
陈巍谈芯:本文是《GPT-4核心技术分析报告》的第5章。从GPT-4和ChatGPT的准确算力需求,讲解GPT-4和ChatGPT模型训练集群和与大模型计算相关的各类芯片技术,适合GPT-4技术入门和投资人熟悉相关技术。主编作者本人曾担任领域知名自然语言处理( NLP )企业的首席科学家。
本章目录
5 GPT-4的算力要点与芯片
5.1 成本估算
5.1.1 训练与部署的阶段划分
5.1.2 算力成本评估
5.2 AI训练集群
5.2.1 集群架构
5.2.2 服务器互连
5.2.3 存储墙
5.3 GPT-4计算服务器架构
5.3.1 大算力AI服务器架构
5.3.2 AI服务器内部卡间互连
5.4 GPT-4计算相关芯片
5.4.1 CPU在大模型浪潮中的角色
5.4.2 GPGPU的技术进化
5.4.3 DSA/TPU的高性能与降本增效
5.4.4 存算一体的高算力密度
5.4.5 大算力芯片架构的对比
5.4.6 HBM与Chiplet
5.5 Infiniband技术
主要参考文献
作者:陈巍博士团队
陈巍 博士
存算一体/GPU架构和AI专家,高级职称。中关村云计算产业联盟,中国光学工程学会专家,国际计算机学会(ACM)会员,中国计算机学会(CCF)专业会员。曾任AI企业首席科学家、存储芯片大厂3D NAND设计负责人。
耿云川 博士
资深SoC设计专家,软硬件协同设计专家,擅长人工智能加速芯片设计。曾任日本NEC电子EMMA-mobile构架多媒体计算系统,日本瑞萨电子车载计算SoC芯片构架(唯一外籍专家),日本瑞萨电子R-Mobile/R-Car系列车载计算芯片负责人。
陈巍:AI大模型 & GPT-4技术学习与产业资源地图(上次更新于23/07/25)陈巍谈芯:GPT-4核心技术分析报告(2)——GPT-4的技术分析(收录于GPT-4/ChatGPT技术与产业分析)由GPT-4/ChatGPT及其下游需求,带动了大量的模型设计与产业应用需求,带动了从服务器集群到大算力芯片的海量计算需求。根据IDC预计,到2026年AI推理的负载比例将进一步提升至62.2%,特别是预训练大模型几乎成为AI开发的标准范式。同时,这一需求也导致了A100 GPU的价格在几个月内暴涨超过50%,而且大量断货。
那么,在多模态大模型逐渐火热之后,GPU是唯一的算力选择吗?GPU会不会导致模型企业同质化竞争的加剧?
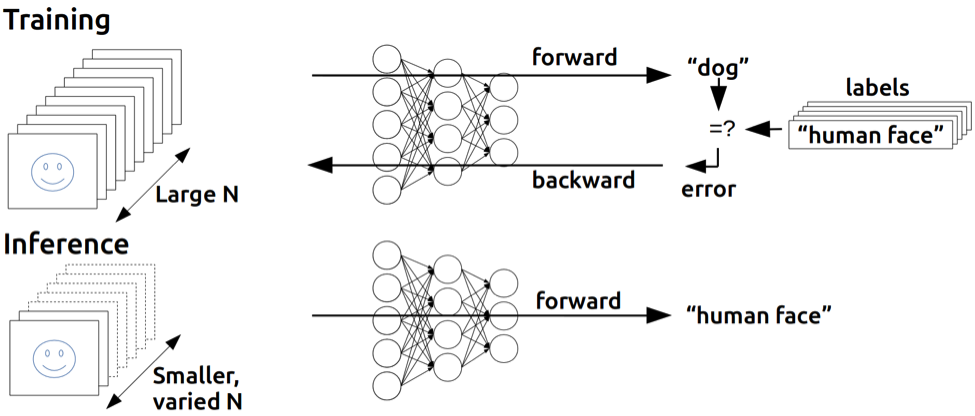
当前主流的大模型算法一般可分为“训练”(Training)和“推断”(Inference,也有媒体称推理)两个阶段。训练是建立和推导大模型参数的过程,而推断是基于模型参数进行深度学习应用或部署的过程。训练过程可以视为根据模型的海量推断结果进行反馈调优的过程,比单纯的推断多了反馈循环。一般来说,在模型的生存周期内,大模型的研发团队也会不断的进行精调(Fine-tune,可视为小规模的训练)
GPT plus 代充 只需 145
训练与推断的对比(来源:Michael Andersch)
对于ChatGPT等大模型设计或应用企业,算力的需求体现在如下三个细分阶段.
这一阶段从无到有建立预训练模型,通过大量通用数据训练和验证预训练模型。(形成模型的“通识”)然后针对具体的商用或应用场景的特定数据,对预训练进行针对性的微调,加强对场景的应答准确度。
