

月之暗面最新开源了基于MoE架构的高效多模态模型Kimi-VL,它具有先进的多模态推理、长文本理解以及强大的agent能力,模型总参数为16B,但是推理时激活参数不到3B。
- 技术报告:https://github.com/MoonshotAI/Kimi-VL/blob/main/Kimi-VL.pdf
- 模型:https://huggingface.co/collections/moonshotai/kimi-vl-a3b-67f67b6ac91d3b03d382dd85
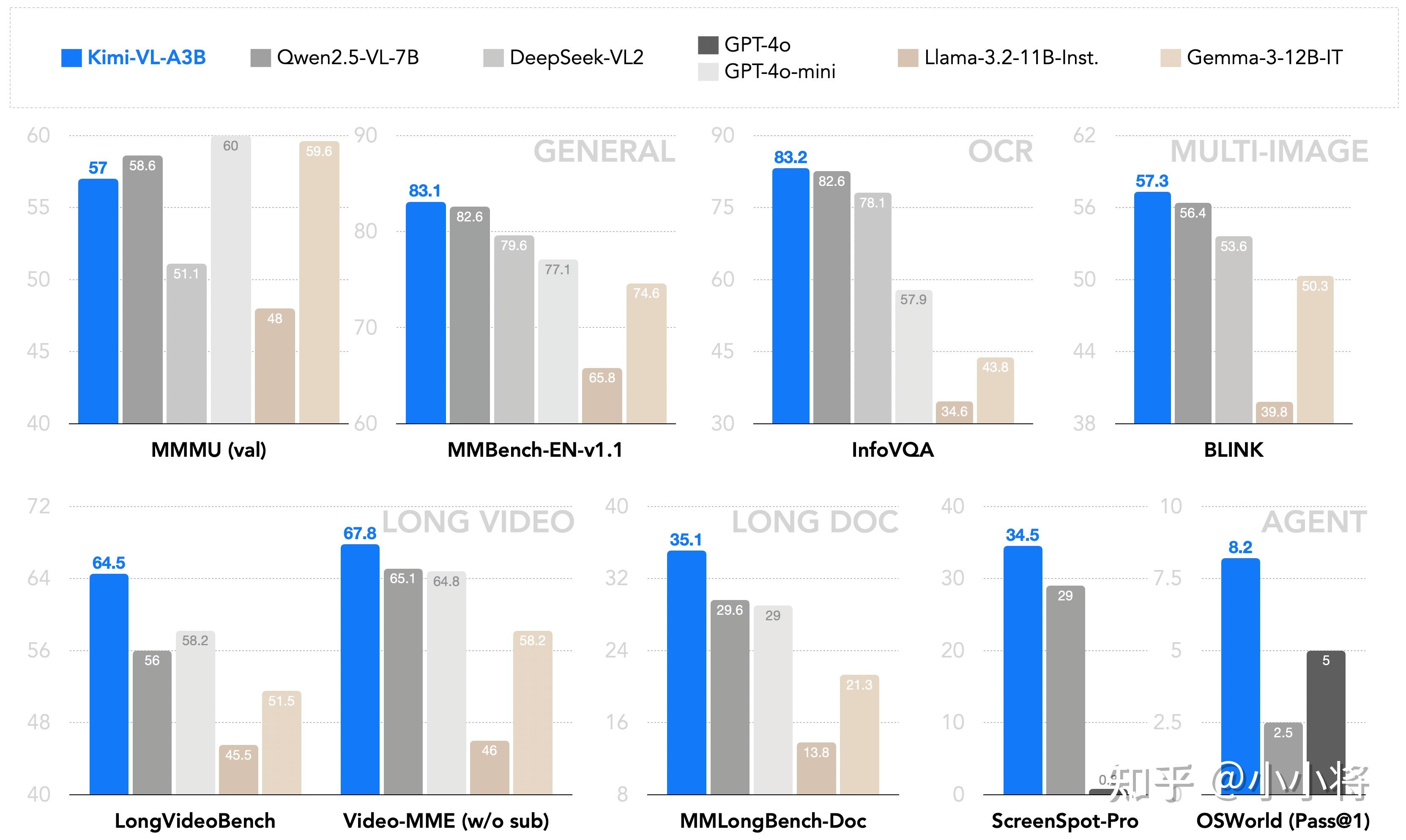
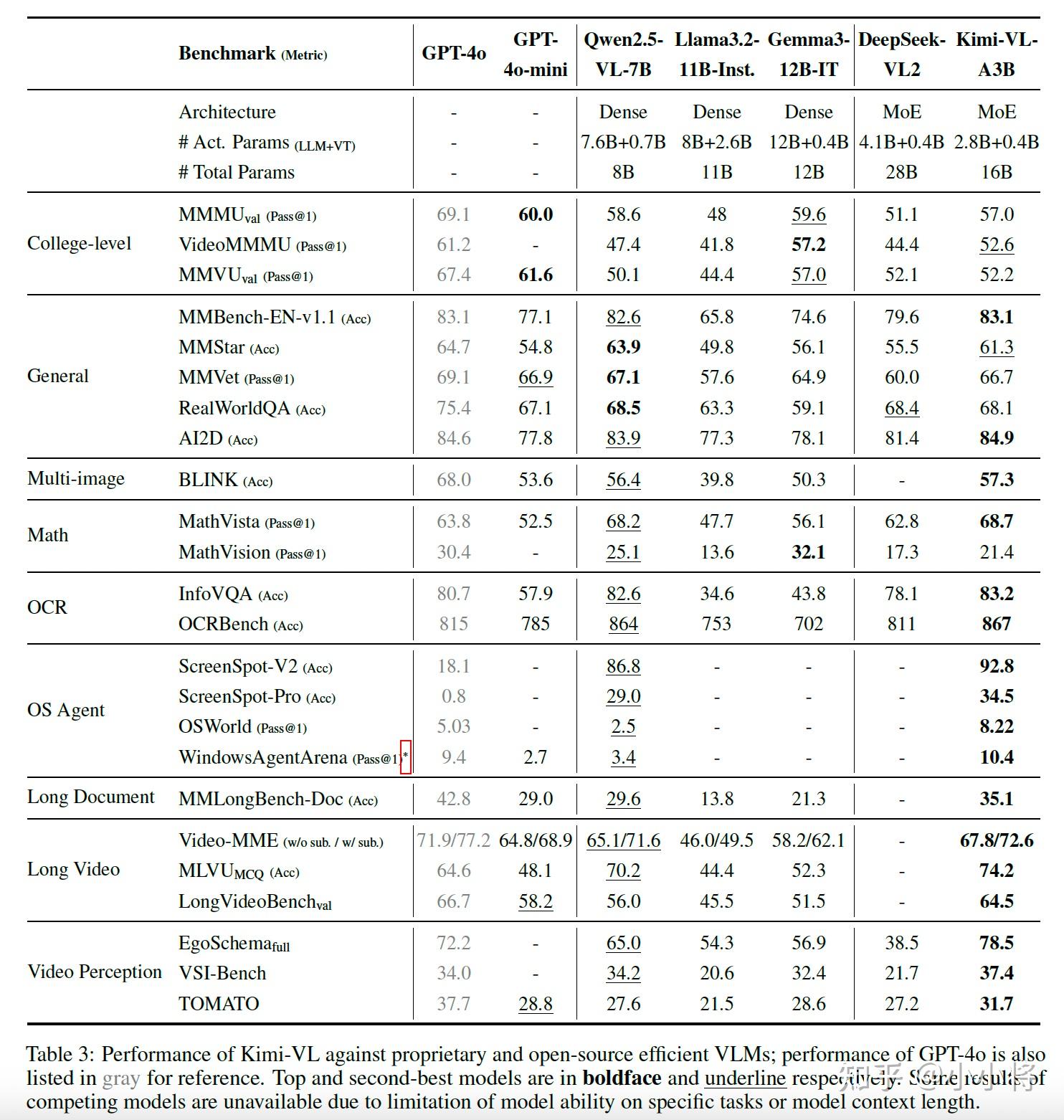
作为一个通用的VLM,Kimi-VL在多轮agent交互任务(例如OSWorld)中表现出色,取得了与旗舰模型相当的最先进的结果。此外,它在各种具有挑战性的视觉语言任务中展现出卓越的能力,包括大学级别的图像和视频理解、光学字符识别(OCR)、数学推理、多图像理解等。