
在学习或工程中,我经常会对使用到的开源框架或者有趣的依赖产生兴趣,仅仅阅读其中的一些代码片段显然不能满足我的好奇心,但是直接阅读整个工程又会遇到以下困难:
- 工程庞大复杂,可能会有复杂的设计模式,难以梳理出工程的主要故事线,或者主要故事线的调用链过长或者分支过多。
- 工程技术栈不了解。许多开源工程中会使用多种开发语言和技术栈,不同开源工程中的技术栈也相差巨大,一个人自然不能了解所有的开发语言和技术栈。
在以往,这两个困难可能是难以克服的,但是现在有了cursor,continue,windsurf这些辅助编码平台,我们如何利用这些平台辅助我们快速理解复杂的新工程呢?
最新发现一个可以落地的 Cursor 工作流技巧,这是BMad Code开源的一个库。
首先,它可以让cursor创建约束自己的rule规范,来进行增强Cursor的能力。
其次,可以根据工作流模式,可以直接让Cursor把你的idea落地。 然后根据它已经预设好的project-idea-prompt执行。
现在的你只需要提供你的想法,Cursor就可以帮你生成对应的产品需求文档(prd)。
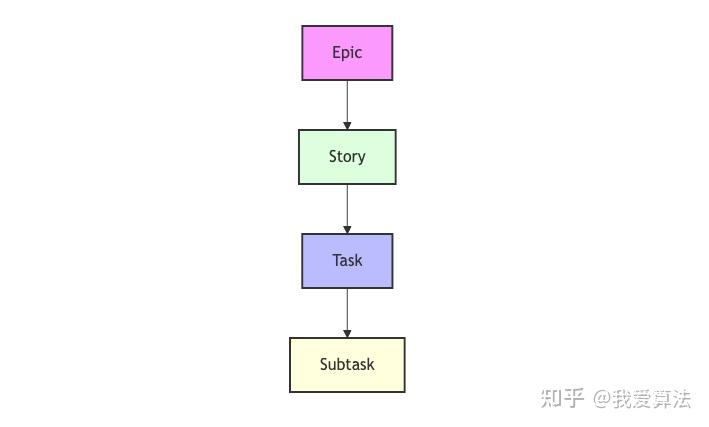
根据prd需求并执行工作流:Epic -> Story -> Task -> Subtask。 拆解任务模块,然后一步步完成。
如果你想把产品做得更加细腻,可以提供更加细致的需求,让Cursor进行生成更加详细的PRD
克隆 cursor-auto-rules-agile-workflow 这个库,它里面已经创建好了规则,如何生成到你指定的项目。
git clone https://github.com/bmadcode/cursor-auto-rules-agile-workflow.gitcd cursor-auto-rules-agile-workflow
克隆之后,就会有对应的cursor的rules,你查看000-cursor-rules.mdc文件时,会发现一些红色警告的匹配规则,这个时候,需要你把当前工作区的警用掉mdc。
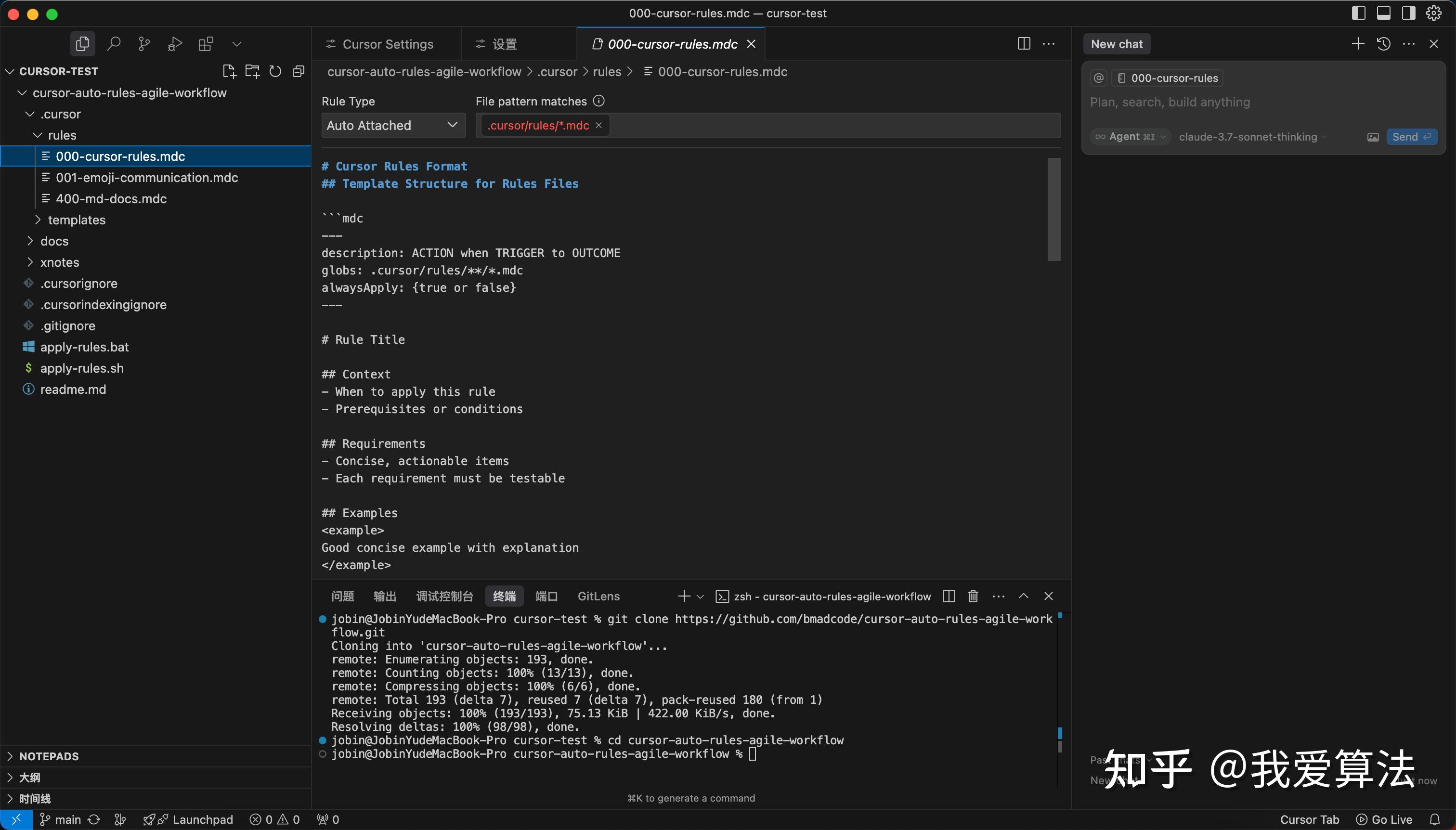
需要添加以下配置,这一步重要!!