在这一阶段,一般需要超算级别或数十台服务器来进行一个大模型的训练计算,计算以大量矩阵计算和求解为主。
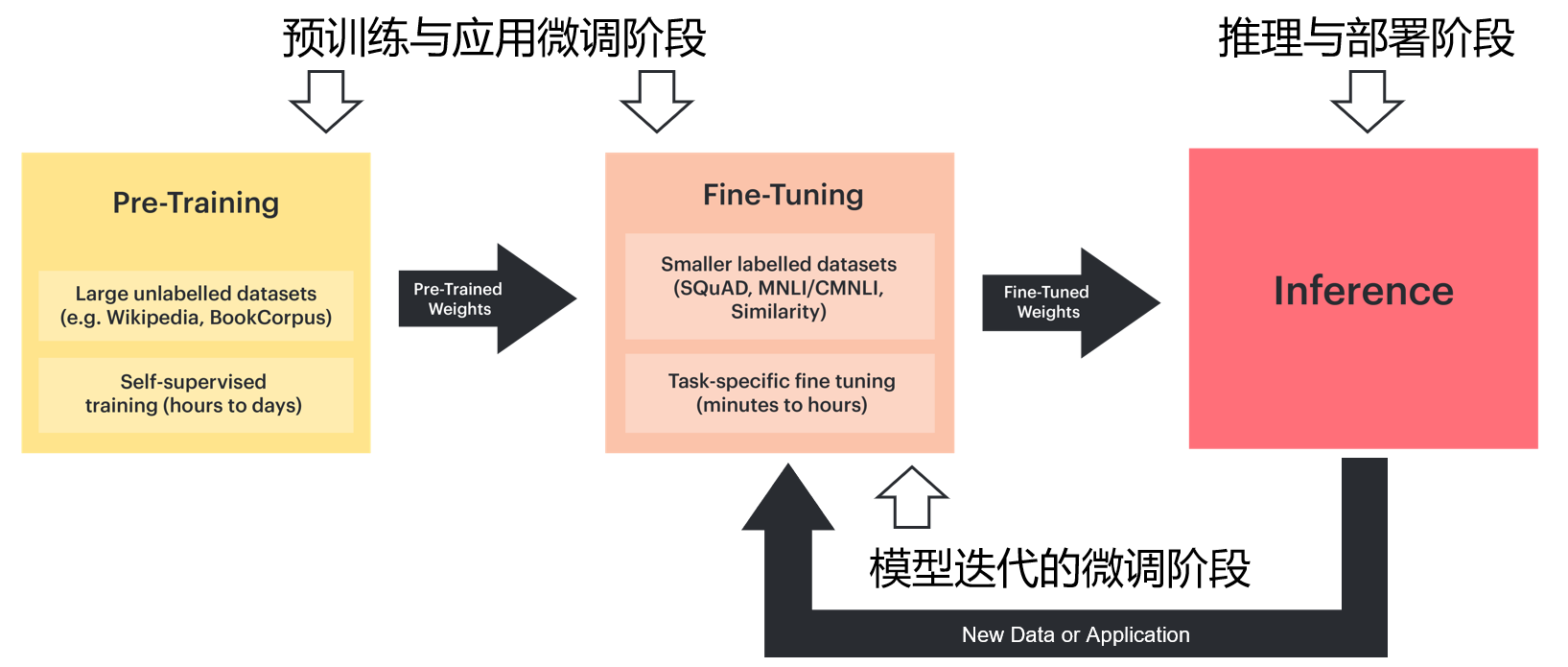
预训练模型的生命周期阶段划分(修改自GRAPHCORE)
根据场景微调后的大模型,就可部署到实际生产环境中应用。相对训练来说,部署要求的算力相对不是很高,但是部署基数特别大。特别对于大量在线交互来说,部署阶段的服务器/芯片成本要远远超过训练阶段。
在这一阶段,每台AI服务器可以部署一个模型,集群上会有大量服务器进行并行的网络服务,计算以大量矩阵计算和存储调度为主。
每使用一段时间,就会根据使用者或者客户反馈,对模型进行调整,以提高客户满意度。这个过程就是模型迭代的过程,一般相当于小规模的训练,训练所用的数据规模不大,计算以大量矩阵计算和求解为主。
之前国内有10000卡A100才适合进行175B量级大语言模型的传闻,但实际上是误传。在Azure 2020年为OpenAI准备的超算级训练研发平台上,CPU与GPU的数量比接近1:2,配置了1万块V100 GPU,而不是国内误传的A100。(在2020年初建好OpenAI超算的时候,A100还未批量上市)而且除了ChatGPT模型训练外,这一超算同时还要做DALL E 2和GPT-4等模型的训练。

训练时间的经验公式(修改自NVIDIA)
根据各家论文的严谨测算,单次GPT-3模型(175B)训练,在规模300B token下成本约为35000卡·天(A100),也就是相当于35000块A100 GPU跑1天能完成单次训练,或者2500块 A100 GPU跑2周。

根据175B参数量计算GPT-3训练时间(来源:NVIDIA)
在NVIDIA联合发布的学术论文中,给出了训练时间的经验公式。训练时间与GPU数量和模型大小成正比,与单卡实际计算吞吐量成反比。并使用训练的并行技术将GPU算力利用率提升到52%。在这一论文的实验中,训练175B GPT-3需要34天,使用了1024块A100 GPU。并行技术包括数据并行、流水线模型并行、张量模型并行和服务器通信优化。对于A100 GPU来说,有效吞吐量大概在137-163 TFLOPS附近,算力利用率在约44%到52%之间。这是目前已公开的学术论文给出的严谨算力估算。
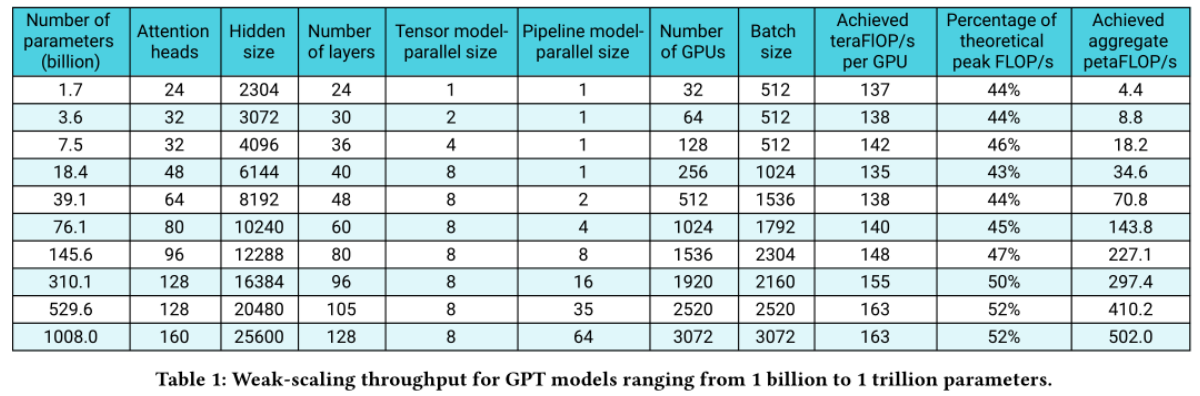
算力利用率与单卡吞吐量在不同模型大小时基本稳定(来源:NVIDIA)
ARK投资给出了北美云计算的评估,大概45万美元,即可完成单次GPT-3级别模型的训练。这个成本远远低于国内误传的10000块A100的云服务成本。
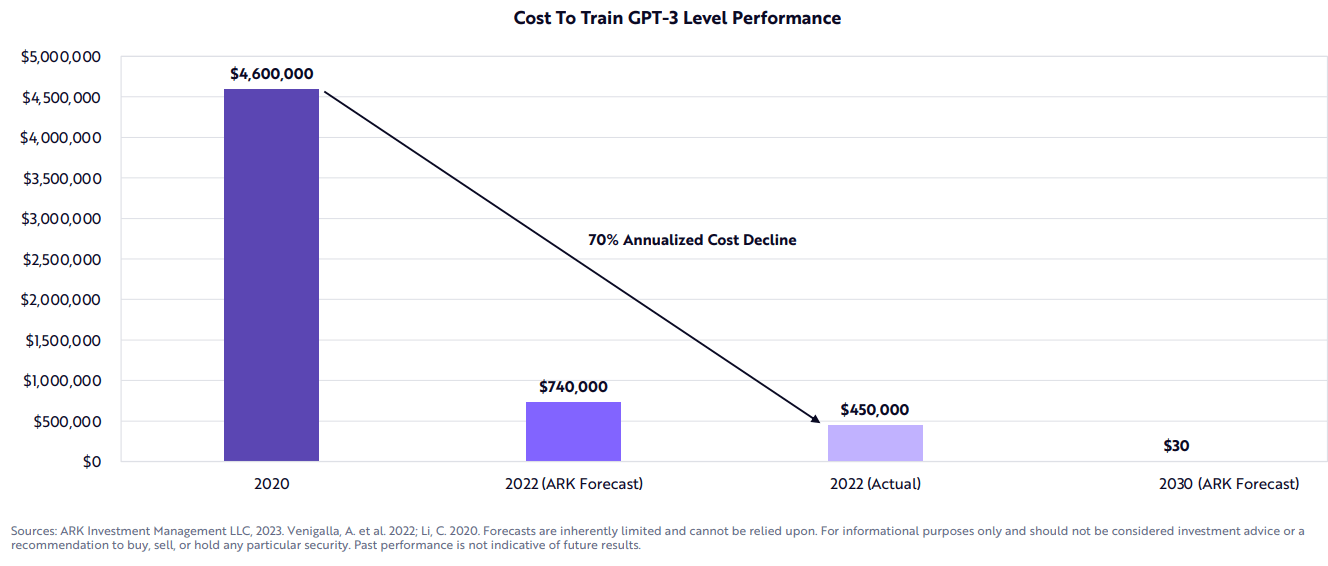
GPT-3级别模型2022年单次训练成本约为45万美元
(来源: ARK Investment Management LLC)
在整个训练用的超算平台上,除GPU外还有大量的CPU、DSA、存储等需求。尽管也有小型化的模型,但小型化模型更多适用于垂域或私人场景,或不适合互联网通用服务。
对推断部署来说,可通过类似公式线性推算计算时间。例如对6B大小的模型,进行单次推断需要6ms,则175B级别模型单次推断需要约350ms。一般一次对话约有30 token或30次推断,按照目前国内云计算服务的价格(A100 10000元/年·卡),一次GPT-3和GPT-3.5的应答成本约5分钱(RMB)。而实际上对于搜索引擎的商业模式,大概需要能低于3.5分才能收支平衡。以10亿次访问量评估,一年云计算成本约180亿RMB,远远高于训练成本。其中GPU性价比为主要瓶颈。对于多模态的GPT-4,理论上算力需求会更加巨大。
