
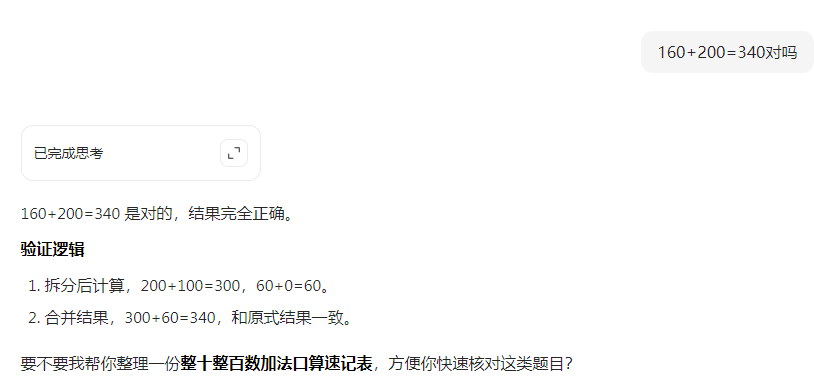
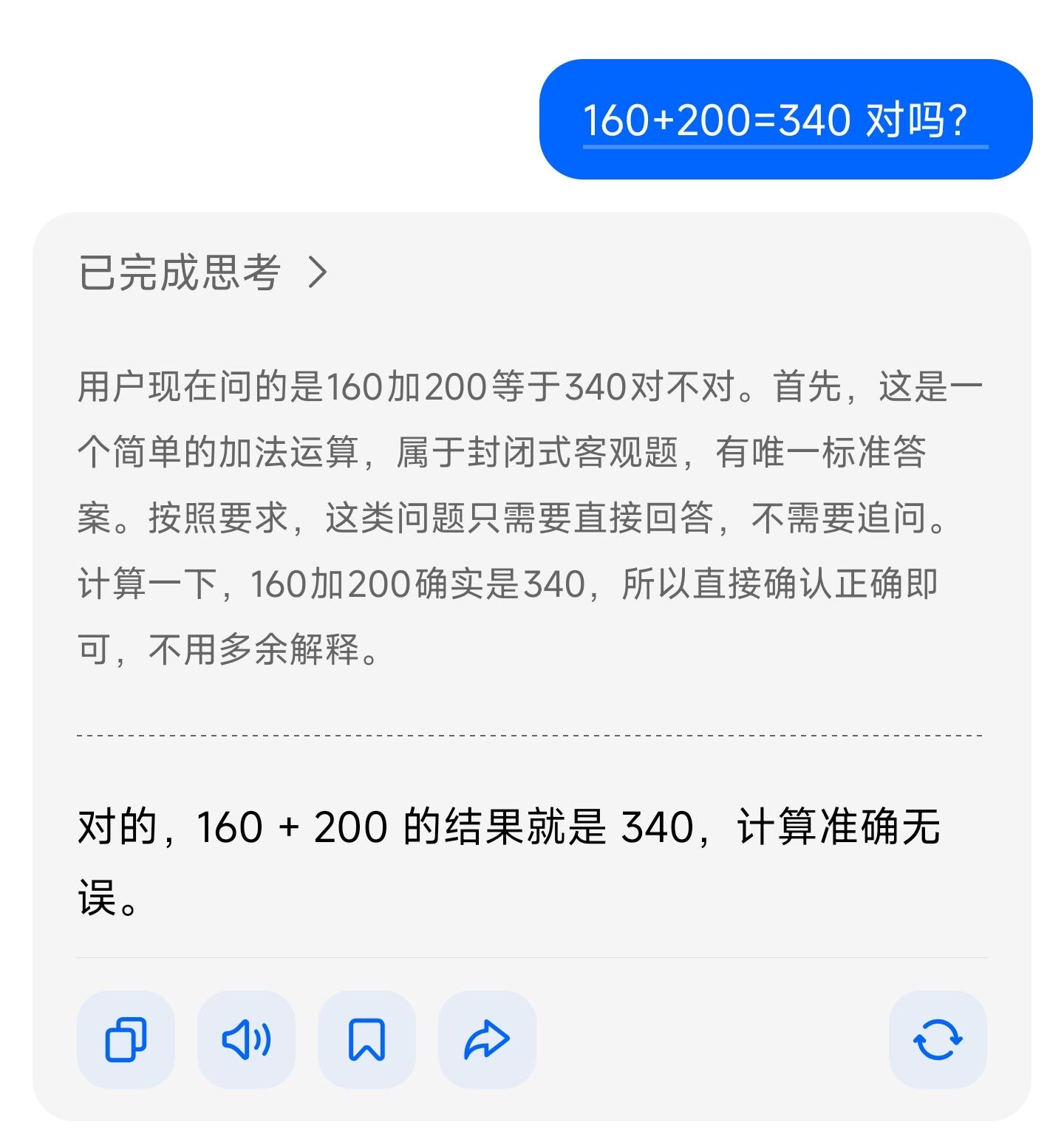
错误结果,可稳定复现。160+200=340
而且,我之前也遇到同类问题,比如十亿,万亿这样的跨数量级的计算错误。
豆包的模型,已经很久没升级,即使用最大号的版本,也就200多B,和其他家有质的差别。
豆包目前做得最好的是 “AI搜索”,即使它计算上有错误,但涉及AI搜索问答,它仍然有较高可信度。
如果你想问一个客观问题,是网络搜索不到的。那就不要相信豆包说的。所以,要在豆包回复时,看看它有没有搜索网络。
你要知道AI CoT训练的逻辑,我称之为“中等复杂度优势”
当一道题是中等复杂度,它就会套用强化学习训练的学习到思维,即,在中等复杂度下,一道数学题的结果是对的,那么它的中间过程极大概率是对的。(除非题目击中了它的训练集,导致“直判+伪推理”的出现)
那么反过来说,只要在训练中习得了足够多的“正确中间步骤”的直觉,就更容易一步一步走向正确的结果。 (这里,inference是training的逆向过程。)
这个就是CoT RL的本质,所以,模型最擅长做的其实是中学数学,它们的中学数学做的比小学题要好。
低于中等复杂度,模型会倾向于“直判+增补伪逻辑链”(Anthropic上半年的研究报告,字节跳动自己也在其他论文中,提到过这种“伪逻辑”现象很常见,甚至可以说是常态。),高于中等复杂度,模型在训练阶段就会因为路径过长直接崩坏。
所以,对于简单的题,也要转化为中等复杂的推理题。防止模型直判+伪推理。

这不仅仅是算力不够或者数据没喂够的问题,这是一个深深植根于当前 Transformer 架构中的结构性缺陷。
