
2025年10月20日,deepseek首次发布了OCR模型,本文记录了在本地环境中部署的完整过程,并简单地进行了OCR识别的效果测试。
- 操作系统:Windows 11专业版(WSL2)
- Python 版本:3.12.9
- GPU:RTX 4090
依托python3.12.9构建了虚拟环境, 如图1所示。
(1)安装torch库
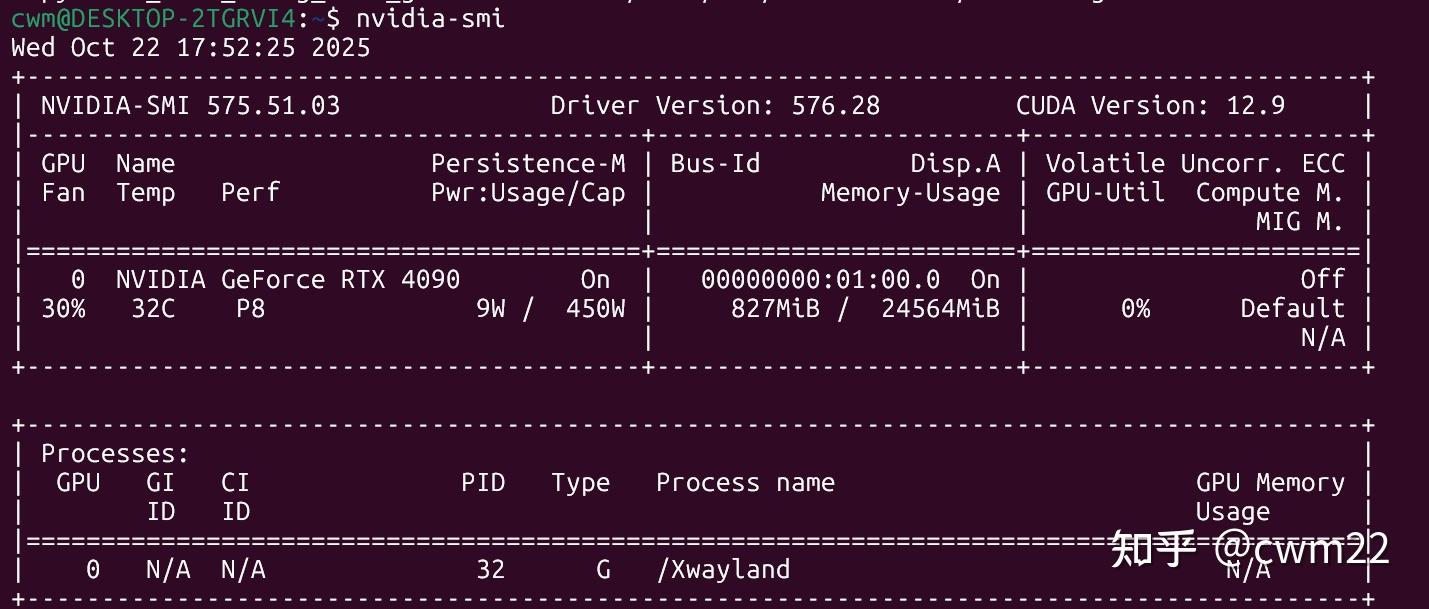
首先安装gpu版本的torch库,在安装之前,请先通过 nvidia-smi 命令查看当前 NVIDIA 驱动所支持的最高 CUDA 版本。如图2所示,输出显示 CUDA Version: 12.9,则表示我的驱动最多支持 CUDA 12.9。
安装 torch 时,应选择 CUDA 版本 ≤ 12.9 的GPU 构建版本(如 cu121、cu118 等),不可选择高于 12.9 的 CUDA 版本,否则可能导致兼容性问题或无法使用 GPU 加速。
安装模型推荐的torch2.6.0的命令
pip install torch==2.6.0 torchvision==0.21.0 torchaudio==2.6.0 –index-url https://download.pytorch.org/whl/cu126(2)安装相关库
在torch库安装成功后,依次安装下述版本的库,往往会比较顺利。
transformers==4.46.3 tokenizers==0.20.3 einops addict easydict(3)安装flash-attn库
flash-attn库也可以不用安装,不影响正常推理,该库主要用于推理的加速。如果直接安装flash-attn库往往会报错,我的报错内容如图3所示。
