
随着生成式AI技术的快速发展,文本到语音(Text-to-Speech, TTS)和语音转换技术在内容创作、虚拟助手、无障碍服务等场景中展现出巨大潜力。GPT-SoVITS 作为当前备受关注的开源语音合成项目,融合了GPT的序列生成能力与SoVITS(Soft Voice Conversion with Text-to-Speech)的高保真语音转换机制,实现了高质量、低样本依赖的声音克隆功能。
本教程将围绕 GPT-SoVITS 镜像环境的使用流程 展开,重点介绍如何通过可视化界面(WEBUI)完成语音相似度评估任务,帮助开发者和研究人员快速上手并应用于实际项目中。文章属于 教程指南类(Tutorial-Style) 内容,遵循从零开始、分步实践的原则,确保读者能够在短时间内掌握核心操作流程。
2.1 核心特性解析
GPT-SoVITS 是一个基于深度学习的端到端语音合成与转换框架,其主要特点包括:
- 极低样本需求:仅需5秒目标说话人音频即可实现初步声音克隆。
- 支持微调优化:提供完整训练流程,使用1分钟以上高质量音频进行模型微调,显著提升音色还原度。
- 多语言兼容性:支持中文为主,部分版本适配英文及其他语种。
- 开源可扩展:代码完全公开,社区活跃,便于二次开发与集成。
该模型的核心架构由两部分组成:
- GPT 模块:负责建模语音的韵律、节奏和上下文连贯性,提升自然度。
- SoVITS 模块:基于VAE(变分自编码器)结构,提取声学特征并实现跨说话人的音色迁移。
二者结合,使得系统既能保持原始文本语义的准确表达,又能高度还原目标说话人的音色特征。
2.2 应用场景举例
- 虚拟主播/数字人配音
- 个性化语音助手定制
- 影视后期配音替换
- 有声书自动化生成
- 语音情感迁移实验
这些应用均依赖于对“语音相似度”的精准控制与评估,因此掌握相关工具的使用至关重要。
本节为实操部分,指导用户通过预置镜像环境快速启动 GPT-SoVITS 并完成一次完整的语音相似度评估任务。
3.1 环境准备
GPT-SoVITS 的部署通常涉及复杂的依赖安装(如PyTorch、CUDA、FFmpeg等)。为降低门槛,推荐使用 CSDN星图平台提供的预配置镜像,该镜像已集成以下组件:
- Python 3.9 + PyTorch 1.13
- GPT-SoVITS 最新主分支代码
- Gradio 构建的 WEBUI 界面
- 常用音频处理库(librosa, soundfile, ffmpeg)
无需手动编译或下载模型权重,一键启动即可进入交互界面。
提示:访问 CSDN星图镜像广场 搜索 “GPT-SoVITS” 即可获取最新可用镜像。
3.2 启动与入口定位
Step 1:进入 GPT-SoVITS 显示入口
登录平台后,在应用列表中找到 GPT-SoVITS 图标,点击进入服务详情页。

此页面显示当前实例状态、资源占用情况及访问方式说明。
Step 2:打开 WEBUI 界面
点击“启动服务”按钮后,系统会自动拉起 Gradio Web 服务。待状态变为“运行中”,点击“打开 WEBUI”链接,跳转至如下界面:
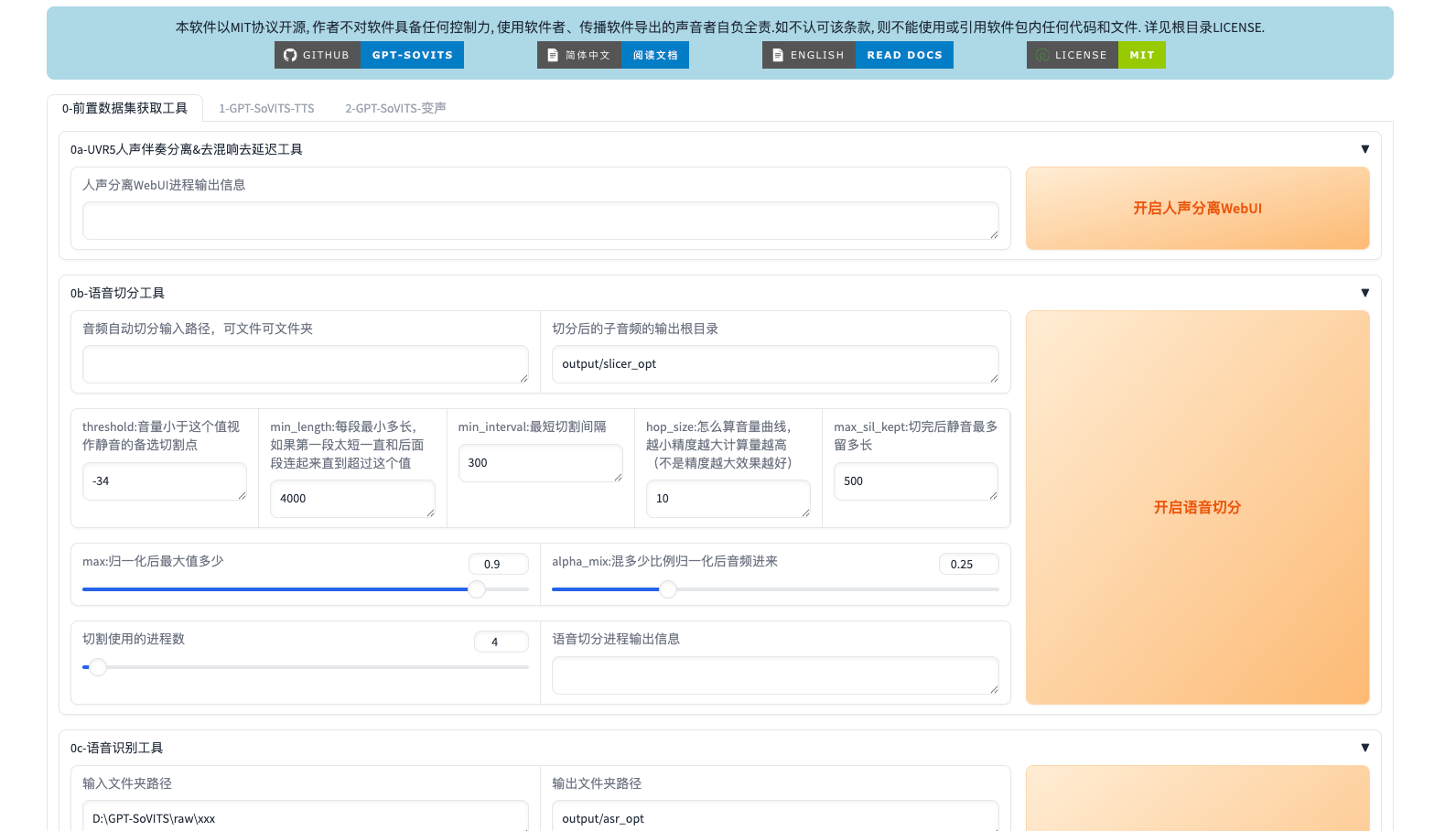
该界面即为 GPT-SoVITS 的主操作面板,包含多个功能模块,涵盖推理、训练、语音对比等功能。
3.3 语音相似度评估流程详解
语音相似度评估是验证声音克隆效果的关键环节。以下是具体操作步骤:
Step 1:上传参考音频
