
最近Token疯涨,coding plan快顶不住了。有没有系统性的介绍如何OpenClaw如何省Token的方案?
先说方案——用QMD!立减80%!
优化的关键,是抓住大头,在细枝末节上节省收效甚微。
OpenClaw这只小龙虾🦞之所以这么能吃Tokens,大头是啥?

大头就是OpenClaw的Memory管理实在差点意思,倒不是想法有问题,而是实现有问题,往Context里塞了太多Memory。
OpenClaw的基本想法是:
- 使用Markdown文本来记录所有对话内容,作为Memory
- 对Memory做索引(OpenClaw用的SqlLite,我认为是最大的败笔)
- 每轮对话,搜索相关的Memory放在Context里
- 必要的时候,压缩Memory
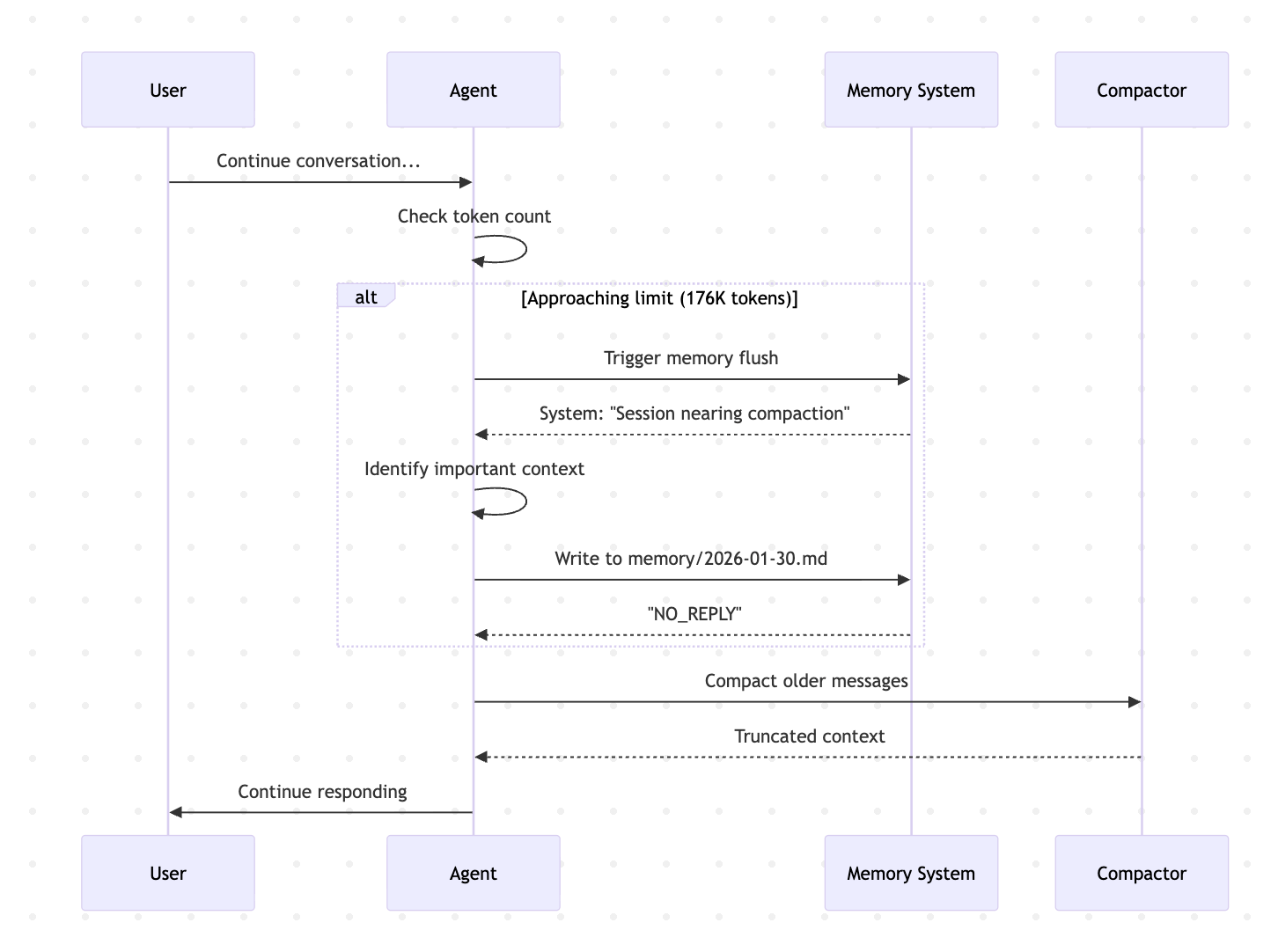
这想法其实不错,但是OpenClaw到目前实现的不行。
解决方法很简单,用QMD。
我是前阵子用Claude Code来管理Obsidian笔记的时候注意到了qmd,其实用CC来管理Obsidian笔记这事,和管理OpenClaw的Memory一回事。
你看我Obsidian上笔记已经写了几兆markdown了,如果要CC去总结一个东西,把这几兆markdown全发给AI模型,那一个回合就消耗几百万个Tokens,那真的根本花不起啊!
