
一、背景:
- 是不是所有模型都支持cache的这种机制的,尤其是对于我所用的GLM code plan模型?
- 缓存的什么周期如何控制呢
从deepseek给我的回答看,这个心跳间隔的设置,对于cache的成本影响还是很大的,尤其是新手如果会话重开的频率比较频繁的时候,感觉上这个心跳是依赖于会话存在的,如果会话关闭了,心态就停了,缓存也就没了,重开会话就得重新发一次缓存,这一次的收费应该较高;另外如果间隔设置不合理,也会导致缓存太快失效,导致每次发消息都得重复发送一次?这里先有一些概念,后面有时间再深挖吧。。。。。

三、排查经过
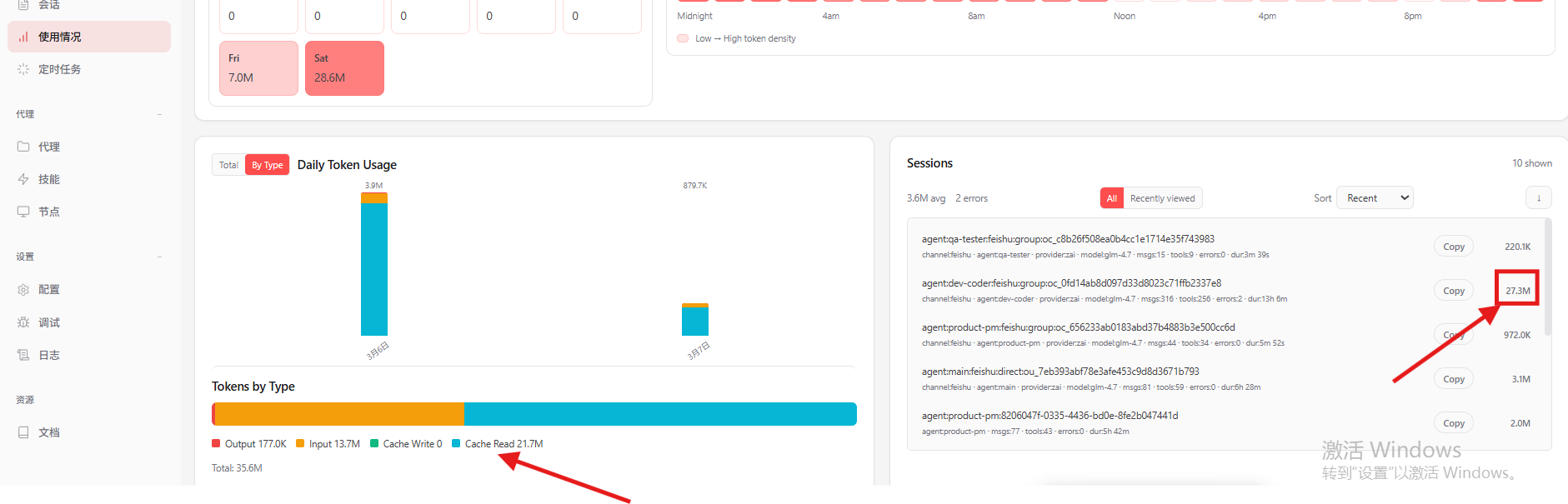
2.1 通过dashboard查看三个智能体的session的token增长情况
小猿潘的token增长是最多的,不知道是否因为是开始写代码的原因,它是否每次和大模型交互,都会把整个工程代码和中间编译结果都发给大模型,导致token/上下文迅速增加,超出大模型处理限制从而导致异常?
