
在与大型语言模型(LLM)的交互中,我们常常会遇到一个核心挑战:上下文限制。模型似乎总是“记不住”我们在几轮对话前说过的话,更不用说理解我们的长期偏好和特定工作流程了。这种“健忘”极大地限制了AI作为生产力工具的潜力。
然而,一个设计精良的记忆系统可以彻底改变游戏规则。它能让AI助手从一个无状态的文本处理器,转变为一个真正懂你、能够持续学习和适应的个性化伙伴。今天,我们将深入剖析一个名为 OpenClaw的AI助手其背后复杂而精妙的记忆系统架构,看看它是如何通过多层次、自动化的机制来解决记忆难题的。

OpenClaw的记忆系统主要由两大核心部分构成,它们在不同的阶段、以不同的方式将信息注入AI的“大脑”中:
1.工作空间引导文件 (Bootstrap Files):这是一组静态的Markdown文件,它们定义了AI的核心身份、行为准则和用户的基本信息。这些文件在每次会话开始时被加载,并注入到 System Prompt 中,为AI的行为设定了基础框架。
2.动态记忆系统 (Dynamic Memory System):这是一个动态变化的记忆集合,它在对话过程中实时捕捉、检索和归档信息。这些记忆根据其类型和时效性,被灵活地注入到 User Message 或整个 messages 数组中。
接下来,我们将逐一拆解这两个系统,探究其内部的运作逻辑。
想象一下,在你开始一天的工作前,你会先回顾一下自己的身份、今天的目标以及和你协作的伙伴是谁。OpenClaw的引导文件扮演的正是这个角色。这些文件存储在工作空间的根目录(/clawd/),构成了AI稳定不变的“人格”和“世界观”。
| 文件 | 主要用途 | 注入时机 | 内容摘要 |
| AGENTS.md | 核心行为规范 | 始终 | 定义内存管理、安全边界、群聊准则等。 |
| SOUL.md | AI人格与语气 | 始终 | 塑造AI的性格、价值观和沟通风格,例如“简洁、不谄媚、有自己的观点”。 |
| USER.md | 用户档案 | 主会话 | 记录用户的姓名、时区、偏好等,实现个性化交互。 |
| IDENTITY.md | AI身份标识 | 主会话 | 定义AI自己的名字、形象(Avatar)和代表性Emoji。 |
| TOOLS.md | 本地工具配置 | 始终 | 记录特定环境的配置信息,如SSH服务器地址、TTS首选音色等。 |
| MEMORY.md | 手动长期记忆 | 主会话 | 由用户或AI人工整理的关键信息,如重要决策、长期目标等。 |
| HEARTBEAT.md | 心跳定时任务 | 主会话 | 定义需要AI定期(如每小时)检查的任务清单,如“检查未读邮件”。 |
这种设计的精妙之处在于分离了“不变”与“可变”。通过将这些核心定义固化在System Prompt中,OpenClaw确保了其在任何对话中都能保持一致的行为和身份认知,避免了在长对话中“迷失自我”。
其中,MEMORY.md 和后面将要介绍的自动记忆系统形成了有趣的对比,它代表了一种“人工精炼”的记忆模式,适用于那些需要被永久置顶、不容忽视的核心事实。
如果说引导文件是AI的“本我”,那么动态记忆系统就是其在与世界互动中不断形成的“经验”和“见闻”。该系统由四种不同生命周期和用途的记忆组成。
这是最基础的记忆形式,即我们熟悉的多轮对话历史。它以jsonl格式持久化存储在本地,确保了对话的连贯性。除非用户主动执行/new命令重置会话,否则AI会一直“记得”当前的对话上下文。
在群聊场景下,AI需要理解在它没有参与时其他人聊了什么。群聊历史机制会在AI被@时,自动抓取最近的聊天记录(如50条),并将其打包注入到当前用户消息的Body文本中,帮助AI快速跟上节奏,做出有上下文的回复。
这是OpenClaw记忆系统中最具创新性的部分。它利用向量数据库LanceDB实现了自动化的长期记忆捕获与检索。
它是如何工作的?
