
OpenClaw 是目前最火的 AI Agent。上个月底它刚火出圈时我没怎么关注,因为我觉得大模型底层的不确定性无法根除,这无非是一个体验稍好点的 AutoGPT 罢了。加上当时正忙着关注史诗级的白银暴跌事件,便没太在意。
如今一个月过去了,OpenClaw 热度不减,甚至百度和 Kimi 都跟进推出了面向用户的同类产品。最近又刷到不少关于“用 OpenClaw 赚钱”的帖子,我决定深入看看这个项目到底有何特别之处。
作为来自上个世纪的程序员,我习惯通过直接阅读源码来了解项目。但 OpenClaw 的代码库已经膨胀到了 100 万行(其中 TypeScript 有 76 万行),人类已无法快速通读。因此,我借助 DeepWiki 提取要点来了解。
虽然代码量巨大,但其核心架构和原理其实非常简单,概括如下:
- 接入层:启动一个 WebSocket 服务,作为网关接收来自 WhatsApp、飞书等各个渠道的消息。
- 核心循环:用户在客户端发起消息后,系统进入 Agent 核心循环(基于 pi-agent-core)。这一步会进行记忆检索、安全检测,进而调用核心工具(Tools)或技能(SKILLs)来执行任务,最后将结果写入消息队列。
- 响应和存储:将执行结果返回给客户端,并存储聊天记录。
那这 76 万行代码都写了啥?其实大部分是在处理各消息平台的对接、会话及记忆管理、配置管理、大模型连接适配、错误处理、安装向导、CLI 接口、扩展机制以及 Mac 客户端开发等。这些虽然是工程落地的必要部分,但与核心 AI 能力关系并不大。
如果你只需要支持少数几个国内消息平台,完全可以用不到 1 万行代码开发出一个实现 OpenClaw 99% AI 能力的 Agent,比如 nanoclaw 和 nanobot。
因此,我认为没必要死磕 OpenClaw 的源码。它功能不复杂,代码却太冗长。它真正值得研究的价值,在于演示了一个专业开发者如何利用代码 Agent 达到超越整个团队的产出量。
GPT plus 代充 只需 145
OpenClaw 的作者 Peter 最高一天能提交 1881 次代码,平均几分钟一次,每天修改代码量甚至能达到 10 万行。这在传统软件工程中是不可想象的——在 AI 介入前,最优秀的开发者每天平均产出也不过 1000 多行。
代码智能体彻底打破了“人月神话”,将开发者之间的产出差距急剧放大。会用 Agent 的人,一个人就是一支上百人团队。
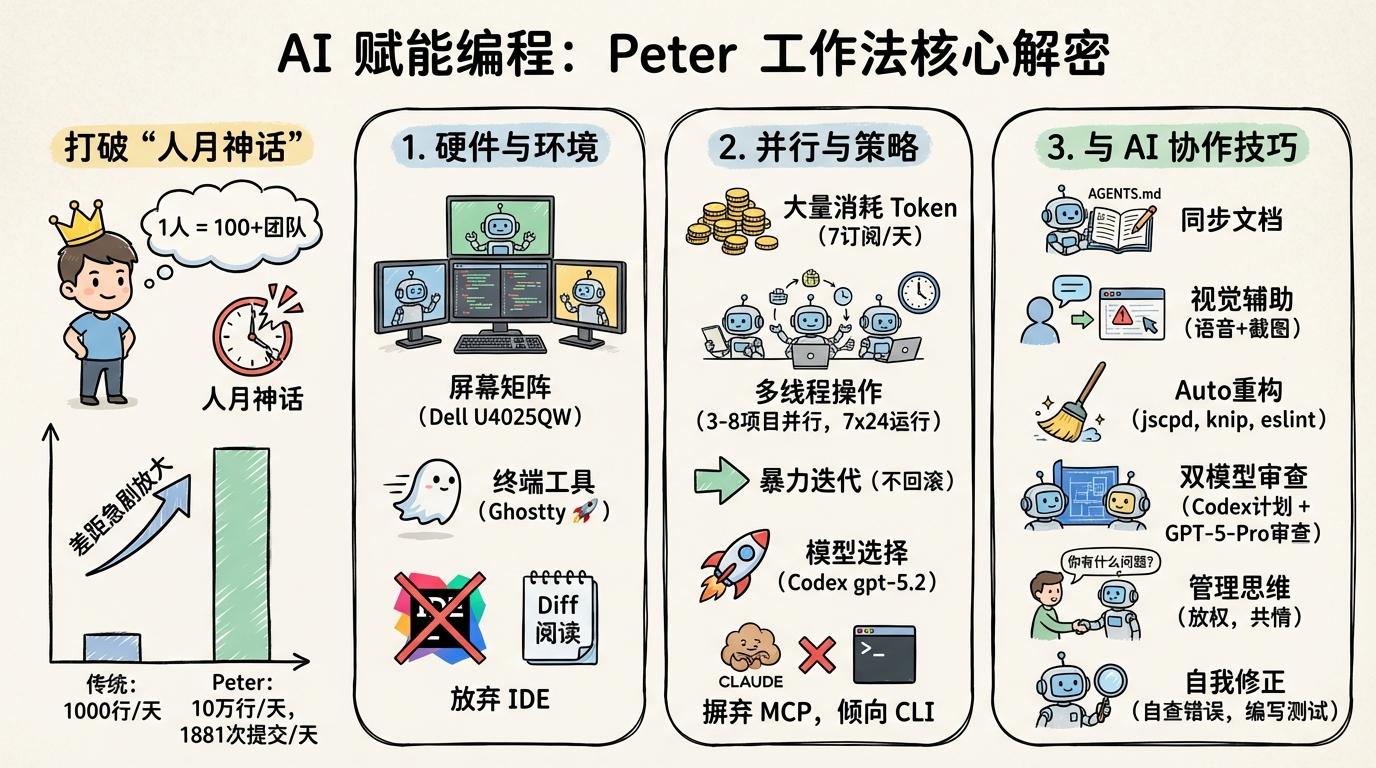