在基准测试中,它超过了GPT-4o-mini、Qwen2.5-VL-7B和Gemma-3-12B-IT等高效的VLM模型,同时在几个专业领域超越了GPT-4o。
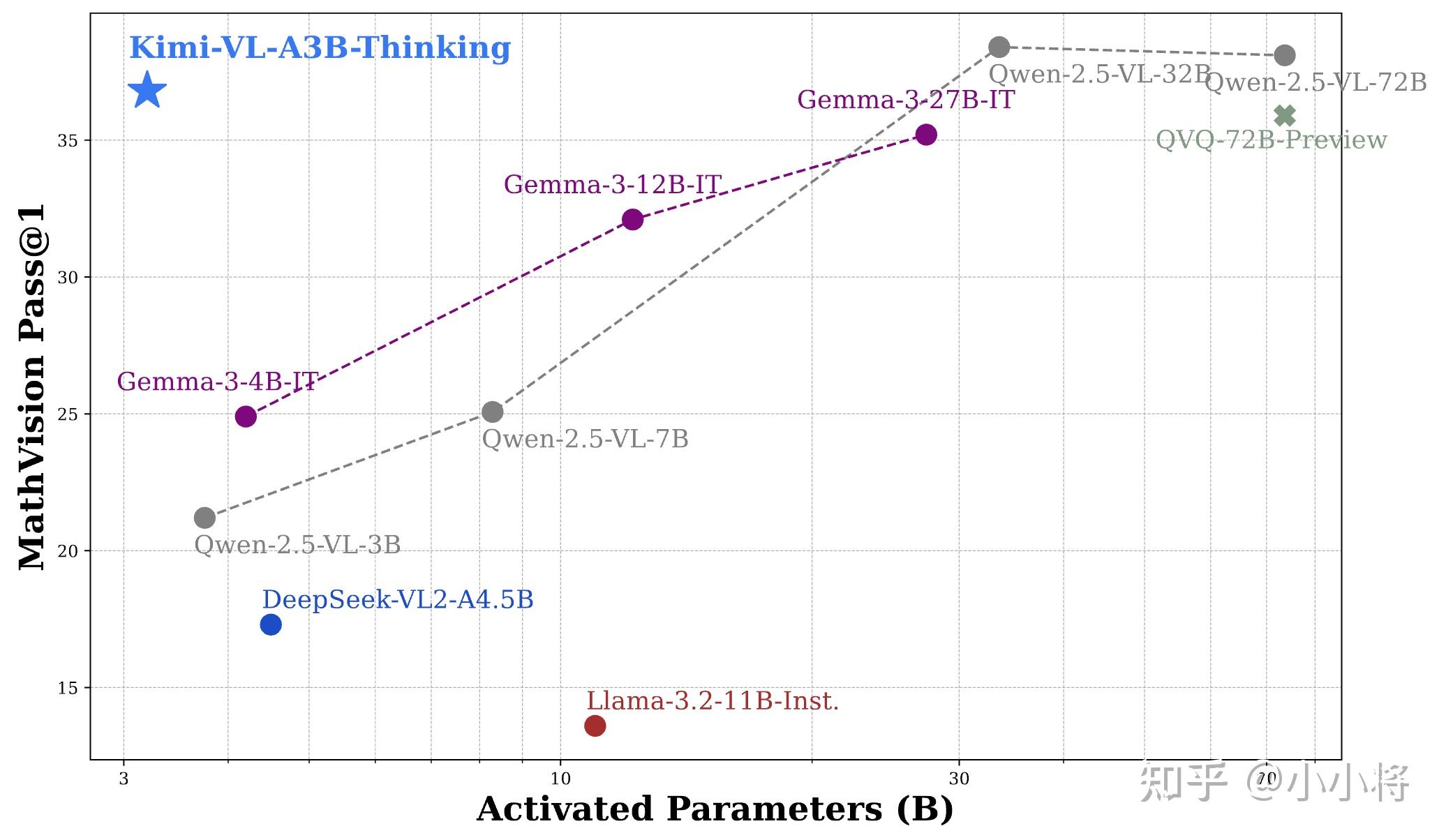
Kimi-VL还在处理长文本和清晰感知方面推进了多模态模型的帕累托前沿:配备了128K扩展上下文窗口,Kimi-VL能够处理长且多样化的输入,在LongVideoBench上得分64.5,在MMLongBench-Doc上得分35.1;其原生分辨率的视觉编码器MoonViT,进一步使其能够看到并理解超高分辨率的视觉输入,在InfoVQA上取得了83.2的分数,在ScreenSpot-Pro上取得了34.5的分数,同时在处理常见视觉输入和一般任务时保持较低的计算成本。
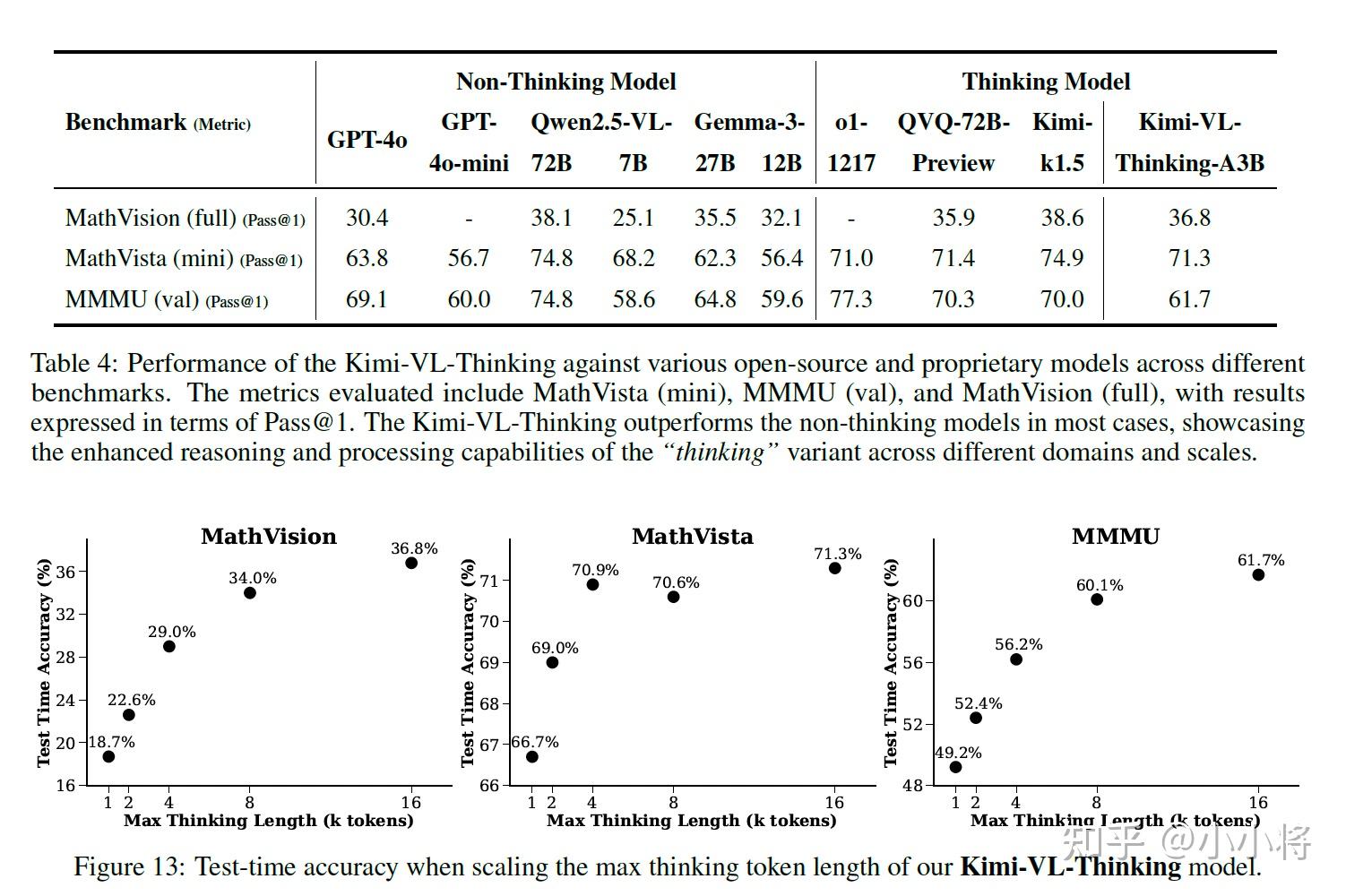