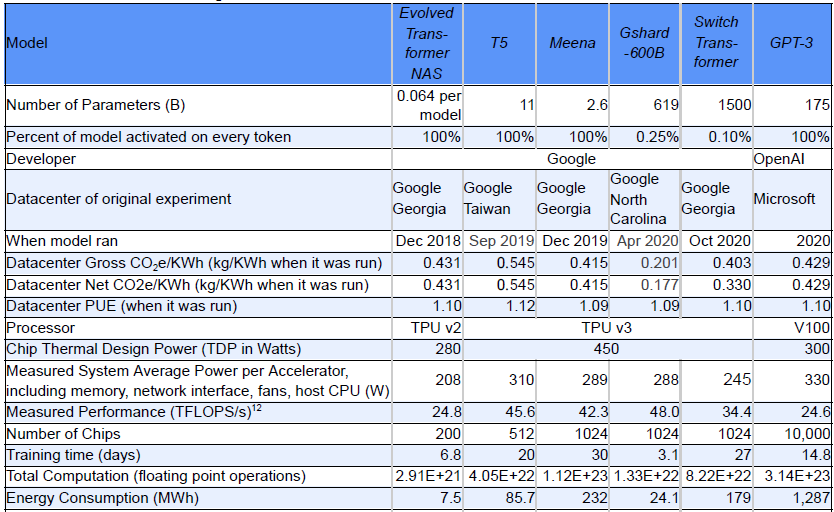
使用100块 V100(算力大概A100的3-6倍)训练GPT-3需要14.8天
(来源:Google)
虽说目前GPT-4需要跑在云服务器上,但未来GPT-4可用于私人场景或内部办公场景。在这些场景下,用户需求相对单一,使用频繁,通过硬件购置的方式部署综合性价比更高。目前看175B这个模型量级还需5块A100进行部署(主要受限于单卡存储容量和单卡算力),未来或小型化为单卡或迷你机,给大算力芯片市场带来巨大需求。
目前GPT-4和ChatGPT的训练还无法进行常规的单卡训练,往往需要要跨多个计算节点配置训练集群,通过训练软件或框架,使训练程序跨多个节点运行多个进程,多个进程协作完成单节点的功能。其中每个节点可由单台到多台AI服务器组成。
典型的计算集群包括了计算、存储和网络通信功能。跨多个系统的扩展应用程序带来了传统数据中心不常见的独特挑战。系统组件的任何瓶颈(计算、存储或通信瓶颈)都会影响应用程序有效扩展的能力。
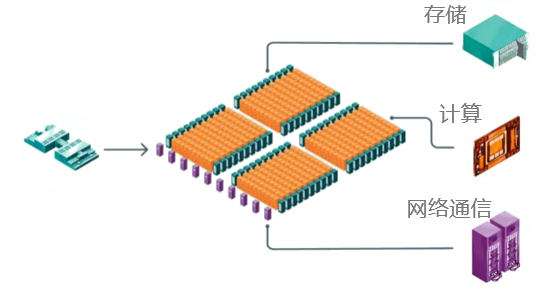
计算集群的组成(来源:互联网)
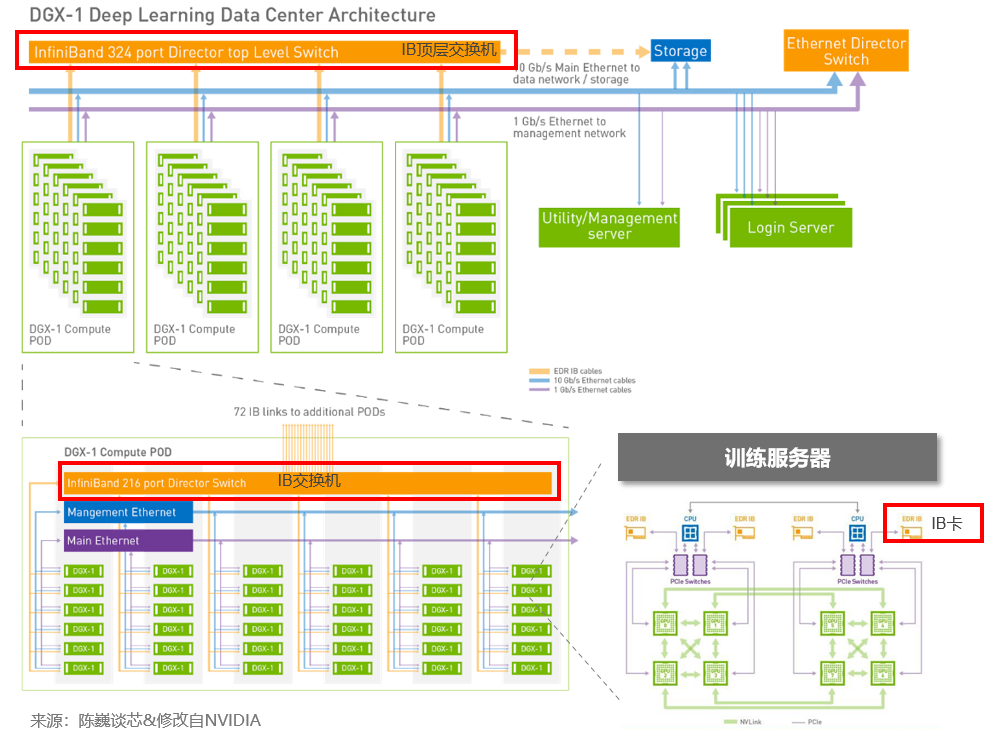
例如下图是基于 128 个 DGX-1 系统的集群架构。128 节点配置使用高速 InfiniBand 和 10Gb/s 以太网网络连接不同 DGX-1 系统以进行计算和存储。集群的网络拓扑结构针对深度学习类型的任务负载进行了架构优化,按层级分为POD内的InfiniBand网络和顶层InfiniBand网络,层之间通过InfiniBand交换机连接。
随着更多计算服务器被添加到集群节点,应用程序线程之间的通信成本会导致训练性能的显著下降。在传统服务器中,AI计算卡之间的通信受到 PCIe 总线带宽的限制,只能以 GPU 内存中数据传输速率的约1% 移动数据。另外,不同服务器上AI计算卡之间的通信更会受到传统数据中心网络带宽的限制(例如10Gb/s 以太网)。
Infiniband的分层结构(来源:NVIDIA)
这其中,影响最大的是服务器间的高速互连。
为了提升互连带宽,计算服务器之间的高速互连通过Infiniband实现。以DGX-1为例,DGX-1服务器在每个服务器系统上配了至少4个 Infiniband互连卡,以在系统之间提供 100 GB/s 或更高的带宽,改善GPT类模型训练的通信带宽进而提升算力的有效利用率。
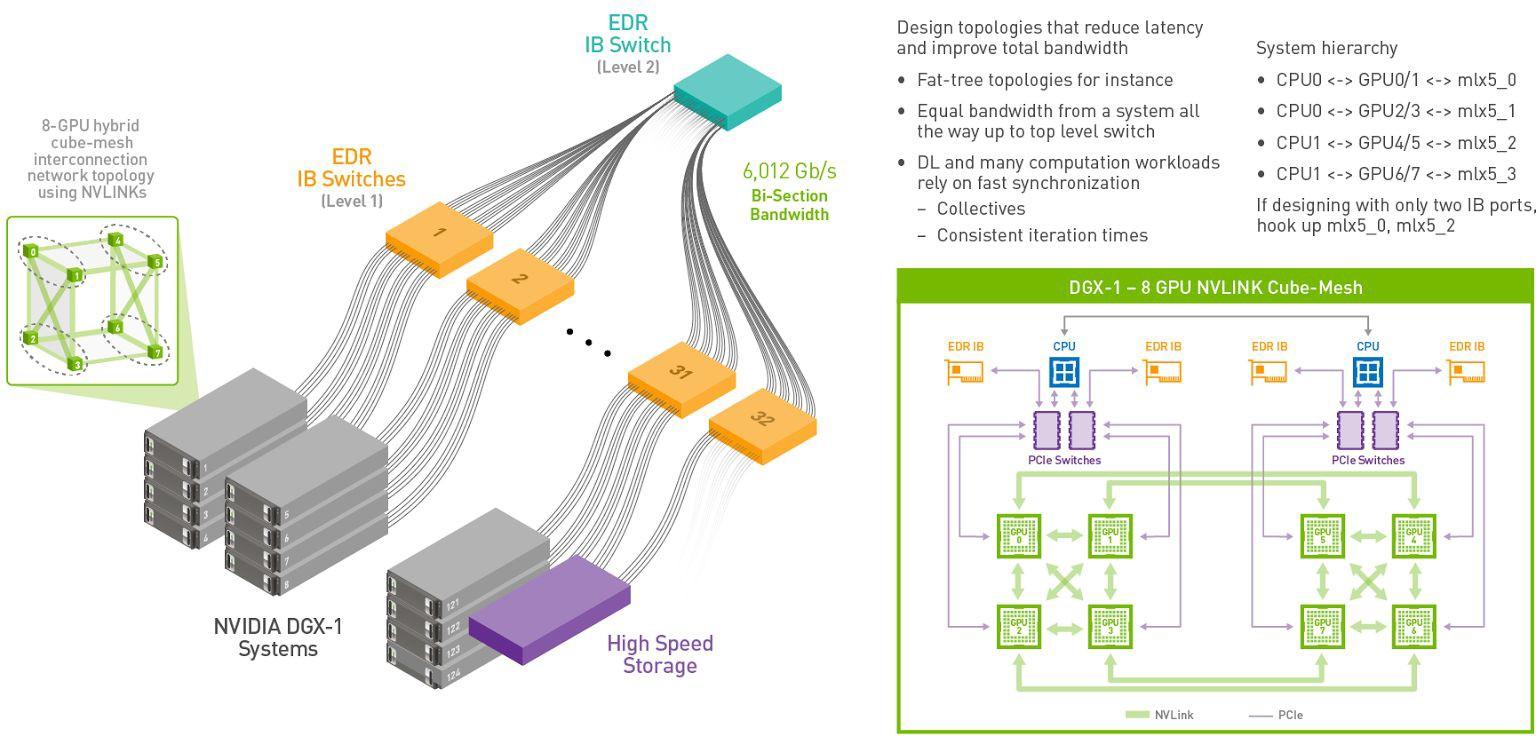
InfiniBand 具有高带宽、低延迟和低 CPU 开销的优势,几乎是HPC 网络中的事实标准,目前是在多节点集群上部署大模型网络的主流服务器间通信方案。为了实现跨集群节点的算力扩展,一般使用两层 InfiniBand 交换架构。两层架构包括一级 InfiniBand 叶(1 级)交换机,每个交换机最多可连接 4 个 DGX 节点,每个节点最多有 4 个 InfiniBand EDR (EDA为100Gb/s带宽,之后有更高带宽的HDR和NDR)连接到InfiniBand交换机。这 16 条链路通过 16 条上行链路完全连接到 InfiniBand 顶级(第2级)交换机(也称为根交换机或主干交换机)。