Peter 是怎么做到的?结合他在 Lex Fridman 访谈 和个人 Blog 中的分享,我将他的工作法总结为以下三类:
- 屏幕矩阵:使用 Dell UltraSharp U4025QW 显示器,同时监控 4 个智能体实例。
- 终端工具:使用 Ghostty,因为渲染速度快。
- 放弃 IDE:很少使用 IDE,编辑器主要用来阅读 diff,甚至现在连代码都很少读了。
- 大量消耗 Token:最多时候有 7 个订阅(就是注册多个帐号),每天能消耗一个订阅的 Token 用量。
- 多线程操作:同时处理 3-8 个项目。因为智能体写代码、执行通常需要半小时,并行处理可以最大化利用时间。只需盯着它们干活,发现不对劲就终止。
- 7x24 运行:同时运行 4-10 个智能体,睡觉时也在跑。
- 暴力迭代:不回滚代码,有问题就让智能体继续改。
- 模型选择:现在主要使用 Codex (gpt-5.2-codex high)。相比 Claude Code,Codex 上下文更大(230k)、Token 更高效、支持消息队列、且基于 Rust 编写速度更快(不像 Claude Code 经常占用数 G 内存)。
- 摒弃 MCP:Peter 和 pi-mono 的开发者 Mario 都很反感 MCP,认为占用了太多上下文,他们更倾向于使用支持命令行的 CLI 工具。
- 同步文档:编写代码的同时让智能体编写文档。在
AGENTS.md里,让智能体执行任务时参考这些文档。 - 视觉辅助:利用 Codex 强大的多模态能力,开发 UI 时只需 1-2 句语音提示词配上错误截图,智能体就能理解。
- 自动化重构:使用
jscpd处理重复代码,用knip标记无用代码,利用eslint的react-compiler检查,拆分大文件,自动添加测试和注释。 - 双模型审查:遇到棘手问题,先让 Codex 讨论并写出开发计划,再交给 GPT-5-Pro 审查(通过 http://chatgpt.com),看看是否有更好的想法。
- 管理思维:像管理团队一样放权。不要在命名等细节上死磕,要有共情能力,经常问智能体“你有什么问题要问我吗?”。
- 自我修正:让智能体自查错误(“你看到了什么错误?去读源码,搞清楚问题在哪”),并要求在每次修复后编写测试,这往往能发现人类忽视的逻辑漏洞。
整个过程完全是不断试出来的,结论就是要多和 AI 说话来培养直觉,通过多轮对话来交流,如果你是程序员,我建议最好赶紧学习如何鞭策多个智能体写代码,这个技能将是未来程序员之间的最大差距,说实话我自己也不太习惯这种工作方式,现在只敢让智能体做些简单的事情,看来后续得多尝试适应 AI 了。