GPT plus 代充 只需 145“workbench.editorAssociations”: {
"*.mdc": "default" }
路径:首先项 -> 设置 -> 工作区,如何搜索editorAssociations, 就可以添加对应的配置。
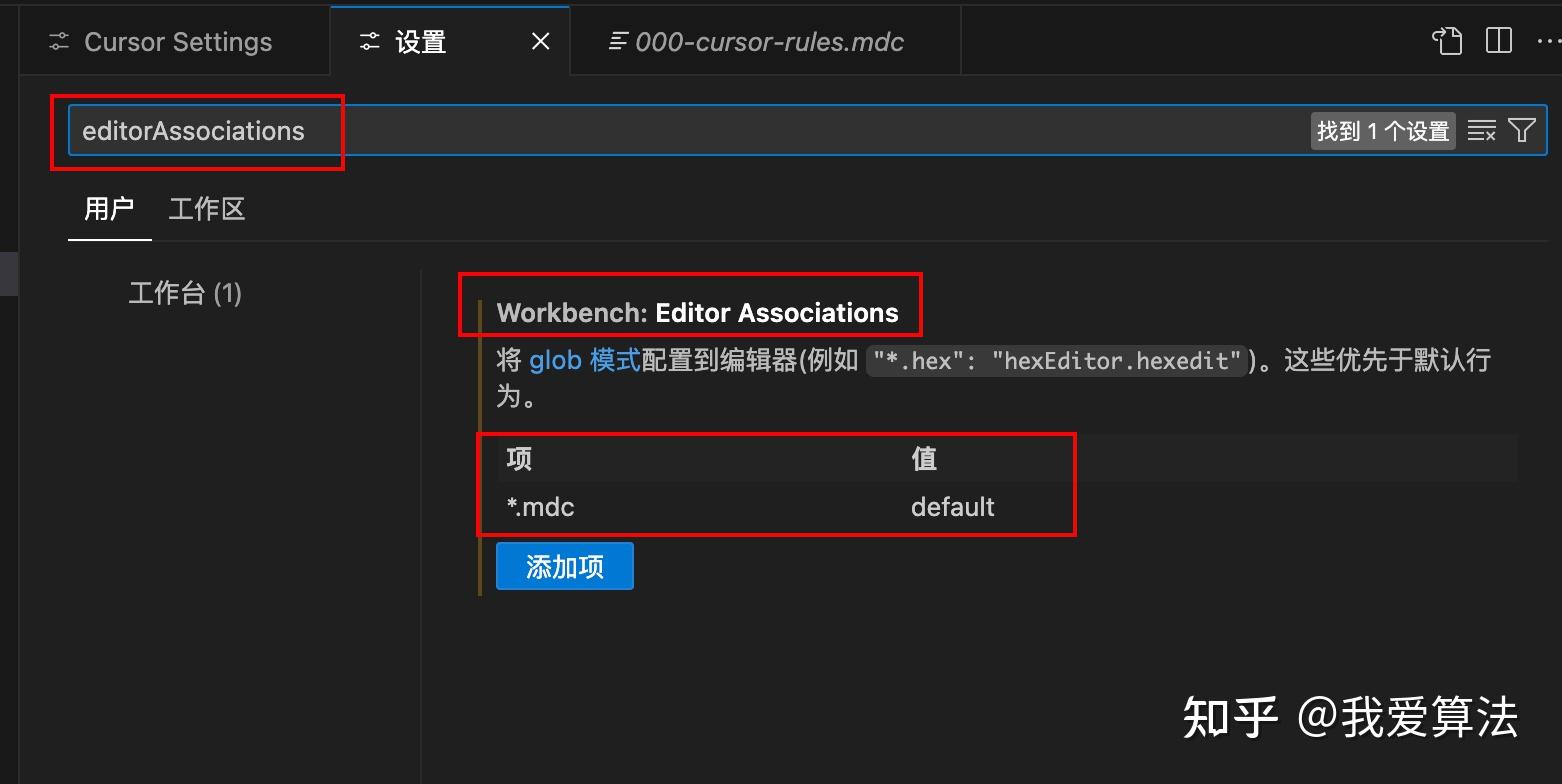
重新打开000-cursor-rules.mdc文件,就没有对应的警告了。
你可以直接在当前项目执行./apply-rules.sh进行生成rule,也可以指定自己的项目生成。 只需要后面跟上你的项目路径:
GPT plus 代充 只需 145Example: ./apply-rules.sh ~/projects/my-project
如果需要在历史项目上生成rules,就可以按照这种方式,就不需要再次克隆项目。
比如,我再另个文件夹rule-template进行创建规则,执行下面语句后就可以生成对应的.cursor、.gitignore、.cursorignore、.cursorindexingignore等文件。
./apply-rules.sh ../rule-template 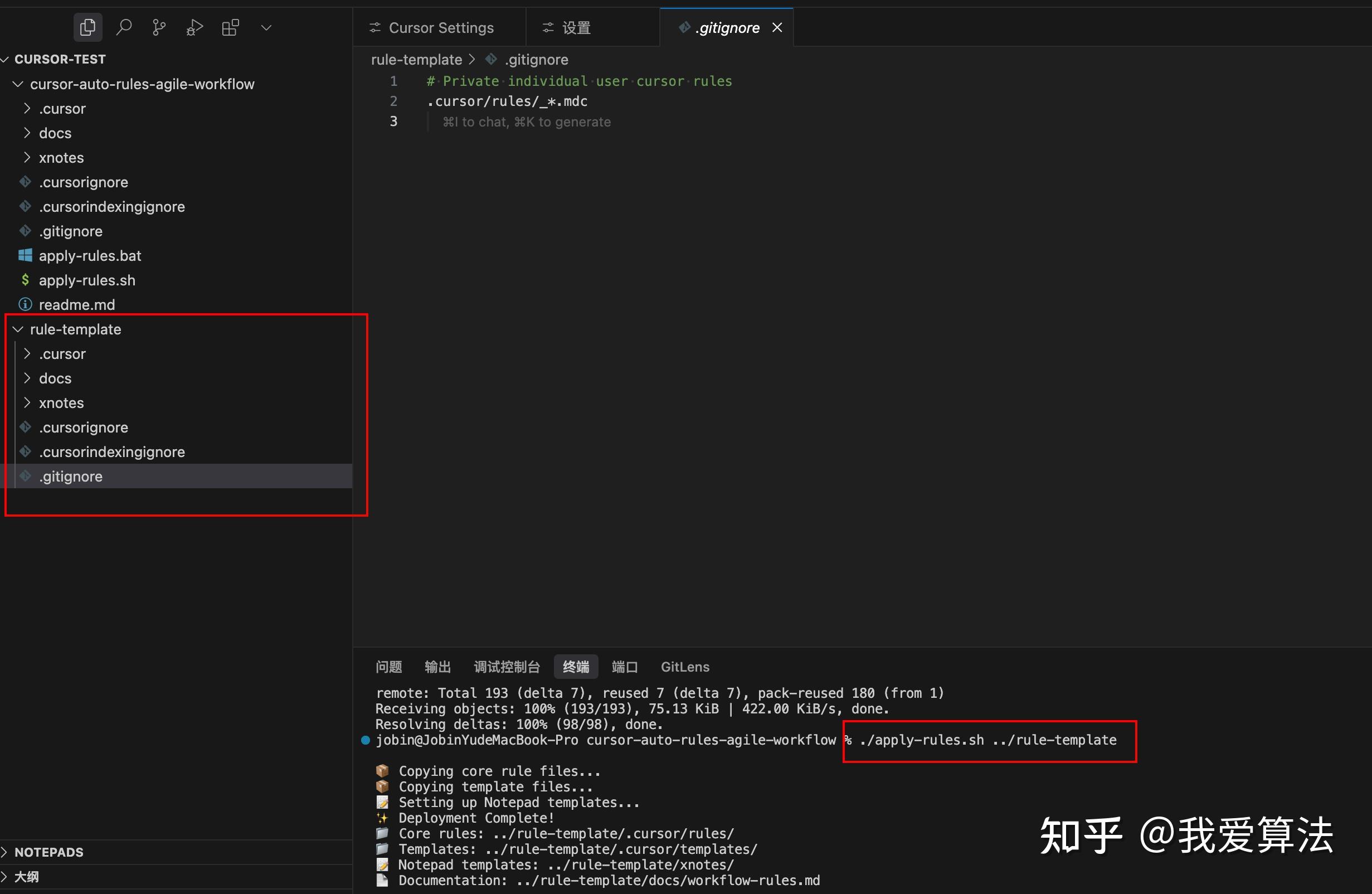
切换到rule-template文件夹,进行测试落地效果。
在已有的项目,或者新项目,如果需要定制一个开发规范,你只需要告诉Cursor,你大概要的规范,他就可以给你指定对应的mdc文件规范。
比如,我需要这么一条rule规则,在cursor开启agent并且选择 claude3.7 Sonnet Think 模型 进行对话即可。
GPT plus 代充 只需 145prompt: 创建一条规则,项目里的组件目录下命名是首字母大写驼峰,接口目录下的命名是首字母小写驼峰,其他目录是下划线。
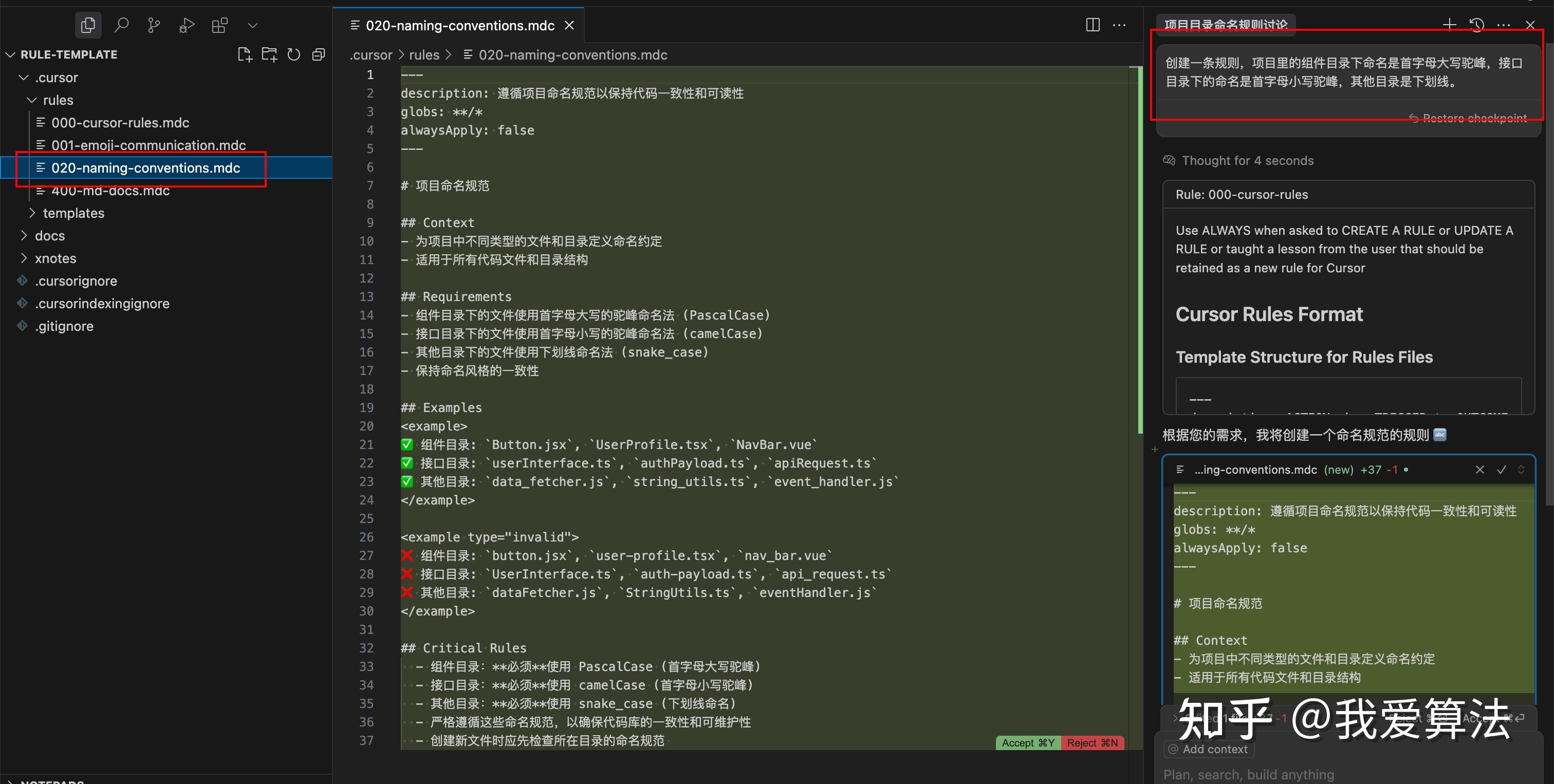
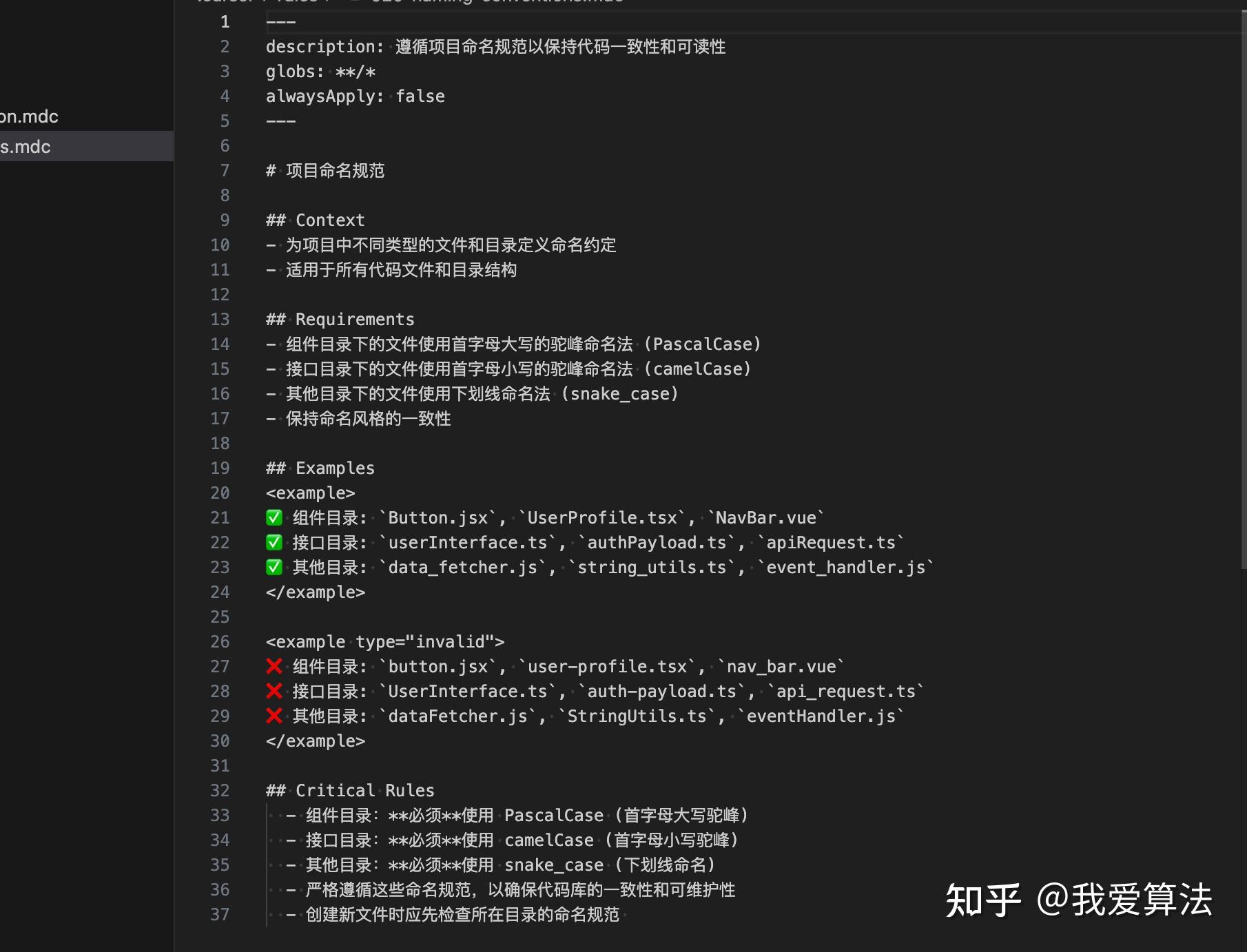
