
Photo by Tweesak C. on Pexels
每次对话结束,AI agent 就会忘记一切。
这不是比喻。OpenClaw 的默认 把记忆写进本地 文件,当文件积累到上百个,agent 没有能力在每次对话前全部扫描——记忆变成了需要你主动提示才能检索的档案馆。
更根本的问题是:记忆无法跨 agent 共享。你告诉过主 agent 的偏好,coding agent 从零开始;每个 agent 都活在自己的信息孤岛里。
理想的 agent 记忆系统应该满足四点:自动注入、跨 agent 共享、新记忆实时可用、数据留在本地。
带着这四个要求,我开始寻找答案。这篇文章 介绍了 mem9 作为 AI agent 记忆方案的思路,给了我很大启发。但原文使用的是 mem9.ai 云服务——记忆数据存在远端。考虑到 agent 的记忆里沉淀着大量个人习惯、工作偏好和私人决策,这些数据不应该离开本机。因此本文在此基础上进一步,把整套系统搬到本地自托管。
调研阶段评估了两套方案,它们的设计哲学截然不同。
memsearch 的思路是向量索引:对本地 文件做 embedding,构建语义搜索能力。优点是部署简单,能在历史记忆文件中做精准的语义检索。但它有一个根本限制——注入是手动的。memsearch 本身没有 hook 机制,agent 需要主动调用 CLI 查询,无法做到对话前自动感知相关记忆。
mem9 的思路完全不同:它是一个独立的 memory server(mnemo-server),通过 REST API 管理记忆,并注册了 OpenClaw 的 hook。每次对话开始前,它自动提取上下文、搜索相关记忆、注入 system prompt——整个过程对 agent 透明。
核心差异对比:
最终选择以 mem9 为主、memsearch 为辅。两者互补:mem9 覆盖日常自动记忆,memsearch 处理需要在大量历史文件中深度回溯的场景。
最终落地的系统由四层组成,存储基于 TiDB(一款兼容 MySQL 协议的分布式数据库):
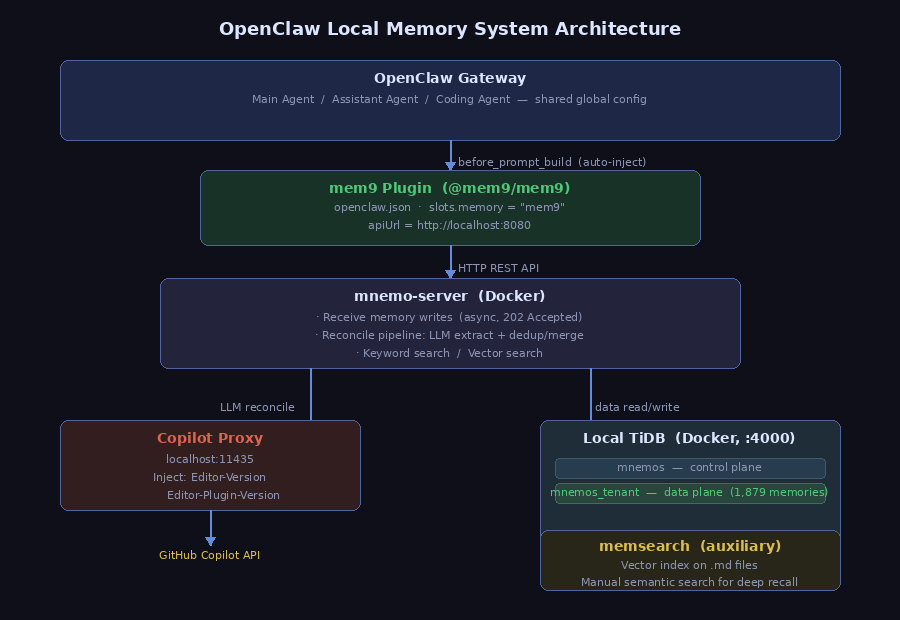
几个关键设计决策值得说明:
全局配置,三个 agent 自动继承。 mem9 配置在 的顶层 节点:
OpenClaw 不支持 per-agent 插件覆盖,但 mem9 内部通过 区分每个 agent 的记忆写入来源,逻辑隔离等同独立记忆。
控制平面与数据平面分离。 TiDB 里维护两个数据库,通过 SQL 将 tenant 指向本地:
