
昨天去某厂做了场Cursor入门分享(由于他们本身也有相关业务,所以这里不方便公开名字),这场分享的核心观点总结起来就三点:
1、AI编程有很多局限,包括但不限于“抽盲盒”、“偏科”、“健忘症”、“消息滞后”;
2、几乎所有AI编程工具都是围绕着这些局限去打造功能;
3、用好Cursor的关键,就是善用Cursor的功能来削弱这些局限。

之所以单独整理这篇文章,一方面是作为自己的复盘,补充自己在分享中可能遗漏的一些内容,另一方面是把这场分享的一些观点分享给大家,希望对大家也有启发。
关于AI编程局限的观点,最初萌芽于我的这篇文章>>>AI编程的使用场景、局限,以及我们的应对(其实大家可以不看这篇文章,因为核心观点都在这里了)。
后来随着对Cursor更深度的使用,以及对AI编程更深入的了解,我对AI编程慢慢有了个初步的认知框架。
这次线下分享,是限定主题,要讲Cursor基础入门,要相对系统。由于我不想只是简单地把所有功能罗列一遍(这也太无趣了),我更希望帮助大家构建起对Cursor或者说对AI编程的整体认知,这样不论是当前已有的功能,还是未来推出的新功能,都可以基于这个认知框架去理解。
后面我想到了之前那篇文章,想起自己在小报童社群、在知识星球老说到的一些观点,然后很多以前飘着的零散的想法,一下子串联起来了。
1、AI编程的局限,很多时候是LLMs(大语言模型)的本身局限带来的,包括但不限于生成的随机性、上下文限制、训练数据有大众小众之分、训练数据有截止时间等。
2、LLMs的这些局限,有些在AI编程中是被放大的。
3、比如AI生成的随机性(大模型是根据概率在预测下一个token),这种随机性放在AI写作上(非法律、医学等行业)一般不会有太大问题,即使错了一两个字,我们一般也能快速理解作者要表达的意思。但放到AI编程里,这其实很致命,因为代码本身是非常结构化的,但凡少了个大括号,逗号,整段代码可能都没法运行,
