
你是不是经常想抓点网页数据,却被“不会写代码”这道坎拦住了?
别担心,这篇文章就是为你准备的。
不用懂编程,只要会描述需求,剩下的交给 AI。
准备好了吗?我们马上开始!
开工前,先准备下环境。
用到两个主角:Cursor 和 Python。
Cursor 负责写代码,Python 负责跑代码,它是爬虫界的天选之子。
都能在官网直接下载,安装过程很简单,一路下一步就行。
- Cursor
下载地址:https://www.cursor.com/
- Python
下载地址:https://www.python.org/downloads/
本文基于 Cursor 0.49.6、Python 3.12。
环境准备好了,下面开始。
随便找一个网站,比如:https://mcpservers.org/
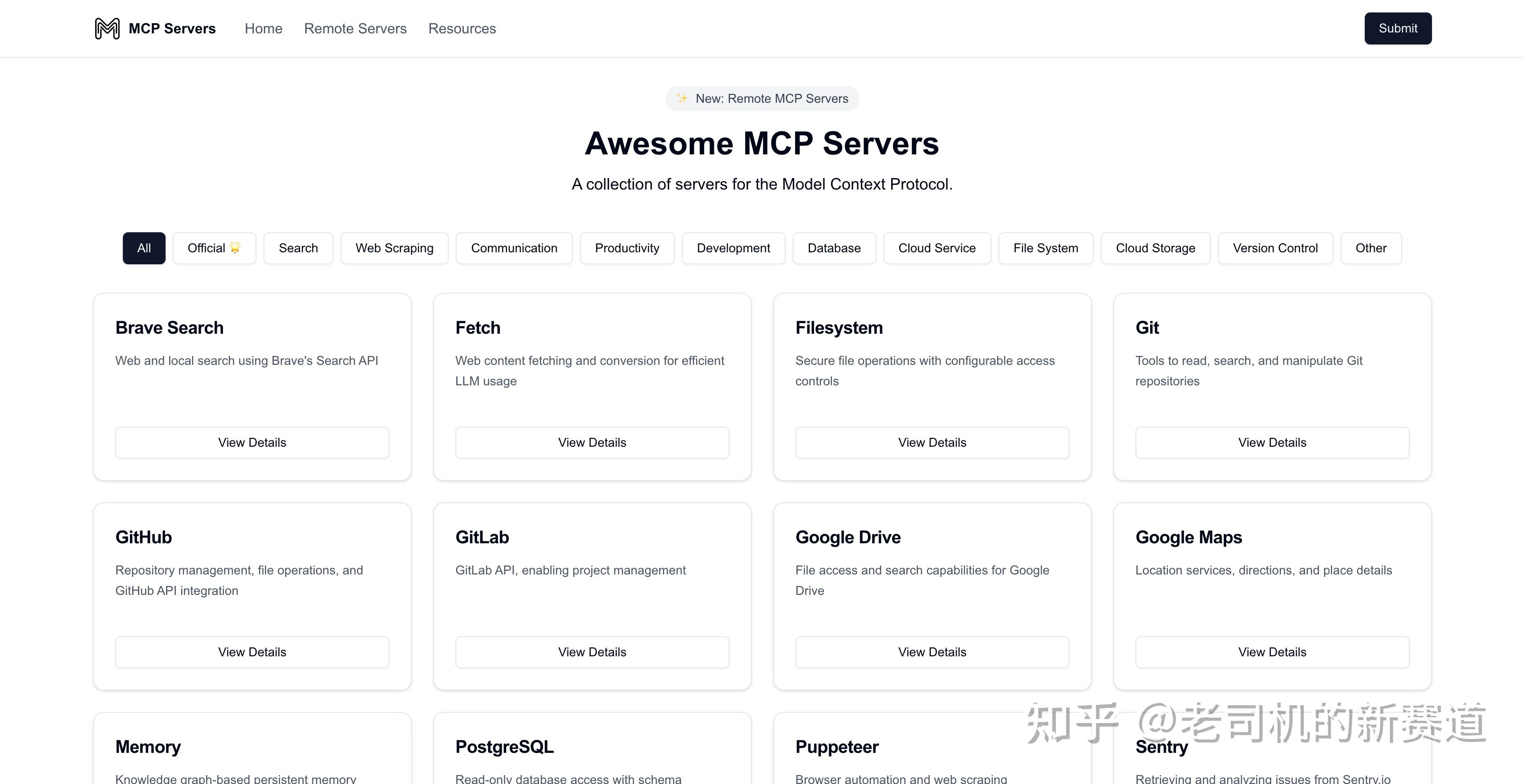
需求很简单:把这个网站上所有 MCP Servers 的信息都爬下来。
包括每张卡片里的标题、描述和网址,最后保存成一个 JSON 文件。
接下来,先看看网页长啥样。
我们能看到有很多“卡片”,里面的数据就是我们需要的。
这些卡片都被装在一个大容器里。
我们进一步分析下网页的 HTML 代码结构。
用 Chrome 浏览器,按 F12,打开开发者工具。
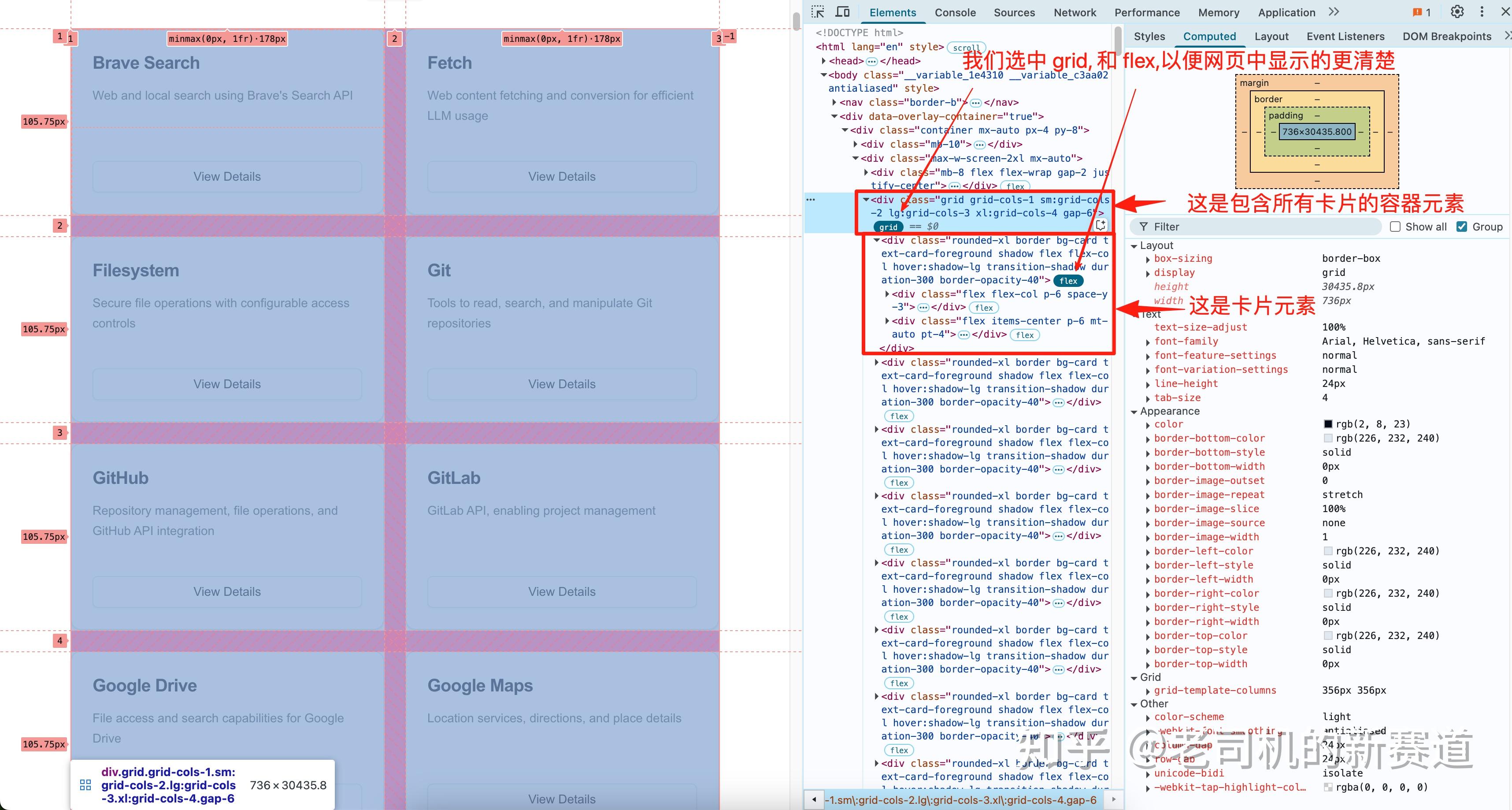