存租户配置(控制平面), 存实际记忆数据(数据平面)。两者解耦,数据平面可独立迁移,不影响控制逻辑。
存储完全本地。 TiDB 和 mnemo-server 均以 Docker 容器运行在本机,没有任何数据离开本机。
读取侧由 负责,写入侧则由 hook 驱动。
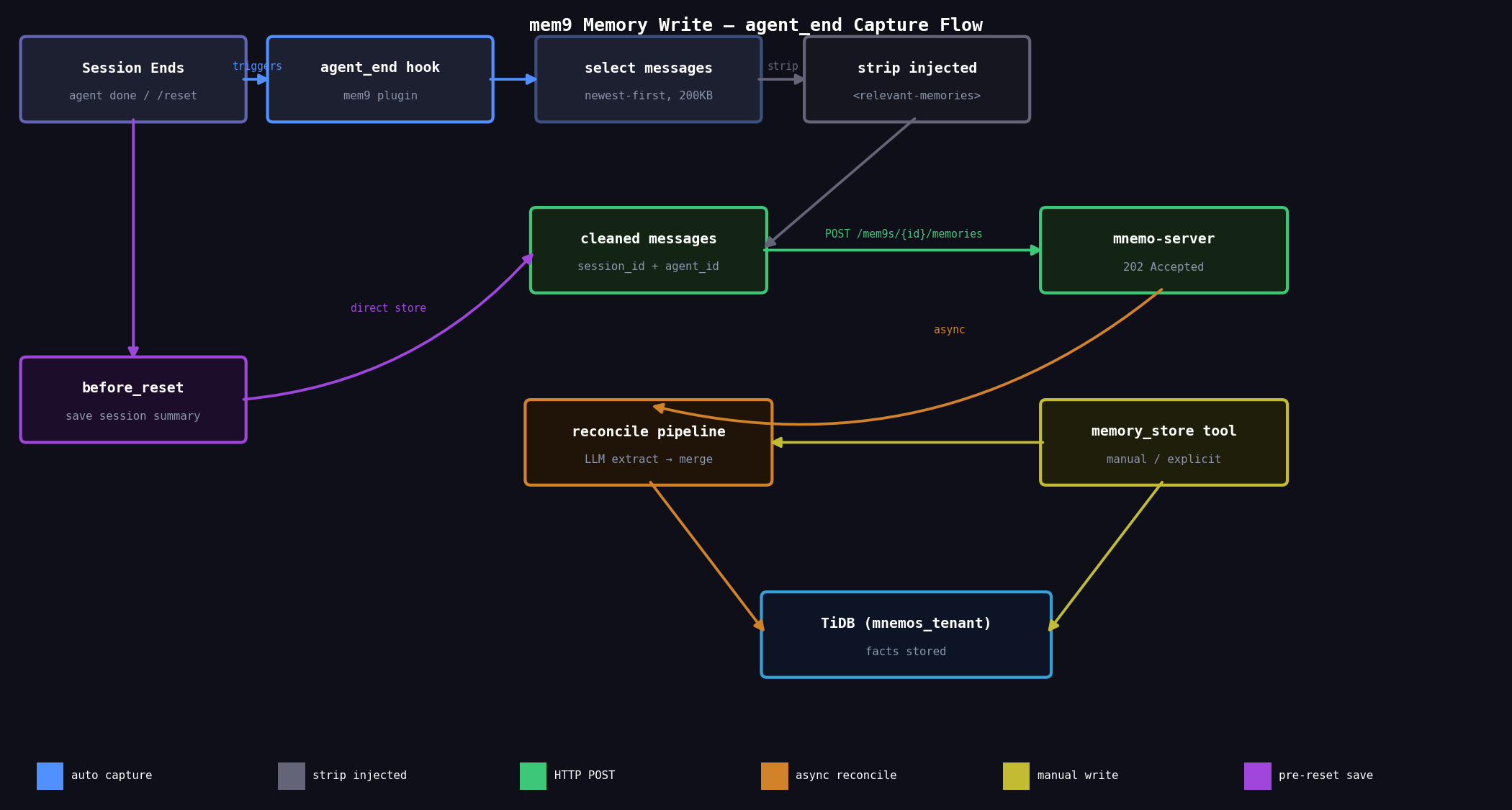
每次会话结束时,OpenClaw 触发 ,mem9 插件自动执行:
- 从本次会话 messages 中向后选取最新内容(上限 200KB / 20 条)
- 剥除 注入块,防止记忆循环回写
- 将选取的 messages 连同 、 一起 POST 到 mnemo-server
- 服务端返回 ,异步触发 reconcile pipeline
此外, hook 会在 清空上下文前额外保存一条 session summary,确保即使手动重置也不丢失关键上下文。
对于需要主动记录的场景,agent 也可以直接调用 工具显式写入。
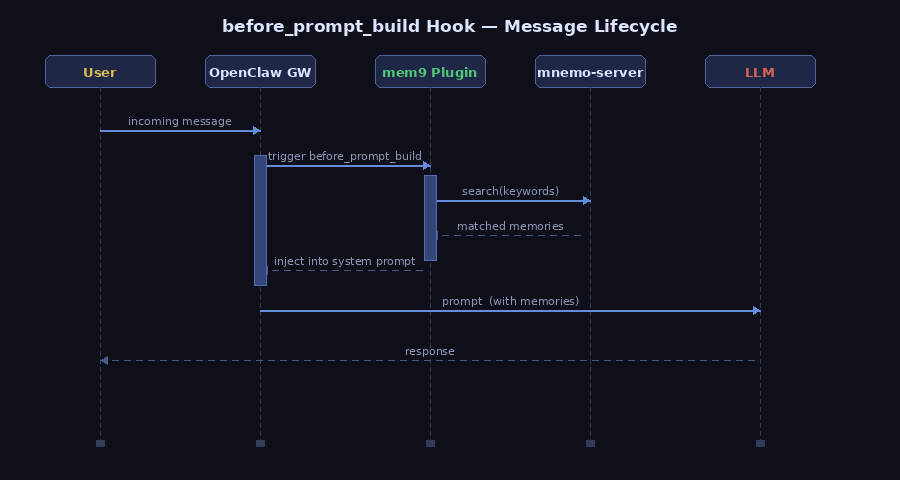
OpenClaw 在处理每条消息时,会按顺序触发一系列生命周期 hook。 是其中最关键的一个——它在 system prompt 构建完成之前触发,允许插件向 prompt 注入额外内容。
这个机制类似 Web 框架里的中间件:每个注册了该 hook 的插件都有机会在请求到达 LLM 之前修改上下文。插件可以追加系统指令、注入工具描述,或者——正如 mem9 所做的——把相关记忆塞进去。
mem9 插件利用这个 hook,在每次对话前自动完成三步:
- 提取当前消息的关键词
- 向 mnemo-server 发起搜索,拉取匹配的记忆片段
- 将结果追加到 system prompt
整个过程对 agent 完全透明。agent 感知到的不是 “ 有人塞了记忆进来 “,而是 ” 我本来就知道这些事 “——这正是自动注入与手动检索最本质的区别。
相比之下,memsearch 没有 hook 集成,只能由 agent 主动调用 CLI 查询。这要求 agent 有意识地去 “ 回忆 “,而不是自然地 ” 记得 “。
新记忆写入时,mnemo-server 不是简单地存储原文,而是经过一套提炼流程:
- 调用 LLM 从内容中提取 “ 事实 “(facts)
- 与已有记忆做比对,合并重复或冲突的信息
- 将提炼后的事实存入数据库,旧记忆标记
