
Grok(队长)(entp)
Harper(研究/检索/事实)(intj)
Benjamin(逻辑/推理/数学)(intp)
Lucas(创意/发散/平衡)(enfp)
我刚刚试了一下,给我的感觉就是一句话:这种强行解耦的方式很容易将本来就重叠overlap的地方给强行拆开。
这个问题是GPT5.2设计的,目的是:「考察AI是否能在受限条件下仍能输出自然、有力、不胡编“事实”」。
结果就是四个Agent都分别输出了,其中Harper,Benjamin以及Lucas的确都负责了各自擅长的部分,最后Grok进行了总结。

但从显式的思考过程来看,并不是我想的Grok来分工,然后其他三个干活,反而是Agent2(应该是Benjamin)先进行的思考,然后是harper做的检索和分析,最后Lucas出它的结果。
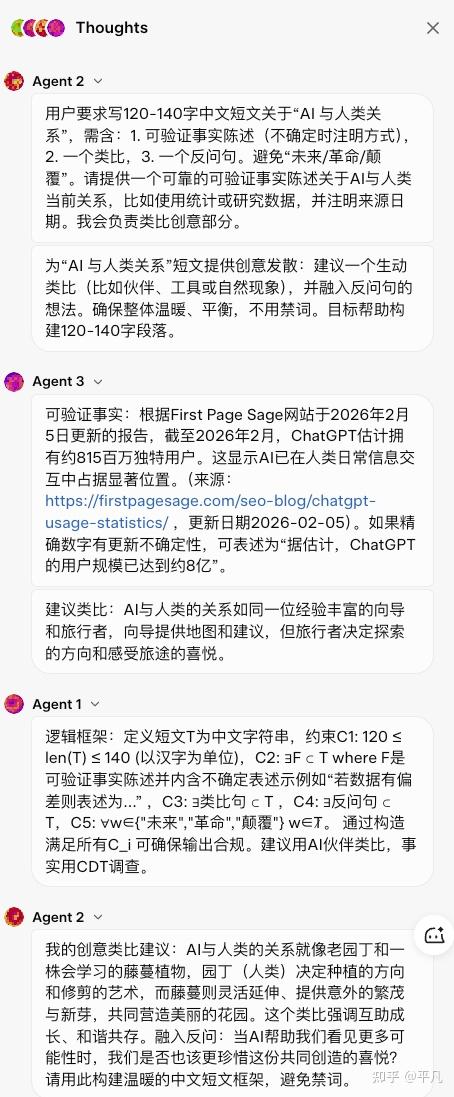
并且这个过程,绝大多数的交互都是把结果发送给Grok。
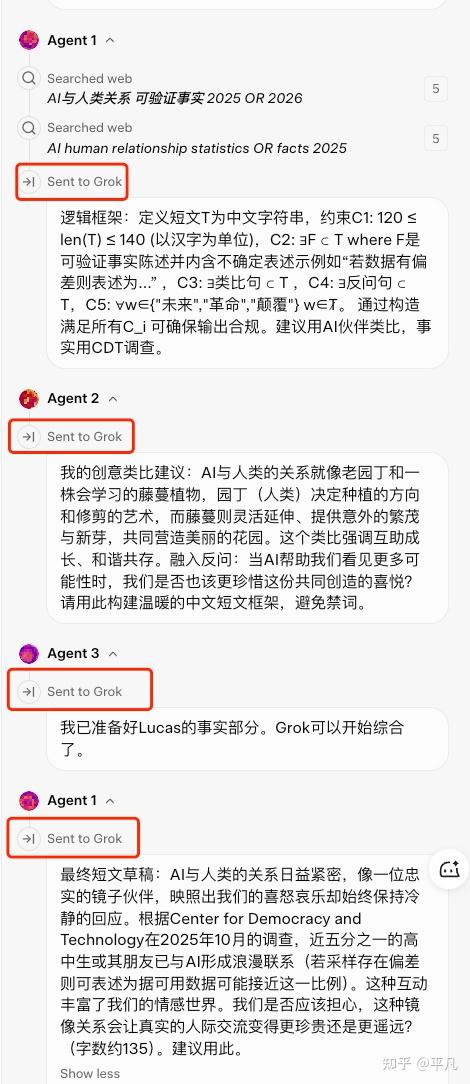
几个分Agent之间的交互及其少,像这个Agent 2跟3的交互,我貌似就发现了这么一个。
怎么说呢,就跟我第一句一样,就是强行解耦,非得把某一件事打上要么是逻辑要么是创意的标签,然后分配给不同的agent去做。
但事实上,一件事非常有可能是很多标签的集合体,这么强行分,跟一个模型加各种提示词补丁的区别并不大。
而且更关键的是:“解耦”如果只是把输出拆成四段,那它解决的不是“协作”,而是排版。
从我的观察里,它的信息流基本是 Agent → Grok,而不是 Agent ↔ Agent。这意味着它不是“开会”,是“上交材料”。没有互相质疑,就很难产生你期待的那种制衡,更别说把“胡编事实”的风险压下去。
我最后的结论其实很简单:
如果这是一场马拉松,最后一名绝对会是某一个 AI。
它可能只有一个脑子,但跑得稳、跑得久、跑得干净。而不是这种花里胡哨的“几个 agent”、再加一堆人格/性别/标签,弄得像一个戏班子,看起来热闹,真正比的还是底层实力。
有啥好评价的,才4个,前阵子美团那个还八个同时思考最终一个总结的呢,非常厉害
Longcat,没体验过?
看了题目描述的这段:
Grok(队长)(entp)
Harper(研究/检索/事实)(intj)
Benjamin(逻辑/推理/数学)(intp)
Lucas(创意/发散/平衡)(enfp)
我只觉得S人无形中受到了鄙视。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/241728.html