Infiniband的速率代划分(来源:互联网)
GPT-4等大模型涉及非常大的训练数据集和对应的存储需求。通常来说,典型的HPC程序可分为读密集型、写密集型和读写密集型。GPT-4的数据集和对应存储设备在每个训练Epoch开始时都是读取密集的。与写入密集型的HPC 应用不同,GPT-4等深度学习模型训练中的训练集通常是静态的,涉及大量存储的随机读取和重复访问,相同的数据(主要是高质量数据)可能在训练中多次使用。
在训练时AI计算集群就会遇到训练数据和网络参数共享的存储墙问题。在这里会通过类似存算一体的方式来减少大量训练数据对服务器间通信带宽的消耗。一般是在每个训练任务开始时,将所有的训练数据集复制并缓存到每个 DGX-1 节点的本地存储内(例如SSD),并通过SSD NFS 缓存架构中央集群共享存储的带宽压力。

计算服务器架构对比
针对GPT-4这类大模型的计算架构,按照计算芯片的组合方式,一般可以分为:“CPU+GPGPU”,“CPU+DSA”,和“CPU+DSA+GPGPU”三种类型。这三种类型目前均已在云计算场景广泛应用和部署。
DSA即领域专用加速器,是用于一些特定场景或算法族计算的芯片级加速。最早的GPU也属于DSA,也就是图形加速的DSA。随着GPU逐渐演化,将非常小的CPU核心加入GPU形成GPGPU架构后,才具备了通用化的计算能力。
1)CPU+GPGPU是较早且部署众多的一种。由于这种架构的计算灵活度高,也可用于模型训练和非AI类计算。适合任务种类繁多且差异化大的云计算场景。
2)CPU+DSA是目前Google云计算(GCP)应用较多的方式。例如Google去年发布的Pathways计算系统(包含6144 块 TPU)就是这类架构的典型代表。这类架构计算灵活性稍低一点,但是计算性能和成本都非常明显优于CPU+GPGPU模式,非常用于GPT-4或其他算法部署场景。例如早些年的AlphaGo的性能突破很大程度上来自于Google自研的TPU。当时如果用GPU,估计超过人类棋手的集群成本恐是当年的Google也难以承受的。
除了Google大量使用DSA作为AI计算部署外,微软也在秘密研制其代号为雅典娜的DSA芯片,通过专用芯片的性能优势来降低GPT这类大模型的部署成本。显然Google和微软都更看好DSA在GPT-4等大模型部署的应用。
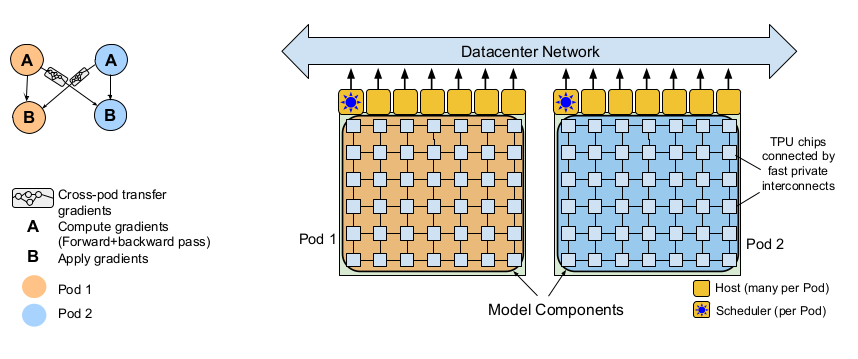
Google Pathways “CPU+DSA”训练集群基础架构(来源:Google)
3)CPU+DSA+GPGPU介于前两者之间,充分提高了灵活性又明显降低了计算成本。这类架构需要算法设计/部署人员有丰富的异构架构部署经验。
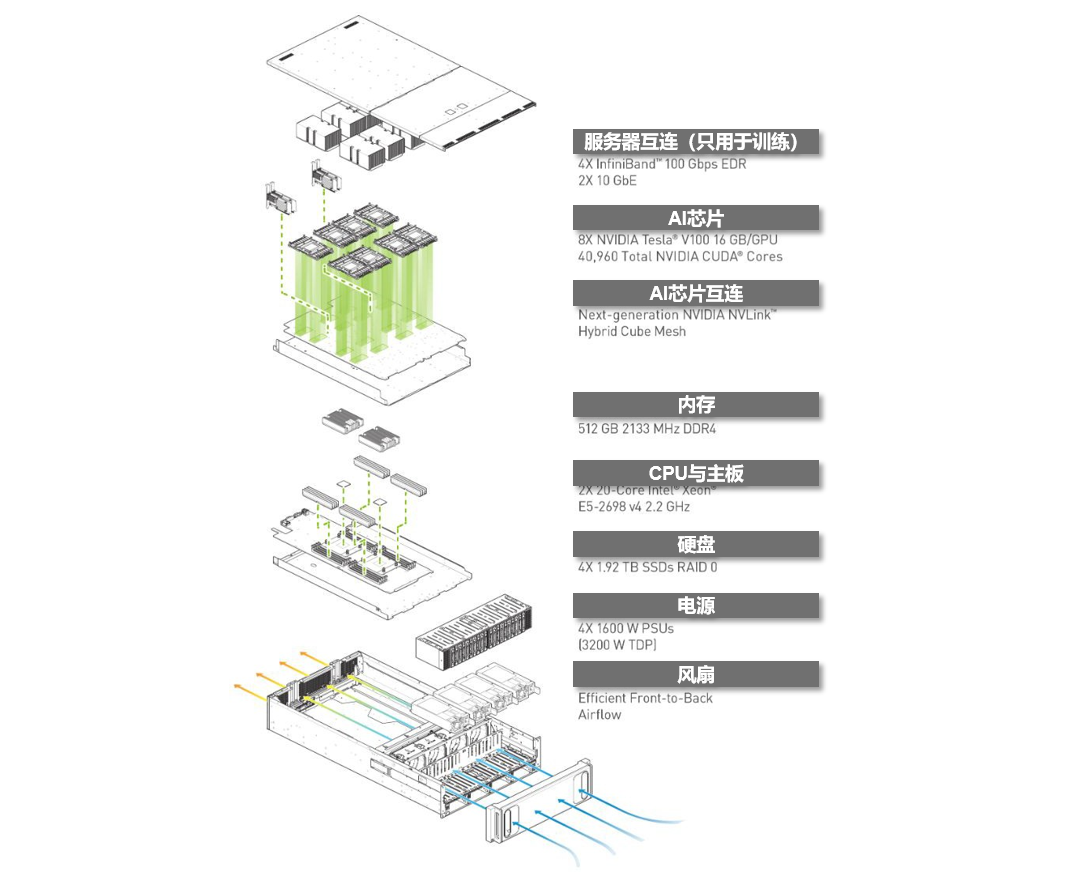
典型的AI服务器物理结构
计算卡间的高速互连对GPT-4计算的影响排在单卡算力之后。对于多数GPU来说,由于一般需要多卡才能放下一个模型,因此整体的计算效率受限于互连带宽和单卡有效算力密度。(算力密度大可以减少互连交互的总数据量)
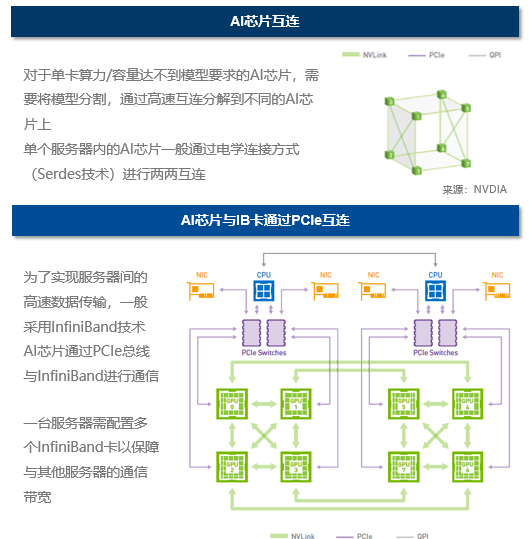
AI服务器内部的卡间互连