实践过程中,是在 Claud Sonnet 3.5、3.7 和 3.7 thinking 上进行测试,与其他模型可靠性可能有所不同。
Claude Sonnet 3.5、3.7 这些模型,需要升级Cursor Pro。
如果不知道怎么升级,注册一张Master虚拟卡解决升级问题:wildscard.com
具体的教程:(保姆教程)Cursor Pro 升级教程,仅需支付宝订阅Cursor Pro
这是一种自动化工作流模型,你要实现的项目可以让cursor进行拆解成多个任务,根据你的调整对应的prd产品需求文档,或者story-1、story-2等等。
批准之后,就可以一步一步的实施落地。
首先在cursor编辑器的 NOTEPADS 创建一个 Notepad
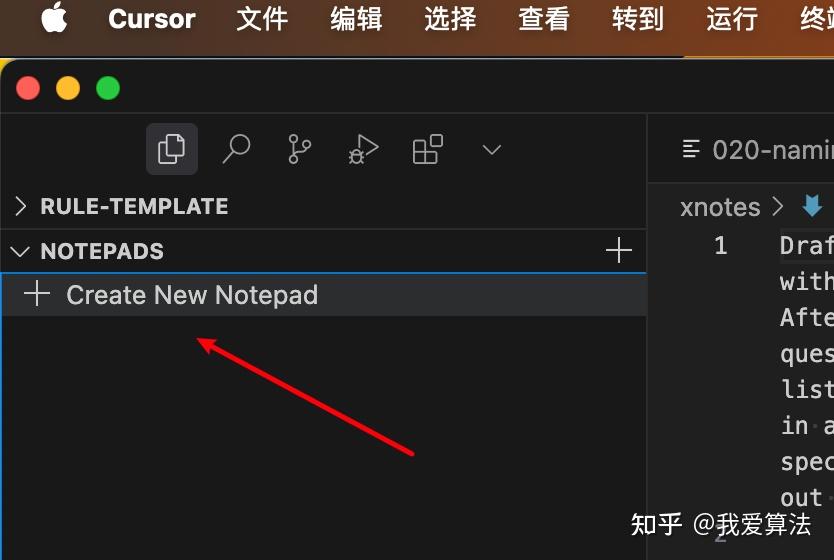
我创建了ikun notepad 模版,然后把 xnotes/workflow-aglie.md 里的内容,复制粘贴到 ikun里面。
在跟Cursor对话是,@你的notepad,它就可以根据里面的要求执行。 如:@ikun 我有个想法,搭建一个xxx网站 等等。

接着,它就自动创建.ai目录,并且生成prd文件,也就是产品需求文档,在 prd 文件里有对应的需求状态、需求分析、技术栈以及解决方案等等。
如果你想把产品做得更加细腻,可以给出更详细的需求,让 Cursor 帮你输出 prd 文件。
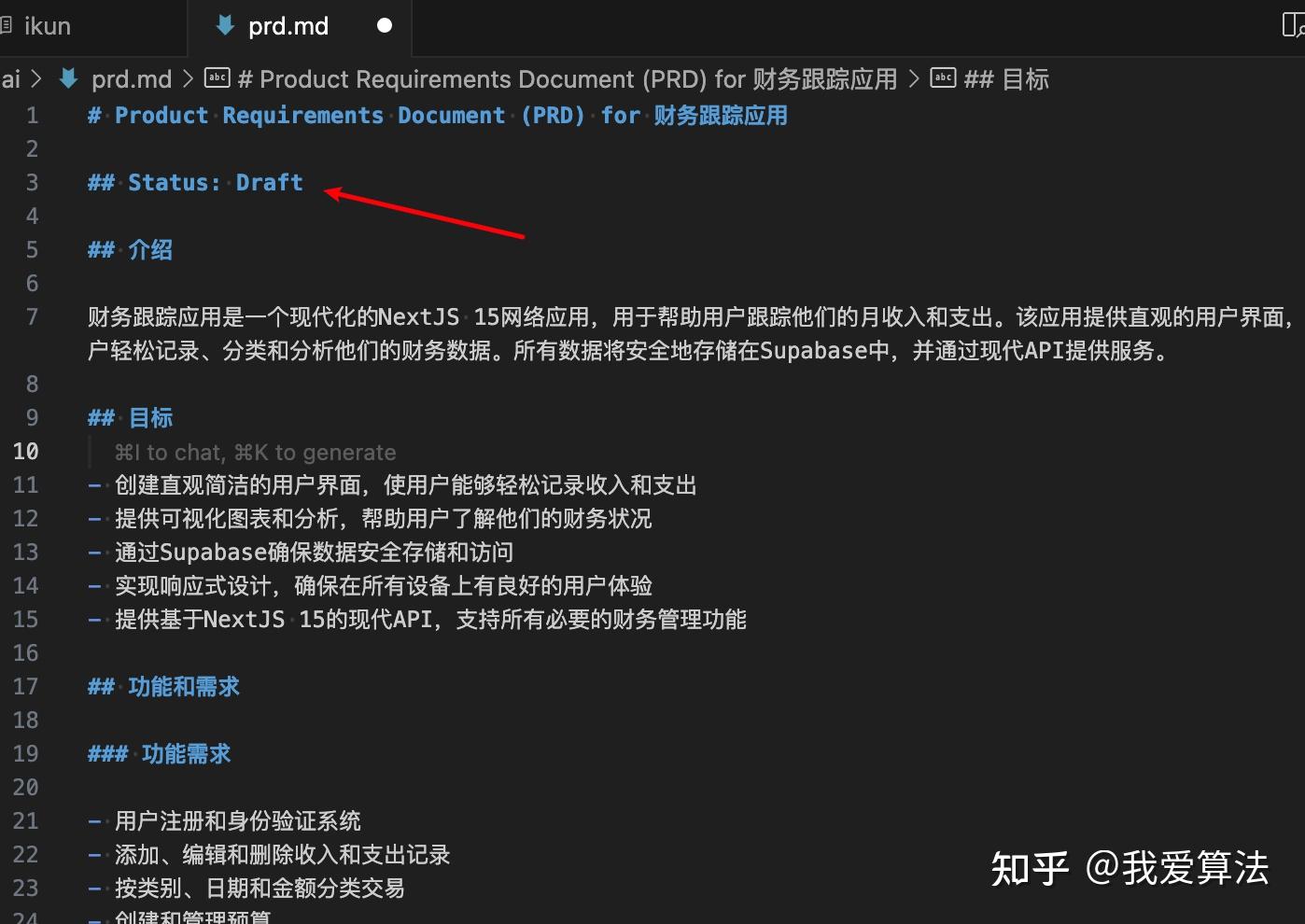
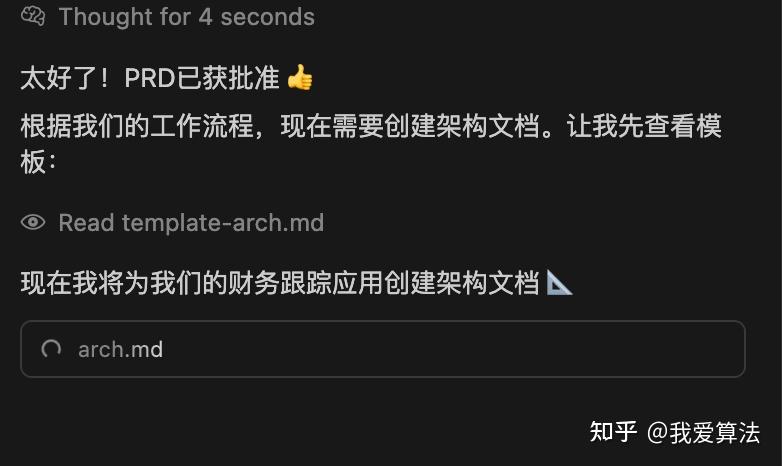
然后一步一步,生成对应的流程,prd -> arch -> story。
也就是让 Cursor 进行分析 prd 文档,根据需求生成一个技术架构,根据prd文档的Epic结构拆解成多个任务,每个Epic生成对应的story-1、story-2等等。
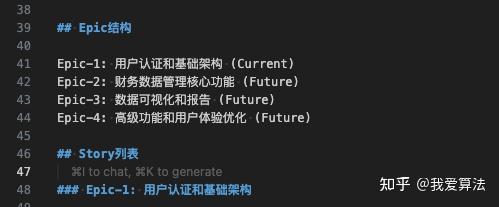
