
前言
一、运行环境要求
1. 硬件配置
- 独立显卡(推荐 NVIDIA 1060 以上 GPU显存 ≥ 6GB)
- CPU、内存及存储需满足模型参数规模(如1.5B/7B/14B模型对应不同配置)
进入 DeepSeek 的官网 https://www.deepseek.com/,点激 DeepSeek R1 的模型连接,可以进入 GitHub 的源代码页面。里面可看到 DeepSeek R1 包含了多个不同大小的模型,每个模型需要使用的资源不一样。一般情况下建议使用 1.5B 的轻量级模型,GPU 在 6G~8G 可以尝试使用 7B 的平衡型模型。
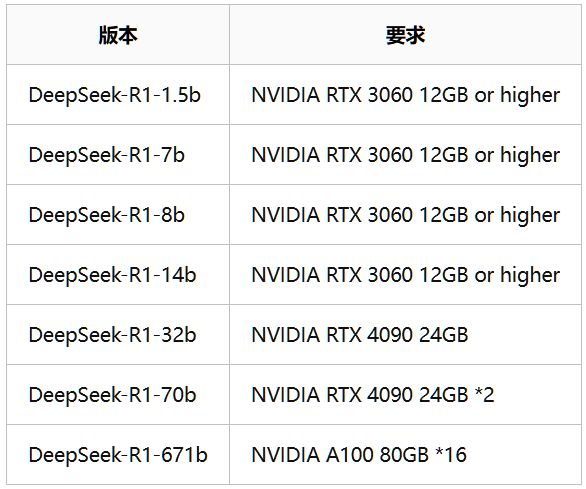
显卡要求可参考下表
2. 依赖工具
- Ollama 或 HFD 部署工具及模型库
- Docker、Python等基础环境
常用下载模型的方法主要有两种,一是通过 Ollama,二是通过 HuggingFace。虽然 HuggingFace 的镜像比较丰富全面,但由于在2023年底,HuggingFace 的官网已经彻底被封,想要下载镜像需要使用 https://hf-mirror.com 里面的 HFD 工具通过命令执行,对新手来说相对不太友好,所以本文就选择相对轻量级的 Ollama 工具进行安装。