以英伟达的集群架构为例,HGX 平台上有六个 NVSwitch。每个 NVLink 连接2块GPU,总共有 12 个最短数据通道直连,形成接近立方体式的数据交互网。这里之所以说接近,是因为0123和4567平面之间的连接还不是两两互连,这一结构会限制GPU所能运行的模型的规模效率。
这其中,NVLink是一种基于有线的串行多通道近距离通信链路,可双向互连,每个方向8个差分对信号线,单方向可提供超过数十Gb/s的数据传输速率。一个设备(芯片)可以由多个 NVLink 组成,并且设备间使用网状网络而不是中央集线器进行通信,支持不同类型设备间的高速通信。NVSwitch则是具备多个接口的NVLink交换机,总带宽可达数TB/s,可有效提升NVLink网络的结构互连能力。
对于GPT-4这类大模型来说,其部署需要大量的大算力计算、存储和数据交互芯片,包括:
- AI计算:算力>100TFLOPS的GPGPU或大算力AI芯片
- CPU:核数>8的CPU
- 存储:内存/GDDR/HBM/NVMe
- 数据交互:Infiniband卡
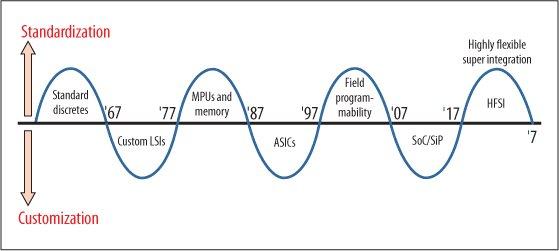
牧本周期(来源:互联网)
根据半导体产业界经典的牧本周期,半导体器件会在标准化和可定制两种相反的趋势中来回震荡,大概每10年调整一次方向。这一周期本质上是开发效率(生态)和性能之间的Trade-off。
在Transformer技术兴起之后,传统CUDA核心的算力支持能力已表现出劣势,英伟达便在其GPU中添加Tensor Core这类DSA单元,以适应算力需求的变化。考虑到GPU这类通用计算架构芯片在计算效率和算力上已经暂时落后于GPT-4/ChatGPT这类大模型的发展速度,从芯片/半导体的历史发展规律看,预计近几年可能会有新的专用架构大发展来填补这一需求。这类新架构也许是针对大模型的DSA,或者是更接近于DSA的GPGPU。
中央处理器(简称CPU)作为计算机系统的运算和控制核心,是信息处理、程序运行的最终执行单元。现代的CPU一般通过多核技术来提升并行处理能力。最新几年新兴的DPU也可以近似为具有网络接口的多核CPU。

RISC-V生态的蓬勃发展(来源:http://riscv.org)
在GPT-4等大模型的计算服务器中,承载操作系统的CPU依然是程序主控的核心,目前来说任何服务器都需要CPU参与。例如在GPGPU服务器中,CPU与GPGPU在服务器上的比例一般是2:8 - 2:16(8卡或16卡服务器)。
目前的CPU主流架构包括x86架构、arm架构和RISC-V架构。x86架构是一种CPU指令集,也叫Intel指令集和IA32指令集,是Intel公司开发的CPU架构标准(Intel/AMD)。arm架构,曾称为先进精简指令集机器(Advanced RISC Machine),是一种arm公司开发的精简指令RISC处理器架构,已开始规模部署在云计算场景。RISC-V是基于精简指令集计算(RISC)原理建立的开放指令集架构(ISA)。特别是近几年,Intel也开始进入RISC-V领域。
CPU与GPU在深度学习计算中的性能差异(来源:Deci.ai)