2.1.1 小猿潘的token增长,如下:
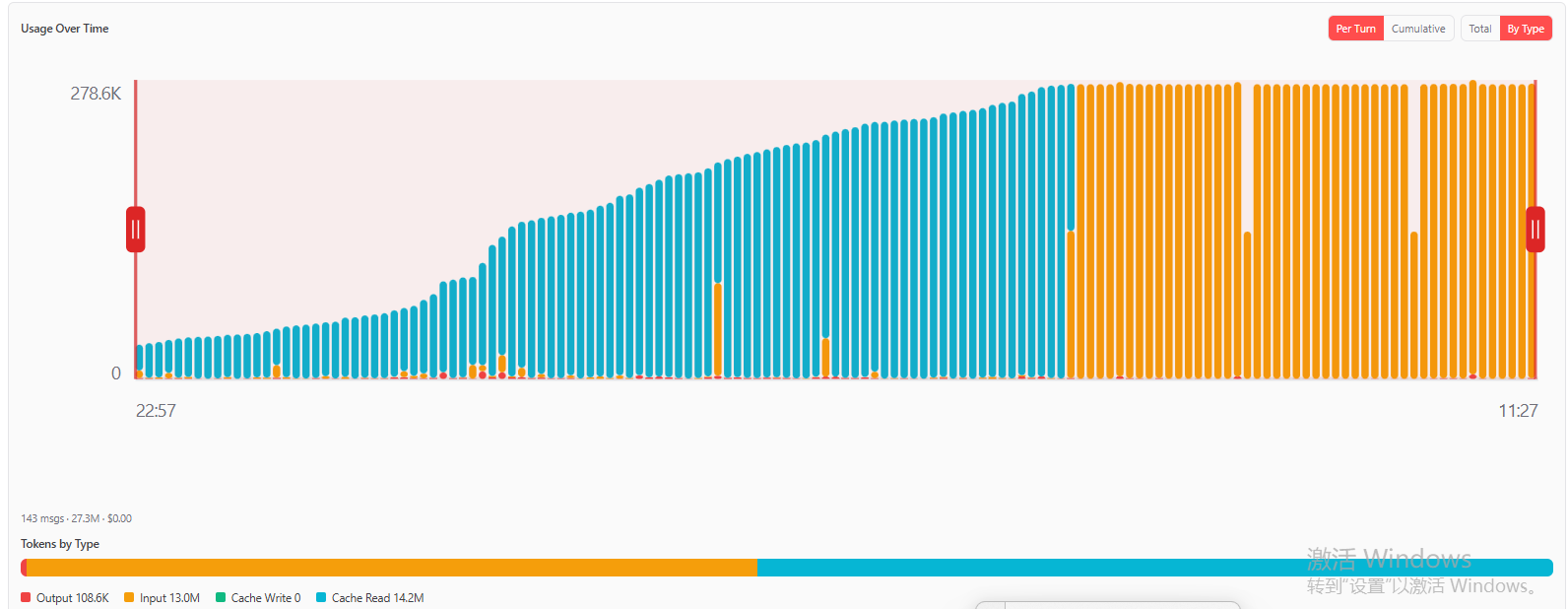
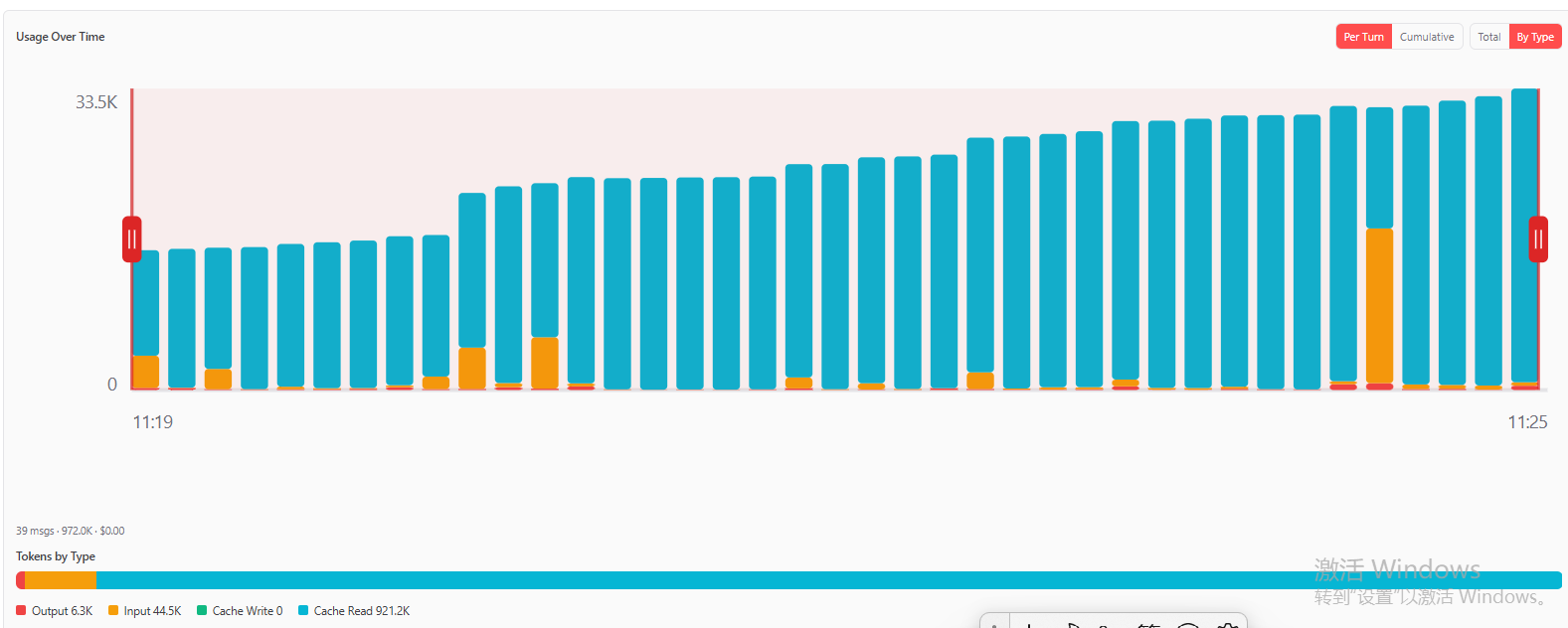
在早期cache还是很明显的,但是后面再token/上下文长度见顶之后,就没有使用cache了,是因为开始写代码,建工程了吗,这里先抛出几个疑问
疑问一:如果openclaw在本地发现上下文太长,主动对上下文进行修剪或者压缩,对之前的缓存是什么影响
疑问二:服务商会提供多大的cache容量呢,如果我本身代码仓库就比较大,是否会有问题
疑问三:这个是否进行缓存的动作是由openclaw主动控制的,还是由大模型体提供商控制的。
我又把疑问抛给deepseek,他的解答大概是:压缩后会破坏缓存,然后重建之后会重新命中,cache容量一般无限制,但是缓存时间有限制,一般由openclaw通过cache_control进行控制是否要进行缓存。(但是到平台期后我并没有发现有重新命中的迹象?这又是为什么呢?)
