
最近我发现一个有趣的现象:很多人跟风安装了OpenClaw,配置好了模型渠道,却在"技能市场"(ClawHub)里挑花了眼。
下载了几十个Skills,结果发现——用起来并不顺手。要么是功能太通用,跟自己的实际工作流对不上号;要么是权限太大,安全性让人心里发毛;要么就是水土不服,各种报错。
这其实是一个必然阶段。OpenClaw的核心优势不在于它自带多少工具,而在于它的Skills(技能)系统 ——你可以把它理解成一个"可插拔的工具箱"。别人写的技能再好,那也是别人的工作流;真正能让AI成为你"私人助理"的方式,是自己动手写Skills。
那这篇文章,我会从三个层面彻底讲清楚这件事:第一,为什么我建议自己写 Skills;第二,怎么写 Skills(从格式到心法);第三,怎么让小龙虾帮你写 Skills(高级玩法)。最后,我会分享一个我自定义的skills案例——批量阅读文献、自动生成笔记、同步到本地Obsidian。
你去ClawHub(OpenClaw官方技能市场)逛一圈,会发现一个有意思的现象:下载量最高的那些技能,往往不是最好用的 。这听起来有点反直觉,但仔细想想其实很好理解。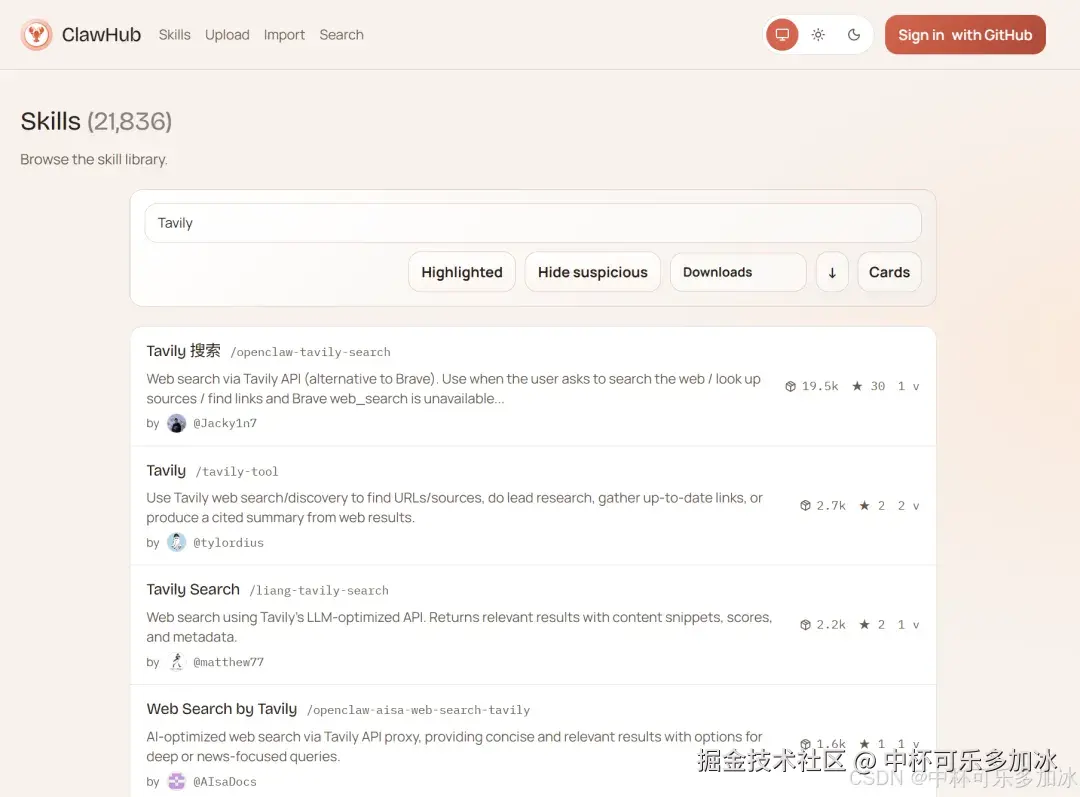
以Tavily搜索为例,这是一个联网搜索技能,号称"AI Agent标配"。装上之后,你确实可以让小龙虾帮你查资料、搜新闻。但问题来了------如果你想让它查的是你公司内部的知识库 、特定的行业数据报表 ,甚至你个人笔记里的某个片段,Tavily完全帮不上忙。它只会搜公开的互联网内容。
这就是"通用技能"的尴尬处境。它们像是一把瑞士军刀,什么都能干,但什么都不精。
第一,精准匹配你的工作流。
你自己写的Skill,可以精确到你电脑里的某个文件夹路径、你API的认证方式、你团队内部的协作规范。比如,你可以写一个Skill,专门读取你公司飞书多维表格里的销售数据,然后自动生成周报。这个需求,让别人写的通用Skill来实现,可能需要Token烧了半天还不见得能跑通。
第二,安全可控,不用把数据交出去。
这是最容易被忽视但最重要的一点。为什么要强调"本地部署"?因为很多通用Skill需要把你的数据发送到第三方服务去处理。你愿意把自己的财务报表、客户隐私、论文笔记都上传到别人的服务器吗?自己写Skill,你可以完全控制在本地执行,所有敏感数据不出本地机器。最近的数据安全形势有多严峻,大家心里都有数。
第三,成本可控,上下文更高效。
用过AI的人都遇到过这种情况:丢给AI一篇50页的论文让它总结,结果上下文窗**了,输出质量大打折扣。自己写Skill,可以先把论文在本地用Python脚本提取关键信息,做成精简版再喂给AI------token消耗能省下一大半。这个账,积少成多是相当可观的。
在说怎么写之前,先来搞清楚Skills到底是什么。
OpenClaw的Skills系统与Anthropic提出的AgentSkills 规范高度兼容。从技术上说,一个Skill就是一个文件夹,里面最核心的是一个叫SKILL.md 的文件。这个文件使用YAML frontmatter(就是文件开头的元数据区域)加上Markdown正文,定义了AI在什么场景下应该怎么干活。
OpenClaw官方文档明确指出:Skills采用三层渐进式信息披露系统(Progressive Disclosure)来优化运行效率。这个设计非常聪明,它避免了把所有细节都塞进上下文窗口里,导致AI"消化不良"。
- L1层:元数据(name、description等基础信息)。这部分会始终预加载到系统提示词中,让AI知道"什么时候该叫我"。
