
闻乐 发自 凹非寺
量子位 | 公众号 QbitAI
GitHub最新热榜榜首,来自字节。
这波自研硬核技术不是别的——
正是豆包手机的核心支撑,GUI Agent模型UI-TARS。
力压OpenAI官方Skills,开源登顶榜首,突破26k Star!
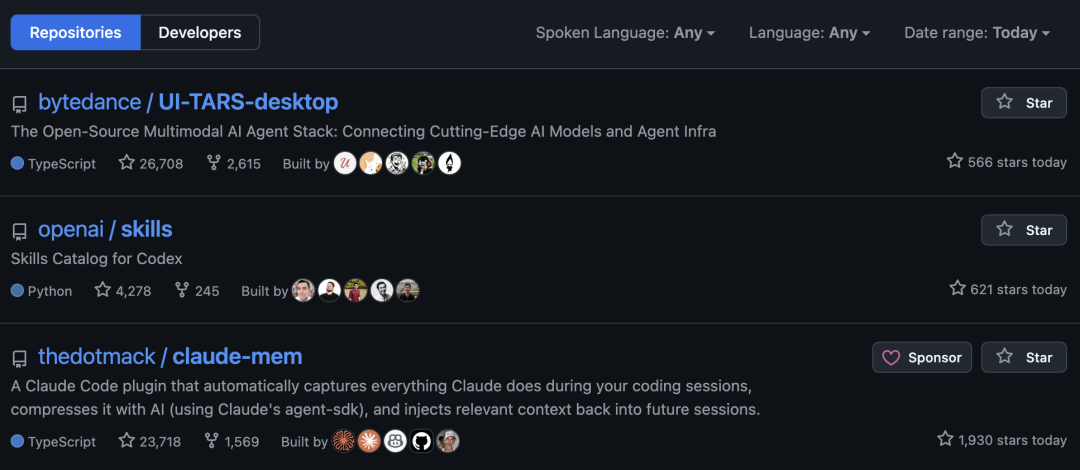
UI-TARS的核心是个多模态AI智能体,你只要通过自然语言指令——
也就是说句人话,就能让它自己点鼠标、敲键盘、拖动滚动、翻页浏览,在浏览器和各种软件里帮你完成一整套复杂操作。
主要包含了Agent TARS和UI-TARS-desktop两个项目。
Agent TARS支持一键式开箱即用的CLI,可以在有界面的Web UI环境执行,也能在无界面的服务器环境运行;
UI-TARS-desktop则是一个桌面应用程序,主要帮你操作本地电脑和浏览器。
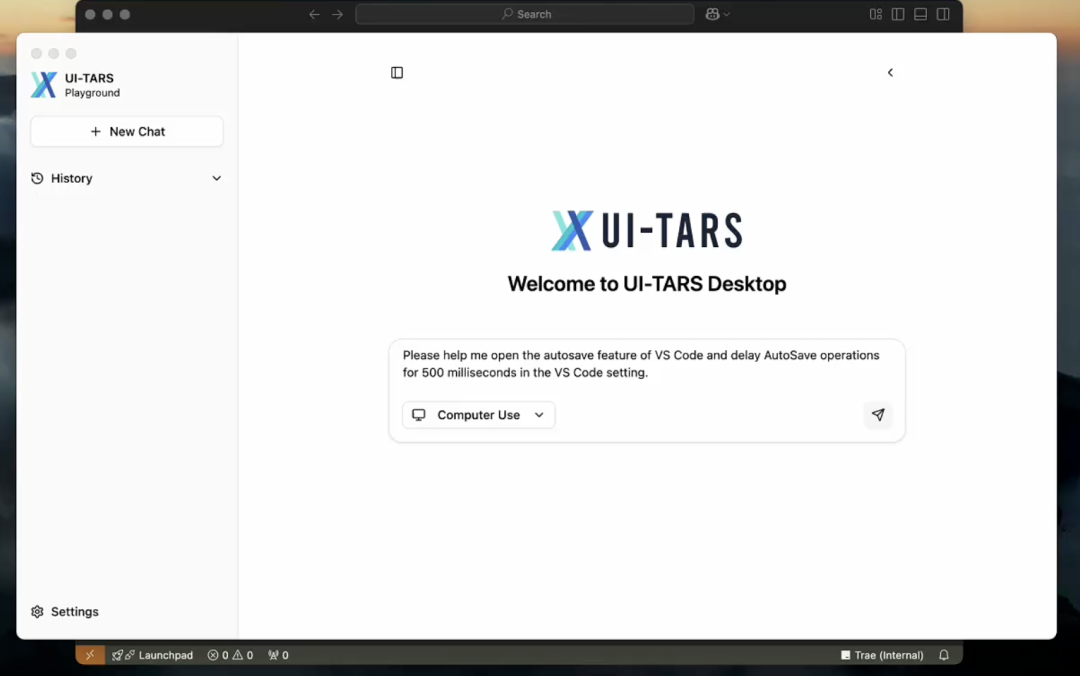
纯视觉驱动
UI-TARS这种GUI Agent的核心逻辑其实就是五个字——纯视觉驱动。
纯视觉有啥特点呢?