所以需要安装一个QMD,QMD是Query Markup Documents,是电商平台Shopify创始人 Tobi开发的一个本地语义搜索引擎,可以说是专为AI Agent量身定制。
让CC先去利用qmd去搜索Obsidian的文档,得到的相关结果可能也就几K,只把这几K文档发给AI模型去总结,就非常节省Tokens了。
因为QMD 不是傻瓜式切字符,它会根据 Markdown 结构(标题、列表、代码块)智能分块,保证语义完整,所以特别适合Obsidian文档,当然,也适合OpenClaw的Memory。
所以,为了省OpenClaw的Tokens消耗,就让它把QMD用起来就OK了。
步骤:
先用npm或者bun安装上qmd
npm install -g @tobilu/qmdor
bun install -g @tobilu/qmd
然后修改OpenClaw的配置文件~/.openclaw/openclaw.json,加上这些下面这些内容:
{ memory: {backend: 'qmd', // Backend storage type citations: 'auto', // Auto-manage citation behavior qmd: { includeDefaultMemory: true, // Load default memory file update: { interval: '5m', // Sync interval debounceMs: 15000, // Delay before syncing after changes onBoot: true, // Run sync on startup waitForBootSync: false, // Don't wait for sync before continuing boot }, limits: { maxResults: 7, // Max number of search results maxSnippetChars: 700, // Max characters per snippet timeoutMs: 4000, // Query timeout in ms }, scope: { default: 'deny', // Default access policy rules: [ { action: 'allow', // Permit direct chats match: { chatType: 'direct' }, }, ], }, paths: [ { name: 'memory', path: '~/.openclaw/workspace/memory/', pattern: '/*.md', // Markdown memory files }, { name: 'notes', path: '~/obsidian/', pattern: '/*.md', // Notes from Obsidian vault }, ], }, }, }
最关键的几个配置:
- backend,必须是qmd,这就是让qmd成为OpenClaw的memory来源
- maxResults,不要太大,这就是qmd搜索结果排在前面多少个结果放到Context,我选择7,因为我喜欢7这个数字
- paths,列上所有希望成为需要参考的文件
一切就搞定了。
用了QMD,Tokens消耗量可以减少80%。
当然,我事后诸葛亮地想,可能省Tokens主要是因为maxResults这个配置,但是QMD又快又准地搜对内容,也是功不可没。
最后,还是友情提醒一下,OpenClaw是给专业人士的工具,如果你都不明白我上面的教程说些什么,那你可能不适合使用OpenClaw。
不要因为看别人跟风所以养小龙虾,工信部都认定OpenClaw存在安全风险。
不要被Web4.0概念忽悠去养小龙虾,这玩意币圈都下场了,可见割韭菜的刀已经磨亮了。
Claw只是一种形态,何必单恋OpenClaw一枝花。
大家静待更加安全、更加易用的Claw就好,我相信,各个大厂很快就会推出很棒的Claw产品的。
我一天烧几百m的claude opus token,账单都不敢看了,今天到处看省钱攻略
当然最省钱的是换便宜模型,但是模型选差了就不出活了
看一些攻略说简化 memory 或者 agent 设定,对于新手意义有限
得经常主动和 openclaw 强调节约,让它自己想好办法。我让我养的🦞从 memory 中总结一些经验
1. 大文件不要整个读,采样关键段就行
2. 上下文窗口不要太大 100k 通常足够用
3. heartbeat 选个便宜的或者免费模型(如 step 3.5 flash)