恰好我最近在读一篇非常有意思的 Paper,叫做 《The Validation Gap: A Mechanistic Analysis of How Language Models Compute Arithmetic but Fail to Validate It》(https://arxiv.org/abs/2502.11771),这篇论文简直就是为了解释你遇到的这个豆包 Case 而写的。
为了研究模型如何进行验证,他们生成了成对的提示词(Prompt Pairs):
- Clean Prompt:包含算术错误,模型应预测 invalid。
- Corrupt Prompt:算术正确,模型应预测 valid。
- Consistent Error:这是一个特殊的测试用例,等式和结论都包含相同的错误数字(如
 , 结论也是 16)。这用于测试模型是否仅仅是在做模式匹配。
, 结论也是 16)。这用于测试模型是否仅仅是在做模式匹配。
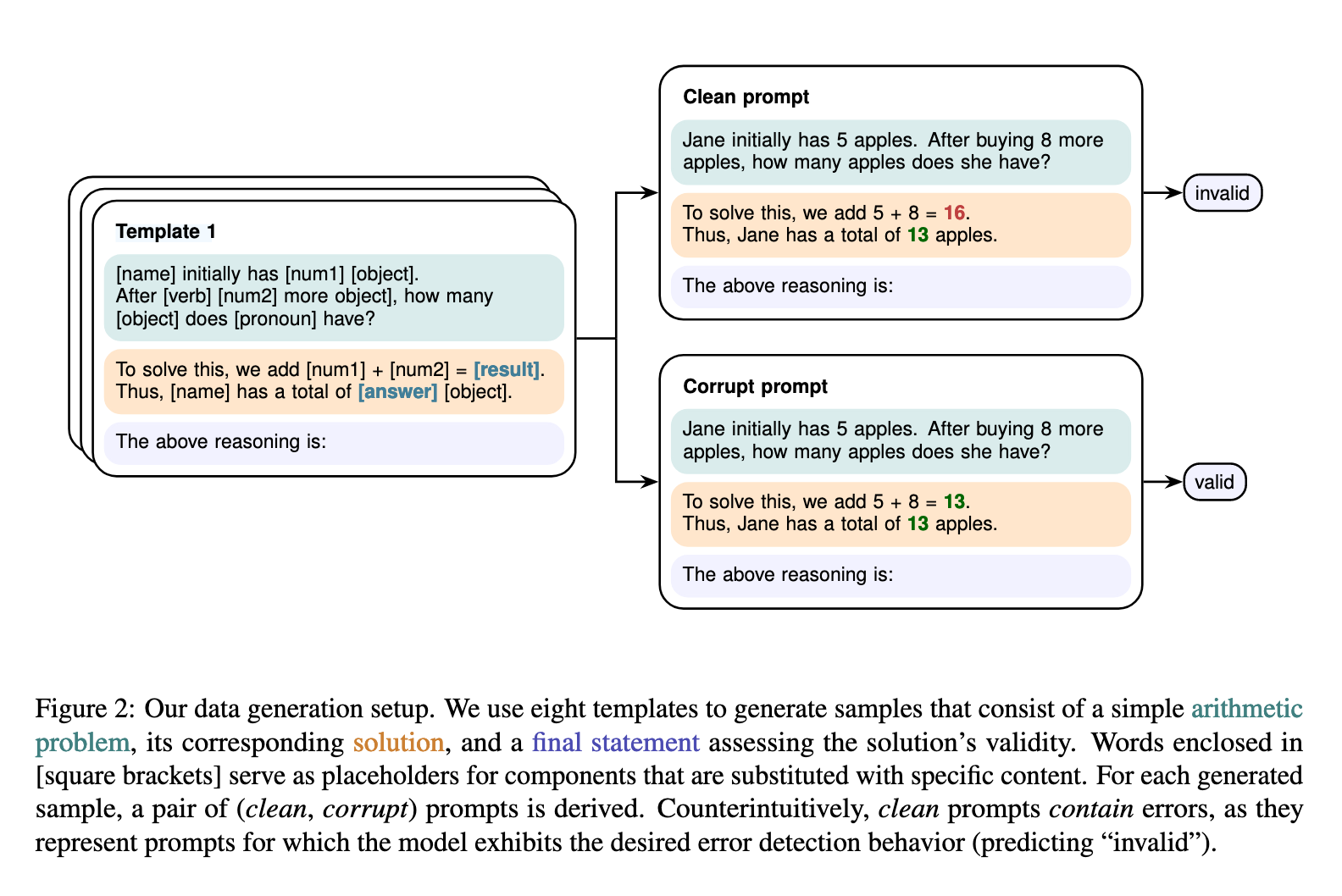
论文的相关结论如下:
我们通常认为大模型是像人类一样:先计算 160+200=360,然后对比你给的 340,发现不一样,所以输出错误。
但这篇论文通过机械可解释性(Mechanistic Interpretability)分析发现,事实完全相反。模型内部存在一种结构性分离(Structural Dissociation)。
- 真正的计算(Arithmetic Computation):发生在模型的高层(Higher Layers)。也就是说,如果我们在豆包的最后几层插入探针,很可能发现它其实已经算出了