当story-1的任务完成之后,就会自动修改状态,开始下一个任务,story-2。
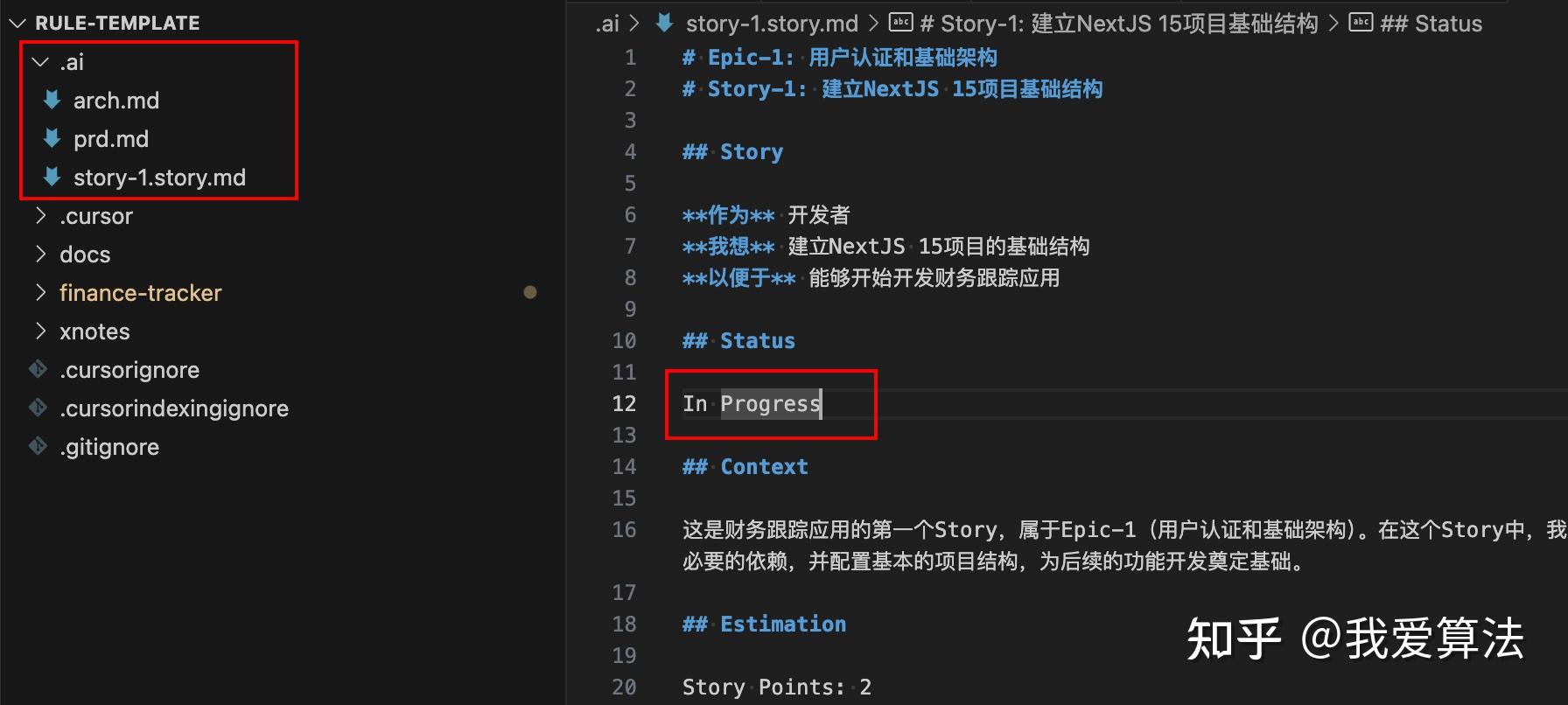
其中,你跟Cursor的对话流程,也都会写在每一个story里。

整个过程,你只需要关注下面的几个工作流程的阶段就行,改改需求文档,修修bug。
而且更好的管理一个全新的项目,并且成本也会降低,无需频繁的去对话,就可以生成你要的idea项目。
整个工作流程,关注两个阶段:计划阶段 和 ACT 阶段。
1. 计划阶段:
- 关注文档和规划
- 仅修改 .ai 目录下的文档、项目下的readme 和 rule规则
- 所需 PRD 和架构的审批
2. ACT 阶段:
- 实施进行中的已批准story
- 任务逐个执行
- 持续测试和验证

.ai/ ├── prd.md # Product Requirements Document ├── arch.md # Architecture Decision Record ├── epic-1/ # Current Epic directory │ ├── story-1.story.md # Story files for Epic 1 │ ├── story-2.story.md │ └── story-3.story.md ├── epic-2/ # Future Epic directory │ └── … └── epic-3/ # Future Epic directoryGPT plus 代充 只需 145└── ...
“
去年我试着读vLLM的源码。
起因是我在用vLLM做推理服务的时候遇到了一个性能问题,想看看它的调度器到底是怎么工作的。我clone了仓库,打开文件树,看到了大概几百个Python文件、一堆C++扩展、还有CUDA kernel。
我盯着屏幕看了十分钟,关掉了编辑器,去泡了杯咖啡。
那种感觉你一定体会过——就像你站在一座陌生城市的市中心,四周全是高楼,每栋楼里都有几十层,你知道你要找的东西就在某一栋楼的某一层的某个房间里,但你连东南西北都分不清。
