
- https://docs.langchain4j.dev/tutorials/chat-memory/

记忆缓存是聊天系统中的一个重要组件,用于存储和管理对话的上下文信息。它的主要作用是让AI助手能够”记住”之前的对话内容,从而提供连贯和个性化的回复。
我们随便打开一个大模型对话聊天就明白了。
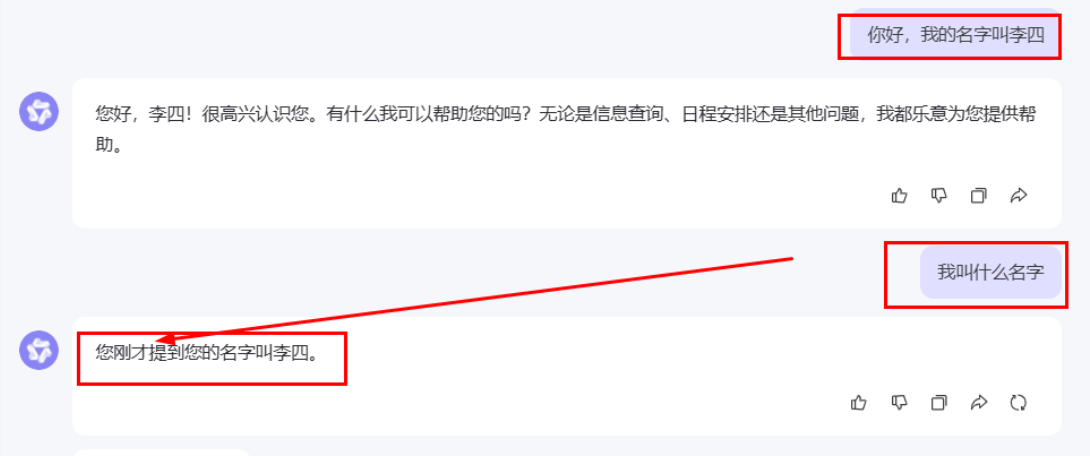
简单的理解就是:一个让大模型可以记住我们上面一段历史内容上对它的提问,和索引需要的内容:


官方解释:LangChain4j提供了2种开箱即用的记忆缓存的实现方式如下:
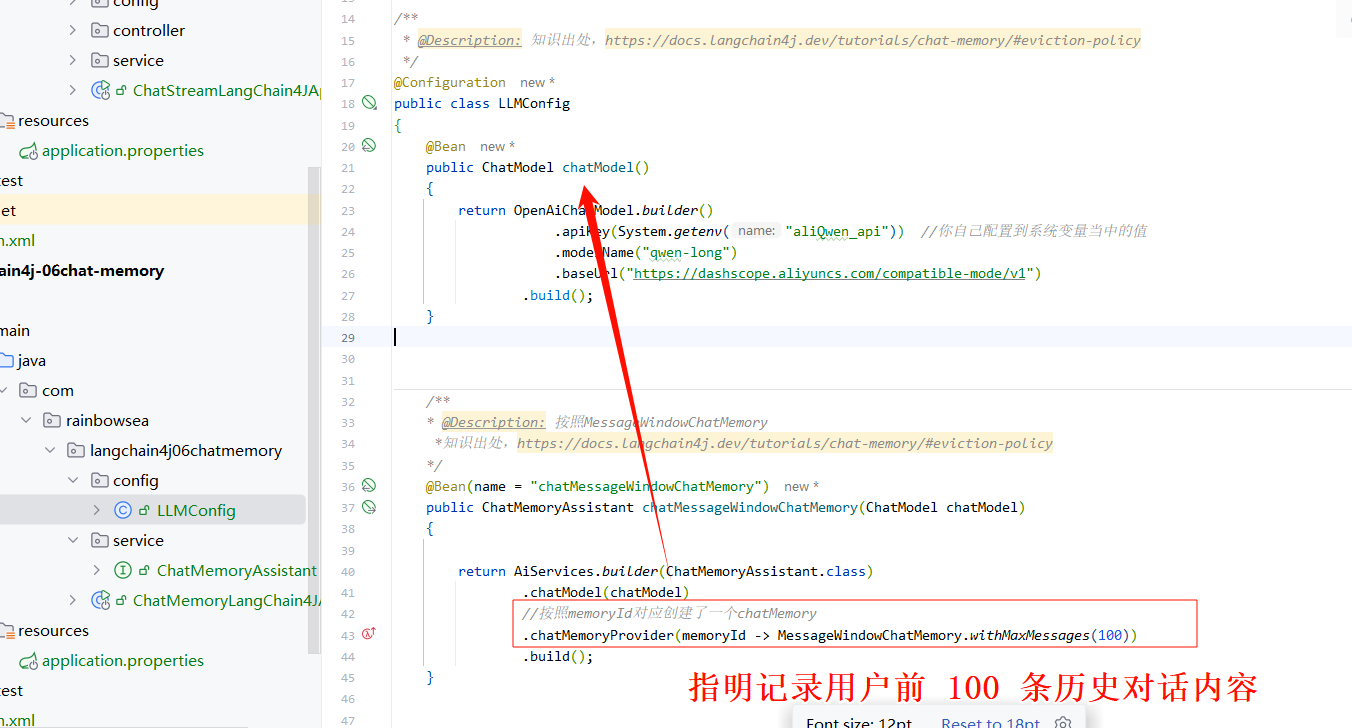
- 一种是:通过提问的条数,记忆几条提问记录信息。比如:记忆存储你提问的前 100 条的记录内容。推荐
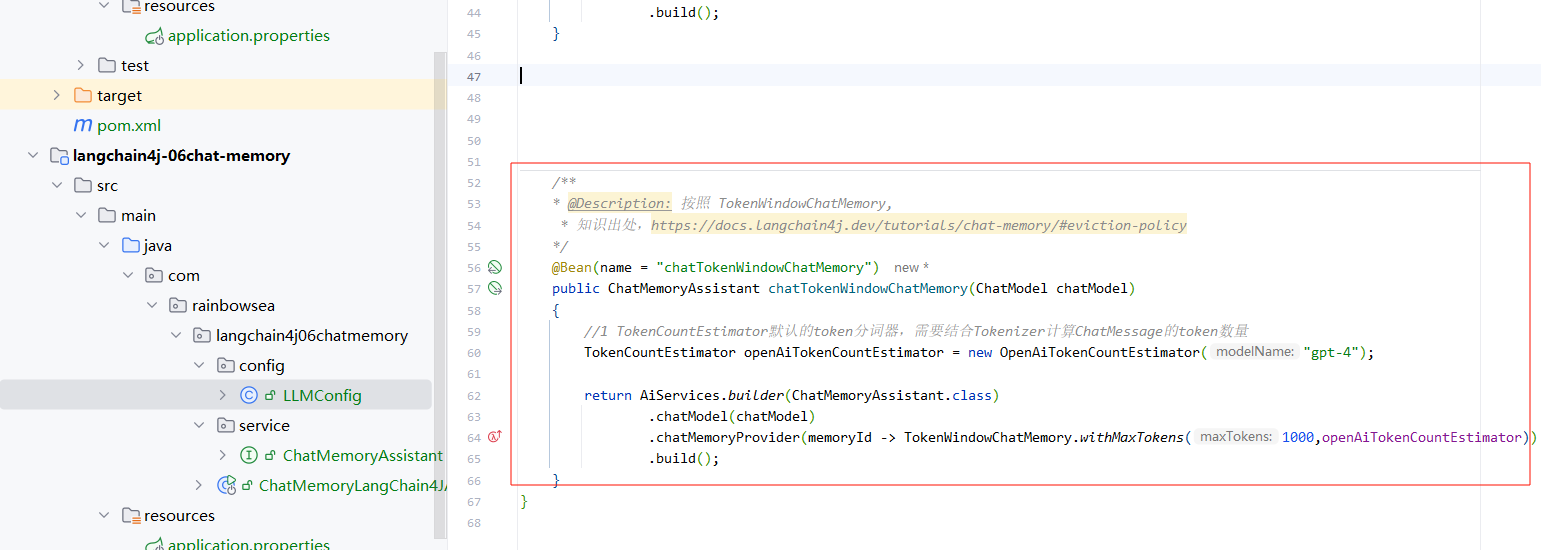
- 第二种:则是通过记忆存储你的 token 数目,这种方式不推荐,因为不同的大模型的 token 计算的方式不同。