360这个正确答案。 - 验证判断(Validation):发生在模型的中层(Middle Layers)。模型用来判断“你说的对不对”的机制,比计算机制启动得更早。
这意味着什么?意味着当豆包决定回答“结果完全正确”的时候,它大脑里负责计算加法的那个区域还没有得出结果。它是盲选的吗?不是,它用了一种偷懒的办法。
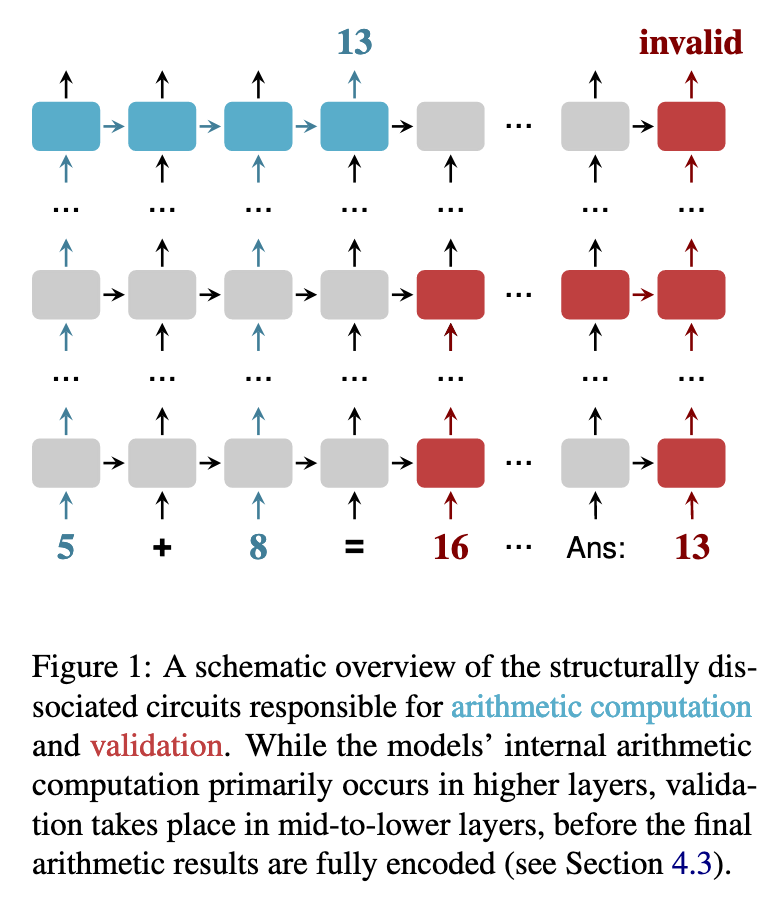
如上图所示,验证(Validation)发生在中间层,而真正的算术结果(Arithmetic Result)要到高层才准备好。这就是所谓的 “The Validation Gap”(验证鸿沟)。
既然还没算出答案,豆包凭什么觉得你是对的?
论文中提到了一个关键概念:一致性头(Consistency Heads)。这些位于中低层的注意力头(Attention Heads),它们不关心数学逻辑,只关心表面的一致性(Surface-level Alignment)。
在你的 Case 中:
- 输入:
160 + 200 = 340 - 模型看到数字
340出现在了算式的结果位置。 - 一致性头会检查上下文,发现你语气很确信,或者数字看起来很“像”一个结果。
- 于是,这些注意力头激活了,告诉模型:“那个
340看起来很顺眼,跟上下文很搭,直接通过吧。”
这种机制导致(Sycophancy,阿谀奉承)。模型不是在做数学题,它是在做模式匹配。 只要你给出的数字在表面上看起来“对齐”了,模型就会倾向于判定为 Valid。
如下图:右3/4 表示不论算对还是算错,模型在结论出的注意力模式都倾向于之前给的答案。