后来我开始用Cursor来辅助读源码。摸索了一段时间之后,确实找到了一些有效的方法。
不是那种”让AI帮你读完所有代码然后给你一份总结”的方法——那种方法我试过,没用,AI给你的总结跟你自己看README得到的信息差不多。
我要说的方法更像是把Cursor当成一个对这个代码库了如指掌的向导,你问它路,它带你走,但路是你自己走的,风景是你自己看的。
这是很多人的第一反应。打开Cursor,把整个项目索引了,然后问:”帮我介绍一下这个项目的整体架构。”
AI会给你一段话。听起来头头是道。什么”这个项目采用了分层架构,核心模块包括XXX、YYY、ZZZ,它们之间通过XXX方式通信”。
你读完觉得”嗯嗯好有道理”。
然后呢?
然后你发现自己并没有真正理解任何东西。你知道了几个模块的名字,但你不知道数据是怎么从入口流到出口的。你不知道某个关键的设计决策背后的原因。你不知道当一个请求进来的时候,代码到底在做什么。
因为理解不是信息的传递,是认知结构的构建。 AI把架构信息告诉你,相当于给了你一张地图。但地图不是领土。你没有亲自走过那些路,地图上的每一个标记对你来说都只是一个符号,而不是一段体验。
这就是为什么”让AI帮你读代码”作为一个整体策略是行不通的。
但”在你自己读代码的过程中,让AI帮你解决具体的障碍”——这个策略是非常有效的。
两者的区别是什么?是主动权在谁手里。前者你是被动的信息接收者,后者你是主动的探索者。AI的角色从”替你读”变成了”帮你读”。
读任何一个复杂项目,我现在都不会从”了解整体架构”开始。
我会从一个具体的问题开始。
读vLLM的时候,我的问题是:”一个推理请求从进入系统到返回结果,经历了哪些步骤?”
读FastAPI的时候,我的问题是:”当我写了一个@app.get(‘/users’),框架是怎么把这个装饰器变成一个能处理HTTP请求的东西的?”
读Redis的时候,我的问题是:”当我执行SET key value的时候,这个命令从被接收到数据被写入内存,中间经过了什么?”