与很多人想的可能不太一样,在实际的GPT类大模型部署中,CPU也是主要算力之一。一方面,从云计算的经济学模型上看,在GPT-4训练时的CPU的闲余算力可用于模型的(部署)计算或训练,另一方面,CPU可以直接对接数T容量的内存,在一些对计算延迟要求不敏感的场景可能会获得更高的性价比。尽管其计算能效比不如GPGPU,但可充分利用GPU折旧产生计算价值。这是由于云计算按整台服务器收费,在训练时,CPU闲余算力的使用成本接近于0(仅需电费),计算性价比更高。
除了传统的多核架构CPU外,众核架构的CPU也登上了历史舞台,而且可能获得巨大成功。例如特斯拉的Dojo芯片架构,可视为RISC-V CPU整合近存计算DSA的典范。其集群的算力密度超过大部分同工艺的GPGPU集群。
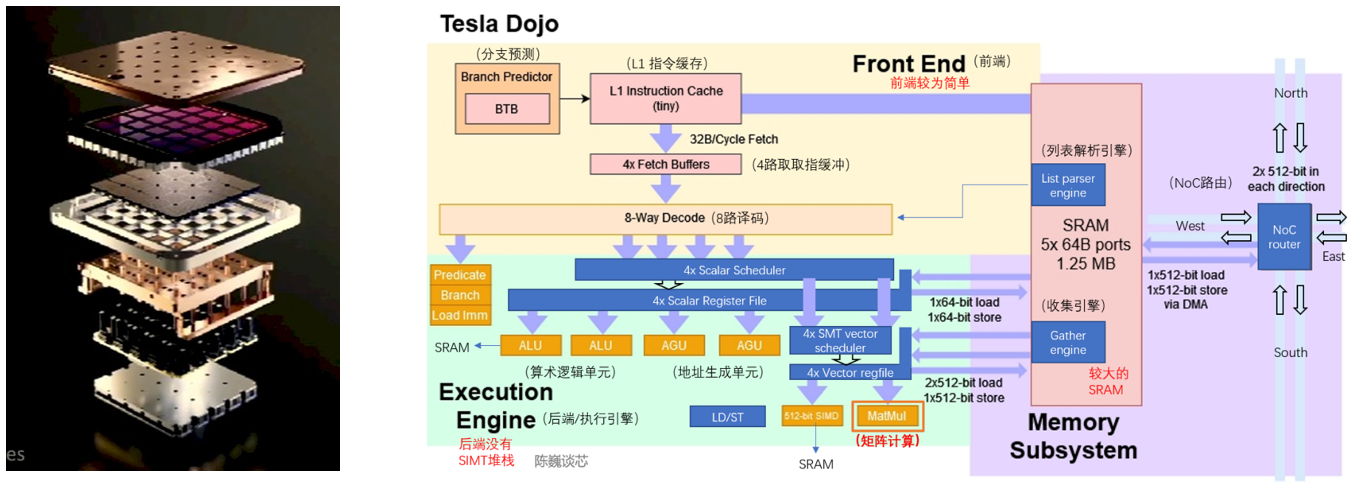
Tesla Dojo芯片架构(陈巍谈芯/修改自Tesla)
通用图形处理器(简称GPGPU),是利用并行图形处理单元来计算原本由中央处理器处理的通用计算任务的处理器。这些通用计算常常与图形处理没有任何关系。在平时使用时,大家常说的GPU的概念范畴事实上包括了GPGPU和传统的GPU。
可以做一个简单的对比:GPGPU算力大侧重于大规模的并行计算;而传统的GPU算力小,更侧重于图形显示(包括3D)加速。
事实上,GPGPU在2012年之前并不是AI计算的主力。在2012年之前,AI计算主要由CPU完成。那时训练一个现在看起来很小的深度学习网络也需要CPU集群,就如同我们现在使用GPGPU集群训练大模型一样,需要使用大量的计算芯片。
但2012年,AlexNet团队将深度学习算法从CPU转换到GPGPU上,获得了更快更高的模型性能,向AI界证明了GPGPU的算力优势。之后CUDA生态也水涨船高,成为主流AI编译生态。
但如果GPGPU只走到这一步就不再进化,估计也无法达到现在的地位。为了巩固自家产品的优势,NVIDIA又在GPGPU中整合近存计算架构和DSA技术。
2016年NVIDIA发布的P100率先在GPGPU中引入HBM,通过近存计算架构(Chiplet方式封装)提升数据吞吐速率。我们在这里就已经可以看到,无论是HBM还是Chiplet,都是为了更好的实现近存计算架构和集成度。
2017年发布的Volta GPGPU架构使用Tensor Core(一种DSA结构)来提升AI计算性能3-12倍。Tensor Core(张量计算核心)是由NVIDIA研发的DSA核心,也是GPGPU算力的主要来源,可实现混合精度的矩阵直接计算,并能根据精度的降低动态调整算力,在保持准确性的同时提高吞吐量。
GPT-3或GPT-4训练对于GPGPU的要求并不低,并不是所有的GPGPU都适合进行大模型训练。根据经验,能进行大模型训练的GPGPU单卡算力应大于100TFLOPS,且具备类似NVLink的高速互连接口,相应的服务器接口生态也必须支持类似InfiniBand技术,并且能支持主流的AI训练框架。从这个角度看,目前能支持到位的AI芯片或GPGPU寥寥无几。
对于部署来说,GPGPU的性能要求只要做到单卡算力>100TFLOPS,支持主流AI框架就差不多,对生态要求明显低于训练场景。需要注意显示型GPU的性价比和单卡算力一般不适合GPT类大模型的计算。
对于国产GPGPU来说,由于面对着NVIDIA、AMD和Intel等芯片巨头的围堵,如果想在GPT-4应用场景获得足够的竞争力,应该考虑以下差异化策略:
1)因大部分采用imagination的IP,应尽可能规避同质化竞争。
2)因缺乏CUDA这样的强有力的训练生态支持,应尽量在算法部署编译上进行优化,或支持开源GPGPU编译生态发展。