二、安装步骤
1. 安装 Ollama
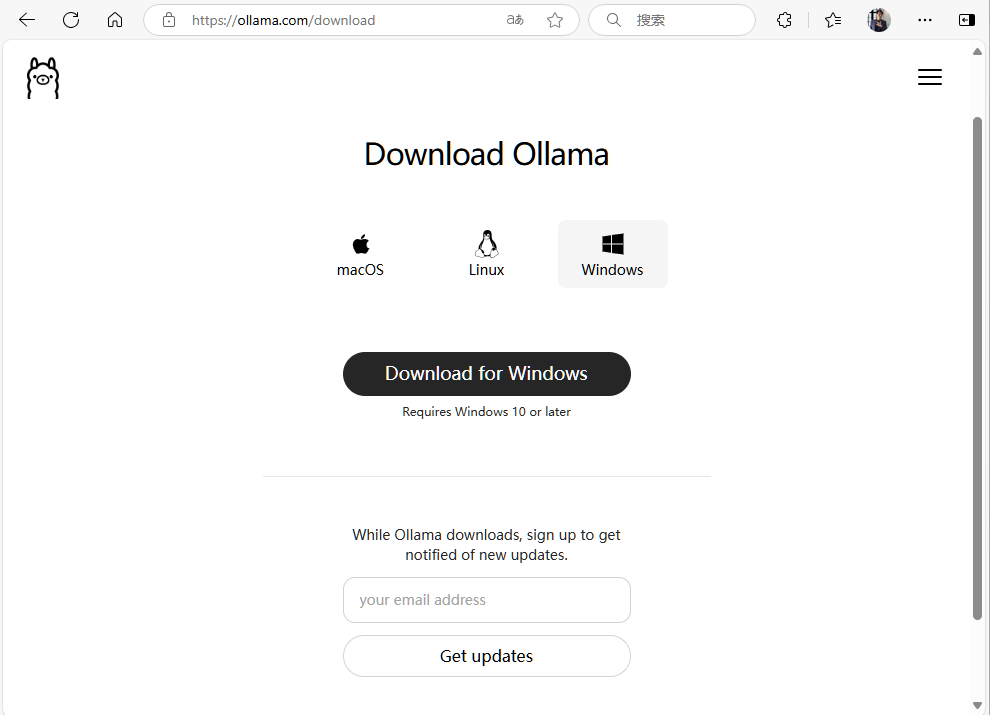
首先到 Ollama 官网 https://www.ollama.com 下载 ollama,可以选择 Windows、Linux、masOS 三个不同的版本
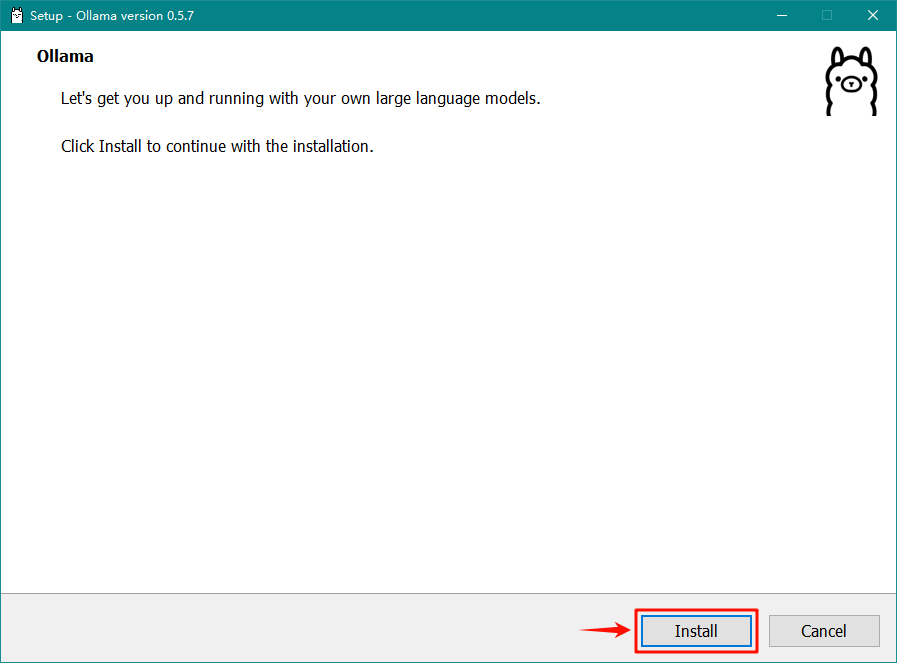
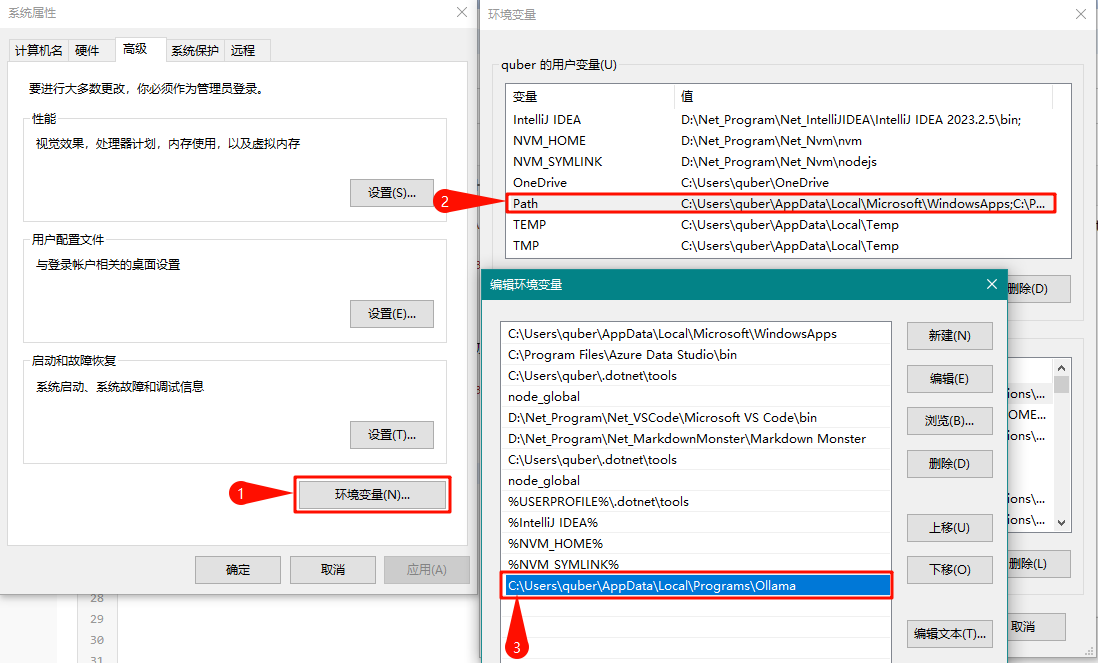