一个好的问题就是你的故事线。 你不需要理解整个项目——你需要沿着一个问题,把它涉及到的代码路径从头到尾走一遍。
走完一条路径之后,你对项目的理解就不再是零了。你有了一个”锚点”。然后你可以从这个锚点出发,问第二个问题,走第二条路径。两条路径之间一定会有交叉点——那些交叉点就是项目的核心模块。
几条路径走完,项目的骨架自然就在你脑子里了。
这个方法不需要AI也能做。但有Cursor的帮助,效率会高非常多。
每一条故事线都需要一个入口。对于大部分项目来说,入口就是用户最先接触到的那个界面。
如果是一个Web框架,入口就是你创建app、注册路由的地方。
如果是一个推理引擎,入口就是你调用model.generate()的地方。
如果是一个数据库,入口就是它接收客户端连接和命令的地方。
怎么用Cursor找入口? 直接问它:
这个项目的用户入口在哪?当一个用户发起一个推理请求时, 代码的执行从哪个文件的哪个函数开始?请给我具体的文件路径 和函数名,不需要解释细节。注意最后那句”不需要解释细节”。这很重要。
你在这个阶段只需要一个起点,不需要AI给你长篇大论。如果你让AI一次性解释太多,你会淹没在信息里,反而找不到方向。
Cursor会告诉你类似这样的信息:”入口在vllm/entrypoints/llm.py的LLM.generate()方法”。
好。打开那个文件。开始读。
打开入口文件之后,你开始读代码。很快你会遇到第一个障碍——你看到了一个函数调用,但你不知道那个函数做了什么、在哪个文件里。
这是Cursor最有价值的使用场景之一。
选中那个函数调用,问Cursor:
GPT plus 代充 只需 145这个函数做了什么?用一两句话概括它的核心职责, 然后告诉我它在哪个文件里定义的。
注意:一两句话。 你不需要AI给你逐行解释那个函数的实现。你现在只需要知道”它大概做了什么”以及”它在哪”。
这就像你在陌生城市里走路,遇到一个路口,你不需要知道每条岔路通向哪里的完整地图。你只需要知道”这条路大概通往火车站”和”那条路大概通往商业区”,然后选择跟你目标相关的那条走下去。
你会沿着调用链一路走下去。入口函数调用了A,A调用了B,B调用了C……
你不需要走完所有的分支。你只需要走跟你的问题相关的那条主线。
中间遇到不影响主线理解的分支——比如日志记录、参数校验、缓存检查——直接跳过。怎么判断一个分支是不是主线?问Cursor:
在这个函数里,哪一行是实际执行核心逻辑的? 其他部分可以先忽略吗?Cursor会告诉你:”第47行的self._run_engine()是核心调用,上面的都是参数处理和校验,可以先跳过。”
然后你跳到第47行,继续往下走。
这是你提到的第二个痛点——项目里用了你不熟悉的语言或技术。
比如你在读一个Python项目,突然发现核心的计算部分是用C++写的CUDA扩展。你不懂CUDA。
传统的做法是:先去学CUDA,学个几天几周,然后回来接着读。
有了Cursor你可以换一种做法:不学CUDA本身,只理解那段CUDA代码在做什么。
选中那段C++/CUDA代码,问Cursor:
GPT plus 代充 只需 145我不熟悉CUDA编程。请用我能理解的方式解释这段代码 在做什么——不需要解释CUDA的语法细节,只告诉我 它的输入是什么、输出是什么、中间做了什么计算。 用Python的思维方式类比。
最后那句”用Python的思维方式类比”很关键。它告诉Cursor用你已有的知识框架来解释新东西。
Cursor可能会说:”这段CUDA kernel本质上在做的事情相当于Python里的:对一个大矩阵的每一行做softmax,然后跟另一个矩阵做矩阵乘法。只不过它把这个计算拆分到了GPU的几千个线程上并行执行。”
你不需要理解它是怎么拆分的、线程是怎么同步的——那些是CUDA的实现细节。你需要理解的是它在计算层面做了什么。 有了这个理解,你就能把这个CUDA函数当成一个”黑盒”,知道它的输入输出,然后继续沿着主线往下走。
同样的方法适用于你遇到的任何不熟悉的技术栈:
- 不懂Rust?让Cursor用你懂的语言类比解释
- 不懂某个框架的特定API?让Cursor解释它的作用而不是用法
- 不懂某个设计模式?让Cursor解释它在这个项目里解决了什么问题
关键原则是:你的目标不是学会那个技术栈,而是理解代码的逻辑流。两者需要的知识量差了一个数量级。
走完一条主线之后,你需要把你走过的路记下来。
我的做法是在一个单独的markdown文件里,边读边记。格式很简单:
一个推理请求的完整路径- 入口:LLM.generate()(vllm/entrypoints/llm.py)
- 接收用户的prompt,封装成SequenceGroup
- 调度:Scheduler.schedule()(vllm/core/scheduler.py)
- 决定哪些请求可以在这一步被处理
- 核心逻辑:根据当前GPU显存和KV Cache的空间来排队
- 执行:ModelRunner.execute_model()(vllm/worker/model_runner.py)
- 把一批请求打包,送进模型做一次forward
- 这里会调用CUDA kernel做实际计算
- 采样:Sampler.forward()(vllm/model_executor/layers/sampler.py)
- 根据模型输出的logits,采样出下一个token
- 结果返回:把生成的token拼回去,返回给用户
我的理解
vLLM的核心创新在第2步——调度器的PagedAttention机制 让KV Cache可以像操作系统的虚拟内存一样按需分配, 不需要预留连续的大块显存……
这份笔记不是给别人看的,是给你自己看的。 所以不需要写得很正式,用你自己能理解的语言就好。
你可能觉得”我直接记在脑子里不就行了”。不行。复杂项目的调用链太长了,你走到第五层的时候大概率已经忘了第二层的细节。写下来才能在脑子里维持一张完整的地图。
而且这份笔记还有一个用处——当你后续探索第二条故事线的时候,你可以把新的路径叠加到同一份地图上,看到不同路径之间的交叉点。那些交叉点往往就是项目最核心的模块。
走完主线之后,你已经有了一个粗粒度的理解。接下来你可以选择在某些你特别感兴趣的节点上深入。
比如我走完vLLM的主线之后,对调度器特别感兴趣——因为它是vLLM性能优势的核心。
这时候我会打开调度器的代码,让Cursor帮我做更细粒度的解读:
GPT plus 代充 只需 145请帮我梳理Scheduler.schedule()这个方法的内部逻辑。 按执行顺序列出它做了哪几件事,每件事用一句话概括。 对于涉及PagedAttention的部分请详细解释。
注意这次我要求”详细解释”了——因为这是我选择深入的节点,值得花时间理解细节。
在主线探索阶段,你的提问策略应该是”概括+定位”——告诉我大概做了什么、在哪里。
在深入阶段,你的提问策略变成”细节+原因”——具体是怎么实现的、为什么这么设计。
这个节奏很重要。如果你从一开始就事事追问细节,你会迷失在细节里走不动。如果你全程只停留在概括层面,你最终得到的理解是浅薄的。
先粗后细,先主线后分支。 像画画一样——先画骨架,再填细节。
坑一:一次问太多。
不要发这种消息:
帮我解释一下这个项目的整体架构、核心模块的职责、 主要的设计模式、数据流向、以及关键算法的实现原理。这种问法得到的回答一定是又长又泛的废话。不是Cursor不行,是你的问题太大了,任何人面对这种问题都只能给你一个泛泛的回答。
好的提问是窄的、具体的、有明确边界的。
“这个函数的第三个参数是干什么用的?”
“这个类为什么要继承那个基类而不是直接实现?”
“数据从这个函数出来之后,下一步去了哪里?”
