
现在千问新出了一个QwQ-32B,在自己电脑上部署了一下,确实挺强的。
本来是计划直接pip安装vllm的,但是装好之后出现了一个报错,好像是找不到某个so库。vllm0.7.3指定要torch2.5.1,我电脑装这个torch版本就会报错,其他的torch版本可以正常运行。最后还是只能用docker。记录一下安装过程。
(1)拉镜像
docker pull vllm/vllm-openai:v0.7.3(2)下载模型
GPT plus 代充 只需 145from modelscope.hub.snapshot_download import snapshot_download
model_dir = snapshot_download(‘Qwen/QwQ-32B-AWQ’, cache_dir=‘path/to/local/dir’)
(3)启动镜像
下面有几个参数需要注意一下:–api-key 是增加鉴权用的, –enable-auto-tool-choice和–tool-call-parser hermes是为了使用QwQ的工具调用能力。
docker run -d
–runtime nvidia
–gpus all
-p 7860:8000
–ipc=host
-v /home/user/model/QwQ-32B/Qwen/QwQ-32B-AWQ:/model
vllm/vllm-openai:v0.7.3
–model /model
–max-model-len 4096
–api-key user-abc123
–enable-auto-tool-choice
–tool-call-parser hermes
根据知乎大佬 @李玛碧 反馈,T4 * 8卡的环境下,直接拉取我的镜像无法使用,需要修改启动的bash脚本,增加环境变量 VLLM_USE_MODELSCOPE 。
脚本内容如下:
GPT plus 代充 只需 145#!/bin/bash export VLLM_USE_MODELSCOPE=False
启动服务的命令
nohup python -m fastchat.serve.controller –host=0.0.0.0 & nohup python -m fastchat.serve.vllm_worker –model-path /workspace/model/Qwen/qwen/Qwen-14B-Chat-Int4/ –tensor-parallel-size 1 –trust-remote-code –host 0.0.0.0 &
将最后一个服务命令保持在前台运行,不然容器会直接退出
python -m fastchat.serve.openai_api_server –host 0.0.0.0 –port 8001
本人在单卡3090环境下直接拉取原镜像可以直接使用,不过我还是更新一下镜像。
新镜像: docker pull l99500/vllm_gptq:v1
镜像启动和测试参考下文。
(1)现在模型越来越大,占用的显存越来越多,体验大一点的模型只能使用量化版;
(2)目前flash-attention不支持v100, 只能使用vllm;
(3)不使用vllm加速,模型生成速度很慢。
docker + vllm-gptq + fschat
ubuntu 22.04 显卡 3090 (v100加centos也试过)
参考教程:魔搭社区牵手FastChat&vLLM,打造极致LLM模型部署体验, vllm-gptq
如果你还没有安装docker以及 gpu docker,可以参考苏洋大佬的这两篇博客:《更简单的 Docker 安装》和《GPU Docker 环境的安装和配置》。
- 第一步:拉基础镜像
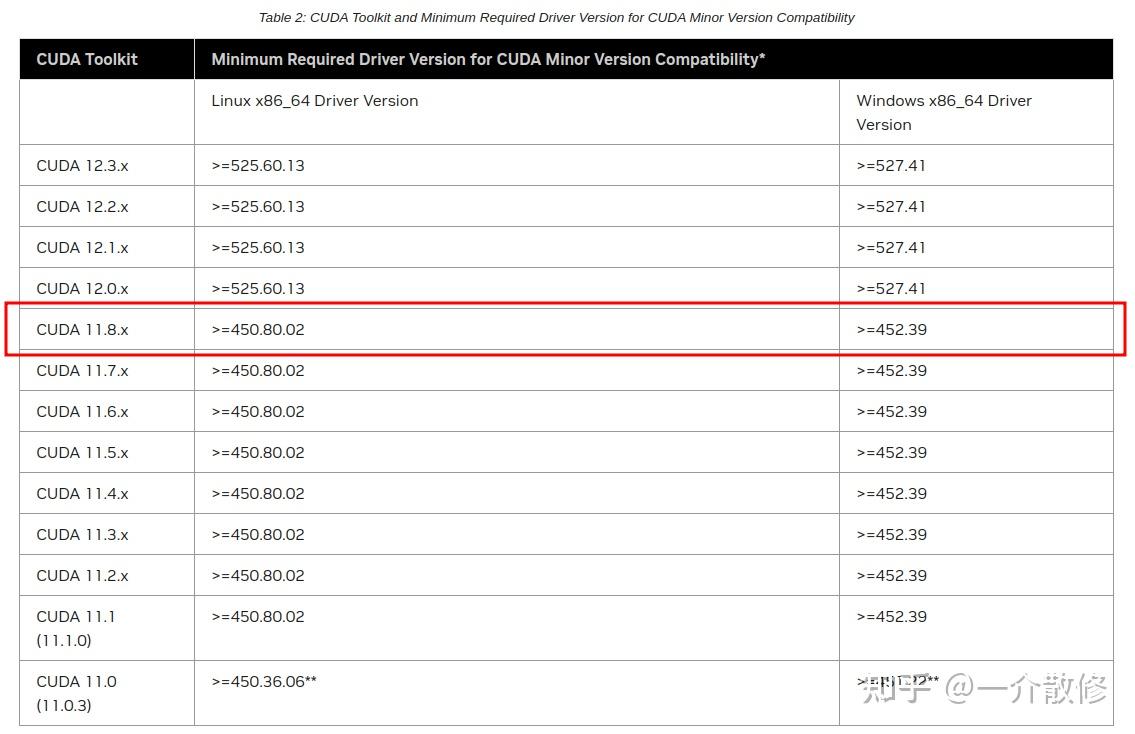
docker pull registry.cn-hangzhou.aliyuncs.com/modelscope-repo/modelscope:ubuntu22.04-cuda11.8.0-py310-torch2.1.0-tf2.14.0-1.10.0这里再插一句题外话,虽然说docker镜像免去了我们安装环境的很多事情,但是我们的显卡驱动必须支持cuda11.8.0。显卡驱动与cuda对应版本可以参考下图。英伟达官网查看网址。
- 第二步:启动镜像为容器 暂时先交互式运行容器,因为还要重新编译vllm。