图中红色箭头指向的 grid 元素,就是装卡片的父级元素; 箭头指向的 flex 元素是单张卡片。
为方便理解,我把 grid 和 flex 都选中了,这样左边的网页就会高亮显示布局了。
搞清楚这些层级关系,后面提取数据就简单多了。
打开 Cursor 的聊天页面,并选择 Agent 模式。
输入以下提示词:
帮我写一个 python 程序,爬取 @https://mcpservers.org/ 上的所有 MCP Servers 列表,要求如下:- 抓取 class=grid grid-cols-1 sm:grid-cols-2 lg:grid-cols-3 xl:grid-cols-4 gap-6 元素下的所有 class=rounded-xl border bg-card text-card-foreground shadow flex flex-col hover:shadow-lg transition-shadow duration-300 border-opacity-40 的子元素。
- 循环提取每个子元素的 title, description, url 三个属性。
- 将提取的内容保存到一个 data/mcp-servers.json 文件中。
以下是 Grid 中某个元素的 HTML 标签内容:
提示词很简单:先是列出三条规则,后面跟了一个卡片元素的 HTML 示例。
第一条规则:指示了如何定位父容器元素以及子元素
抓取 class=grid grid-cols-1 sm:grid-cols-2 lg:grid-cols-3 xl:grid-cols-4 gap-6 元素下的所有 class=rounded-xl border bg-card text-card-foreground shadow flex flex-col hover:shadow-lg transition-shadow duration-300 border-opacity-40 的子元素。
- 父元素的 class 对应截图中带有 grid 标识的那个元素的 class 值。
- 同理,子元素的 class 就是那个 flex 元素的 class 值。
第二条:写明希望抽取哪些信息。
循环提取每个子元素的 title, description, url 三个属性。
第三条:写明期望的数据格式,及保存路径。
将提取的内容保存到一个 data/mcp-servers.json 文件中。
最后一条规则:
主要是给一个从网页中复制的元素 HTML 示例,说明需要提取的 title、description、url 三个属性所在元素的 HTML 结构。
我懒得写。因为要为这三个属性详细指定如何定位?太麻烦!
这些麻烦事,应该由 AI 去主动理解并搞定。
我就直接将卡片元素的 HTML(在前文截图中开发者工具中找)拷贝到输入框中了。
提示词写好后,剩下的就交给 Cursor 吧。
确认一下模式是不是 Agent,没问题就点“发送”。

