
Requests-HTML 对 Requests 进行了封装,添加了解析 HTML 的接口,是一个 Python 的 HTML 解析库
由于该库是解析 html 对象,所以可以查看对应的 html 对象包含哪些方法与与属性。
html 对象的方法包括
find:提供一个 css 选择器,返回一个元素列表;xpath:提供一个 xpath 表达式,返回一个元素列表;search: 根据传入的模板参数,查找 Element 对象;search_all:同上,返回的全部数据;
html 对象的属性包括
links:返回页面所有链接;absolute_links:返回页面所有链接的绝对地址;base_url:页面的基准 URL;html,raw_html,text:以 HTML 格式输入页面,输出未解析过的网页,提取页面所有文本;
示例:爬取下面网站对于的网站名和网址
国外网站大全|世界网站排名|全球知名网站_世界各国网址大全

from requests_html import HTMLSession
session = HTMLSession()
page_size = int(input("请输入总页码:"))
for page in range(1, page_size + 1):
world = session.get(f'http://www.world68.com/top.asp?t=5star&page={page}')
world.encoding = 'gb2312'
# world.html.encoding = "gb2312"
# print(world.text)
print("正在采集数据", world.url)
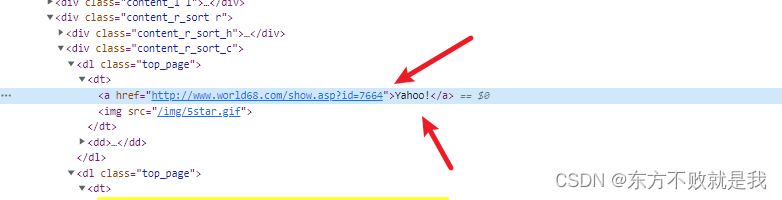
title_a = world.html.find('dl>dt>a')
for item in title_a:
name = item.text
url = item.attrs['href']
with open('webs.txt', "a+", encoding="utf-8") as f:
f.write(f"{name},{url}\n")讯享网
world.encoding,设置了网页解析编码;world.html.find('dl>dt>a')通过 css 选择器,查找所有的网页标题元素;item.text提取网页标题内容;item.attrs['href']获取元素属性,即网站域名
输出: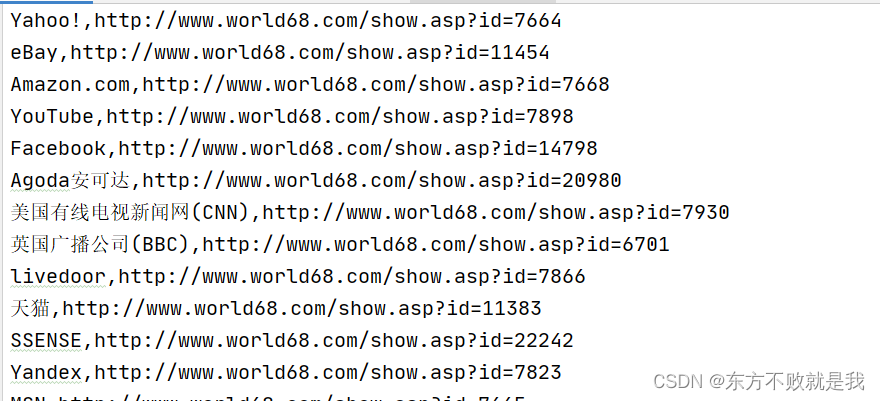
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/22568.html