从传统RPA这类自动化工具来看,它们要想干活儿就得去扒复杂的网页源码、记控件编号,而且一旦这些界面稍微改一点,脚本就直接报废了。
纯视觉就是说,靠内置的视觉大模型,AI就能直接像人眼一样观察屏幕。
不管软件有没有开放API、不管界面有多复杂,只要你能看清菜单在哪、按钮在哪,它就也能,然后帮你操作。

如果有朋友想体验,部署起来也非常简单,只需要三步。
第一步,检查有没有安装Node.js和Chrome,没安装Node.js的话,要安装一个>=22的版本。
检查可以用如下命令:
node -v
如果没有还没有安装,可以用nvm先安装一下:
# Install Node.js LTS
nvm install –lts
# Switch to Node.js LTS
nvm use –lts
第二步,安装Agent TARS。
最新版:
npm install @agent-tars/cli@latest -g
公测版:
npm install @agent-tars/cli@next -g
第三步,选择模型,需要API,当前Agent TARS可兼容Seed1.5-VL、claude-3.7-sonnet和gpt-4o。
agent-tars
–provider volcengine
–model doubao-1-5-thinking-vision-pro-
–apiKey {apiKey}
或
agent-tars
–provider anthropic
–model claude-3-7-sonnet-latest
–apiKey {apiKey}
或
agent-tars
–provider openai
–model gpt-4o
–apiKey {apiKey}
选完模型后,出现如下界面就表示部署完成啦!
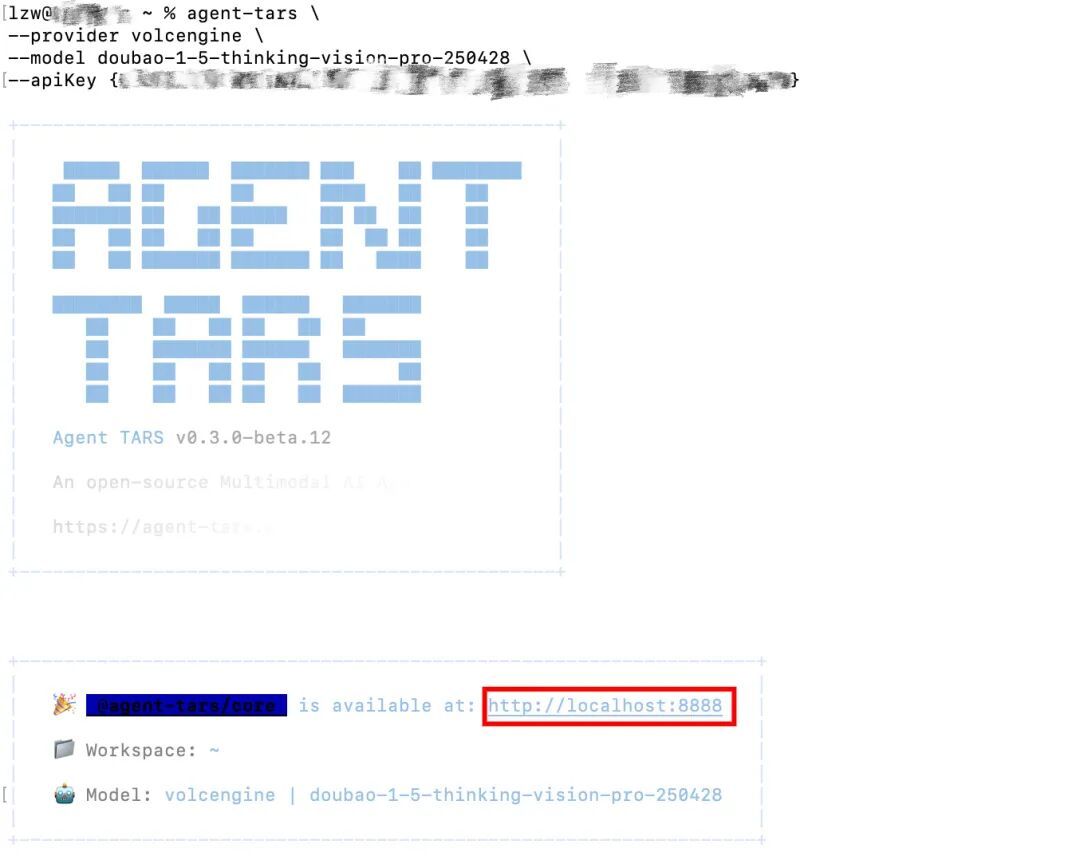
然后我们点击上面框选的链接,即可打开Web用户界面。
