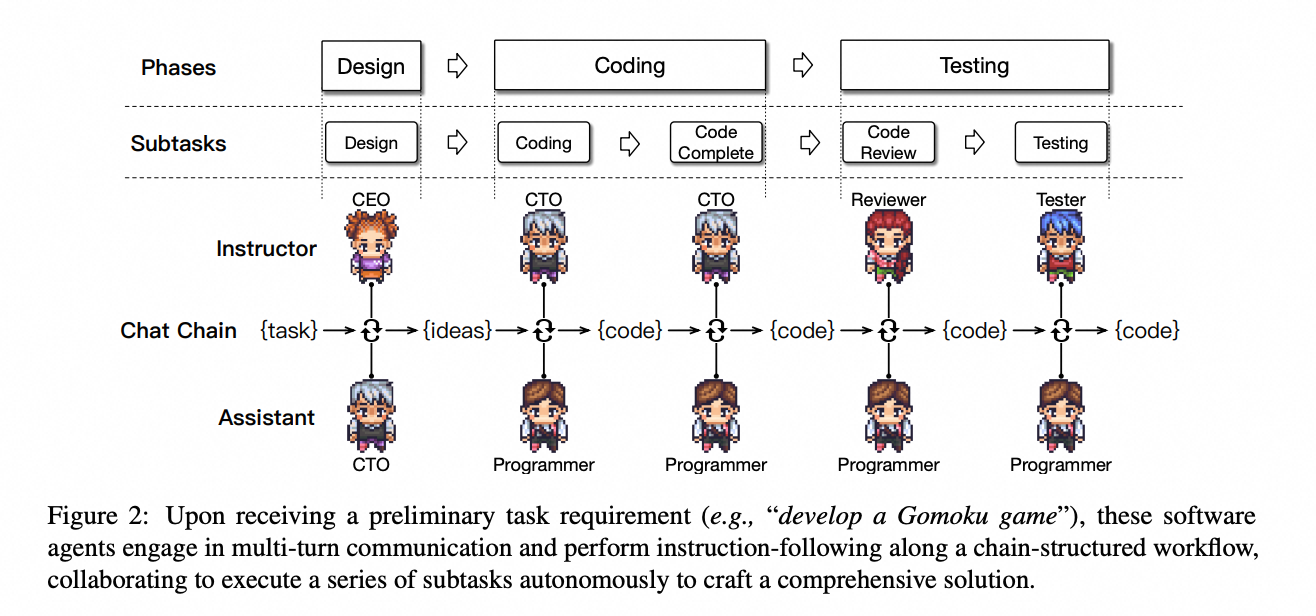
驱动智能体交流对话的主要机制为:角色专业化(Role Specialization)、记忆流(Memory Stream)、自反思(Self-Reflection):
- 角色专业化通过角色扮演机制(Role-Playing)确保每个智能体各司其职,在指定的专业角色下完成相应的方案提议和决策讨论。
- 记忆流通过将历史对话进行呈现,保证上下文感知的对话过程,并动态地对对话历史信息进行汇总和决策。
- 自反思机制在对话没有自动触发结束协议时生效,通过整轮对话进行文本摘要,摘录出对话过程达成一致后的最终决议。
目前已经覆盖的落地场景有:编程助手(网络爬虫、数据库读写、文件批处理、网页设计),休闲小游戏(五子棋、贪吃蛇、乒乓球游戏)、效率管理工具(代办清单、数字时钟、数学计算器、密码生成器),创作辅助工具(词典、绘画板、图片编辑器)等。
ChatDev 的意义在于: 证明了 Multi-Agent 可在单一垂类中实现端到端交付。
github:https://github.com/agentscope-ai/agentscope
论文:AgentScope: A Flexible yet Robust Platform for Building Multi-Agent Applications
(Alibaba Cloud Team, arXiv:2402.14034, 2024)
由阿里云推出的 AgentScope 是面向企业级场景的Multi-Agent框架,主打 鲁棒性、多模态与分布式能力。
AgentScope 框架的核心是其 分布式 Actor 架构与中心化调度机制。每个智能体(Agent)作为一个独立的 Actor 运行,拥有自己的状态、工具集和通信通道;同时,系统提供统一的消息总线和任务调度器,确保多个 Agent 能在跨节点环境下高效协同。开发者可以通过简洁的 Python API 定义 Agent 行为,并利用内置的容错重试、超时控制等机制提升系统稳定性。
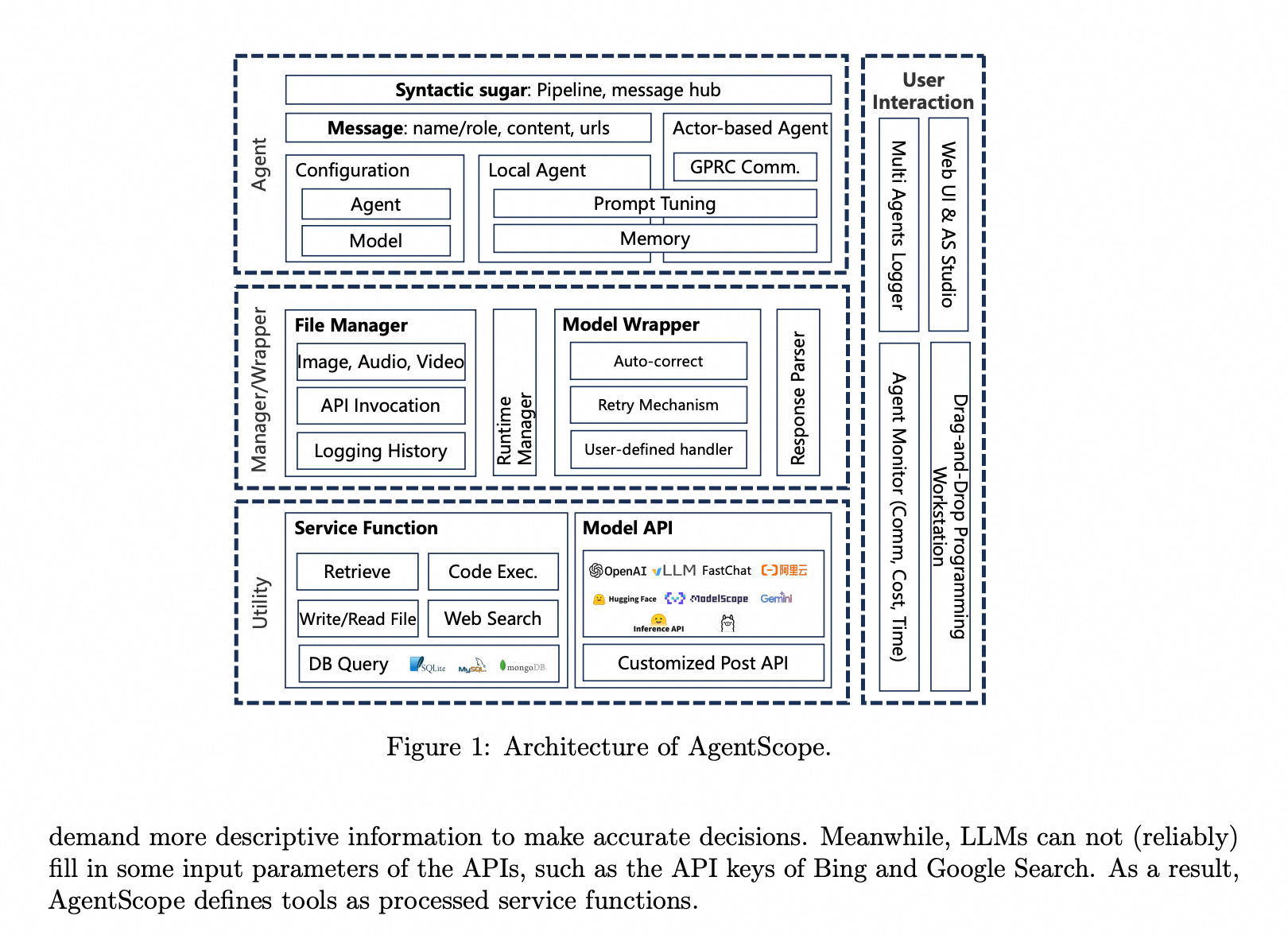
AgentScope 通过将底层通信、状态管理和执行环境标准化,大幅降低了多智能体系统的开发门槛。无论你是想构建一个能实时响应玩家行为的游戏 NPC 群体,还是搭建一个自动生成短视频的创作流水线,AgentScope 都提供了坚实可靠的运行时基础。更重要的是,它全面兼容 MCP(Model Context Protocol)等新兴工具协议,确保你的智能体能轻松接入未来生态。