3)尽整合先进DSA技术,整合存算一体架构(包括基于HBM的近存计算等)。
4)积累关键专利,避免与NVIDIA或AMD的专利战。
5)结合信创保护伞,绑定垂域客户。
领域专用加速器(简称DSA),是使用专用电路结构进行一些特定场景或算法族(例如AI算法)计算的芯片级加速。GPGPU内的Tensor Core(张量核心)也属于DSA。DSA的计算并行度比传统的GPGPU更高,与之相近的概念是TPU/NPU/ASIC。
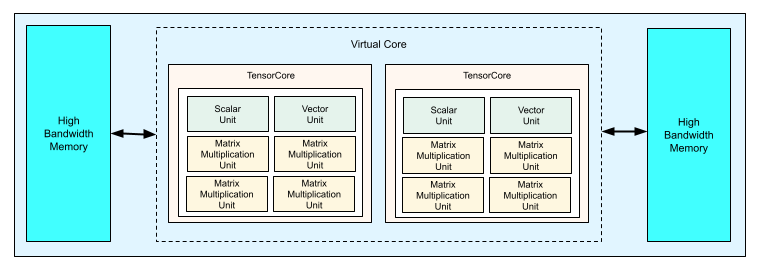
Google TPU的架构(来源:Google)
但实际上用ASIC概念来代表AI专用芯片并不合适,相较之下DSA更适合描述AI领域的加速芯片(或IP核)。传统的ASIC( Application Specific Integrated Circuit )指专用集成电路,包括电视遥控器里的芯片也是ASIC。ASIC的分类一般针对应用场景,比如计算器、电子表、遥控器、家电控制。目前传统ASIC的使用场景已大量被MCU/SoC所代替。
目前DSA的典型代表是Google的TPU。根据Google提供的数据,在Google内部,TPU大概有57%的资源使用在了各类Transformer大模型训练中。相对于同工艺代的A100,TPU大概有50%的能耗降低。这50%的能耗降低事实上意味着大概GPGPU 1⁄2~2/3的硅片面积和更具优势的制造成本,在大规模的模型部署中会具有非常大的成本优势。
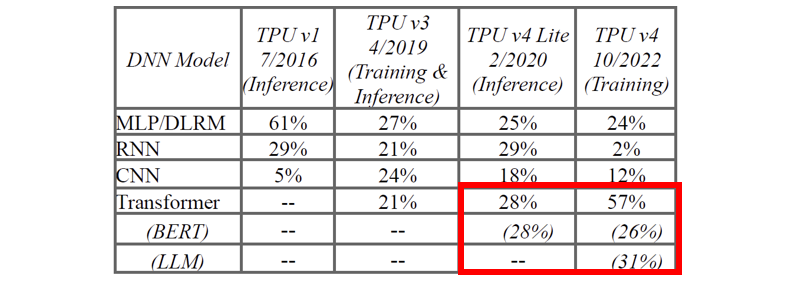
Google TPU 57%的机时用于Transformer类大模型的训练(来源:Google)
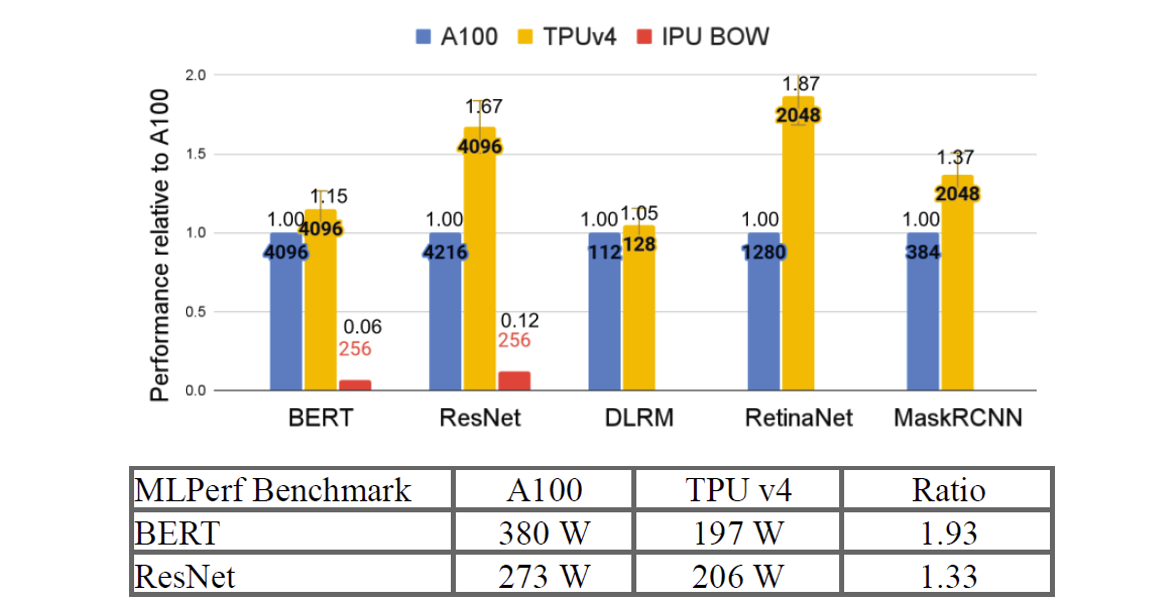
Google TPU表现出同工艺代A100 2倍的功耗优势(来源:Google)
国产AI芯片(DSA)目前面临一定的破局难点,比如大部分生态灵活性不如GPGPU、在技术代上短期难以超过NVIDIA集成的DSA( Tensor Core )。
AI技术的快速发展,使得算力需求呈爆炸式增长。虽然多核(例如CPU)/众核(例如GPU)并行加速技术也能提升算力,但在后摩尔时代,存储带宽制约了计算系统的有效带宽,系统算力增长步履维艰。例如,使用8块1080TI 从头训练BERT模型需99天。
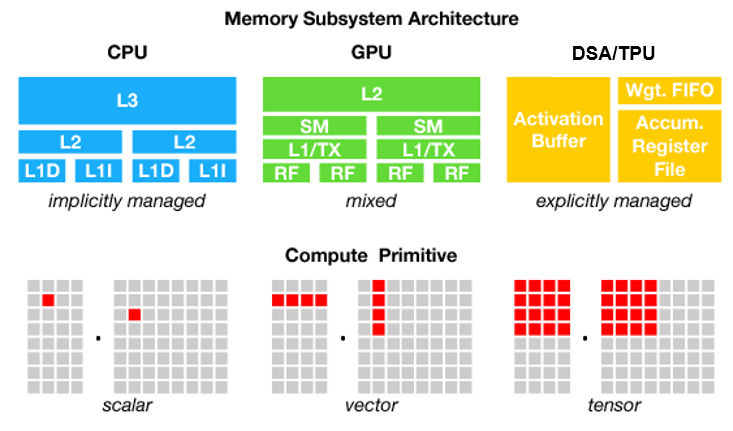
CPU、GPU、DSA的存储层次和计算模式对比(来源:互联网)
扩大芯片面积(包括使用Chiplet技术整合多块计算芯片)虽然能提升算力,但能效制约和性能瓶颈依然存在。
由于传统架构中计算与存储分离,在计算的过程中就需要不断通过总线交换数据,将数据从内存读进CPU,计算完成后再写回存储。这一运转方式让传统冯·诺依曼架构难以适应GPT-4等AI计算的大算力需求的快速增长趋势。
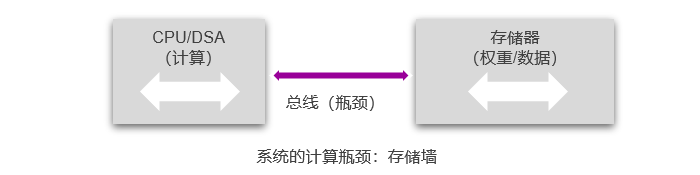
存储墙是现代计算的主要瓶颈
在目前看,存算一体是工艺更新外最有可能提升芯片算力的技术。
存算一体是在存储器内或附近叠加计算能力,以新的高效运算架构进行二维和三维矩阵计算的技术。存算一体具有的优势包括可以实现更大算力(1000TOPS以上)、实现更高能效(超过10-100TOPS/W),从性能和成本优势上超越同工艺代的传统ASIC算力芯片。存算一体具有典型的降本增效优势(可超过一个数量级),可减少数据搬运(降低能耗至1/10~1/100)。