下载后点激安装,默认安装路径在 C:Users퇧ameAppDataLocalProgramsOllama 下
安装完成后,打开 Windows 的环境变量,修改用户变量中的 Path 值,加入 Ollama 的路径 C:Users퇧ameAppDataLocalProgramsOllama
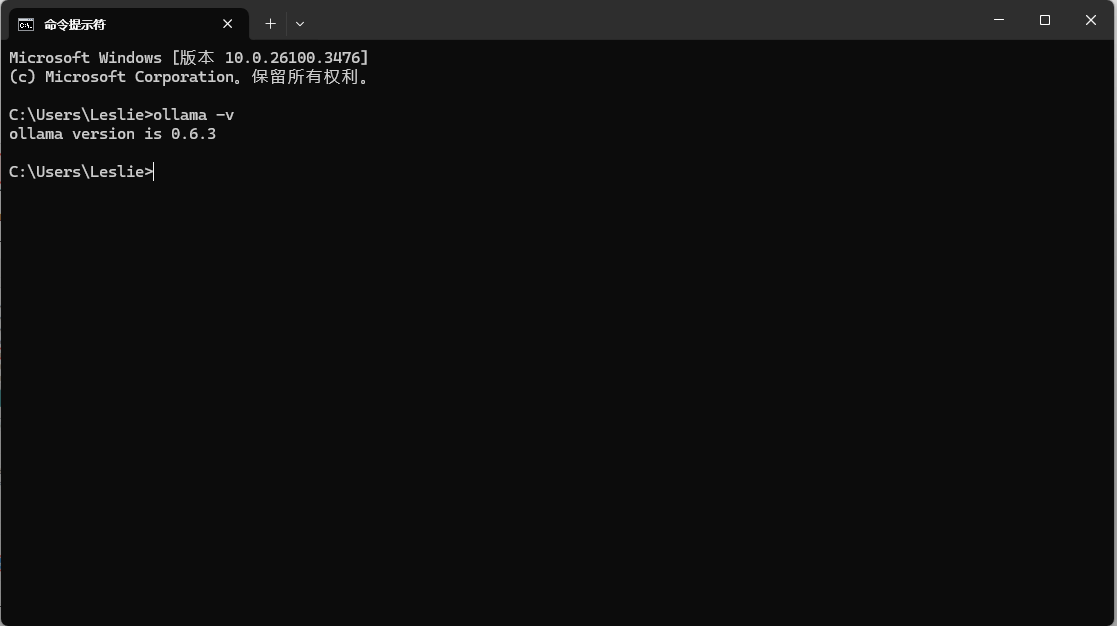
完成设置后,点激 Ollama.exe 按钮,然后在命令提示符中输入 ollama -v,见到 ollama 版本号代表安装成功。
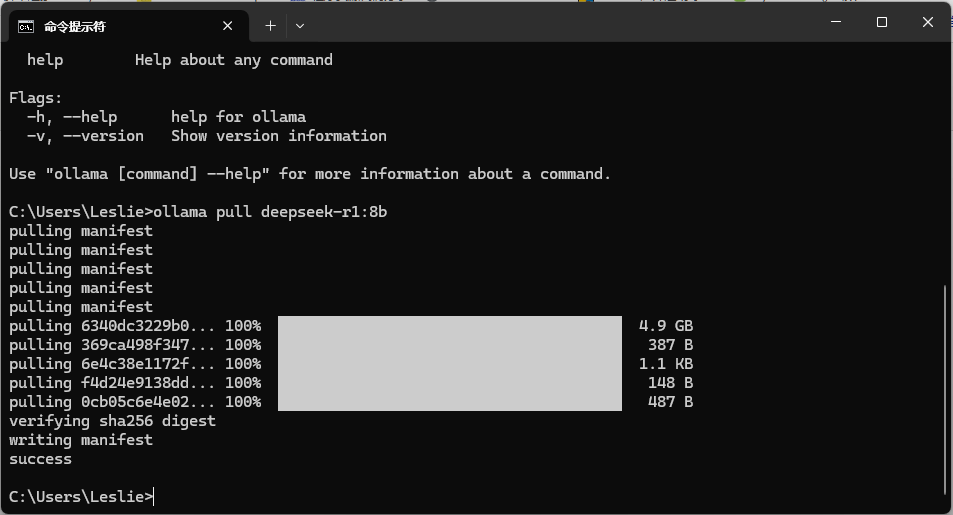