写入接口是异步的(返回 ),reconcile 在后台完成。这个设计保证记忆库随时间推移不会膨胀成噪音——系统越用越精炼,而不是越堆越多。
mem9 用 区分不同 agent 的记忆写入来源。三个 agent 共享同一个 tenant,但各自的记忆在逻辑上是隔离的。注入时,插件只拉取与当前 agent 相关的记忆,不会互相污染。
安装后需要重启 Gateway 使插件生效。
完成 Step 2 部署 mnemo-server 后,可以通过以下命令获取 :
然后编辑 ,在顶层 节点添加:
使用 Docker Compose 一起管理两个容器:
确保 TiDB 健康后才启动 mnemo-server, volume 保证数据持久化,容器重启不会丢失记忆数据。
初次启动后创建数据库:
这里 指向的是本机 Copilot Proxy(后文说明)。
mnemo-server 启动后会自动创建 tenant 记录,但默认指向云端存储。需要手动更新:
mnemo-server 的 reconcile pipeline 需要调用 LLM 来提炼记忆。如果你使用的是标准 OpenAI 兼容 API(如 OpenAI、Ollama、DeepSeek),直接配置 和 即可,跳过这一步。
本文使用的是 GitHub Copilot 订阅,模型选择 ——reconcile 是后台批量任务,对速度和成本都有要求, 在 Copilot 订阅里消耗低、速度快,适合这个场景。
问题在于 Copilot API 除标准 header 外,还强制要求两个 VSCode 插件标识头:
mnemo-server 的 LLM client 无法添加自定义 header,因此需要在本地起一个代理(),监听 端口,在转发请求时自动注入这两个 header,同时从 OpenClaw 的 token 文件读取最新 token。
为确保机器重启后自动恢复,将其注册为 systemd user service:
替代方案:除了自己写代理脚本,也可以用 LiteLLM 作为统一的 LLM 代理层。LiteLLM 支持 100+ 模型提供商,可以在配置文件里统一管理 header、认证和模型映射:
然后将 指向 LiteLLM 的本地端口即可。
有两类历史数据需要迁移:本地 记忆文件和 mem9.ai 云端记忆。
踩坑记录:mem9 的 端点不支持 格式(返回 )。正确做法是逐条读取文件内容,POST 到正确的 tenant-scoped 端点:
云端数据则通过 Python 脚本批量拉取后生成 SQL,pipe 进本地 TiDB。迁移完成后共 1,879 条记忆全部落地本地。
