
OpenAI的chatGPT背后的大模型是GPT-3.5和GPT-4,大家常说chatGPT有1750亿参数,其实是指GPT-3.5和GPT-4的参数数量。但实际情况是:
1、GPT-3有大大小小好多个模型,最大的一个模型的参数是1750亿,这个是OpenAI自己公布的。
2、GPT-3.5是基于GPT-3进行指令调优和RLHF调优来的,模型名称是text-davinci-003,参数数量估计和GPT-3一样,也是1750亿。
3、至于gpt-3.5-turbo,是经过蒸馏或shrink的,实际参数可能也就十几亿(所以才会又快又便宜)。
4、而GPT-4,今天早上才有消息说,大概是将近2万亿参数的规模(可以参考我刚写的另一篇文章《MoE:GPT-4超过了1.76万亿参数,是怎么做到的?》)
既然GPT-3是基础,而且它的架构和参数数量都是公开的,我们不妨自己测算一下它的参数数量是怎么来的,也借这个机会熟悉一下GPT系列模型的decoder-only架构。
一、首先,GPT-3的模型是由四个部分组成的:输入层,Attention层,前向连接层,输出层。具体过程是:
1、一系列的字符串(窗口长度那么多),经过输入层,变成了一系列的tokens(表示为窗口长度*词向量维度的一个矩阵)
2、在经过多层的Attention层和前向连接层,变成了另一系列的tokens(表示为窗口长度*词向量维度的一个矩阵)
3、经过输出层,变成了一个token(表示为一个词向量)
二、其次,我们来看GPT-3的模型参数都分布在哪里:输入层和输出层是共享参数的,所以只计算输入层的就可以了。Attention层和前向连接层是连在一起的形成单独的一个transformer层。整个GPT-3就是由一个输入层,若干个transformer层,一个输出层组成的。所以,下面的公式基本上就是GPT-3的主要的参数分布的位置了:输入层参数 + 层数 *(Attention层参数 + 前向连接层参数)。
1、输入层参数包括两部分:embedding编码层参数+位置编码层参数
embedding编码层参数量 = 词向量维度 * 词表大小
位置编码层参数量 = 词向量维度 * 窗口长度
所以,输入层参数量 = 词向量维度 * (词表大小 + 窗口长度)
2、Attention层参数包括两部分:QKV三个矩阵+线性变换层参数
QKV三个矩阵的大小都是一样的,3个矩阵大小=3*词向量维度*词向量维度
线性变换层参数量=词向量维度*词向量维度
所以,Attention层参数量 = 4 * 词向量维度 * 词向量维度
这里有人会问,那个多头自注意力里的头数呢?其实,在每个头的每个QKV矩阵中,都是注意力维度*词向量的大小。在GPT-3中,注意力维度设置成了词向量维度/注意力头数量。这是个超参,就是根据经验试出来的:)
3、前向连接层参数包括四个部分:两个权重矩阵 + 两个偏置变换
权重矩阵(向隐藏层映射)参数量 = 词向量维度 * 隐藏层维度
偏置变换(隐藏层)参数量 = 隐藏层维度
权重矩阵(从隐藏层映射)参数量 = 隐藏层维度 * 词向量维度
偏置变换(词向量层)参数量 = 词向量维度
GPT-3中,隐藏层维度设置成了4倍的词向量维度。这又是个超参,还是根据经验试出来的:)
所以,前向连接层参数量 = 8 * 词向量维度 * 词向量维度 + 5 * 词向量维度
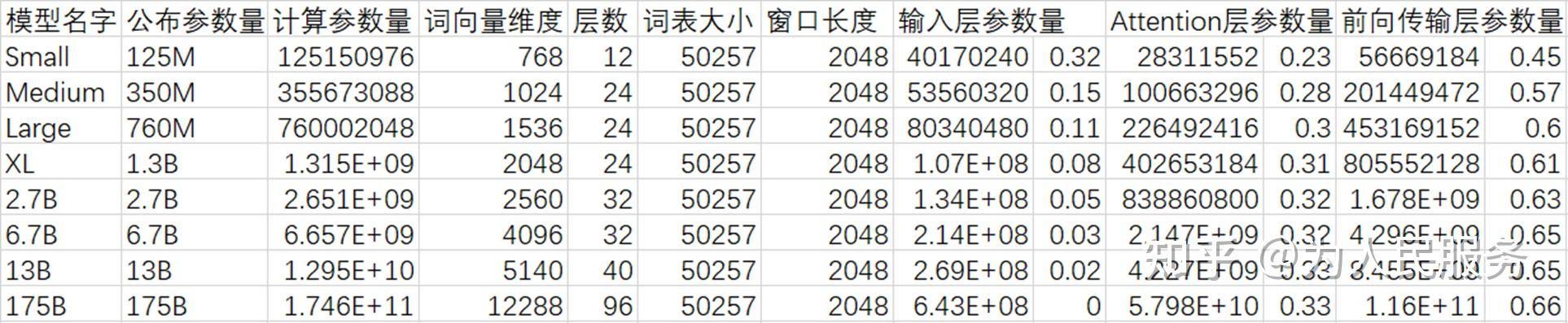
三、最后,我们来实际计算一下GPT-3的8个模型的参数量,并分析一下参数分布情况,以及影响参数量的主要因素:
1、GPT-3的参数量 = 输入层参数量 + 层数 *(Attention层参数量 + 前向连接层参数量)
= 12 * 层数 * 词向量维度 * 词向量维度 + (词表大小 + 窗口长度 + 5 * 层数) * 词向量维度
2、我们把GPT-3的8个模型的超参带入以上公式,计算得到每个模型的参数量。
GPT plus 代充 只需 145
3、我们分析GPT-3模型的参数分布,可以得出三个结论:
1)影响参数的主要变量有四个,其中影响最大的是词向量维度(指数影响),其次是层数(高线性影响),最小的是词表大小和窗口长度(低线性影响)。
2)输入层参数量占比最低,而且模型越大,占比越低(在175B模型中几乎可以忽略不计)。 在八个模型中,175B一般被称为GPT-3模型。
3)前向传播层参数量占比最高,约为Attention层的2倍多一点点。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/211049.html