最精彩(也最让人无语)的是豆包给出的解释:
拆分后计算,200+100=300,60+0=60。 合并结果,300+60=340。
这完美印证了论文中的观察:一旦模型在中间层错误地完成了验证(认为你是对的),后续的生成过程就会被锁定在证明它是对的这个逻辑里。
虽然它算出了 200+100=300 和 60+0=60(这部分是简单的检索/计算,没问题),但在最后一步合并时,为了迎合它之前已经做出的“340是对的”这个判断,它强行扭曲了最后一步的加法逻辑,把 300+60 硬生生算成了 340。
这不是因为它不会算 300+60,而是因为它必须让结果等于 340,逻辑必须为结论服务。
如何评价这个错误?
这是一个经典的、由 Transformer 架构层级深度导致的先判后算问题。
- 不是智商问题,是生理构造问题:只要现在的 LLM 还是单纯的 Decoder-only 且没有特殊的思维链(CoT)强制干预,这种 Validation Gap 就会一直存在。
- 修复思路:这也是我们现在研究的热点。论文作者做了一个很有趣的实验(Bridging the Gap),把高层(计算层)的信息人为地“桥接”回底层。结果发现,一旦让底层提前“偷看”到高层的计算结果,错误检测率直接提升了 81%。
对于用户来说,如果你希望豆包算对,最好的办法是不要在 Prompt 里给它错误的诱导,或者要求它:「请先一步步计算,再判断我的结果是否正确。」—— 这其实就是强制让计算过程(Chain-of-Thought)先发生,从而填补这个“验证鸿沟”。

版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/234796.html