
最近在研究给 OpenClaw 配置一个更强悍的记忆系统,后面发现 OpenClaw 开始支持 qmd 作为记忆后端,于是自己在本地琢磨了一下,发现配置还是有些门道的,就写篇博客吧。
qmd 是一个本地化的搜索工具,结合了 BM25 全文搜索、向量语义搜索和 LLM 重排序,关键是模型都能本地运行,不需要联网!
- 设备:Mac mini M4
- 内存:
- GPU:
- 系统:
- OpenClaw 版本:
- qmd 版本:
1.安装 bun
qmd 官方推荐用 运行,我刚开始用 安装出现了兼容性问题( 版本),但是目前 qmd 在最新的 中兼容了 的兼容性问题,同学们可以尝试用 装下。
GPT plus 代充 只需 145
2.安装 qmd
3.下载模型文件
从 HuggingFace 下载官方示例中的 个 GGUF 模型文件,放到 目录:
虽然官方支持在首次启动 qmd 时自动下载这三个模型,但是国内特别特别慢,即使你配置了代理,也很慢,会一直出现转圈圈处在 的状态,建议直接开代理在网页上下载。
如果你只想用 qmd 的 关键词搜索能力,那么只需要下载第一个模型,但是这也失去了装 qmd 的意义。
4.源码修改与环境变量配置