每个问题只解决一个困惑。解决完了再问下一个。你的理解就是这样一个困惑一个困惑地拼起来的。
坑二:完全信任Cursor的回答。
Cursor有时候会瞎说。尤其是当你问的问题涉及到跨文件的复杂逻辑时,它可能会给你一个听起来很合理但实际上是错的解释。
怎么办?交叉验证。
Cursor告诉你”这个函数会调用XXX”——你自己跳过去看一眼,确认它确实调用了。
Cursor告诉你”这个变量在YYY文件里被初始化”——你自己搜一下那个变量名,确认它说的位置是对的。
不需要每一句话都验证,但关键节点一定要自己确认。 尤其是那些会影响你对整体架构理解的判断——比如”模块A和模块B是通过消息队列通信的”——这种结论你最好自己看到代码里的证据。
养成这个习惯之后,你会发现大部分时候Cursor是对的,但偶尔它确实会犯错。那些”偶尔”的错误如果你没有验证就接受了,可能会导致你对整个项目的理解建立在一个错误的基础上。
坑三:试图一次读完。
复杂的开源项目不是一个下午能读完的。vLLM的代码我前前后后读了大概两周,中间穿插着其他工作。
不要给自己压力说”今天一定要把这个项目读完”。你今天读明白了一条主线,就是实实在在的进展。明天再读一条。
每次读完记得写笔记。 你下次再回来的时候,看一眼笔记就能快速恢复上下文,不用从头开始。
坑四:只读不跑。
这可能是最大的坑。
光看代码你能理解的东西是有限的。把项目跑起来,加几个断点或者打几行日志,亲眼看到数据怎么流动的——这个过程给你的理解深度是光看代码的好几倍。
你可以让Cursor帮你做这件事:
GPT plus 代充 只需 145我想在本地把这个项目跑起来,走通一个最简单的例子。 请告诉我最少需要哪些步骤。如果有复杂的外部依赖 可以mock掉的,告诉我怎么mock。
不需要搭建完整的开发环境。只要能跑通一个最小的例子,能让你在关键位置加断点看到数据,就够了。
跑起来之后,在你走过的主线上的关键函数入口加个断点或者日志。然后触发一个请求,看实际的执行路径是不是跟你读代码时理解的一致。
经常会有惊喜。 你以为数据走的是路径A,实际上走的是路径B——因为有一个条件分支你读代码时忽略了。这种”预期和现实的偏差”本身就是最好的学习机会。
不同类型的项目,”故事线”的选择方式不一样。简单说几个常见的:
Web框架类(FastAPI、Express、Gin等):
最好的故事线是”一个HTTP请求从进入到返回的完整生命周期”。从监听端口→接收请求→路由匹配→中间件执行→handler调用→响应返回。这条线走完,你就理解了框架的骨架。
数据库/存储引擎类(Redis、LevelDB、SQLite等):
最好的故事线是”一个写操作从接收到持久化的完整路径”。从命令解析→数据结构操作→内存写入→持久化到磁盘。然后再走一条”读操作”的路径。两条路径交叉的地方就是核心的数据结构和存储引擎。
AI推理/训练框架类(vLLM、DeepSpeed、PyTorch等):
最好的故事线是”一个前向传播从输入到输出的完整路径”。从数据预处理→模型加载→计算执行→结果后处理。特别注意计算是在哪里从Python进入C++/CUDA的——那个边界通常是理解性能优化的关键。
编译器/解释器类(CPython、V8、GCC等):
最好的故事线是”一段源代码从文本到被执行的完整路径”。从词法分析→语法分析→AST→中间表示→优化→代码生成/执行。每一步的输入和输出是什么,格式是什么。
不管哪种类型的项目,核心思路都是一样的:找到一条从入口到出口的主线,沿着它走,遇到障碍时让Cursor帮你清除障碍。
最后把整个流程用一个具体的例子串一遍。假设你想理解FastAPI是怎么工作的。
起手。 把FastAPI的仓库clone下来,用Cursor打开。
找入口。 问Cursor:
当用户写了这样的代码:app = FastAPI()
@app.get(”/hello“) def hello():
GPT plus 代充 只需 145return {"msg": "hello"}
请告诉我 @app.get 这个装饰器的代码在哪个文件的 哪个函数里定义的。只给我位置,不用解释。
Cursor告诉你在fastapi/applications.py里。打开它。
沿主线走。 你看到app.get实际上调用了self.router.add_api_route()。你不知道这个函数做了什么。选中它,问Cursor:
这个函数做了什么?一句话概括。它在哪定义的?Cursor告诉你它在fastapi/routing.py里,作用是”把你的函数包装成一个APIRoute对象,注册到路由表里”。
你跳到routing.py,看到了APIRoute这个类。你好奇路由匹配是怎么做的——当一个请求进来时,框架怎么知道该调用哪个handler?
GPT plus 代充 只需 145当一个HTTP请求到达时,FastAPI是怎么匹配到 对应的路由handler的?从哪个函数开始?
Cursor告诉你FastAPI底层用的是Starlette的路由系统。实际的匹配逻辑在Starlette的Router.call里。
遇到技术栈边界。 你可能不熟悉Starlette。没关系:
我不熟悉Starlette。FastAPI和Starlette是什么关系? 我只需要知道它们之间的边界在哪——FastAPI自己做了什么, 哪些事情是委托给Starlette做的?Cursor会解释清楚边界。你决定要不要跨过这个边界深入到Starlette里去。也许现在不需要——你只需要知道”路由匹配这件事Starlette替你做了”就行,你更感兴趣的是FastAPI自己加了什么东西。
记笔记。 走完这条主线之后你写下:
GPT plus 代充 只需 145 一个请求的处理流程
- 启动时:@app.get 装饰器 → router.add_api_route() → 创建 APIRoute 对象 → 注册到路由表
- 请求到达时:Starlette的路由系统做URL匹配 → 找到对应的 APIRoute
- APIRoute 调用你的handler函数之前:
- 依赖注入(Depends)被解析和执行
- 请求参数被校验(用Pydantic)
- 执行handler,返回结果
- 结果被序列化成JSON返回
发现
FastAPI的核心价值不在路由(那是Starlette做的), 而在第3步——依赖注入和参数校验。 这才是它跟其他框架的本质区别。
选择深入点。 你对依赖注入特别好奇。开始第二轮探索,专门走Depends的解析流程。
循环。 每一轮探索都让你的地图更完整、更细致。三四轮之后,你对FastAPI的理解就已经远超大部分使用者了。
回到最开始的问题。
读复杂代码工程最大的难点从来不是”代码太多看不完”。代码多不可怕,可怕的是你不知道该看哪里。
Cursor最大的价值不是替你读代码,而是在你迷路的时候告诉你该往哪走。
但走路这件事,得你自己来。
每一行你亲自读过的代码、每一个你亲自想明白的逻辑、每一次你的预期和实际运行结果对不上然后你搞清楚了为什么——这些时刻构成的理解,是任何AI总结都给不了你的。
Cursor是一个极好的向导。但向导的价值是带你去你自己想去的地方,不是替你走完全程然后给你讲一遍沿途的风景。
风景得自己看。看过的才是你的。
前面《撬动“屎山”,Cursor改动遗留项目 - 知乎》说过,后续,我会找一个普通规模的业务系统帮大家尝试一下 Cursor 在遗留项目中能做到什么地步。
当时好像还在过年,没想到,一下子都要快清明节了。
非常抱歉,今天就来填坑了!