当前,AI Agent 正从实验室走向产业一线,逐步渗透到各类应用场景中。正如业内一句调侃所言:“十个 AI 应用里面,五个是办公 Agent,三个是 AIGC,还有两成是回春的数字人。” 这虽略带戏谑,却也真实反映了当前 Agent 落地的主要方向。
整体来看,Agent 的应用可归纳为两大范式:自动化(自主智能体) 与 拟人化(智能体模拟)。前者强调任务执行的自主性与效率,后者则聚焦于交互体验的人格化与情感共鸣。
作为 Agent 技术的重要载体,AIGC 已广泛应用于内容生产链条:从文生文、文生图、图生视频,AIGC工作流,再到多轮对话驱动的AIGC生产助手,Agent 不仅能生成内容,还能根据上下文动态调整策略,实现“有目标的内容创作”。
在企业提效场景中,办公 Agent 正成为新生产力引擎:
- NL2SQL:自然语言直接生成数据库查询语句,降低数据使用门槛;
- Copilot 类(如 text2API、text2Code):将开发需求转化为可执行代码,加速软件工程流程;
- 办公助手:Agent 可自动完成邮件撰写、会议纪要整理、日程协调等重复性事务,真正实现“工作流自动化”。
面向特定行业的垂直 Agent 正在教育、零售、电商、房地产、旅游等领域快速落地。例如,教育 Agent 可根据学生答题行为动态调整教学路径;电商客服 Agent 能结合用户历史偏好推荐商品并处理售后;旅游 Agent 则可一站式规划行程、比价、预订。这些应用不仅依赖大模型的语言能力,更需深度融合行业知识库与业务逻辑。
- 泛化问题:当前 Agent 多运行于封闭或半结构化环境(如网页、API、数据库),缺乏与物理世界的“具身交互”。一个能浏览网页的 Agent,是否只需更换接口就能操控无人机编队?答案显然是否定的。现实世界的不确定性、延迟反馈与多模态感知,仍是 Agent 泛化的巨大障碍。
- 交互循环陷阱:为了完成任务,Agent 需要与环境进行大量复杂多步的交互,而一些研究也表明 Agent 很有可能会陷入到无意义的空转中——不断尝试却无法推进任务,不仅浪费计算资源,还产生海量冗余日志,给存储、检索与调试带来新负担。