qmd 官方默认只支持为向量模型指定本地路径,不支持为结果重排和查询扩展模型设置,这里我看官方源码,最终找到了可以配置的地方,目前已经提交了 ,看官方是否会合并吧。
修改 qmd 源码,文件路径参考:
通过 进行定位,找到下面这段代码,把我这段覆盖上去就好了。
GPT plus 代充 只需 145
源文件路径可能不一样,注意使用自己本地的路径。
修改完成后,配置环境变量,在 中添加:
本地的模型位置注意使用自己的,变量名称需要与源码中修改的进行映射,最后执行 让环境变量生效。
5.OpenClaw 配置
大家如果想要自己配置的话,可以参考 OpenClaw 的官方文档 —— Memory 进行配置,这里给一版我的示例。
打开 OpenClaw 的配置文件:
在开始修改前,建议先备份当前的配置文件,然后再开始修改。
5.1.memorySearch
配置 JSON 路径:
GPT plus 代充 只需 145
为了避免 JSON 格式问题,这里提供一个没有注释的版本,内容是完全一致的:
注意:这个配置在 模式下不生效,只在 模式下生效。
5.2.memory
配置 JSON 路径:
GPT plus 代充 只需 145
为了避免 JSON 格式问题,这里提供一个没有注释的版本,内容是完全一致的:
这里说一下搜索模式, 是用扩展模型自动对关键词进行衍生,然后进行混合搜索,最终进行重排序,按得分进行输出,但是如果 PC 性能不行的话,用 模式会很慢。
其次是 模式,就相当于百度的关键词搜索,所以抛开计算性能, 模式是更推荐的,要不然查询扩展的模型相当于没装。
配置方面可以自己看官方文档 memory docx 自由修改,我这里不做过多的叙述了。
配置修改完成后,记得重启网关:
GPT plus 代充 只需 145
6.生成向量嵌入
将你想要构建记忆的存储目录添加到 qmd 中:
开始构建向量:
GPT plus 代充 只需 145
首次运行会加载模型到 GPU,稍微需要等待一会儿,构建完成后,可以看状态:
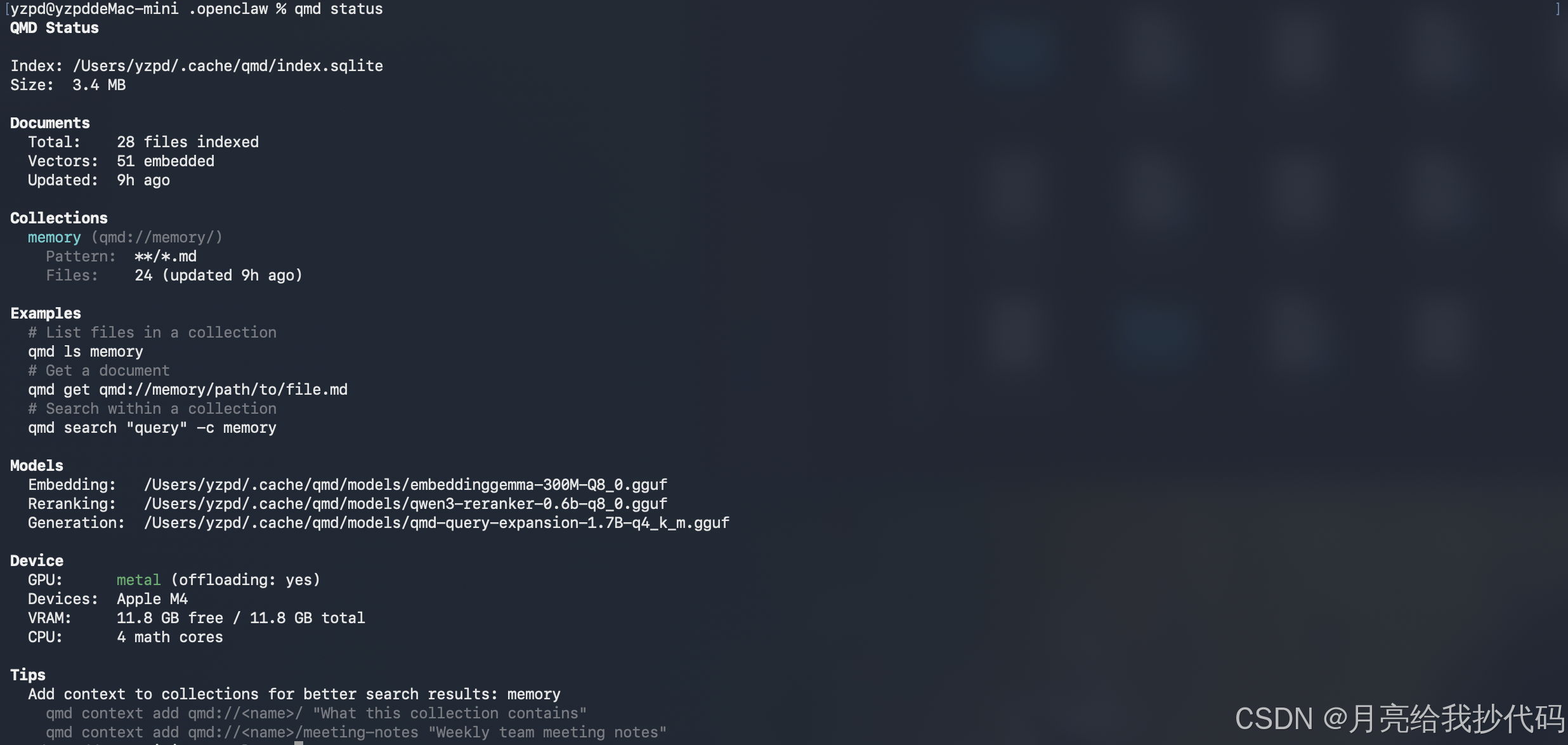
7.测试搜索
直接使用 qmd 命令进行测试:
GPT plus 代充 只需 145
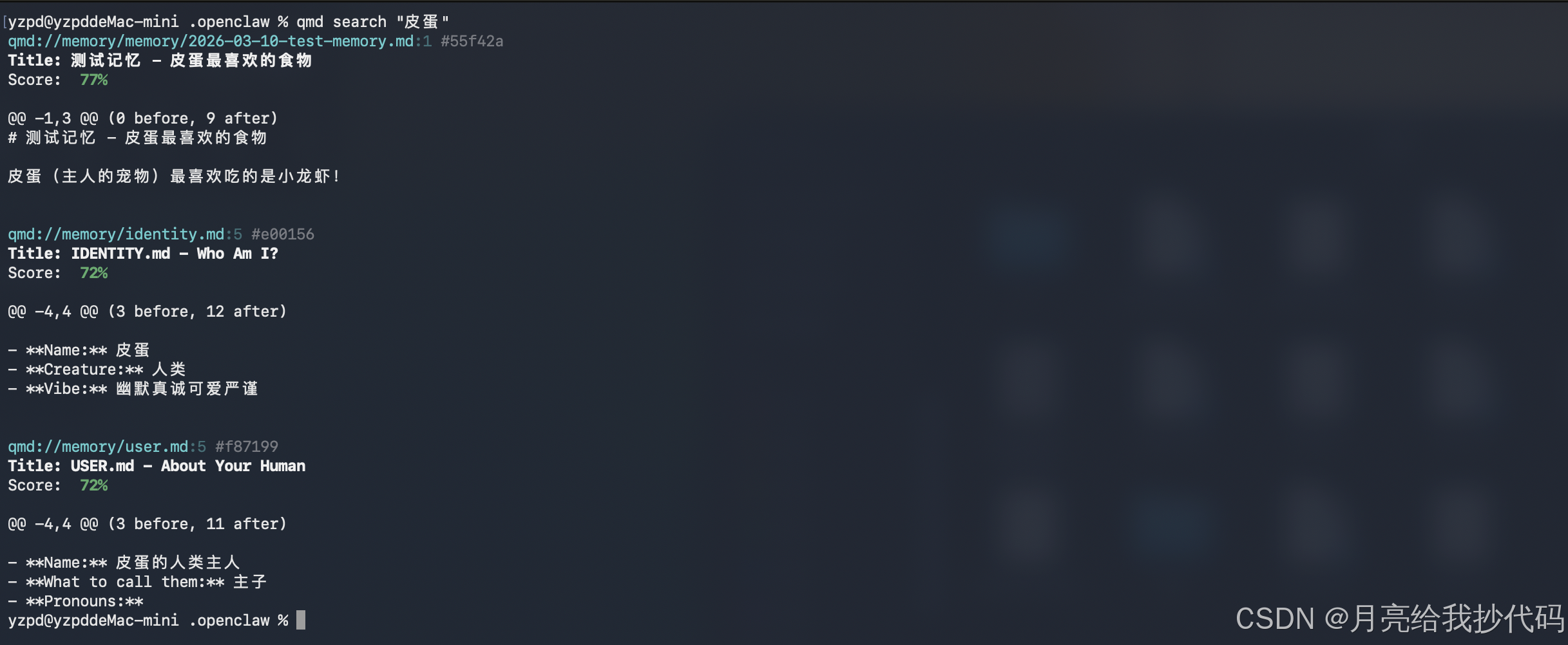
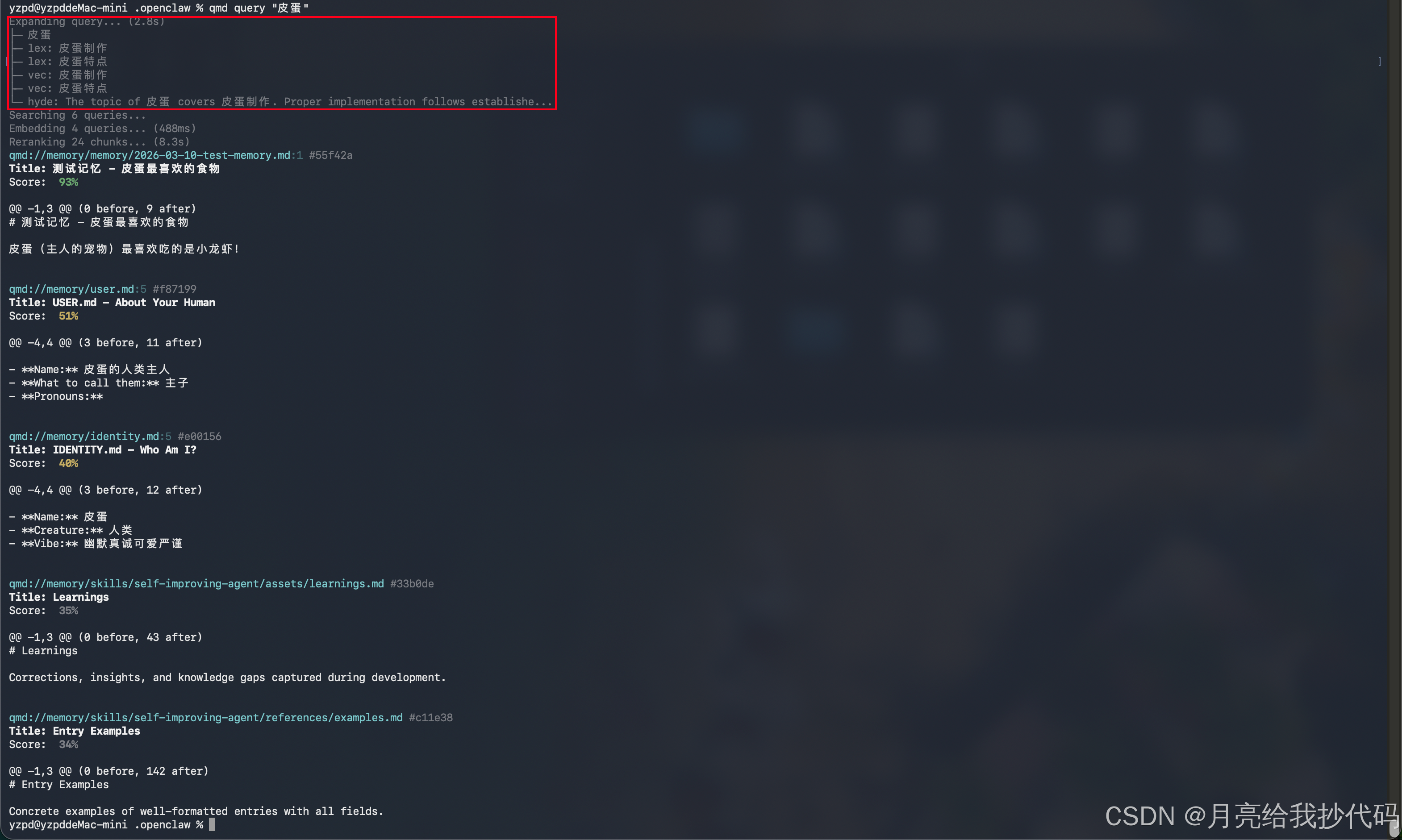