Peter 加入 OpenAI 的原因,我猜很大程度上是因为能无限免费使用基于 Cerebras 的高速 Codex 模型,这对他的吸引力恐怕远大于金钱。
回到 OpenClaw 本身,它与 AutoGPT 等智能体的区别主要在于:
- 交互方式:使用 IM 网关接收命令,而非单纯的命令行。
- 能力扩展:使用 SKILLs 来扩充功能。
- 权限全开:直接执行命令行调用,放开了所有电脑权限。这是它能做很多事的前提,也是最大的安全争议点,以前没人敢这么“做死”。
- 自我进化:可以修改自己的代码。
- 多 Agent 协作:支持多个智能体并行。
- 后台常驻:支持定时心跳自动执行(默认 30 分钟一次)。以前没人做大概是因为没 Peter 那么有钱,烧不起 Token。
这里重点提一下 SKILLs。它本质上是教会模型如何调用命令的 Markdown 文本(参考 Anthropic 示例)。相比 Tools 和 MCP,SKILL 有三大优势:
- LLM 原生:这是更加 LLM 原生的方式,比起之前的自定义的 Tools 和 MCP 服务,SKILL 直接通过文本方式告诉模型如何实现某个功能,这种实现方式大概率在 LLM 预训练的时候就看过了,所以大模型天然就能理解。
- 易移植:拷贝文件即可,skillsmp 等平台上有大量现成资源。
- 门槛低:普通人也能写,不需要像写 Tools/MCP 那样编写代码和测试用例。
我认为 OpenClaw 出圈的重要原因是打通了 IM 和命令行。你可以随时随地通过聊天软件发命令,这种感觉比坐在电脑前敲终端奇妙得多。
了解架构后来看看 OpenClaw 能做什么,以下是一篇宣传文章中的说法:
过去一周左右,我一直在使用一个数字助手,它知道我的名字,了解我早晨的日常习惯,知道我喜欢如何使用 Notion 和 Todoist,同时它还能控制 Spotify 和我的 Sonos 音箱、飞利浦 Hue 灯,以及我的 Gmail。它基于 Anthropic 的 Claude Opus 4.5 模型运行,但我通过 Telegram 与它交流。我给这个助手命名为 Navi,Navi 甚至能接收我的音频消息,并使用最新的 ElevenLabs 文本转语音模型生成其他音频消息进行回应。哦,对了,我还没提到 Navi 可以通过新功能进行自我改进,而且它正在我自己的 M4 Mac 迷你服务器上运行?