docker run -it -p 7860:8001 \ (端口映射) -v /home/zp/model:/workspace/model \ (挂载宿主机的文件夹到容器中,这里是模型参数的保存路径) –gpus all \ (允许容器访问宿主机的所有显卡) –name qwen_vllm \ (给容器起一个名字) ms_vllm \ (上面拉的镜像REPOSITORY,你的名字应该和我不同,我重命名了。) /bin/bash (启动一个交互式会话)(我括号里面的是注释,不要粘贴去执行。)- 第三步:从github上下载vllm-gptq,然后复制到容器中。 原因:vllm不支持量化模型,所有需要使用qwen官方提供的vllm-gptq重新编译,你要是不需要跑量化模型,直接使用这个镜像就行。另外,这个只支持int4。 下载:
git clone https://github.com/QwenLM/vllm-gptq.git(我没用这个指令,直接在网页上下载的zip。) 复制:docker cp vllm-gptq-main.zip qwen_vllm:/(我这里再罗嗦一句,上面不是开了一个容器的交互窗口嘛,这条指令不要在那里执行,在下载的zip文件那里新开一个命令行窗口执行指令。) - 第四步:编译vllm-gptq,安装fastchat。 因为容器的cuda版本是11.8,编译之前有一些必须的操作:(1)进入文件夹vllm-gptq,删除
requirements.txt中的torch依赖,并删除pyproject.toml。 编译:(2)pip install -e .时间可能有点久,耐心等待一下。 安装fastchat:(3)pip install fschat -i https://mirrors.aliyun.com/pypi/simple/(使用阿里源可以加速安装) 如果一次没有安装完,退出容器后,再进容器的指令为:(1)启动容器:docker start qwen_vllm ;(2)开启bash会话:docker exec -it qwen_vllm /bin/bash。 - 第五步:测试 环境变量设置:这里是一个比较坑的点,卡了我快一个小时。容器中环境变量
VLLM_USE_MODELSCOPE默认为True, 导致的结果是代码不会读我本地下载好的模型,而是会去下载模型。这在离线环境是行不通的。(1)查看环境变量:echo \(VLLM_USE_MODELSCOPE</code> (2)在bashrc中设置环境变量:<code>vim ~/.bashrc</code>,在最後面加入<code>export VLLM_USE_MODELSCOPE=False</code>,然后保存退出,重新加载bashrc <code>source ~/.bashrc</code>;(3)最后再测试一下<code>echo \)VLLM_USE_MODELSCOPE结果应该就是False了。 修改测试脚本并进行测试:(1)进入测试脚本文件夹cd /vllm-gptq/tests/qwen;(2)修改脚本,我的脚本如下;(3)python test_qwen.py,然后你就能看到模型的输出了。环境配置到这里基本上完成了。
GPT plus 代充 只需 145from vllm_wrapper import vLLMWrapper
if name == ‘main’:
# 这里是模型的保存路径,之前启动容器的时候挂载进来了 model = "/workspace/model/Qwen/qwen/Qwen-14B-Chat-Int4/" #gptq a16w4 model # tensor_parallel_size 你有几张卡就是多少,要能整除64,例如不能是3 vllm_model = vLLMWrapper(model, quantization = 'gptq', dtype="float16", tensor_parallel_size=1) #a16w16 model # vllm_model = vLLMWrapper(model, # dtype="bfloat16", # tensor_parallel_size=2) response, history = vllm_model.chat(query="你好", history=None) print(response) response, history = vllm_model.chat(query="给我讲一个年轻人奋斗创业最终取得成功的故事。", history=history) print(response) response, history = vllm_model.chat(query="给这个故事起一个标题", history=history) print(response)</code></pre></div><ul><li data-pid="-UzF8ADw">第六步:部署模型,方便后续以api的方式调用 (1)启动控制器:<code>python -m fastchat.serve.controller --host=0.0.0.0</code> 后面这个host必须加上,不然会报错:<code>ERROR: [Errno 99] error while attempting to bind on address ('::1', 21001, 0, 0): cannot assign requested address</code>。