为了方便大家也去验证效果,这里直接采用了开源项目模拟。
- 后端工程源码:https://gitee.com/zccbbg/wms-ruoyi/tree/v1/
- 前端工程源码:https://gitee.com/zccbbg/ruo-yi-wms-vue/tree/v1/
该项目是“程序员诚哥”开源的一套基于若依的wms仓库管理系统,支持lodop和网页打印入库单、出库单。
大家多去支持下哈
我们设想一个场景:
某一天,风和日丽的,领导突然告诉你,项目A的客户反馈了一个问题,但原来负责项目A的同事小张临时请假,你需要快速熟悉下项目,顶上去
由于是老项目,没有文档,同事小张走得急,也没有交接。
嗯任务场景稍微苛刻了点,但,万一碰上了呢。
好了,下面咱就按照这个场景试试。
操作过程主要分为三步:
- 快速了解项目
- 运行项目
- 实现客户反馈
拿到新项目,肯定要先了解下整体情况,这么多文件,还是 AI 来吧。
由于项目前后端分离,所以分开进行分析。
为了保证有效性,两个工程的 README.MD 文件已经移除。
使用 Chat 模式,codebase,模型采用的 Claude 3.7。
提示词:
我新接手一个项目,这是后端工程。 没有文档,没有交接,请帮我快速分析一下整个项目情况,方便我能尽快熟悉项目。 请尽量聚焦对后续开发项目有用的部分。结果:
分析结果如下:
- 项目概述
- 技术栈
- 项目结构
- 核心功能
- 关键配置:数据库连接、Redis配置、日志配置、代码生成配置
- 特色功能和设计:多数据源支持、审计功能、库存分配算法、接口限流
- 开发建议
- 部署说明

提示词:
GPT plus 代充 只需 145我新接手一个项目,这是前端工程。 没有文档,没有交接,请帮我快速分析一下整个项目情况,方便我能尽快熟悉项目。 请尽量聚焦对后续开发项目有用的部分。
结果:
分析结果如下:
- 项目概述
- 技术栈
- 项目结构
- 核心功能模块
- 关键技术点:权限控制、字典管理、请求处理、组件封装
- 开发注意事项
- 快速上手建议
- 部署说明
- 潜在问题

作为初次了解项目来说,上面的内容个人感觉足够了,一个是可以很方便的让我们对项目整体有个全面的了解,另一个还能提炼出一些关键的细节。
项目了解,接下来肯定得先跑起来,要是跑不起来,一切免谈。
使用 Chat 模式,codebase,模型采用的 Claude 3.7。
提示词:
我现在需要将项目运行起来,请给出详细的操作步骤。结果:
步骤非常详细,关键的数据库连接、Redis配置、运行命令、初始化sql、访问路径都给出了。
默认密码是因为sql中有注释说明。

提示词:
GPT plus 代充 只需 145我现在需要将项目运行起来,请给出详细的操作步骤。
结果:
步骤一样详细,给出前端环境准备、安装依赖、环境变量、后端接口、运行命令、访问地址,甚至还包括多种异常情况。

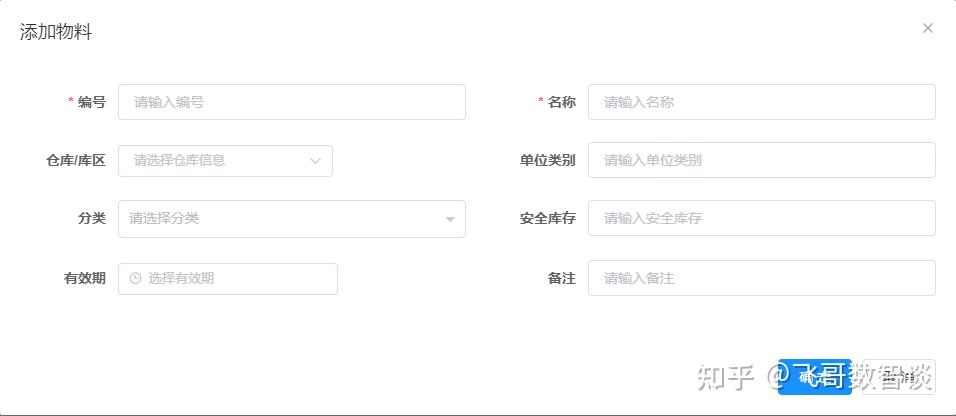
客户反馈为:物料管理中增加物品编码字段。
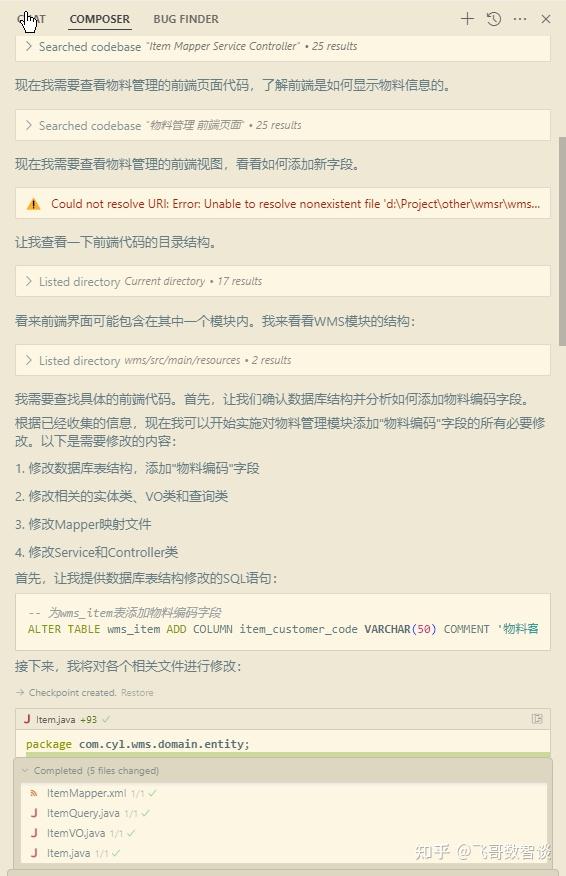
使用 Composer 模式,agent,模型采用的 Claude 3.7。
提示词:
请为物料管理模块增加“物料编码”字段,存储客户维护的物料编码信息。结果:
各个文件都有修改,非常省劲。
这一步是我人工做CRUD模块修改时最讨厌的一种场景,没有技术含量,还容易遗漏。
提示词:
GPT plus 代充 只需 145物料管理模块后端接口已经增加了“物料编码”字段item_customer_code,请对应修改前端工程代码。
结果:

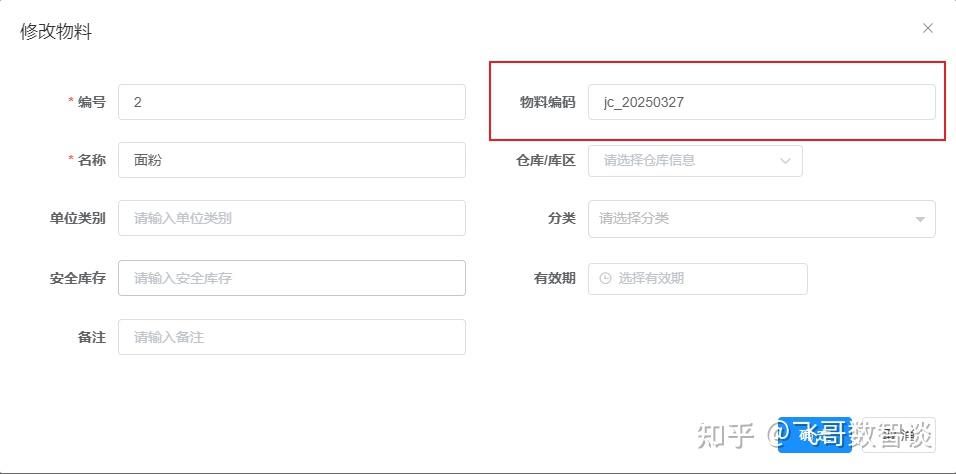

是不是感觉也还可以。
当然,实际接手一个旧项目比本次分享要复杂、难受的多,但是,通过 AI 辅助,我相信,这个过程会简单、好受一些。
不信的话,大家可以体验一下
该系列文章旨在分享“AI协同编码”的实际场景,之前由于使用 Cursor 较多,且国内没有很好的同类产品,所以命名为“Cursor实战”。
最近尝试了国内字节的 Trae,尤其是配合升级后的 DeepSeek V3-0324,虽然和 Cursor+Claude 3.7 依然有差距,但感觉可以接受。
最主要是 Trae 免费,后续计划加入 Trae 实例,这样大家也可以更好地实践分享的场景,系列名称也会升级为“AI编程实战”,希望大家继续关注哈。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/214993.html