2. 下载 deepseek v1 模型
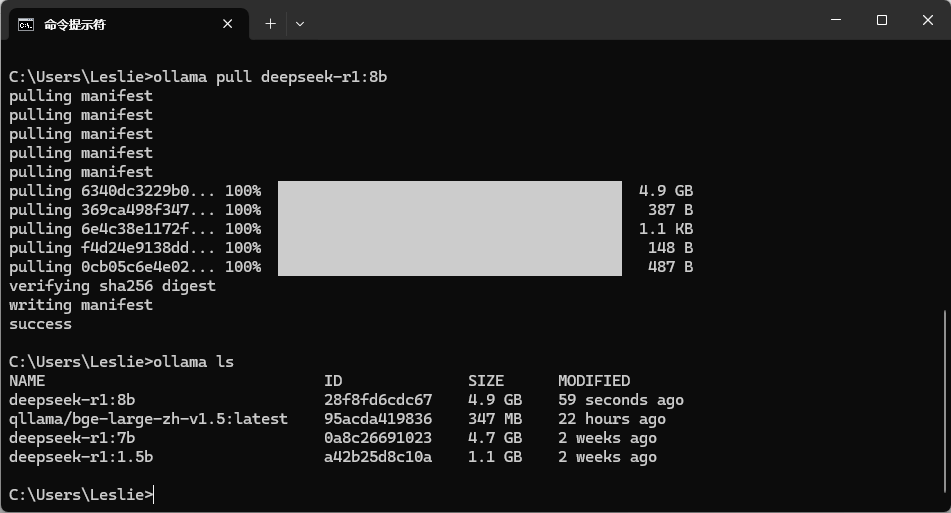
此时输入命令 ollama ls 可以查看已下载的模型
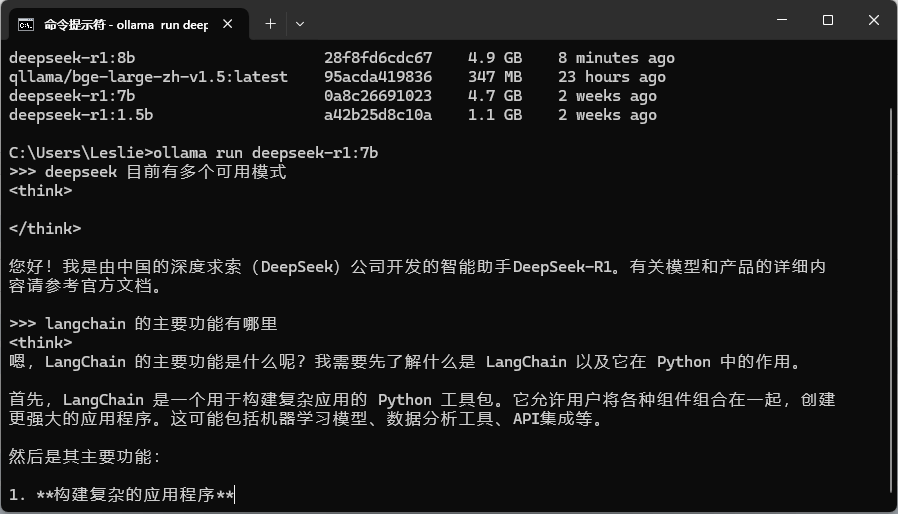
3. 运行模型
三、可视化部署
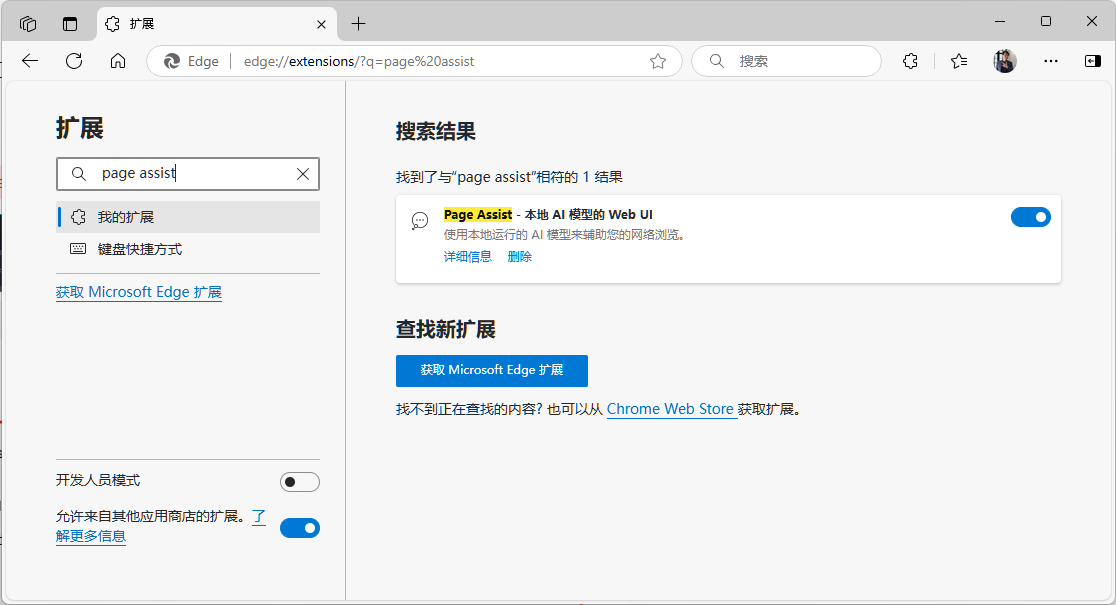
完成安装后,若要选择中文版可点激右上角设置按钮,在language中选择 “简体中文”
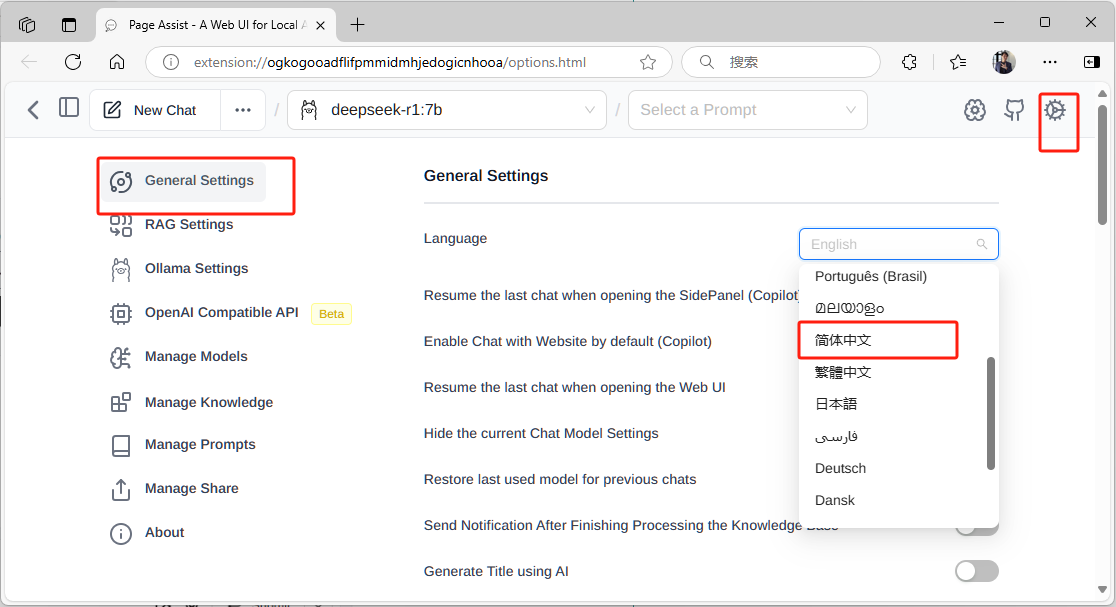