4. 前台不要跑重任务,主要要及时响应用户,具体任务目标交给便宜的 subagent
5. 批量起 subagent 时,回复带 ANNOUNCE_SKIP,不要猛灌 token 回主 agent,采用检查 log 的方式交互结果
6. exec 命令用管道收敛输出。 grep -c 代替 grep | wc -l,tail -5 代替整个 log,du -sh 代替 ls -la。每个 exec 的 stdout 都是 token,管道越紧凑越好。
7. tool call 结果里的报错堆栈是 token 大户。 一个 Python traceback 轻松 2k+ token。exec 里加 2>/dev/null 或 2>&1 | tail -3 过滤掉不需要的 stderr。
8. 多个无依赖的 tool call 合并成一次。 同时调 3 个 exec 比串行调 3 次省一轮 assistant→user 的来回,少重复一次 system prompt 解析。
9. 别反复读同一个文件,记住哪些文件已经在上下文里。
10. compaction 后别急着补上下文。 compaction 刚做完最忌讳「为了安全再 read 一遍所有文件」——那就白压缩了。只读当前任务需要的。
11. 时常想想怎么节约 token
今天看账单只花了前天 1⁄5
关于小龙虾怎么系统性地节省 token,这个我真的是深有体会。
在玩🦞第一周,我跟一个正在使用 Claude Sonnet 4.5 的 agent 只是打了个招呼,说了一句“嗨”,结果我那个五小时的 Claude Code 额度一下子就被掉了1/3,不知道咋回事的我,以为上下文太多了,重启了对话,结果话都没说,又少了1/3的额度。虽然我用的是 Claude Pro plan,但那也是Pro plan 的五小时额度啊,我当场不敢再发信息了。
我马上找别的agent仔细调查,发现本质问题其实很简单:没有做好 context 和 memory 的管理。
要理解这个问题,得先从小龙虾的记忆系统说起。其实它没有那么复杂。小龙虾有一套你可以理解成“配置文件”的东西,在每个 agent 的根目录里,一般都会有几个用大写字母命名的文件,比如 AGENTS.md、MEMORY.md、USER.md、IDENTITY.md。这些文件里会写一些信息,告诉小龙虾它是谁、该怎么工作、该优先遵循什么规则。
除此之外,还有一个小写的 memory 文件夹,里面通常会按日期存放 markdown 文件,记录当天发生的事情。所以如果你当天做了很多事,这部分内容也会越来越大,而且也会被读取进去。
它的读取规则一般是这样的:AGENTS.md 会最先被读取。你如果打开这个文件,通常会看到很多用英文写的规则,其中包括“启动时需要先读取哪些文件”。比如它会在一开始就告诉模型,要读取 MEMORY.md、IDENTITY.md、USER.md 等等。也就是说,这一串文件其实是在 AGENTS.md 里被定义成启动时必须加载的内容。
这就意味着什么?意味着这些文件里的 token,都会在启动时被送进模型上下文里。那你也可以想象,当这些文件变得越来越大时,它消耗的资源就会变得非常夸张。
我当时最后排查下来发现,最大的问题其实就是 MEMORY 文件。因为我不断地让它“记住这个、记住那个”。甚至我出于好心,为了让它多学一点,还让它把我自己开发的一整套金融数据 API 文档都记进去。结果它也真的是老老实实地把这些东西写进 memory 里了,最后光两三个 API 文档就已经非常可观了。再加上每天做事产生的“日记”,它还会读取过去一两天的内容,这部分有时候也会很大。
所以那时候我粗略估算了一下,光是启动时需要读取的这些文件,加起来大概就已经到了十万 token 这样的量级。那自然,你每多说一句话,它背后的成本都会非常高。
这里还有一个经验:这些启动文件的读取,某种意义上属于一种“沉默成本”。也就是说,你每次开新 session、重启 agent,都要重新支付一遍。如果这个沉默成本已经非常高了,那就不要轻易重启,不要轻易新开很多对话,尽量在原来的对话里继续,配合压缩去做。因为在同一个上下文里,模型有可能通过缓存机制减少重复读取这些文件的代价。
但不管怎么说,只要你的 agent memory 被搞得太大,这始终不是一件好事,它会非常夸张地消耗 token。
所以玩了几天以后你就会发现,Claude Code 根本不够用,因为它家模型实在太费 token 了。而且 Claude 还有一个很鲜明的特点,就是特别兢兢业业,记笔记非常详细。这其实一直是它的优点,但某种程度上也是它在这种场景下的缺点:它做事很认真,很啰嗦,很愿意写很多东西。结果就是,它会在你的日记和 memory 里留下大量内容,进一步推高 token 开销。
那问题来了:到底该怎么优化?