mnemo-server 的双库设计乍看多余,实际上解决了一个真实问题:迁移成本。
在完成本地化之前,记忆数据存在 mem9.ai 云端。迁移时只需要更新控制平面里的一条 tenant 记录,将 从云端地址改为本地 TiDB,mnemo-server 的其他逻辑完全不变。数据平面独立,意味着存储后端可以随时替换——今天是本地 TiDB,明天换成 PlanetScale 或者自建 MySQL,上层完全无感。
配置 mem9 时遇到一个问题:OpenClaw 不支持 per-agent 的插件配置( 在 schema 层面被拒绝)。换句话说,无法给每个 agent 配置独立的 mem9 实例。
但深入 mem9 源码后发现这不是问题:mem9 内部用 区分不同 agent 的记忆,写入和检索都带着这个标识。共享 tenant + 逻辑隔离,在功能上等同于独立记忆。
真正的物理隔离(每个 agent 一套 mnemo-server + TiDB)理论上可行,但成本极高,且收益有限。逻辑隔离已经足够。
最终 memsearch 没有被替代,而是留下来作为补充。两套系统的分工很清晰:
- mem9:日常记忆,自动注入,覆盖近期高频信息
- memsearch:深度回溯,当需要在 108 个历史 文件里做语义检索时手动调用
mem9 存储的是 LLM 提炼后的 ” 事实片段 “,memsearch 索引的是原始全文。两者互补,而不是竞争。
云端记忆服务的便利是真实的:开箱即用,不需要维护任何基础设施。但便利的代价是,你最私密的那部分数据——你的习惯、偏好、决策过程、未完成的想法——存在别人的服务器上。
本地化不只是隐私问题。更深层的动机是自主权:对工具链的掌控,对数据生命周期的掌控,对 “ 这套系统在五年后是否还能用 ” 的掌控。云服务可以关闭、涨价、改变 API,本地部署不会。
搭建这套系统的过程比预期复杂——Copilot Proxy、控制平面迁移、历史数据批量导入,每一步都有坑。但跑通之后,1,879 条记忆完整落地本地,mem9 自动注入开始工作,那种感觉是不同的:这是真正属于自己的记忆系统,不依赖任何外部服务的持续运营。
AI agent 工具链正在成熟,但 “ 记忆 ” 这个维度还远没有标准答案。本文记录的只是一种可行路径,随着 mem9、OpenClaw 以及相关生态的演进,更简单的方案一定会出现。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/231968.html