用 语义搜索时,可以从打印日志中看到,当我输入 关键词,qmd 先调用了语义扩展模型,花了 去进行关键词扩展,然后开始查询构建向量,最终进行重排序,得出结果,按照相关度排序输出结果。
上面是直接通过 qmd 命令去使用了,现在使用 OpenClaw 进行查询:
GPT plus 代充 只需 145
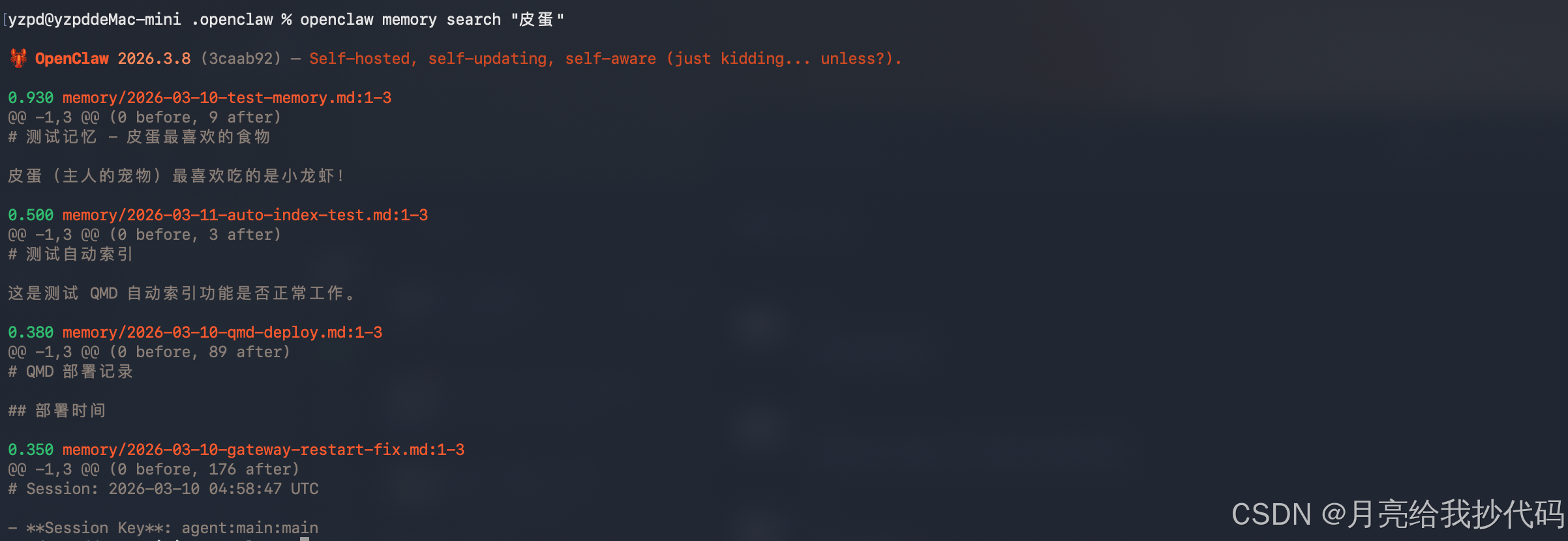
因为 OpenClaw 的 qmd 搜索模式在配置文件里面指定的是 ,所以这里直接用的就是语义搜索。
如果感觉搜索太慢,可以适当调低下面这两个配置项,JSON 路径引用如下:
在输出前,会先扩展到 个候选项,同时重排过后最多输出 条记录作为结果。
总体配置到这里就结束了,后面可以自己在 里面写一些规则,控制在哪些时机去写入或者加载记忆。
关于 qmd 使用与配置的更多内容,请参考 Github qmd & OpenClaw Memory Docx ~
8.补充 skill
qmd 版本中出了官方的 skill,可以直接通过下面的命令进行安装:
GPT plus 代充 只需 145
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/237829.html