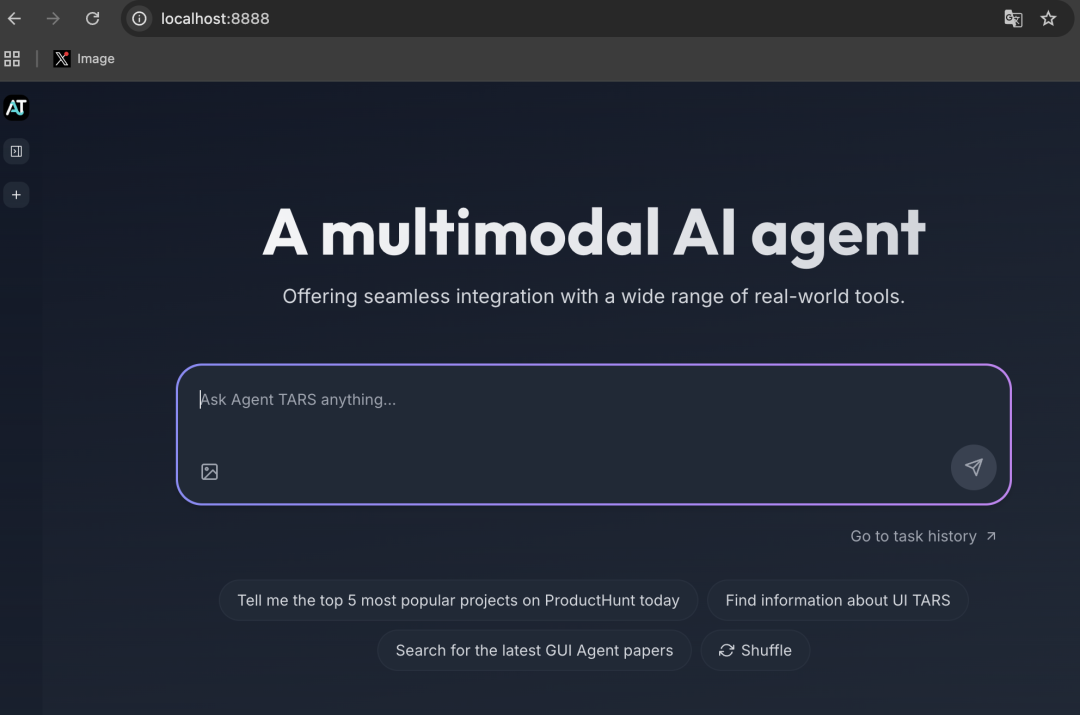
接下来就可以对它发!号!施!令!了。

豆包手机虽然一时成为了现象级的爆款,电脑版现在登顶了开源榜首,但这项技术其实早在一年前就开始布局了。
UI-TARS的核心目标是让Agent真正具备感知、动作、推理、记忆四大能力。
2025年1月和清华合作开源,成为国产纯视觉GUI Agent中首个在权威基准测试对标并超越GPT-4o的项目。
接着它就开始了一路狂飙进化。
初代凭借600万高质量教程数据注入的深度思考能力,以及精准的统一动作空间,让AI像人类一样看懂并操作界面,在多项SOTA榜单上插旗。
短短3个月后,又迎来了UI-TARS-1.5。
让Agent在动手前先多想几步,通过Inference-time Scaling预判后果,尤其在GUI定位任务上刷新了行业纪录。
到了9月,UI-TARS-2的出现彻底将能力拉满,成为豆包手机的底层技术。
它针对数据瓶颈、多轮RL不稳、纯GUI局限、环境乱七八糟四大痛点,通过“数据飞轮”让模型和数据互相喂养进化。
不再局限于单纯的点击与滑动,而是打通了文件系统与沙盒平台,将浏览器、命令行、工具调用全量整合。
几轮迭代下来,UI-TARS已经成为最火的开源多模态Agent之一。
走“前门”的GUI Agent
说到Agent、GUI Agent,就在几天前,理想汽车CEO李想的一条朋友圈也在科技圈引起关注。
他指出2025年最具突破性的三个现象级产品分别是Claude Code、豆包手机、Manus;
而2026年第一个月就出现了三个现象级的产品:OpenClaw、MoltBook、Chrome Gemini。
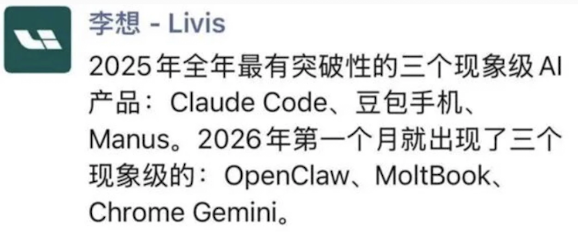
可以说,被点名的6个产品,有5个都和Agent直接相关,甚至有3个都是GUI Agent。
(如果把Claude Code看作Coding Agent,也可以说是6个……)
豆包手机:手机里的GUI Agent,直接让AI像人一样看屏、点击、切换APP;