建议后台运行,不然要多开很多个命令行窗口,使用这个指令<code>nohup python -m fastchat.serve.controller --host=0.0.0.0 &</code>。 (2)启动模型worker:<code>nohup python -m fastchat.serve.vllm_worker --model-path /workspace/model/Qwen/qwen/Qwen-14B-Chat-Int4/ --tensor-parallel-size 1 --trust-remote-code --host 0.0.0.0 &</code> (3)启动服务器: <code>nohup python -m fastchat.serve.openai_api_server --host 0.0.0.0 --port 8001 &</code> </li><li data-pid="zbPxmYRS">第七步:接口测试(在宿主机进行测试)</li></ul><div class="highlight"><pre><code class="language-text">curl -X POST \ GPT plus 代充 只需 145"model":"Qwen-14B-Chat-Int4", "stream":false, "messages":[{ "role": "user", "content": "你好" }]
启动服务的命令
nohup python -m fastchat.serve.controller –host=0.0.0.0 & nohup python -m fastchat.serve.vllm_worker –model-path /workspace/model/Qwen/qwen/Qwen-14B-Chat-Int4/ –tensor-parallel-size 1 –trust-remote-code –host 0.0.0.0 &
将最后一个服务命令保持在前台运行,不然容器会直接退出
python -m fastchat.serve.openai_api_server –host 0.0.0.0 –port 8001
记得要给这个脚本一个权限,chmod +x /path/in/container/start_services.sh 记得替换成自己的实际路径。
- 第二步:将当前容器保存为一个镜像。
docker commit qwen_vllm vllm_gptq:v3镜像名和版本根据实际情况确定。 - 第三步:将刚才保存的镜像启动为容器,指令如下:
docker run -it -d -p 7860:8001
-v /home/zp/model:/workspace/model
–gpus all
–name qwen_vllm
vllm_gptq:v3
/bin/bash -c “/path/in/container/start_services.sh”
单行长这样:docker run -it -d -p 7860:8001 -v /home/zp/model:/workspace/model –gpus all –name qwen_vllm vllm_gptq:v3 /bin/bash -c “/start_services.sh”
最后再按照上面的方法测试一下,完美收工!
- 第一步:为镜像打标签。这个标签应该包括您的 Docker Hub 用户名、仓库名和版本标签。假设您的 Docker Hub 用户名是 yourusername,您的镜像名是 myimage,版本标签是 latest,您可以使用以下命令来打标签:
docker tag myimage:currenttag yourusername/myimage:latest所以我的命令是docker tag vllm_gptq:v3 l99500/vllm_gptq:v0 - 第二步:登录到dockerhub。在上传镜像之前,您需要登录到您的 Docker Hub 账户:
docker login 输入您的 Docker Hub 用户名和密码。 - 第三步:上传镜像。
docker push l99500/vllm_gptq:v0 - 第四步:验证上传。上传完成后,您可以在 Docker Hub 上检查您的账户,以确保镜像已成功上传。
感兴趣的话可以直接拉我的镜像用,docker pull l99500/vllm_gptq:v0。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/216304.html