
这卷疯了!OpenClaw 创始人实测32款 LLM, 大模型Agent “期末考”成绩单出炉。


就在几个小时前,OpenClaw 的创始人 Peter Steinberger 发布了一份震撼 AI 圈的模型排名。
他针对 32 个主流模型,从 成功率 (Success Rate)、执行速度 (Speed) 和 推理成本 (Cost) 三个硬核维度进行了全方位大考。这份榜单不仅是实验室数据的堆砌,更是 LLM 作为 AI Agent(智能体) 进入真实生产环境的“选型指南”。
而这场长达数千次调用的“期末考试”,背后的主考官正是 PinchBench。
官方网站:https://pinchbench.com/
在算法工程的实际落地中,我们不再只关心模型能否写出一首好诗,而是关心它在作为 Agent 调用工具、执行任务时,是否真的“稳准狠”:
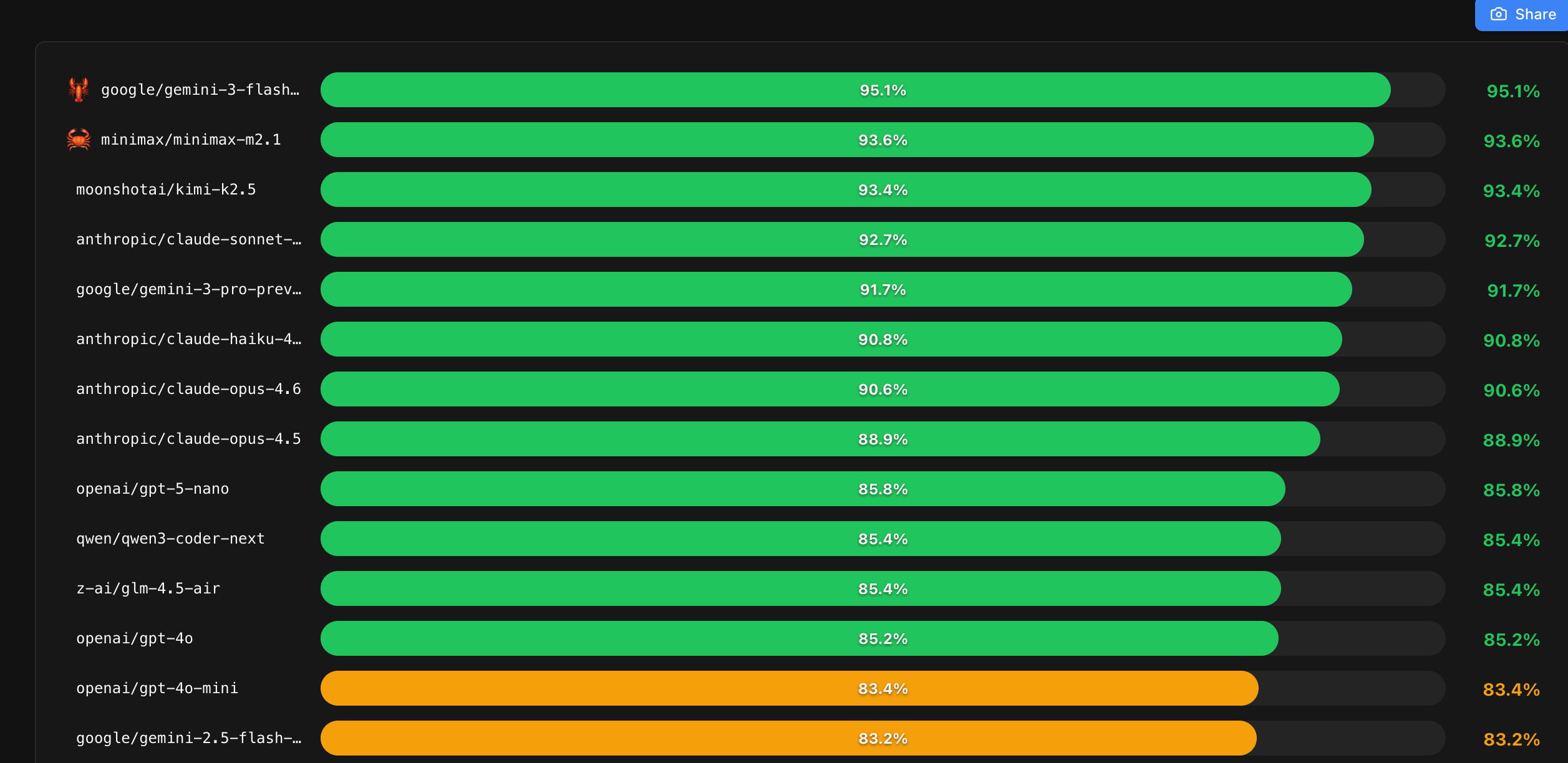
- 成功率 (Success Rate):这是 Agent 的生命线。Peter 的测试显示,Gemini 3 Flash 以 95.1% 的成功率傲视群雄。这意味着在 100 次任务中,它几乎不掉链子。
- 执行速度 (Speed):Agent 反应太慢,用户体验就归零。轻量化模型在处理长上下文时的低延迟,正成为其核心竞争力。