- 创建对应项目的 module 模块内容:
- 导入相关的 pom.xml 的依赖,这里我们采用流式输出的方式,导入这三件必须存在,这里我们不指定版本,而是通过继承的 pom.xml 当中获取。_
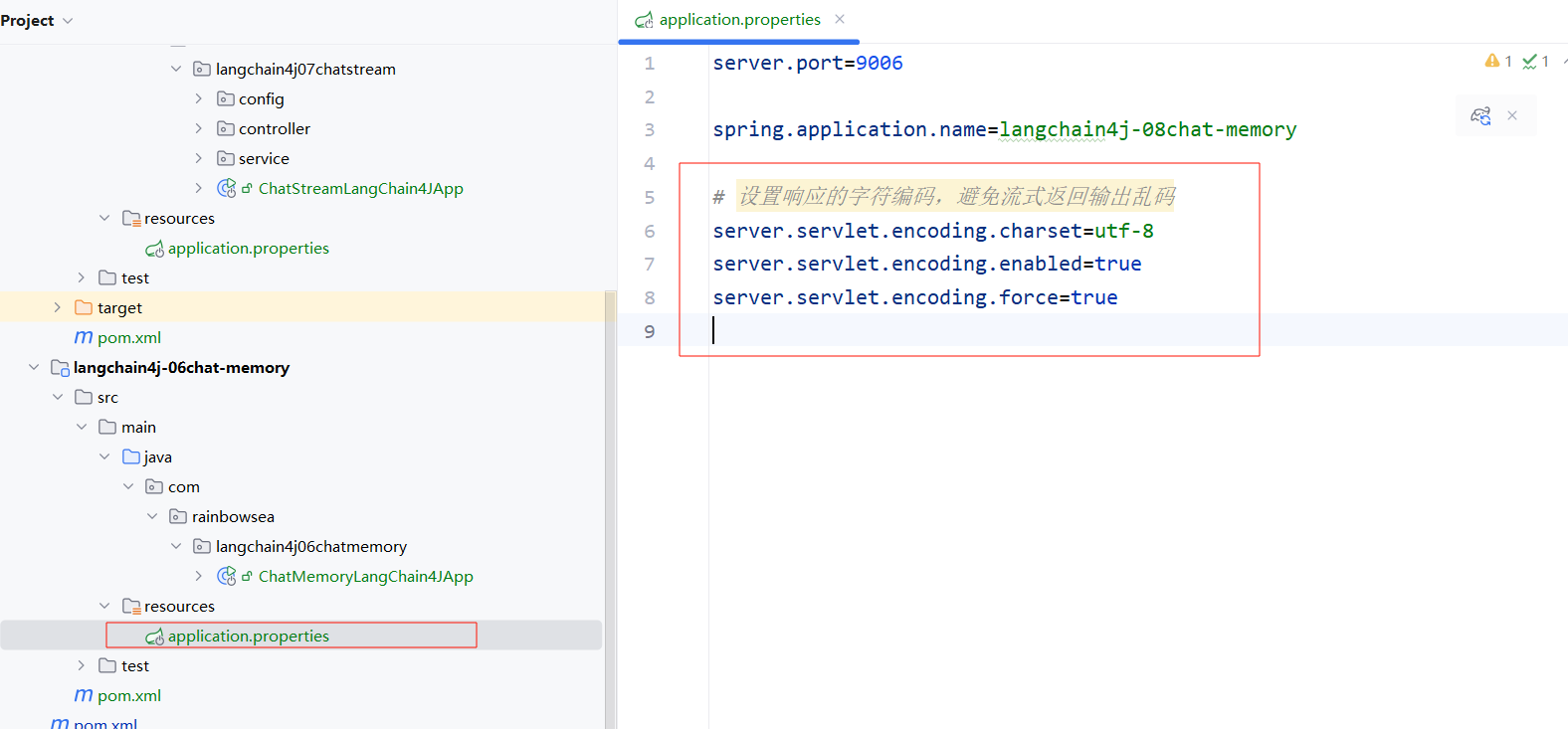
- 配置 applcation.yaml / properties 配置文件,其中指明我们的输出响应的编码格式,因为如果不指定的话,存在返回的中文,就是乱码了。