- L2层:主体说明(SKILL.md正文)。只有当AI判定当前任务与该Skill高度相关时,才会完整加载这一层。这里包含完整的执行指令和工作指导。
- L3层+:扩展资源。可以包含forms.md、reference.py等附加文件,按需动态加载。
这种设计确保了效率与灵活性的平衡------既不会让AI"瞎子摸象",也不会让它"负重前行"。
让我们来看一个最简单的Skill长什么样。这是一个叫"hello"的演示Skill:
就这?这也太简单了吧?没错,这就是Skill的最小形态。但它揭示了一个核心原则:Skill本质上就是一段文本指令,告诉AI在什么场景下该怎么响应。 上面的例子太简单了,我们来看一个真正能"干活"的Skill该是什么样子。以下是一个"每日技术日报"Skill的简化版本,它会调用工具来获取并整理信息:
GPT plus 代充 只需 145 这个例子展示了几个关键点:
- 清晰的触发条件:告诉AI什么时候该用这个Skill
- 具体的执行步骤:一步一步该做什么,甚至细化到用哪个工具、搜什么关键词
- 输出格式规范:输出什么样的Markdown结构,方便后续自动化处理
Anthropic在2025年底发布的《Skills编写完整指南》(33页)中,
提炼了几个核心原则,我结合自己的实践经验总结如下:
原则一:简洁至上(Concise is key)
上下文窗口是有限的。写得越啰嗦,AI越容易"迷路"。能用一句话说清楚的指令,不要用一段话。一个Skill只专注做一件事,不要试图搞一个"巨无霸" 。
原则二:保持原子化(Atomicity)
每个Skill应该是一个独立的功能单元。写一个Skill做"读PDF并总结",就不要再让它同时做"同步到云端"。把复杂任务拆解成多个Skill,然后让AI自己组合使用------这才是正确姿势。
原则三:场景描述要精准(Trigger clarity)
很多新手写Skill最容易犯的毛病就是:触发条件写得模棱两可。"当用户需要帮助时调用这个Skill"------这种描述等于没说。你应该明确写出:用户说出什么具体的话、或者提出什么具体需求时,AI应该启用这个Skill。
这是本文最"硬核"的部分,也是我认为最有价值的部分。
你不需要自己从头写所有代码。你需要做的,是提供足够清晰的上下文和规范,让AI帮你生成符合要求的Skill代码。
这个思路类似于"提示词工程"(Prompt Engineering),但更进了一层------你不是在让AI回答问题,而是在让AI生成可执行的代码和配置文件。
要让小龙虾帮你写出可用的Skill,你需要告诉它三件事:
第一类:API接口规范(API & Return Format)
如果你的Skill需要调用外部API(比如调用你公司的内部接口、或者某个第三方服务),你得把API的调用方式、参数格式、返回数据结构原原本本告诉AI。
示例Prompt:
第二类:安全规范(Security Constraints) 这一步至关重要。你必须明确告诉AI,哪些操作是绝对禁止 的,哪些权限不应该授予。否则,它生成的代码可能会有安全漏洞。
示例Prompt:
GPT plus 代充 只需 145 第三类:执行步骤(Step-by-Step Instructions)
告诉AI,这个Skill需要分哪几个步骤来执行。每个步骤的输入是什么、输出是什么、中间状态如何处理。
示例Prompt:
综合以上,我给你一个可以直接抄作业的Prompt模板:
终于到了最激动人心的实战环节。