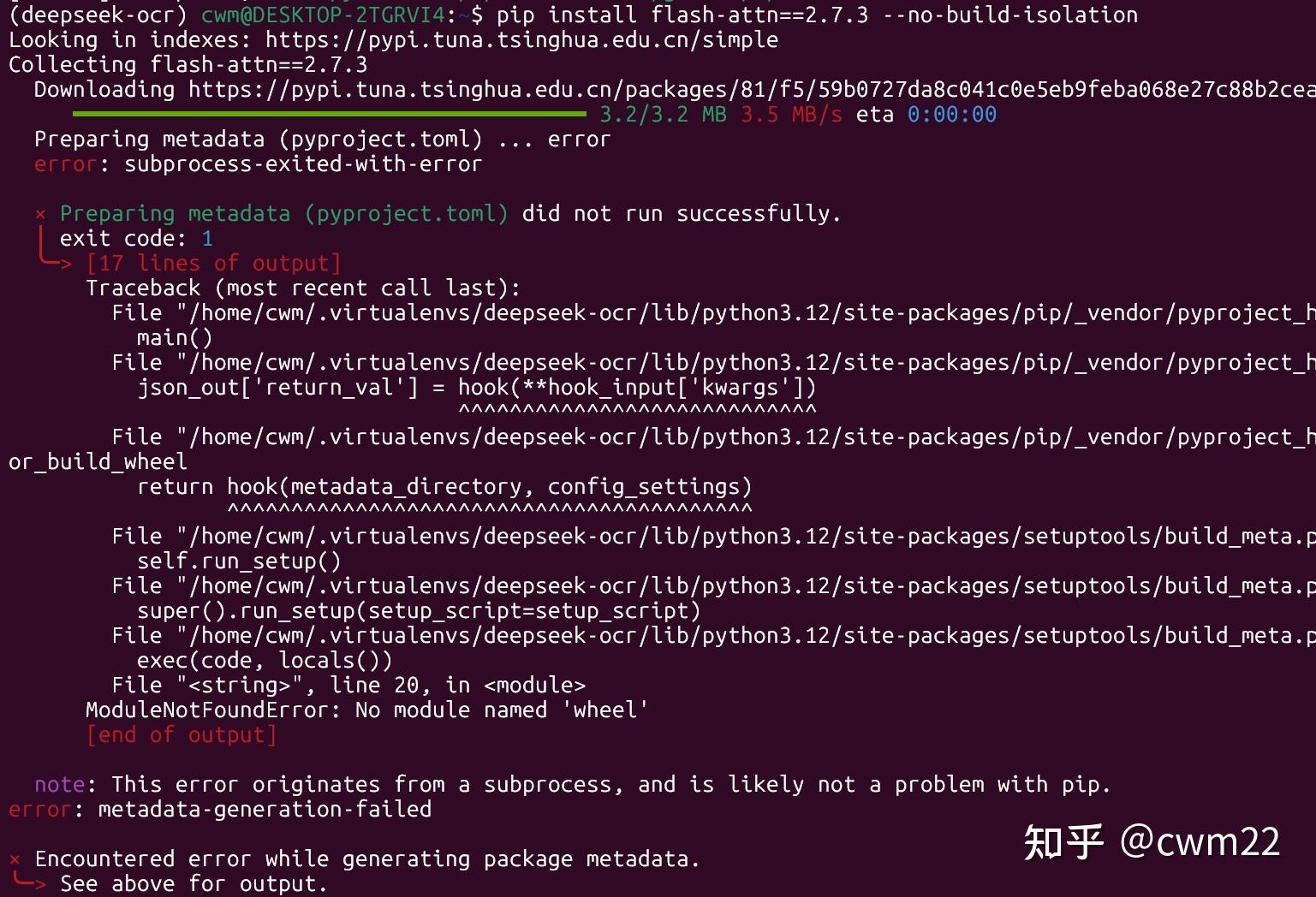
为了解决上述问题,应首先安装依赖
pip install wheel setuptools packaging然后,重新安装flash-attn,该库的安装过程非常非常慢,耗时约3小时。
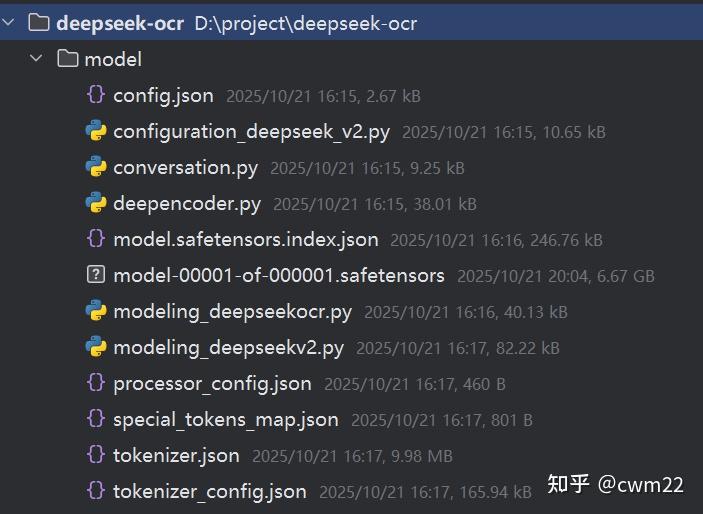
pip install flash-attn==2.7.3 –no-build-isolation从hugging face上下载deepseek-ocr相关的模型和代码,具体文件如图4所示,我把这些文件放在了本地的model目录中。
在项目目录中创建了infer模块,该模块的推理代码为
from transformers import AutoModel, AutoTokenizer import torch import os os.environ[“CUDA_VISIBLE_DEVICES”] = ‘0’ model_name = ‘model’tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
# 如果安装了flash-attn,通过设置进行加速推理 # model = AutoModel.from_pretrained(model_name, _attn_implementation=‘flash_attention_2’, trust_remote_code=True, use_safetensors=True)
# 如果没有安装flash-attn,无需设置 model = AutoModel.from_pretrained(model_name, trust_remote_code=True, use_safetensors=True) model = model.eval().cuda().to(torch.bfloat16)
prompt = “\n<|grounding|>Convert the document to markdown. ” image_file = ‘test_data/p1.jpg’ output_path = ‘output’ res = model.infer(tokenizer, prompt=prompt, image_file=image_file, output_path = output_path, base_size = 1024, image_size = 640, crop_mode=True, save_results = True, test_compress = True)
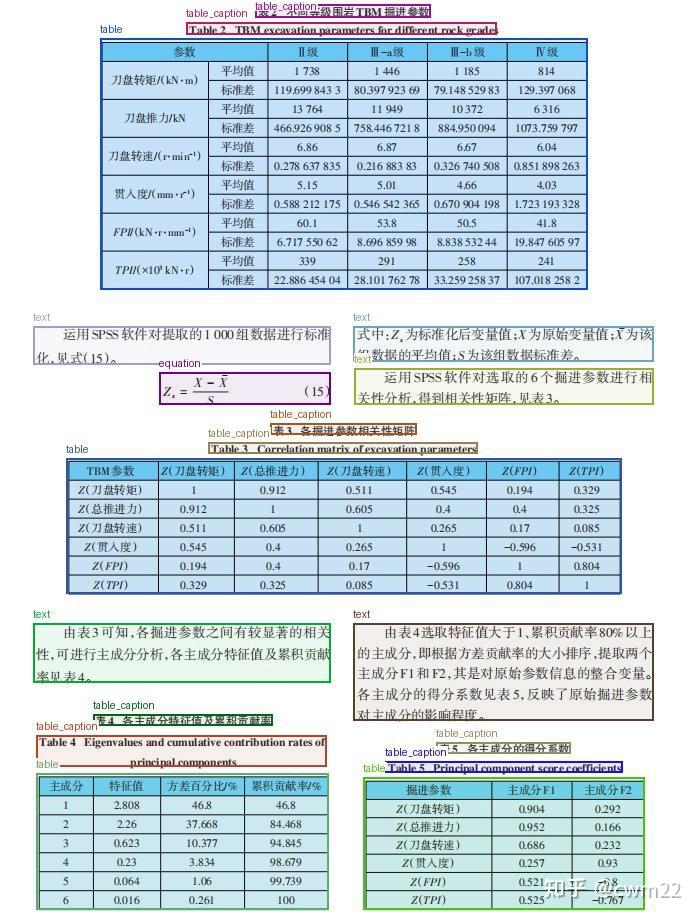
从中国知网上随机下载了一篇论文,并截图作为输入图像对模型进行了测试,结果如图5-7。可以看到准确地识别了文本信息、表格、图、公式,甚至文章标题、子标题、图标题、表标题也准确地识别了出来。唯一的缺陷是,页眉和页脚区域没有识别出来。


对真实的街景数据进行了测试,如图8-12所示。图8中小的电话号码也准确地识别出来了,但是文本的位置不对。图10出现了漏检。图12运行了多次,模型均无法提取出任何文本信息。相对文档型图片,对真实街景图片的识别精度明显偏低。





版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/219196.html