要说 OpenClaw 从根本上改变了我对 2026 年智能个人 AI 助手意义的理解,那都算是一种轻描淡写了。我一直在玩 OpenClaw,已经在 Anthropic API 上烧掉了 1.8 亿个 token。
听起来很美好,但我的第一反应是:真麻烦。
这里面所有第三方应用你都得找到对应的 API 调用方法,还有个智能音箱和 Hue 灯,我不用想就知道我家那些智能设备肯定不会有 API,而且自动开关窗帘什么的为啥要用大模型,另外我也有个 Hue 灯,之前设置了定时开关结果不太准,经常莫名奇妙在白天或下半夜开启,吓死人了,现在我都手动开关。。
在我看来文章里提到这些都没啥用,比起那一点点有的没的收益,我更心疼 token 烧掉的钱,1.8 亿 token 就算只算输入也要 900\(,如果包括输出可能实际花了 2000\),而且这才用了没几天,花那么多钱都够雇佣两个女大兼职了吧,却只能做点不痛不痒的事情,是不是傻???当然不是,这篇文章主要目的其实是卖课。
我搜集了网上其他人用 OpenClaw 做的事,大概有这些:
- 新闻摘要:每天收集新闻整理。
- 评价:有很多公众号每天都有人整理,没必要自己花钱。
- 邮件管理:自动分类、归档、回复。
- 评价:交给大模型做这些事风险太高。
- 日程管理及提醒:
- 评价:这种简单功能免费的 Siri 就够用了。
- 备忘记录:
- 评价:我现在笔记只用 Obsidian,配合 Remotely Save 同步,每个月的花费可以忽略不计。
- IM 消息整理:
- 评价:风险也很高,而且国内微信、 用不了,导致用处不大。
- 网页监控/服务器监控:
- 评价:怀疑是编的,成本太高了,不如传统监控。
- 自媒体运营:查找热点、写文章。
- 评价:这看起来是最刚需的功能,但编写一个专门的 Agent 可能更便宜可控。
- 网站审计:借助 squirrelscan。
- 评价:其实就是调命令行,完全不需要依赖 OpenClaw,怀疑就是来蹭热点的。
- 开发辅助相关:写代码、处理 ISSUE、PR 等
- 评价:和 Code 类智能体能做的事情一样。
- 其他:PDF 处理、PPT 制作、Chat 问答。
- 评价:不如用专门的 Python 脚本或千问/豆包 APP。
整体看似乎没很吸引我的功能,加上 OpenClaw 安装起来挺麻烦,我个人不看好直接给普通用户提供 OpenClaw 的产品,非程序员根本玩不起来,得注册一堆开发者帐号和配置 API,结果就是两头不讨好,普通人玩不明白,会玩的自己搭服务器更便宜可控,而且 OpenClaw 真正运行起来好多是要连 github 等外网资源的,国内机房水土不服,我自己部署也是使用国外虚拟机。
这次 OpenClaw 比较吸引眼球的地方是有人拿它来赚钱了,我找到的赚钱方式有以下几种:
- Polymarket 套利:寻找微套利机会,比如概率总和小于 1 的情况,还有那些极低概率的事情,比如美国政府确认外星人存在。
- 我非常怀疑这件事的真实性,因为这个功能根本不需要用大模型,只需确定规则就能实现,成本低速度快,加上现在知道的人多了,已经没什么机会。
- 代安装/托管服务:帮人安装或提供 SaaS 版 OpenClaw。
- 垂直领域工具:利用它开发面向自媒体、电商、法律的专用工具。但感觉这更像是 Code 智能体的功劳,而非 OpenClaw 本身。
- 卖课:唯一不太辛苦且稳赚不赔的生意。
最后还得是卖课。
如果想开发国内版 OpenClaw,会遇到很多限制,因为国内自从移动时代后就成了数据孤岛:
- 通讯壁垒:微信、 没有 API,只能用飞书。
- 信息封锁:中文互联网围墙高筑,知乎、小红书等平台无 API,小红书还做了反爬机制,检测如无头浏览器。
- 平台限制:拼多多等电商平台甚至没有像样的 PC 站。
所以国内要做类似 OpenClaw 的产品只能是大厂,最好能拥有以下能力:
- 有一个广泛使用的客户端,方便内置 IM。
- 有大规模的大模型推理能力,调用外部服务成本太高不合适。
- 有代码大模型能力,许多高级功能需要依赖代码大模型来即时编写代码。
- 有虚拟化云服务能力,最好自己基于裸金属构建节省成本。
- 有语音和文字互转能力,因为现在流行语音输入和回答。
- 有搜索能力,大量功能都是需要搜索的。
- 有搜索专业数据的能力,比如经济数据、股票等。
没有不行么?如果没有这些能力,就只能高价买第三方服务,或让用户自己配置 AK/SK 及 Token,这样太麻烦了无法作为用户产品。
如果想做得更完善,最好还能有以下能力:
- 生图能力,或专业图片搜索能力,用于生成 PPT 功能。
- 电商平台、外卖平台,让用户可以买东西。
- 酒店旅游服务,实现旅行规划功能。
- 办公相关服务,比如邮箱、日程、笔记等。
这么看来,最后赢家不是千问就是豆包吧。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/213511.html