4、又比如AI是“偏科”的。因为AI的表现能力是基于训练它的数据,对于一些大众的编程语言如Python、JavaScript,AI往往会表现的比较出色,但对于一些小众的编程语言,则可能不尽人意。就拿Claude和Gemini来说,虽然它们都是顶尖编程模型,但由于它们没有太多微信小程序的代码训练数据,在这类项目上的表现往往没那么出色。
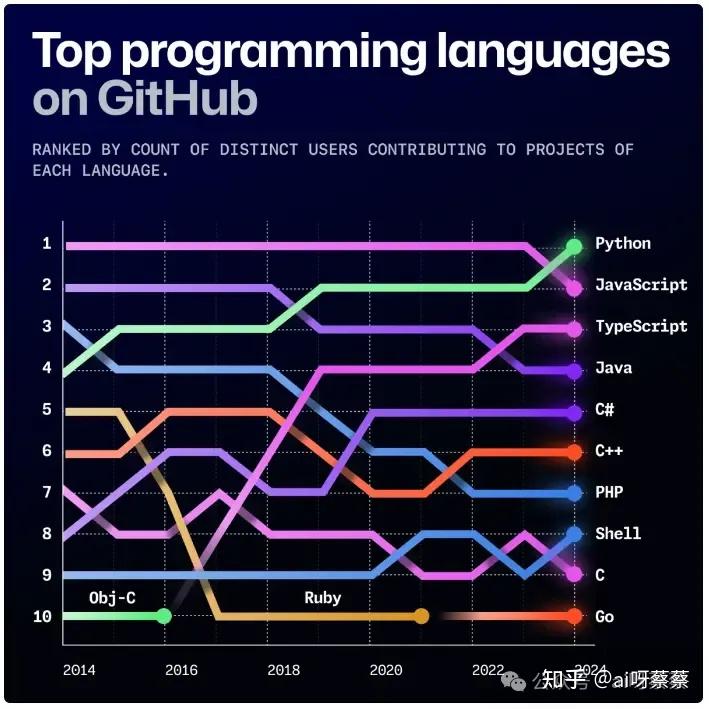
5、再比如“消息滞后”。每个大模型的训练语料都是截至到某个时间点的,如果你不给模型接各种外部工具、数据,那么它能回答的消息是不会超过这个时间点。而在编程领域,一些技术、框架、语言版本的更新是非常迅速的,如果训练数据过时,AI可能会给你生成不兼容的代码,甚至是不安全、有漏洞的代码。
6、除了在AI编程中会被放大的局限,还有一些局限可能没被放大,但目前很难彻底解决,典型如上下文。
7、无论哪个大模型,目前都有上下文局限,区别在于这个上下文的大小。这个上下文局限其实和我们人类的健忘很像,比如你现在看到文章的第7点,可能已经忘记第1点说什么了,你待会看完文章,可能又会遗忘现在第7点的部分内容,这就是上下文局限。放到AI编程里,大家经常把这种情况调侃为工具的降智。之前分享过一篇关于Cursor降智的文章>>>Cursor降智?盘点4种可能原因及解决方法,其中有一点谈的就是上下文限制。
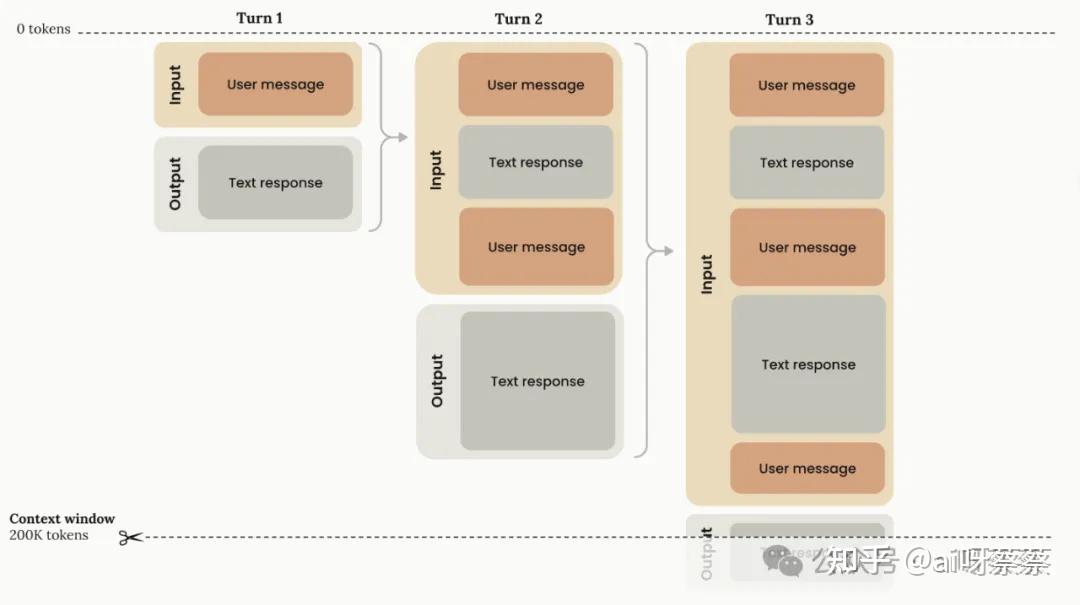
8、由于LLMs本身的这些局限无法彻底解决,所以目前Cursor、Trae、Cline等AI编程工具,都是围绕着这些局限去打造功能的。还有一些第三方工具,也在为克服上述的一个或多个局限推出相关产品。
9、对于代码生成的随机性,这些AI编程工具推出了Rules功能,通过给AI“立规范”来降低这种随机性。之前分享过多篇 Cursor Rules 的文章:
cursor教程 | 如何根据不同项目写好一份合格的cursorrules?