在 WEBUI 的 Inference(推理) 标签页中,找到“Reference Audio”上传区域,上传一段目标说话人的原始语音(建议时长10~30秒,清晰无背景噪音)。
系统将自动提取该音频的音色嵌入向量(Speaker Embedding),用于后续合成过程中的音色匹配。
Step 2:输入待合成文本
在下方“Text”输入框中填写希望合成的文本内容,例如:
注意:文本语言应与训练数据一致(默认为中文),避免出现生僻字或特殊符号。
Step 3:选择模型与参数
- Model Selection:选择已加载的预训练模型(如 )
- GPT Model:对应选择
- Temperature:控制生成随机性,建议设置为 0.6~0.8
- Top-K / Top-P:采样策略参数,保持默认值即可
Step 4:执行推理并播放结果
点击 “Generate” 按钮,系统将在数秒内生成合成语音,并在右侧输出区域展示波形图与播放控件。
此时可反复试听,主观判断音色是否接近原始参考音频。
Step 5:客观相似度评分(可选)
部分增强版镜像集成了 语音相似度打分模块(基于 ECAPA-TDNN 或 ResNetSE 模型),可通过以下方式启用:
说明:得分越接近1.0,表示音色匹配度越高;一般认为 >0.75 为良好克隆效果。
3.4 常见问题与解决方案
4.1 提升音色还原度的方法
- 增加参考音频长度:使用30秒以上连续语音,覆盖更多发音组合。
- 微调模型(Fine-tuning):若拥有更长的目标语音(≥1分钟),可进入“Train”标签页进行局部训练。
- 调整语速与停顿:在文本前后添加 表示短暂停顿,有助于改善语流自然度。
4.2 批量合成自动化脚本示例
对于需要批量生成语音的场景,可编写 Python 脚本调用 API 接口:
注意:需确认 WEBUI 开启了 API 支持(通常位于 中配置 FastAPI 路由)。
4.3 安全与合规提醒
尽管 GPT-SoVITS 功能强大,但在使用过程中应注意:
- 禁止未经授权的声音模仿:不得用于伪造他人语音进行欺骗或传播虚假信息。
- 遵守平台使用协议:镜像服务可能受资源配额限制,请合理使用计算资源。
- 数据本地化处理:敏感语音数据建议在本地环境中运行,避免上传至公共平台。
本文介绍了 GPT-SoVITS 的基本原理及其在语音相似度评估中的实际应用流程。对于初学者,建议按以下路径深入学习:
- 熟练掌握镜像环境下的推理操作
- 尝试使用不同参考音频观察合成效果差异
- 阅读官方 GitHub 仓库文档,了解训练细节
- 结合 Whisper 等ASR工具构建完整语音处理流水线
- 探索与其他TTS模型(如VITS、ChatTTS)的对比与集成
- GitHub 项目地址:https://github.com/RVC-Boss/GPT-SoVITS
- 详细使用教程:GPT-SoVITS使用 - CSDN博客
- ECAPA-TDNN 说话人验证模型:https://github.com/TaoRuijie/Speaker-Verification
获取更多AI镜像
想探索更多AI镜像和应用场景?访问 CSDN星图镜像广场,提供丰富的预置镜像,覆盖大模型推理、图像生成、视频生成、模型微调等多个领域,支持一键部署。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/217638.html