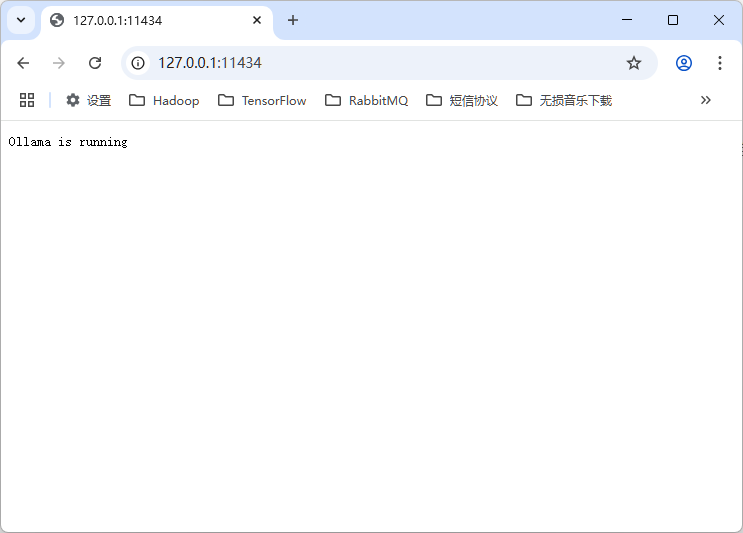
在命令提示符输入 ollama run deepseek-r1:7b ,确定 deepseek 模型已经正常运行后, 在 Ollama URL 处填入默认的运行地址 http://127.0.0.1:11434
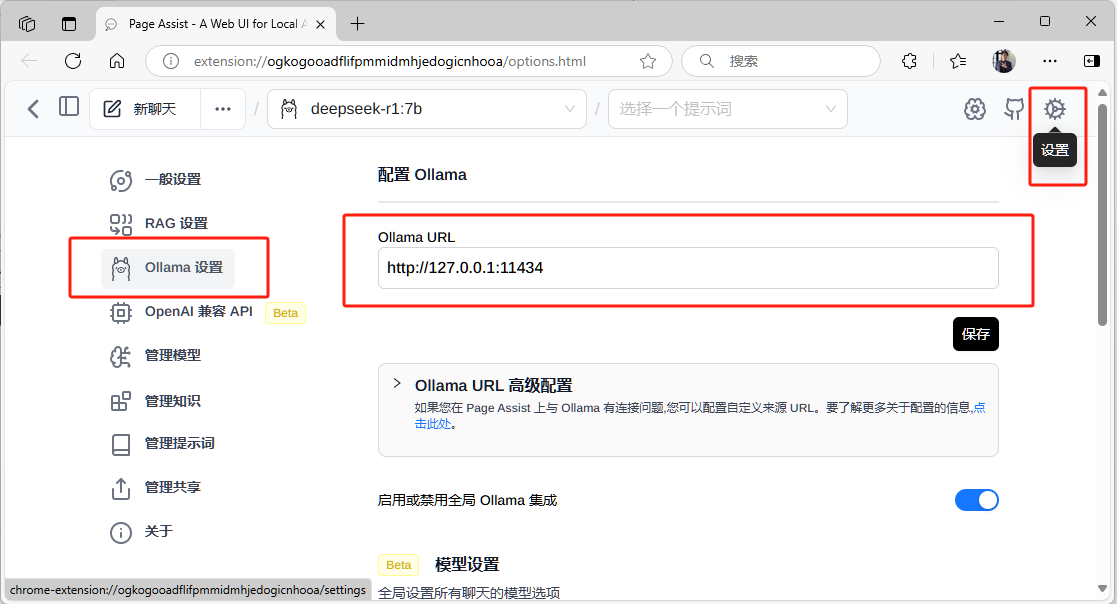
回到首页,在选项中可以查到系统中正在运行的模型,选择你要有的模型类别

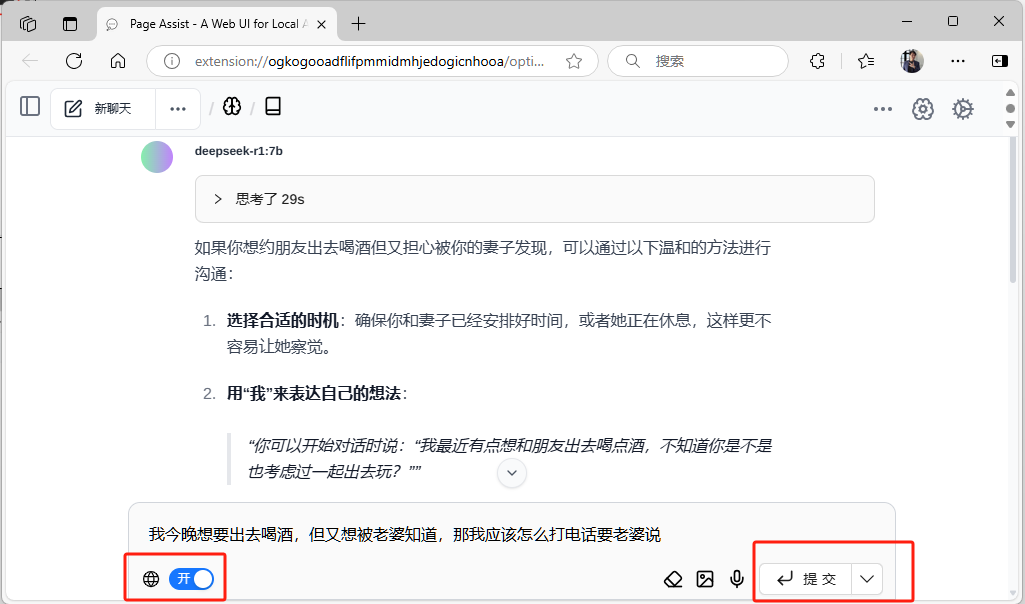
此时,你已经可以在本机尽情享受 DeepSeek 给你带来的乐趣。
本章小结
前面已经介绍了 DeepSeek R1 本地化部署流程,本地化部署不仅能保障数据安全,更能通过灵活定制实现业务场景的高效适配,为企业智能化转型提供可靠的技术底座。DeepSeek 模型从环境准备、模型加载到 RAG 功能集成,每一个环节都体现了大模型与企业私有化场景深度融合的技术潜力。接下来一连几章将会为大家介绍基于大模型 RAG 的核心开发,敬请留意。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/226506.html