那天那个事故发生之后,我基本上已经没法继续正常用 Claudia 了——你说一句话,它几乎就要当机。所以我当时就去问了另外两个模型,MiniMax 和 GLM,甚至还去问了 GPT:到底该怎么优化我的 Memory 和 Agents?
他们给出的答案其实都很一致,核心思路也很简单:不要把那些“有价值但不需要每次启动都读”的东西塞进记忆里。
比如 API 文档就是一个特别典型的例子。它当然有用,但你并不是每次启动 agent 都需要重新理解一遍这些文档。你把它们硬塞进 memory,就相当于每天都要先读一遍《西游记》,可你今天压根又不需要用到《西游记》里的内容,那这就是纯浪费时间,也纯浪费 token。
所以一个基本思路就是:把那些跟特定项目相关、偶尔才用到的资料,比如 API 文档、项目说明、技术细节,全部归档到特定位置。然后在 Agents 和 Memory 里只保留一条简洁的信息:这些资料放在哪里、什么情况下应该去看。
比如你可以把它们放到一个叫 APIdocument 的子目录下面,然后只在 Agents 或 Memory 里写一句话:当任务涉及这个项目或这个 API 时,再去读取对应文档。总体来讲,AI 是完全可以识别这种“按需读取”的结构的。
这其实就是一个非常重要的优化方向:把“内容本体”从常驻上下文里移出去,只保留索引、路径和触发条件。
至于这样做到底有没有用?当然我自己也这么做了。从结果来看,确实有改善,token 的使用情况好了一些。但不可否认的是,随着你用小龙虾越来越久,需要记住的东西一定会越来越多,这是个必然趋势。
那有没有更高级的方法?我觉得当然有,比如各种压缩办法。但现在我越来越倾向于另一个更实用的方案:多建几个 agent。
因为你让一个 agent 干太多事情,本身就不是一个特别好的设计。最后你会发现,你当然可以让一个 agent 什么都知道,但问题是,它知道得越多,启动越重,负担越大;而且它在干第一个活的时候,也不能同时高效地干第二个活。
反过来,如果你把不同工作拆给不同 agent,让他们分别负责不同的方向,甚至某一个功能下还有两三个 agent 可以并行工作,这反而是一个更理想的状态。这样一来,每个 agent 的 memory 和 context 都会更清晰、更轻量、更容易维护。
我现在其实就有一个 agent,是专门用来管理 context 文件的。它会把那些大家都需要遵守的通用规则,提炼成构建时统一遵循的部分;至于其他内容,每个 agent 则根据自己的任务、自己的项目、自己的技术方向去量身定制。这样的话,每个人的 context 都不会太大,而且结构也更清楚。
在这个基础上,如果你再定期做一些记忆优化,比如让“总管 agent”定期帮你检查每个 agent 的 context 情况、做对比、做压缩,那整个系统的可持续性会好很多。
甚至我后来还做得更进一步:我专门建了一个 GitHub repo,用来存储不同 agent 的 context 文件。这样一来,很多本来会被塞进 memory 的内容,就可以转移到外部仓库里进行管理。agent 只需要知道这些内容的地址、用途和调用方式,而不是把所有东西都背在自己身上。
所以总结下来,我现在对这件事的看法非常明确:真正节省 token,不是靠少说几句话,而是靠系统设计。
核心就三点:
第一,不要让 memory 变成资料仓库。
第二,把低频但重要的内容做归档,只保留索引和触发规则。
第三,尽量按任务拆分 agent,而不是让一个 agent 什么都背、什么都干。
这样做下来,不只是 token 会省很多,整个 agent 系统也会更稳定、更清晰、更容易扩展。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/231040.html