GPT plus 代充 只需 145
- 编写操作大模型的 ChanAssistant 接口类。
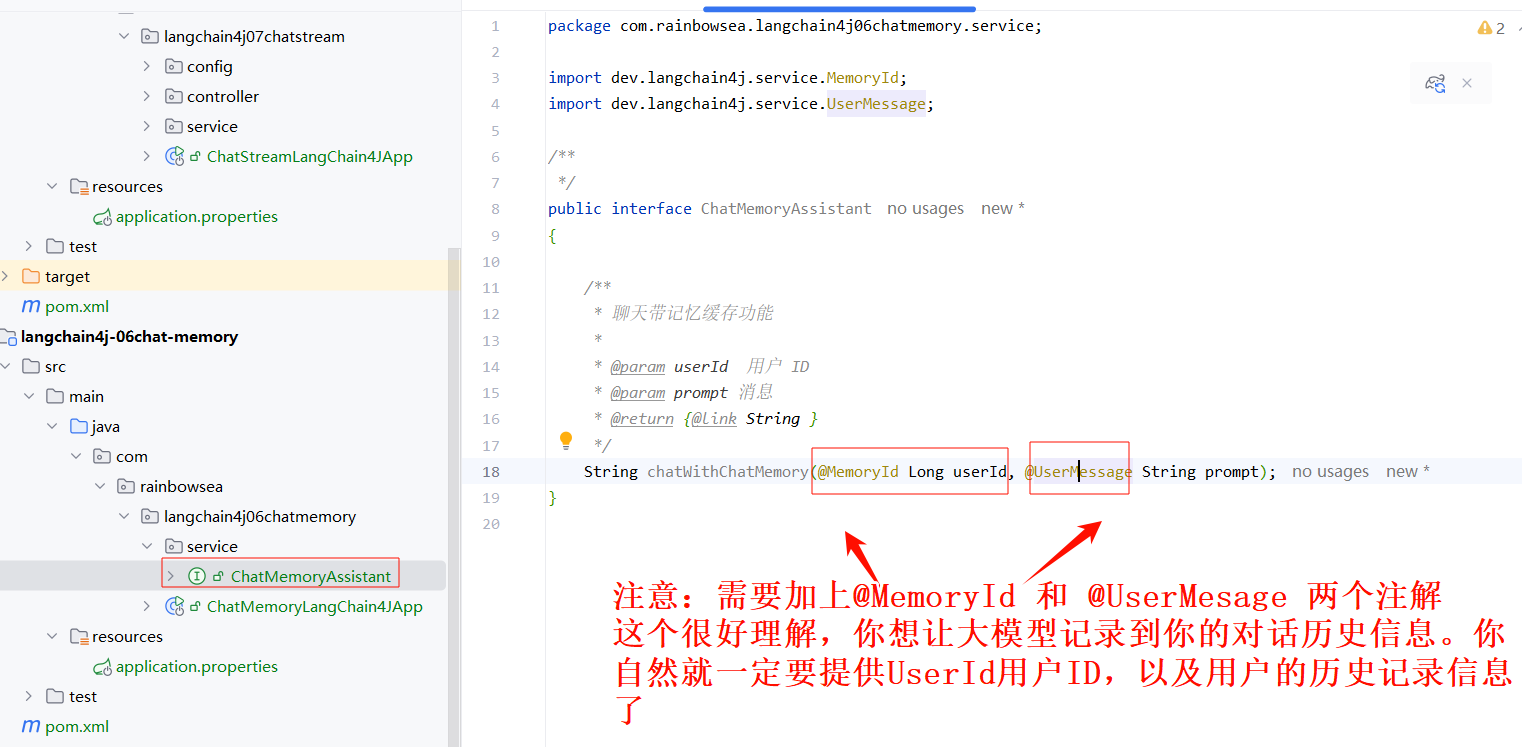
注意:需要加上@MemoryId 和 @UserMesage 两个注解 这个很好理解,你想让大模型记录到你的对话历史信息。你自然就一定要提供UserId用户ID,以及用户的历史记录信息了
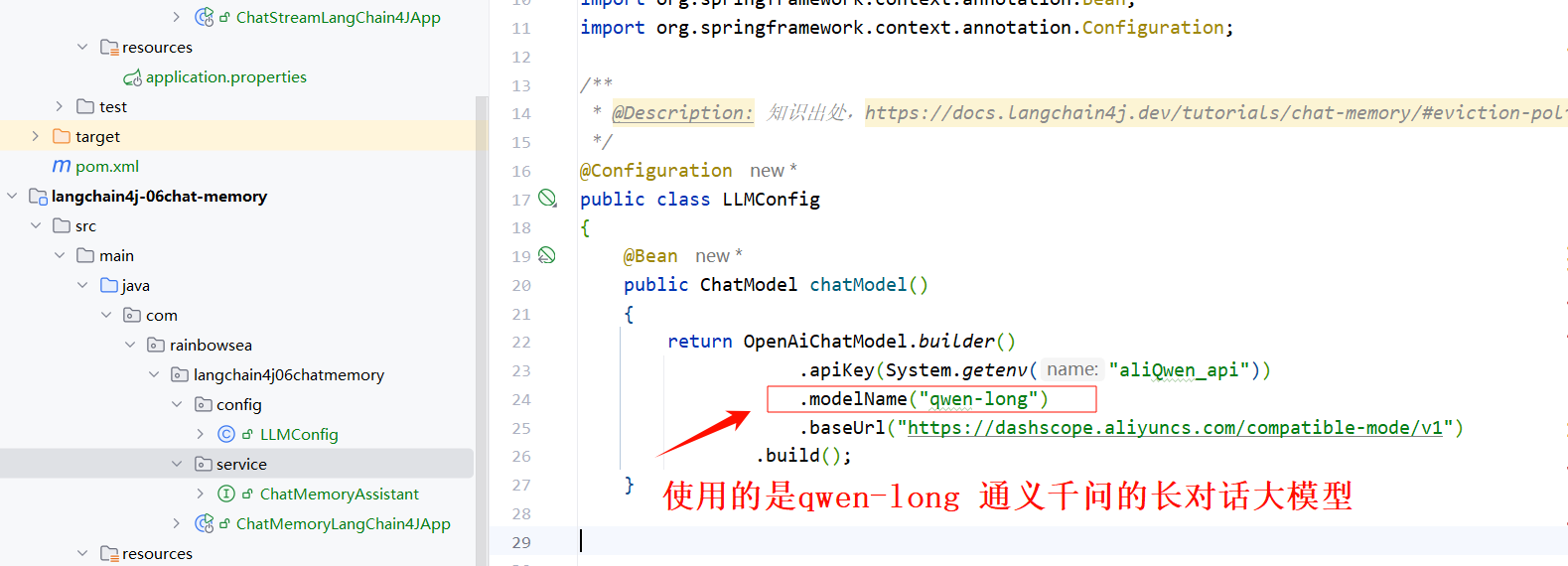