•自动捕获 (Capture):在每次对话结束后,系统会根据预设的触发规则(如包含“我喜欢”、“我们决定”、“我的邮箱是”等关键词的句子)自动从对话中提取关键信息短句。
•分类与向量化:这些短句被分为偏好(preference)、事实(fact)、决定(decision)等类别,然后被转换成向量(Embeddings)存储到LanceDB中。
•自动检索 (Recall):在下一次对话开始前,系统会将当前的用户输入也转换为向量,并在LanceDB中进行相似度搜索,召回最相关的几条记忆。
•注入上下文:这些召回的记忆会以一个特殊的<relevant-memories>标签,被前置注入到当前的用户消息中。
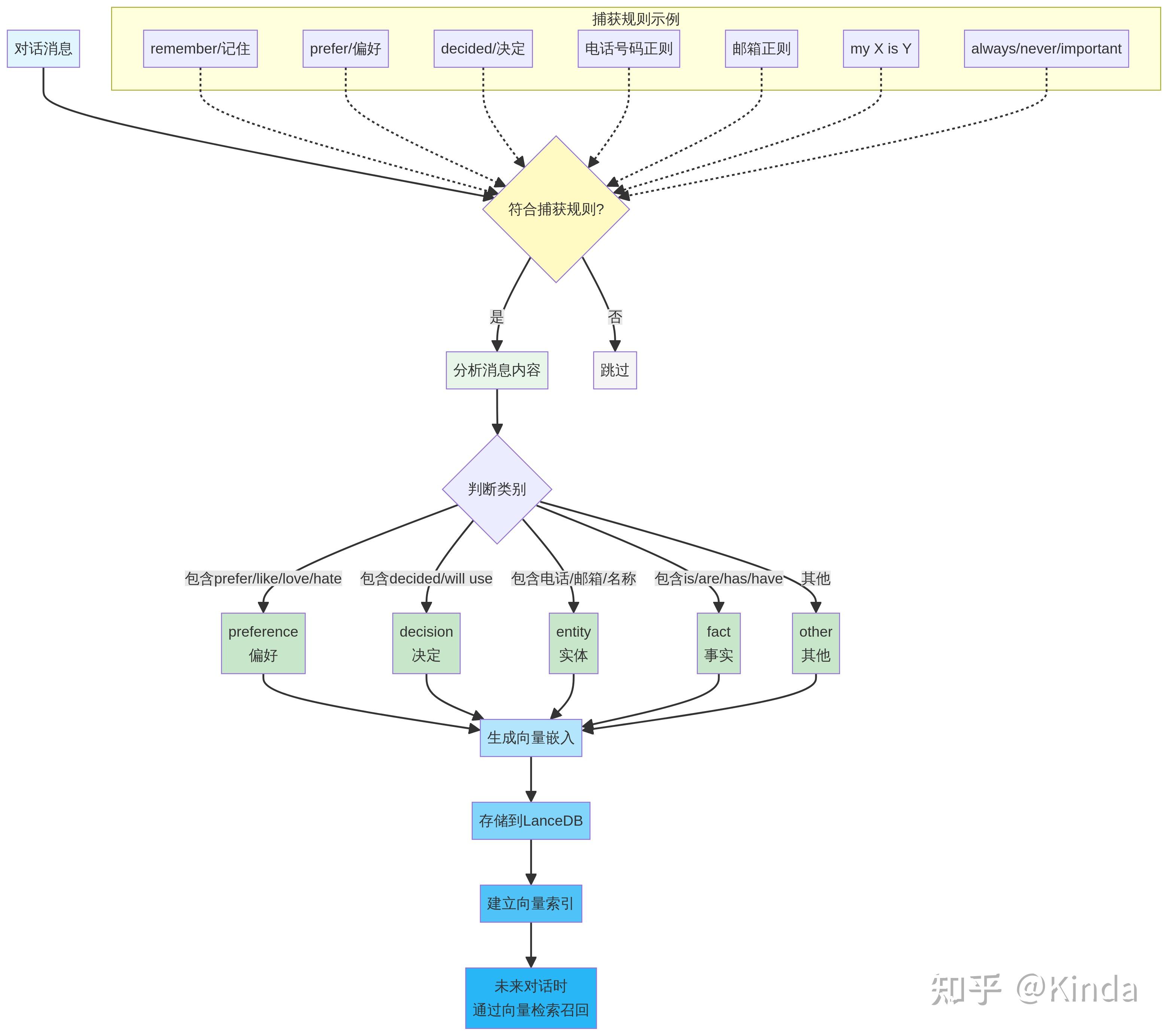
这种机制使得AI能够自动学习和记住用户的偏好、重要事实和决策,而无需人工干预。例如,当用户说过“我更喜欢用TypeScript”,这个偏好会被自动捕获。未来当用户讨论技术选型时,AI会自动回忆起这一点,并可能建议使用TypeScript。