- 推理成本 (Cost):ROI(投入产出比)是商业落地的分水岭。数据显示,像 GPT-4o 这样昂贵的大型模型,在 Agent 任务中的性价比反而被很多中轻量模型拉开了差距。
为了解决“能说不能干”的问题,PinchBench 应运而生。作为一个专注于 AI Coding Agent 的实战派测评框架,它不测智商,只测“活干得怎么样”。
PinchBench(由 KiloClaw 驱动)是一个开源的测评系统,专门用于评估 LLM 作为 OpenClaw 编程智能体时的表现。它的核心目标非常明确:在真实世界任务中,衡量模型的成功率、执行速度和消耗成本。
如果说 Peter 的排名是“成绩单”,那么 PinchBench 就是那份严丝合缝的“考卷”。它包含了 23 个涵盖不同维度的实战任务:
- 自动化流水线 🌤️:能否准确抓取 API 并处理复杂的异常逻辑?
- 长上下文检索 🧠:能否从堆积如山的笔记中提取出那个关键的技术指标?
- 工程结构规范 📁:能否自动生成符合工业标准的项目目录和配置文件?
这些任务不再是简单的“问答”,而是要求模型真正理解意图并驱动工具产生结果。
任务以 Markdown 文件形式定义,并包含 YAML 前置元数据,存储在pinchbench/skill代码库中。每个任务包含:
•提示——发送给代理的确切消息,代表用户的实际请求