在Kimi-VL基础上,月之暗面还推出了支持推理的多模态模型:Kimi-VL-Thinking。通过长链推理(CoT)监督微调(SFT)和强化学习(RL),该模型展现出强大的长期推理能力。它在MMMU上取得了61.7的分数,在MathVision上取得了36.8的分数,在MathVista上取得了71.3的分数。
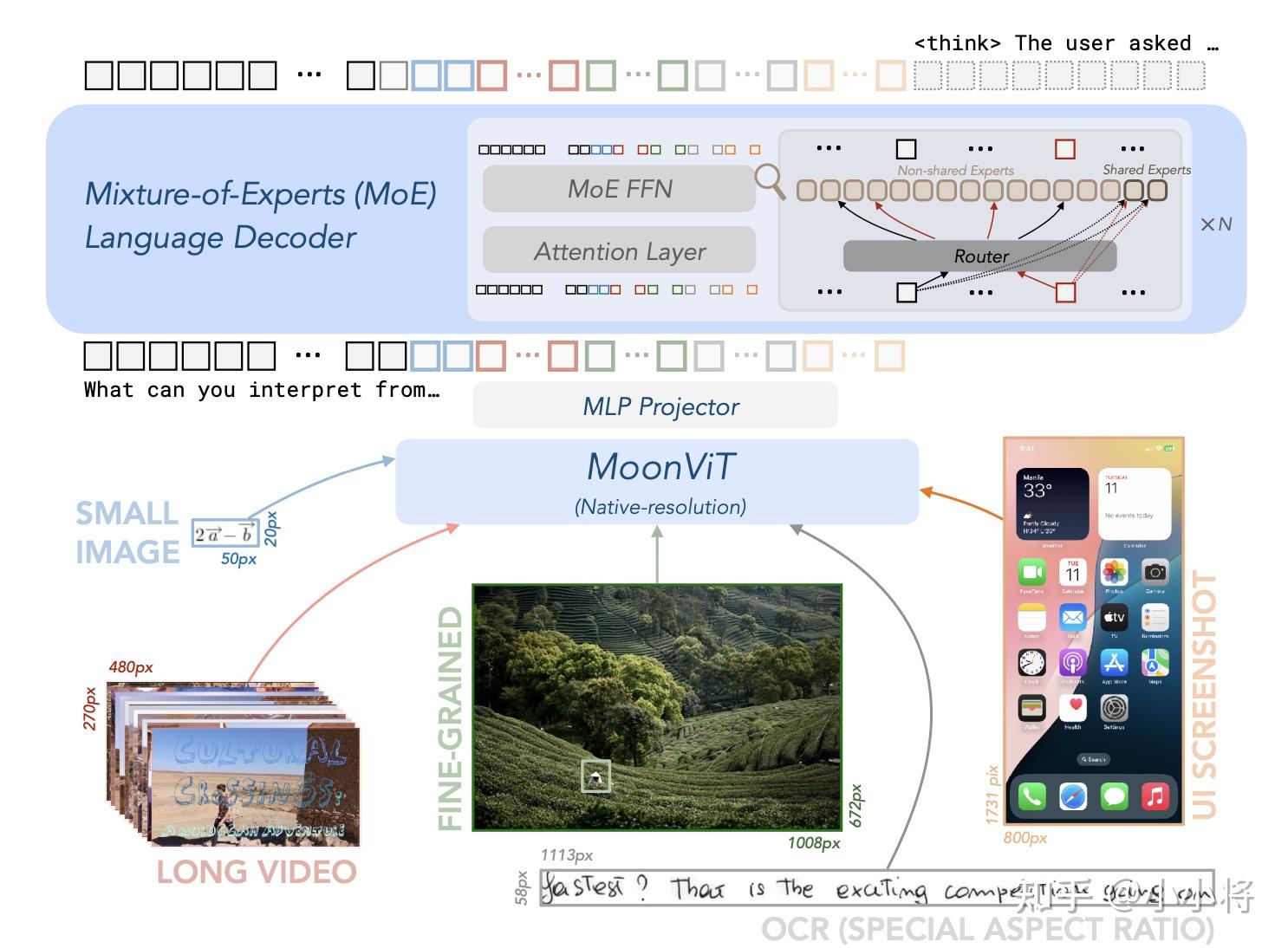
在模型架构上,Kimi-VL采用了专家混合(MoE)语言模型(之前发布的Moonlight-16B-A3B)、原生分辨率的视觉编码器(MoonViT,基于SigLIP-SO-400M微调)以及一个多层感知机(MLP)投影器,如下图所示。
在加载语言模型之后,Kimi-VL的预训练总共包括4个阶段,总共过了4.4T tokens:首先,独立进行ViT训练,以建立一个健壮的原生分辨率视觉编码器,随后是三个联合训练阶段(预训练、冷却和长上下文激活),这些阶段同时增强模型的语言和多模态能力。具体细节如下:

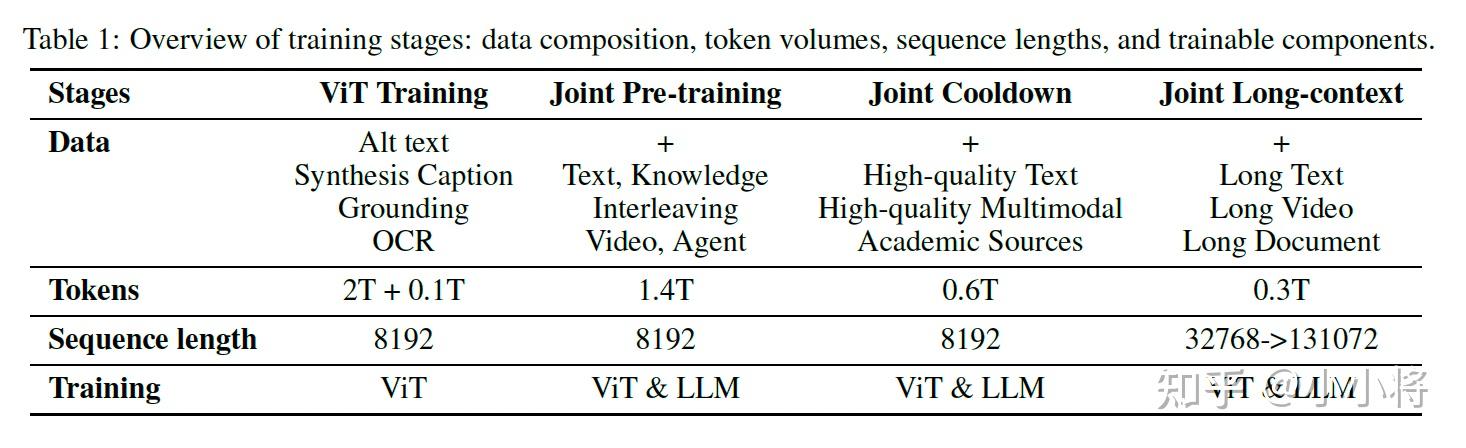
Kimi-VL和Kimi-VL-Thinking的后训练阶段包括在32K和128K上下文中进行的两个阶段的联合监督微调(SFT),以及进一步的长链推理(CoT)监督微调和强化学习(RL)阶段,以激活和增强长期思考能力。

下面是Kimi-VL在一系列基准测试上和其他模型的对比详情:
下面是Kimi-VL一些具体的例子:





目前Kimi-VL已经支持transformers库来使用,具体如下:
from PIL import Image from transformers import AutoModelForCausalLM, AutoProcessormodel_path = “moonshotai/Kimi-VL-A3B-Instruct” model = AutoModelForCausalLM.from_pretrained(
model_path, torch_dtype="auto", device_map="auto", trust_remote_code=True, ) processor = AutoProcessor.from_pretrained(model_path, trust_remote_code=True)
image_path = “./figures/demo.png” image = Image.open(image_path) messages = [
{"role": "user", "content": [{"type": "image", "image": image_path}, {"type": "text", "text": "What is the dome building in the picture? Think step by step."}]} ] text = processor.apply_chat_template(messages, add_generation_prompt=True, return_tensors=“pt”) inputs = processor(images=image, text=text, return_tensors=“pt”, padding=True, truncation=True).to(model.device) generated_ids = model.generate(inputs, max_new_tokens=512) generated_ids_trimmed = [
out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids) ] response = processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False )[0] print(response)
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/220086.html