当一个会话通过/new命令结束时,它并不会被简单地丢弃。session-memory钩子会被触发,将这次完整的对话内容(包括由LLM生成的摘要标题)保存为一个独立的Markdown文件,存储在/clawd/memory/目录下。这些归档文件默认不注入任何上下文,但它们有两个重要用途:
•人工回顾:用户可以随时翻阅这些历史档案。
•AI主动读取:由于AI具备文件读写能力,用户可以命令它“去memory目录下找找我们上次关于API设计的讨论”,AI便能主动去查阅这些归档,实现跨会话的知识检索。
现在,让我们将所有部分串联起来,看看当一个用户消息抵达时,OpenClaw是如何一步步构建出最终发送给LLM的完整上下文的。
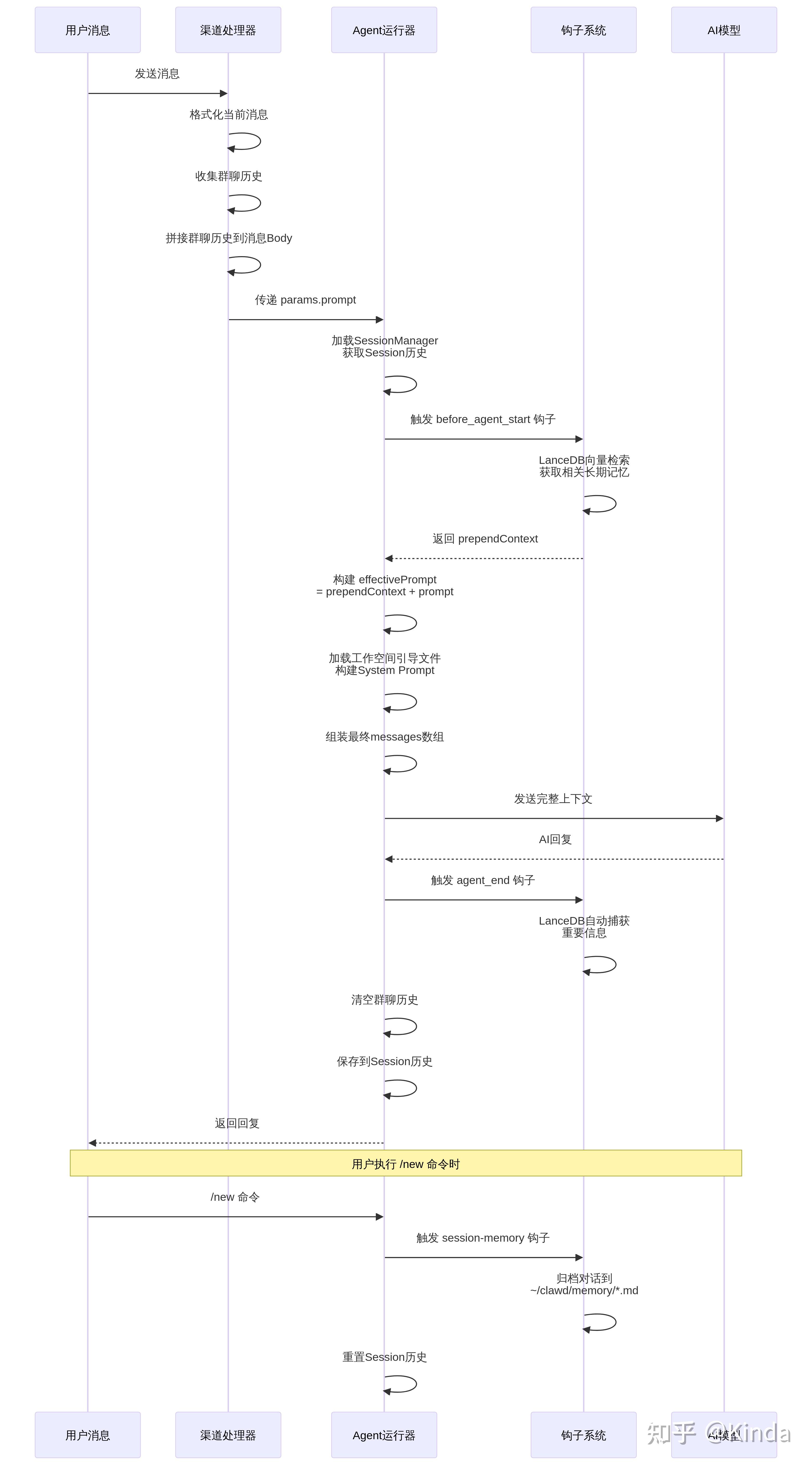
这个过程可以概括为以下几个关键步骤:
1.渠道层处理:接收原始消息,并注入群聊历史(如果适用)。
2.Agent运行器:
a. 加载Session历史(短期记忆)。
b. 触发before_agent_start钩子,检索并前置注入LanceDB记忆(自动长期记忆)。
c. 加载工作空间引导文件,构建System Prompt。