我要实现的场景是:让小龙虾批量读取学术论文/文献,自动提取关键信息生成阅读笔记,然后通过坚果云WebDAV推送到本地Obsidian库中。
这个需求对于做学术研究、或者需要大量阅读文献的朋友来说,应该不陌生。每次读到一篇好论文,都要手动复制粘贴到Obsidian里,标注作者、日期、核心观点------重复性工作做多了真的会怀疑人生。
先来梳理一下整个流程:
按照我们之前学的知识,先来写这个Skill的SKILL.md文件(这个md其实也是小龙虾自己写的,仅供参考):
光有Skill描述还不够,我们需要实际的Python代码来执行具体操作,(这个脚本也是小龙虾给我写的,仅供参考),以下是实现核心功能的代码框架(可以直接放到Skill的skills/目录下):
在运行这个Skill之前,你需要完成以下配置步骤:
第一步:安装Python依赖
懒得自己动手安装,这里也可以叫小龙虾给你安装
GPT plus 代充 只需 145 第二步:在坚果云生成应用密码
- 登录坚果云网页端
- 点击右上角账户名 → 账户信息
- 选择"安全选项"标签页
- 点击"添加应用",输入应用名称(如"OpenClaw论文同步")
- 生成后立即复制保存——这个密码只会显示一次
第三步:在Obsidian中创建笔记仓库
- 打开Obsidian,新建一个仓库(或者使用现有仓库)
- 在仓库根目录下创建一个文件夹,命名为(这个名字可以改,但要跟Skill配置里的对应)
第四步:配置OpenClaw环境变量
在OpenClaw的配置文件中添加刚才创建的环境变量,或者在启动小龙虾时通过命令行参数传入。
完成以上配置后,你就可以这样使用这个Skill了:
- 找到几篇PDF论文,把它们放到一个文件夹里
- 对小龙虾说:"帮我把这几篇论文导入Obsidian"
- 小龙虾会自动调用这个Skill,读取PDF、提取信息、生成Markdown笔记
- 打开Obsidian,等待坚果云同步完成——你会发现笔记已经静静地躺在你的文件夹里了
整个过程,从点击执行到笔记出现在Obsidian里,通常只需要几十秒钟 。而且所有的处理都在本地完成,你的论文内容和笔记数据不会被上传到任何第三方服务器。
写到这里,我想再次强调一下核心观点:用好AI Agent的关键,不在于你装了多少现成的Skills,而在于你能不能把自己的工作流"翻译"成AI能理解的指令。
OpenClaw之所以强大,不是因为它自带了多少工具——那些工具你花点时间自己也能写。它真正的价值在于,它给了你一套"封装经验"的机制。你把自己多年的工作经验、行业知识、流程规范,写成一个个Skill加载进去,然后你的AI助手就开始"继承"你的能力了。
而且,最妙的是——你不需要一次性写对。就像带孩子一样,AI也是在"犯错-修正-成长"中逐渐变强的。每次它做得不对,你纠正它,它就会记住。积累一段时间之后,你就会发现,它越来越懂你、越来越顺手。
2026年,AI Agent的爆发已经是板上钉钉的事实。从Meter机构的数据来看,AI独立干活的时长已经从2024年的几分钟暴涨到2025年的5-10小时,每7个月就翻一番。这个速度意味着什么?意味着你现在不开始学习怎么定制自己的AI助手,几年后可能真的会被甩得尾灯都看不见。
所以,别再犹豫了。装上小龙虾,写下你的第一个Skill——管它写得怎么样,先跑起来再说。完美的Skill是改出来的,不是想出来的。
祝你养虾愉快。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/237833.html