相关参考资料:
(1)GLM文档(自动隐式缓存):https://docs.bigmodel.cn/cn/guide/capabilities/cache
(2)阿里云的prompt cache策略:https://developer.aliyun.com/article/1713315
(3)csdn openclaw配置策略:https://blog.csdn.net/_28809177/article/details/157909207
2.1.2 小产潘的token增长,如下:

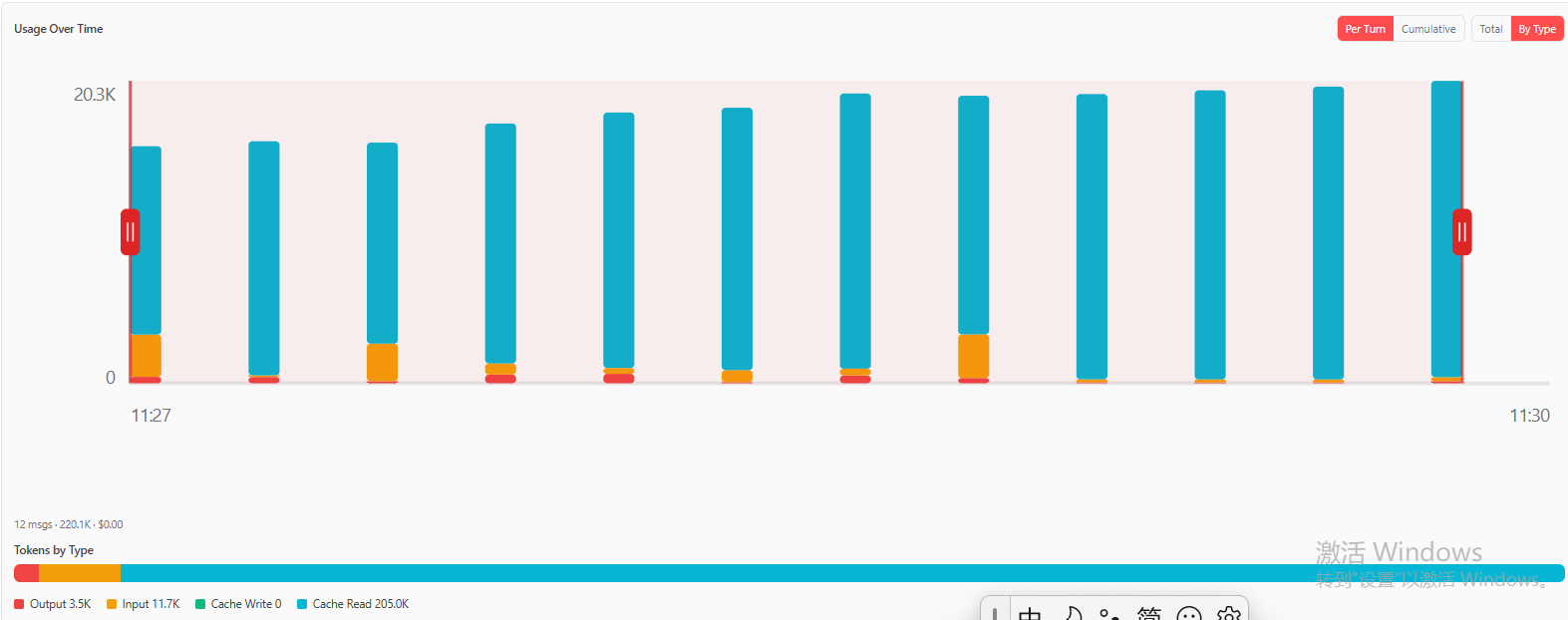
2.1.3 小测潘的token增长,如下:
2.2 翻阅openclaw相关文档(没有太多帮助)
https://docs.openclaw.ai/gateway/troubleshooting(官方文档);
https://zhuanlan.zhihu.com/p/2003144607068861314(知乎的命令合集);
2.3 分析openclaw日志
看到了一些超时的报错信息,不知道在openclaw在遇到超时,会有什么具体表现?有点怀疑我把编程、产品、测试划分到不同独立agent中这种编排工作流的方式是不是不太合理。

其他的把飞书重复插件的问题解决了一下
2.4 参考这个配置了一下,还是命中还是没变化,放弃了,直接/new,建新会话了。。。。。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/228164.html