OpenClaw:电脑里的GUI Agent,可以操作应用程序、管理文件、通过通讯工具接受指令执行复杂任务;
Chrome Gemini:浏览器里的GUI Agent,模拟人类完成网页跳转、信息提取、表单填写等操作。
这三款产品的底层逻辑完全一致,都是纯视觉驱动的端侧交互执行路线。
在输入上,不读取APP/网页/软件内部的空间ID、源码、私有接口等,统一截取屏幕像素图像作为唯一输入,靠多模态视觉模型识别界面元素;
在执行上,不调用API完成功能,直接模拟人的交互行为进行点击、滑动、窗口切换,和真人操作的系统入口完全一致;
在兼容逻辑上,不管目标应用是否开放API、是否老旧闭源、是否加密,只要屏幕能显示、人能操作,它就能执行。

再说说另外两个。
Manus是云端全自主通用Agent,不靠纯视觉模拟界面操作,优先调用API与工具链自主拆解复杂任务,在云端沙箱完成分析、处理、生成全流程,直接交付最终成果,可以说是专注复杂任务闭环的数字员工。
MoltBook则是非执行类Agent载体,不操作界面、不调用API完成实用任务,而是让各类Agent自主发帖、互动、产生内容,是不带物理操作,纯决策层的自主Agent行为。
可以说,这几个产品看似各有领域,却共同指向一个核心问题——
怎么让AI真正“动手”帮人类干活?
GUI Agent们选择“走前门”,直接看屏模拟操作,突破封闭生态的壁垒;
也有的靠聪明规划和工具链闭环来交付成果;
甚至有的把Agent们推向自己的世界,放大AI之间的连接。
于是李想在两天后又发了一条有意思的观点:
原本以为Agent这类AI工具会缩小人与人之间的能力差距,实际上却是十倍、百倍地放大了差距。

GitHub链接:https://github.com/bytedance/UI-TARS-desktop
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/222306.html