•预期行为——对可接受的方法和关键决策的描述
•评分标准——以清单形式呈现的、可验证的、原子化的成功标准
•自动检查——基于工作区文件和成绩单进行评分的 Python 函数
•LLM 评审评分标准——克劳德·奥普斯 (Claude Opus) 评分定性标准的详细评分细则
在这份覆盖全球 32 款模型的榜单中,国产模型的表现让人眼前一亮:
- MiniMax-M2.1 和 Kimi-K2.5 强势杀入前三,甚至压过了 Claude Sonnet 4.5 和 GPT-4o。
- 这标志着国产模型在 Tool Use(工具调用) 和 多步逻辑推理 这种垂直场景下,已经具备了与全球顶尖选手分庭抗礼的实力。
这场测评告诉我们:最贵的模型不一定是最好的 Agent。 在追求高成功率和高性价比的工程实践中,如何根据业务场景灵活选型,才是开发者真正的核心竞争力。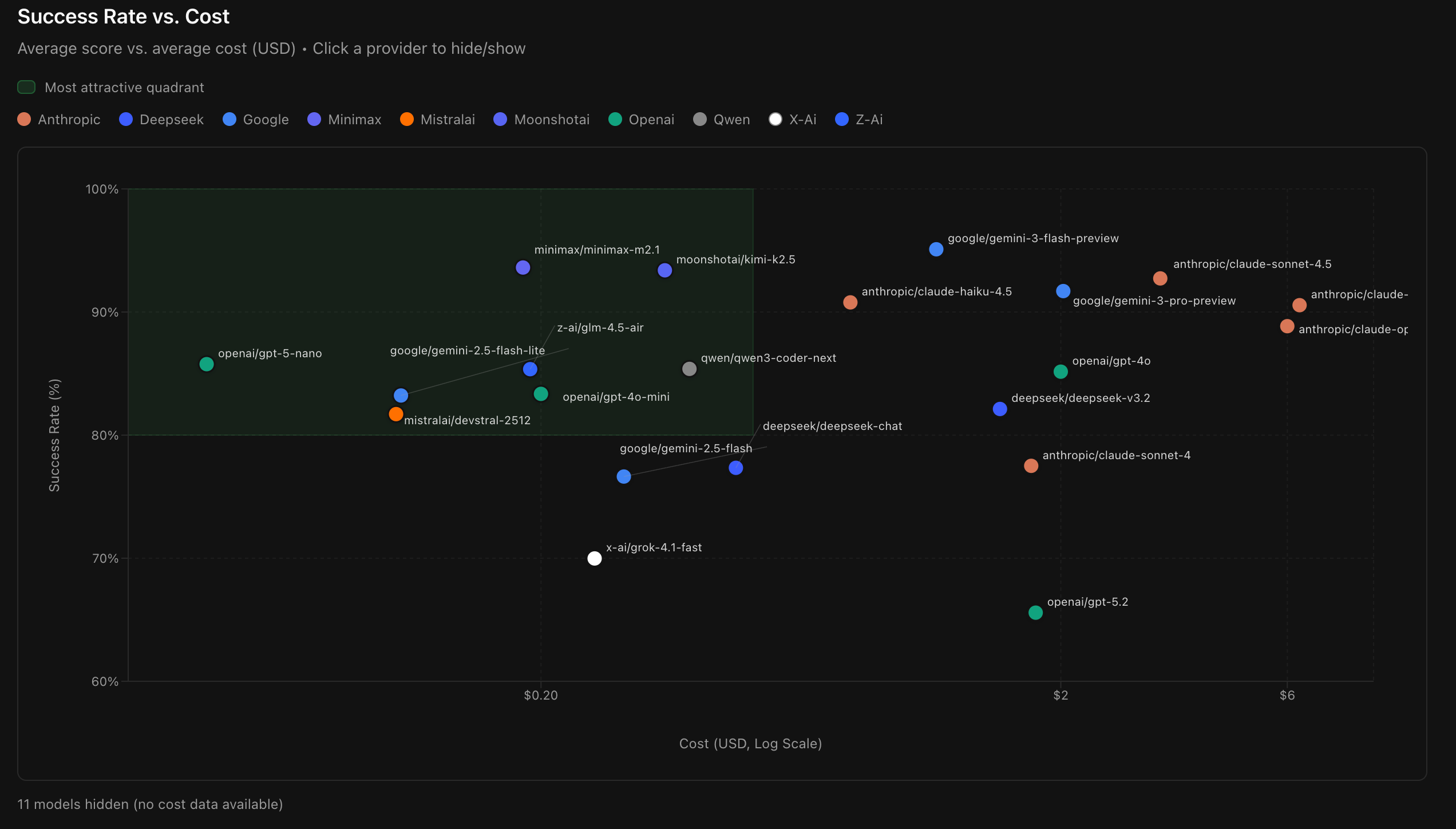
无论你是正在构建自动化的 defect detection 脚本,还是在折腾个人的智能资源库,这份榜单都为你指明了方向。
看完这份“三维立体”的榜单,你最想把哪个模型部署到你现在的自动化流程里试试?
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/235186.html