- 编写大模型三件套(大模型 key,大模型 name,大模型 url) 三件套的大模型配置类。
注意:这里我们要记忆缓存的话,就需要用到我们的通义千问的长对话大模型了。
GPT plus 代充 只需 145
为了保证知识内容上的完整性,这里我也附上通过 token 数记录历史对话的代码
- 编写聊天记忆缓存调用的 cutroller

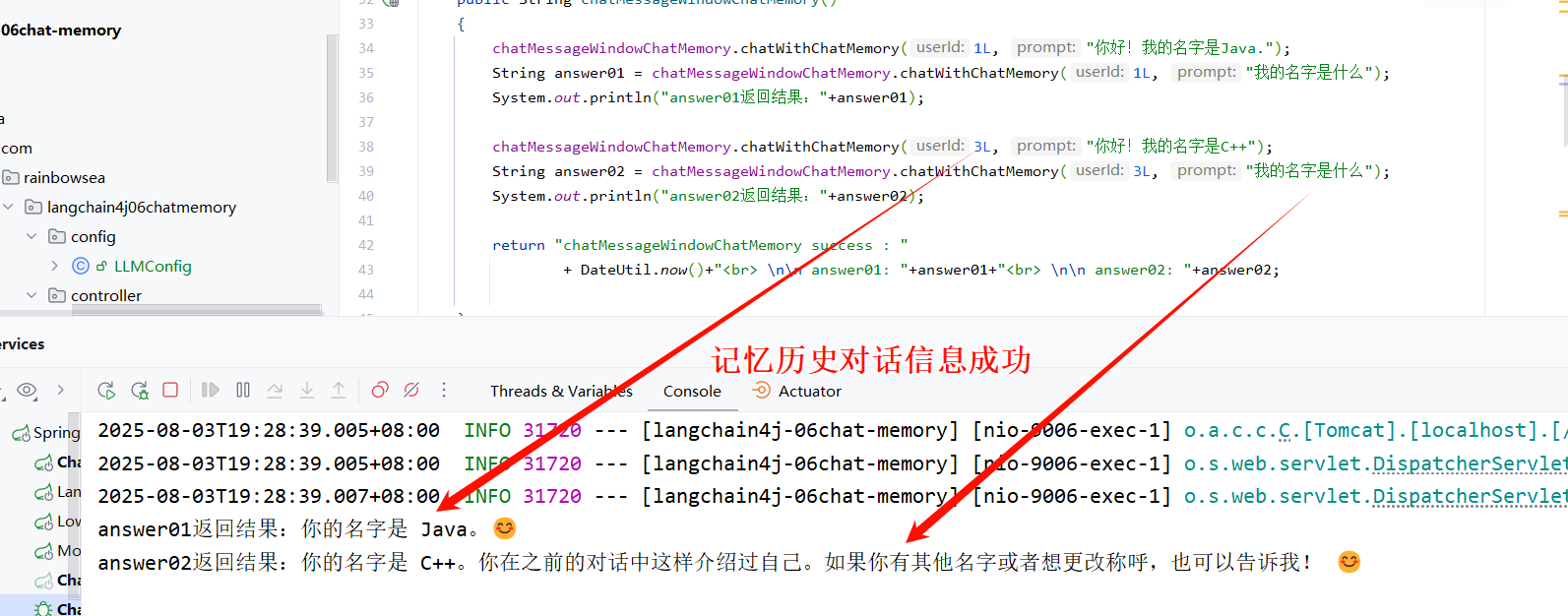
运行测试:
为了保证知识内容上的完整性,这里我也附上通过 token 数记录历史对话的代码
GPT plus 代充 只需 145
“在这个最后的篇章中,我要表达我对每一位读者的感激之情。你们的关注和回复是我创作的动力源泉,我从你们身上吸取了无尽的灵感与勇气。我会将你们的鼓励留在心底,继续在其他的领域奋斗。感谢你们,我们总会在某个时刻再次相遇。”

版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/216401.html