Cursor 在 Agent 模式下会自动写代码、运行代码、生成文件,全程不用你操心。
以下是我的配置项:

只需要等一小会,结果会出来。
运行结束后,打开 data/mcp-servers.json 文件,就能看到结果。
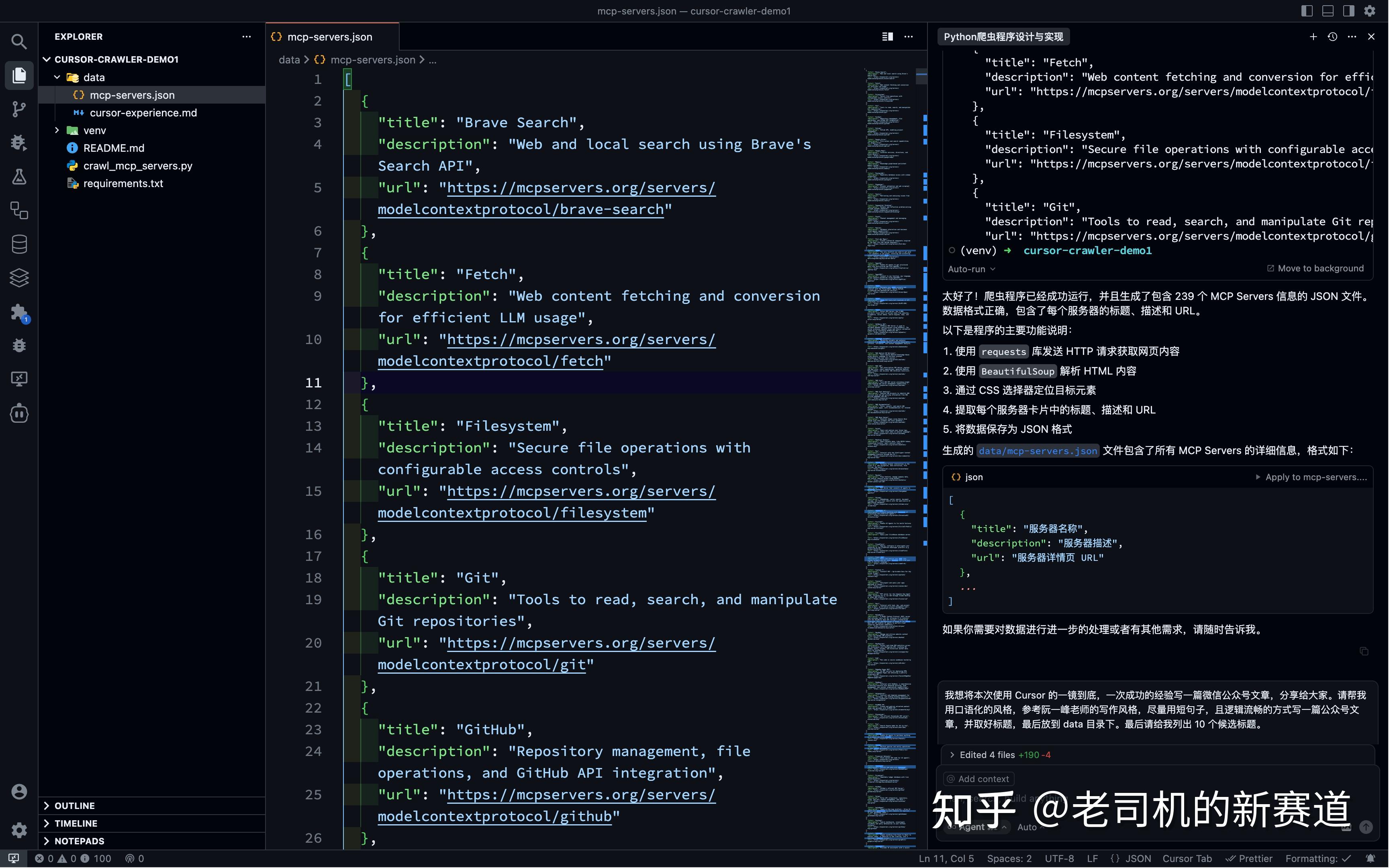
整个过程,我们几乎没有动手,但数据已经到手了。
是不是很有成就感?
就是写了一些提示词,然后等着收货。
额外说明下,模型选择的是 auto,没有选代码能力最强的模型,比如: Claude 3.7 Sonnet 或 Gemini 2.5 Pro。
因为没必要。对于这种简单的任务,很多小模型也能处理的很好。
爬虫的本质是读取页面 HTML 后提取数据。
只用掌握一点网页知识,配合如今的 AI 辅助编程工具,这项任务现在已经变得很简单了。
虽然我用的是 Cursor,但其他 AI 辅助编程工具如 Windsurf、Trae、VSCode + Cline 等也是一样的。
对于独立任务,且从空项目开始的,Cursor 的 Agent 模式是首选。
对于如何绕开反爬机制,使用无头浏览器进行登陆验证,等高级爬虫技术,不在本文讨论范围内。
建议大家也去试试吧,体验一下 AI 编程的乐趣。
希望这篇文章对你有所帮助。如果觉得有用,欢迎点赞、收藏、转发。
也欢迎关注我,一起学习 AI 知识。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/217651.html