.cursorrules将被移除,大家现在就可以迁移使用Project Rules,控制代码更精准
Cursor Rules在实际开发中的三种层级&实际应用(附20个常用Rules)
10、为了进一步降低生成随机性,也为了更好地应对上下文局限,这些AI编程工具还提供了丰富的 Context(上下文)工具,以Cursor为例,它目前提供了10多种 Context 工具,包括但不限于@codebase、@file、@folder、@git 、@terminal、@web、@Cursor Rules(没错,Rules本身就是一种context)等。
11、在这些 Context 工具中,有一些是专门应对“消息滞后”局限的,比如@web 可以实现联网搜索,@docs 可以实现阅读外部文档,还有目前大火的MCP,理论上可以接入所有你可获取的外部工具/数据。关于MCP,可以看之前这篇文章>>>关于A2A、MCP、Agent、LLM的6条极简事实,比较简洁地介绍了MCP和目前LLMs、Agent的关系。
12、由于当前的 Context 工具并不能满足所有人的需求,一些第三方平台基于自己的洞察,结合自身业务,也推出了一些小工具来提升解决“消息滞后”问题的效率,比如之前分享的 Context7 以及它推出的MCP,可以自动获取最新的技术文档,而不需要我们手动复制粘贴。之前在这篇文章也介绍过Context7的用法>>>Cursor官方下场谈Cursor正确用法,以及我的实践解读
13、上述工具往往还可以组合起来使用,比如之前这篇文章>>>Windsurf v1.8.2最值得关注的更新:自定义工作流,介绍的是Windsurf怎么通过 Rules + Workflows + Memories 的方法让代码生成更可控。还有这篇文章>>>Cursor解决bug总在绕圈?可以尝试引入 Memory Bank,介绍的就是怎么通过Rules或自定义模式来建立Memory Bank,后续可以通过@file、@folder来快速理解项目,来克服AI的“健忘症”。
14、这让我想到最近很火的MCP项目——OpenMemory MCP,其实也是在做克服AI“健忘症”的事情,只不过解决的方向更加细分,是让不同工具之间(如Cursor、Claude Desktop、Windsurf、Cline)共享上下文信息。
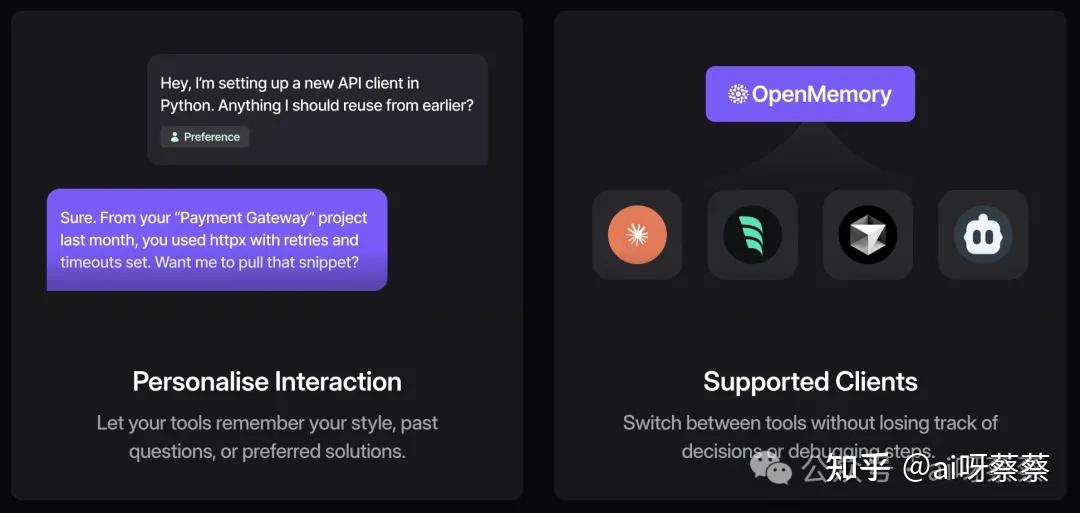
15、可以预想到的是,接下来还会涌现出更多类似 Context7、OpenMemory 的实用工具,用于解决当前AI编程某个细分场景下的问题。Cursor、Trae、Cline这类AI编程工具也会继续围绕前面提到的局限去发力,推出更多新能力去降低这些局限带来的影响。
16、而作为工具使用的我们,只要知道“所有的AI编程工具都是围绕这些局限打造功能的”,那么无论使用哪一款AI编程工具,都可以快速上手。
以上就是我这次线下分享的核心内容以及延展补充,希望对大家有启发。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/222304.html