- Agent 的评估:如何客观的评估一个 Agent 的能力也将是 AI Agent 发展带给我们的新问题,想想几年前 NLP 时代的数据集刷榜的评估方式,这种传统评价方式必然不适用于一个不断与外部环境打交道的 Agent。此外,一个做对了 99 步但生成答案错误的智能体的能力可能要优于一个做错了 99 步但生成答案正确的智能体,因此 Agent 评价也呼唤除了评估执行任务的成功率以外的新指标、新方法。
读到这里,希望你对当前主流的 AI Agent 概念已经有了一个相对系统的认识。
当然,Agent 技术远未成熟——在落地过程中,依然面临效率、可靠性、评估和安全等多重挑战。但正是这些尚未解决的问题,让这个领域既充满不确定性,也蕴藏着巨大的可能性。
如果你对相关内容感兴趣,后续我会在 《AI Agent 入门指南》系列专栏 中持续更新,带大家一起深入:
- 从 LangChain 入门到实战开发
- Agent 工具调用机制(MCP / Function Calling)详解
- Dify、扣子、Manus、Flowith 等热门 Agent 产品的对比与实战
- 企业级 Agent 系统的架构设计与权衡
- 甚至手把手从零复现一个可运行的多智能体协作流程
声明
- 所有文章都为本人的学习笔记,非商用,
- 目的只求在工作学习过程中通过记录,梳理清楚自己的知识体系。
- 文章或涉及多方引用,如有纰漏忘记列举,请多指正与包涵。
AI Agent是RL强化学习中的概念,跟大模型基本无关。
所以按照定义来讲:
①未经微调的基础LLM,不是人工智能。
②经过SFT调教的LLM,也不是人工智能,但可以叫专家系统,国产模型基本都是这一类型。
③在SFT基础上,经过RLHF弱强化学习,有点AI的味儿了,这种RLHF LLM有一定的自主性,弹性大,思维活络,拟人性高,最典型的就是安索佩克的克劳德(我是不是应该称之为Anthropic Claude?)
④更高浓度的强化学习,这就可以被称为Agent了,比如OpenAI的o1。这种RL LLM的自主性就非常强了。它们是一种“自我提示”的Agents,也是目前最接近“通用Superintelligence”的存在。
⑤所以,Agent是那种吃了很多强化学习,在目标领域明显超过人类的存在。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/242015.html