3.组装与发送:将System Prompt、Session历史和经过层层包装的当前用户消息(包含LanceDB记忆和群聊历史)组装成最终的messages数组,发送给AI模型。
4.回复后处理:
a. 触发agent_end钩子,进行LanceDB记忆的自动捕获。
b. 将当前对话存入Session历史。
最终,AI接收到的上下文结构是高度丰富且结构化的,如下图所示:
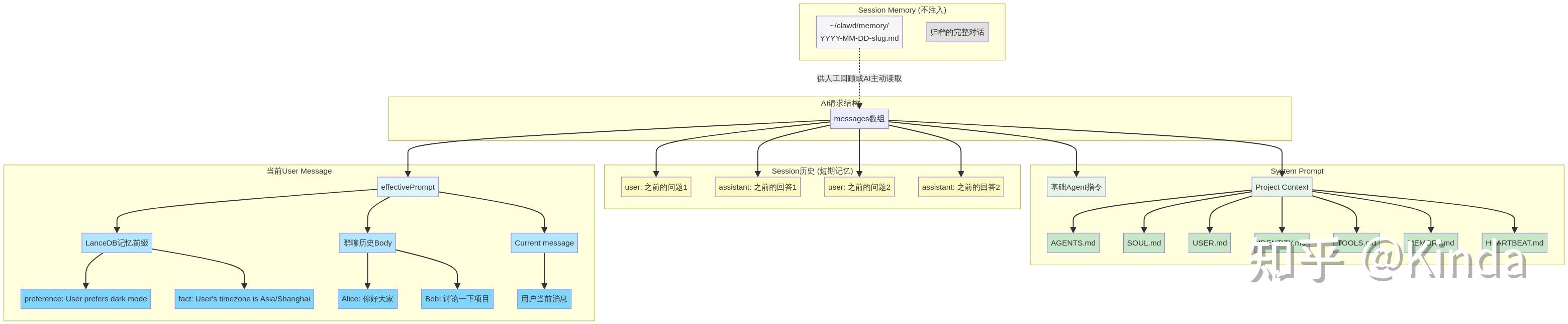
记忆系统的对比与思考
OpenClaw的设计为我们展示了一个优雅的、分层的记忆解决方案。不同类型的记忆机制各司其职,互为补充。
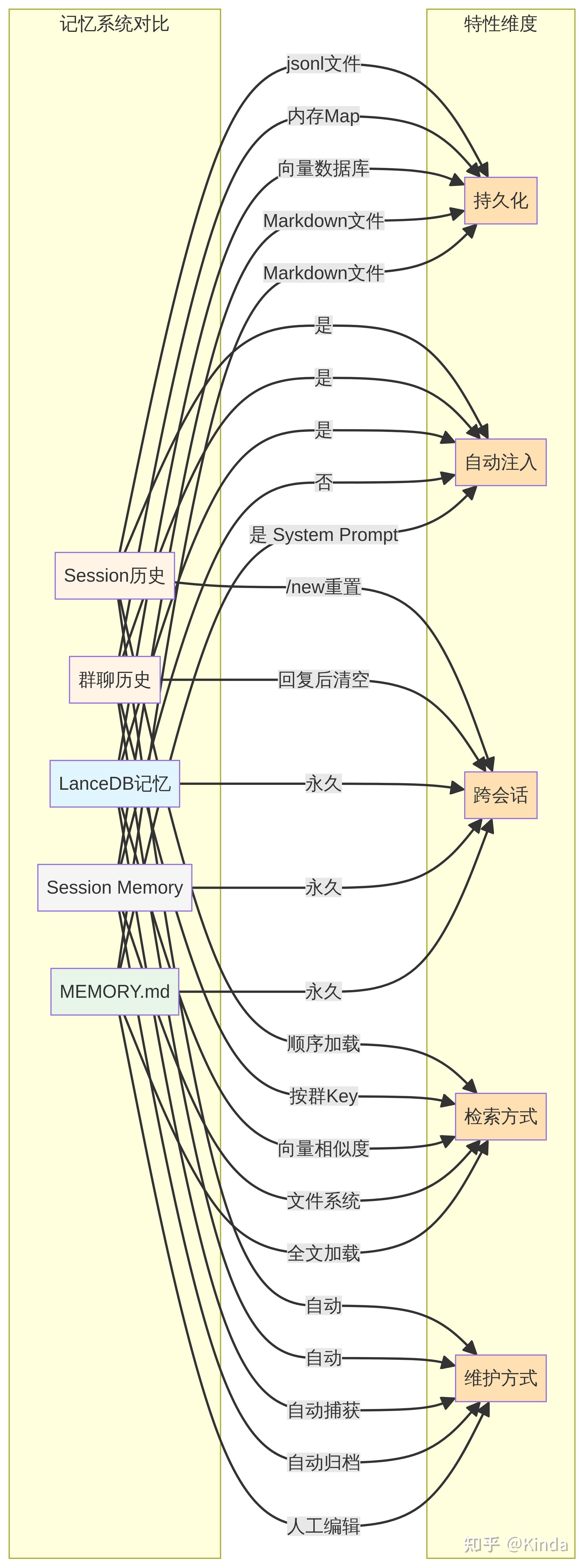
特别值得关注的是 MEMORY.md (手动) vs LanceDB (自动) 这两种长期记忆的实现方式:
| 维度 | MEMORY.md (人工记忆) | LanceDB (自动记忆) |
| 维护方式 | 人工编辑,确保高质量和高信噪比 | 自动捕获,低门槛,覆盖面广 |
| 注入位置 | System Prompt,作为核心背景知识 | User Message 前缀,作为即时相关提醒 |
| 检索方式 | 全文加载,保证核心信息不被遗漏 | 向量相似度,动态、按需召回 |
| 适用内容 | 重大决策、长期规划、核心原则 | 用户偏好、零散事实、联系方式 |
这种“手动+自动”的双轨制设计,兼顾了记忆的准确性和覆盖度,让AI既能牢记那些由人类定义的“顶层设计”,又能从日常交互中不断汲取“营养”,持续成长。
OpenClaw的记忆系统架构是一个精心设计的工程杰作。它通过引导文件、多轮对话历史、群聊上下文、向量数据库和归档机制,构建了一个从静态到动态、从短期到长期、从手动到自动的全方位记忆解决方案。这也是为什么大家用起来token爆炸,感觉自己账单又要超了😄
这种分层、结构化的上下文管理方法,不仅极大地扩展了AI的有效记忆容量,更重要的是,它为构建真正个性化、能够与用户共同成长的AI助手提供了一个坚实而可行的蓝图。未来,我们或许不再需要对AI反复强调我们的需求,因为它们已经拥有了一颗强大的“记忆核心”,真正地“认识”我们每一个人。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/214181.html