在存算一体电路结构中,存储单元可具备一定计算能力(等效于在面积不变的情况下规模化增加计算核心数,或者等效于提升工艺代),存储单元整合一定的计算能力,具有面积更小带宽更大的结构特点。随着存算一体技术的进步,通过新的存内计算和存内逻辑,已经可以完成32位以上的任意高精度计算,普遍适用于从端到云的各类计算需求。

CPU、GPU和存算一体DSA芯片的架构对比
从目前GPT-4的部署需求来看,GPT-4大模型具有数据量大、数据带宽要求高、算力要求高的计算特点,且算法相对单一。如果要提高计算效率和性价比,就应该像超算那样选择更高计算密度的算力芯片。从这个角度上看,具备存算一体结构的DSA可以很好的满足这些要求,并且具备比现有GPGPU更高的计算性能,未来很有可能与CPU或GPU组合,形成GPT-4这类算法的主要部署芯片。
当然,也并不是所有的存算一体技术都适合大算力的计算。例如有些存算一体技术目前做不到大算力,还有些存算一体技术还未解决噪声和温漂问题。使用者在选择存算一体芯片时应根据算法和算力的需求选择更合适更先进的存算一体计算芯片产品。
从算力来说,DSA(存内逻辑)> GPGPU(DSA/Tensor Core+近存架构)> 常规DSA ≥ 常规GPGPU > CPU。
从训练或计算灵活性来说,CPU > 常规GPGPU > GPGPU(DSA/Tensor Core+近存架构) > 常规DSA ≥ DSA(存内逻辑)。
从目前ChatGPT与GPT-4的算力需求来看,由于高度灵活的生态,GPGPU很可能仍然在近期统治大模型训练市场,而在部署方面,基于存算一体技术的DSA则具备非常明显的成本和性能优势,有望挤占大模型部署的市场;而常规的DSA由于性能上不一定能超过带有DSA核心的GPGPU,除了成本优势外,不一定能直接代替GPGPU在模型部署领域的地位。
HBM(High Bandwidth Memory )是通过三维结构与计算裸片堆叠在一起的大容量高位宽DRAM阵列,主要用作GPU或CPU封装内部的高速内存。

HDM结构示意(来源:AMD)
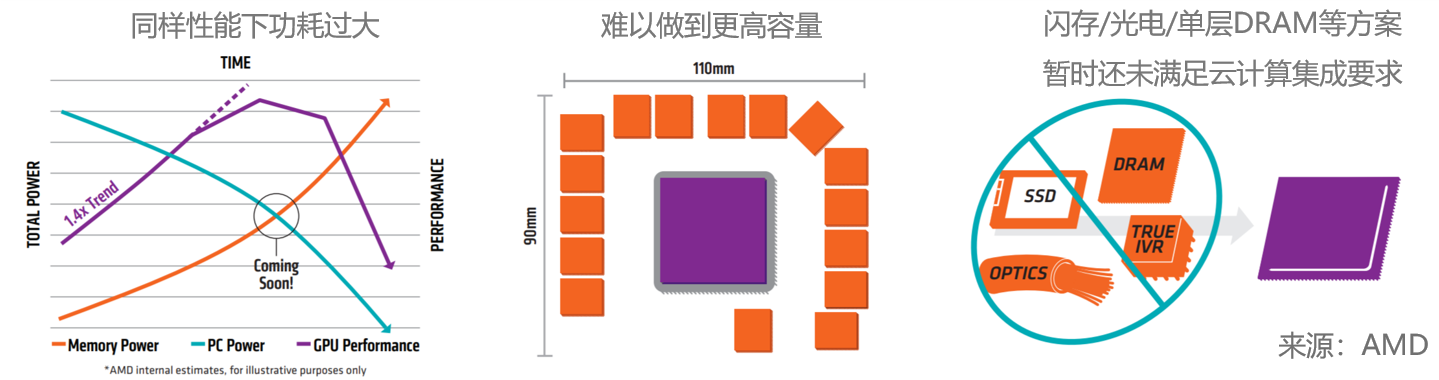
传统DRAM和闪存技术在大算力应用中的不足
HBM一般通过Chiplet技术与GPU或CPU进行整合。绝大部分的Chiplet技术也用于HBM。HBM是近存计算架构的典型代表。通过增加带宽,扩展内存容量,让更大的模型,更多的参数驻留在离计算核心更近的地方,从而减少参数/数据存储带来的延迟。
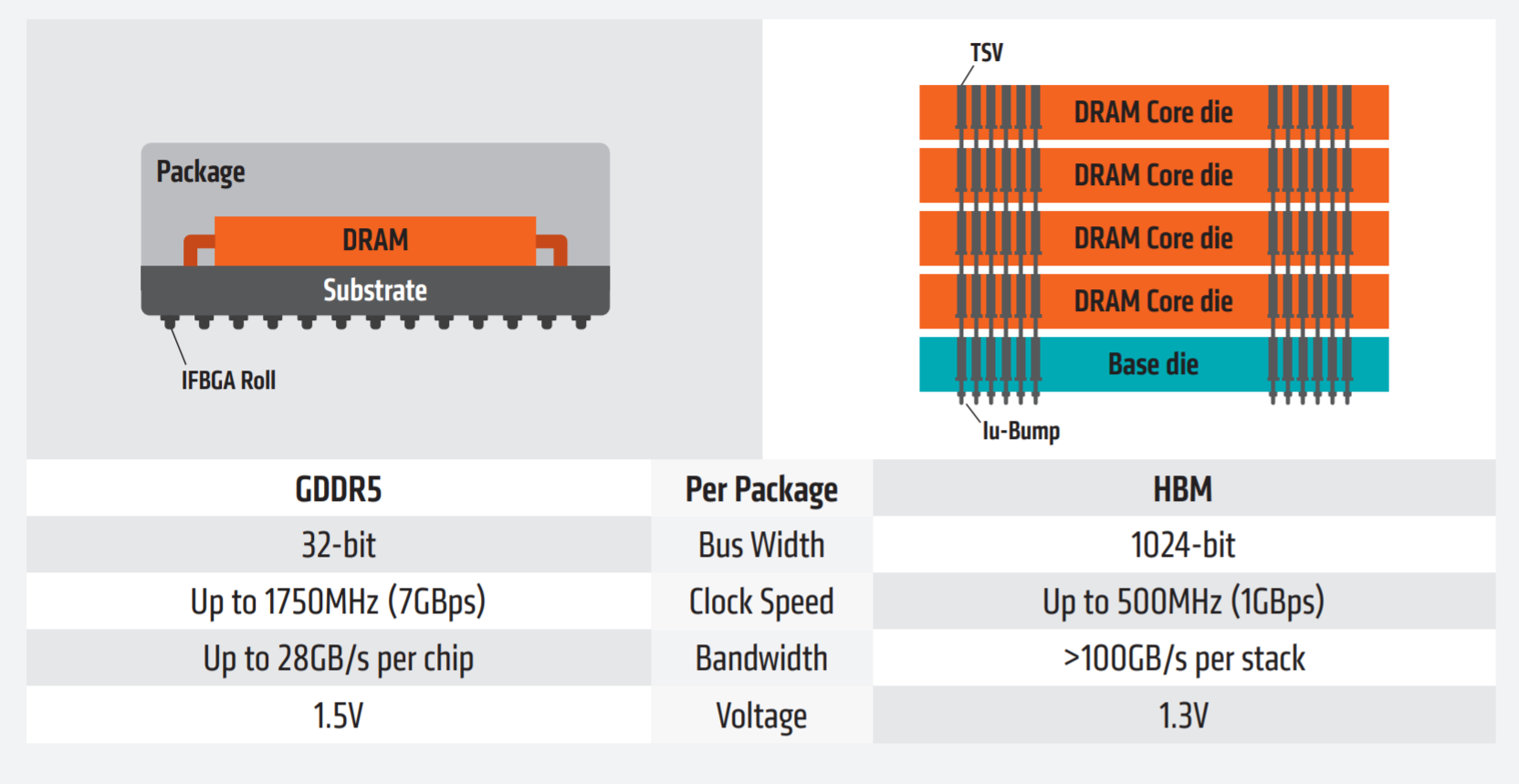
GDDR技术与HBM技术的结构对比(来源:AMD)
Infiniband技术对于大模型的训练至关重要。Infiniband技术的关键在于摒弃了传统网络和应用程序之间消息传递的多层复杂结构,使应用程序之间直接进行通信,绕过了操作系统延迟,大大提高了效率。
而Infiniband所基于的OpenFabrics Enterprise Distribution (OFED )是一组开源软件驱动、内核代码、中间件和支持InfiniBand Fabric的用户级接口程序。开放和高性能使得Infiniband成为集群数据交互的事实标准。
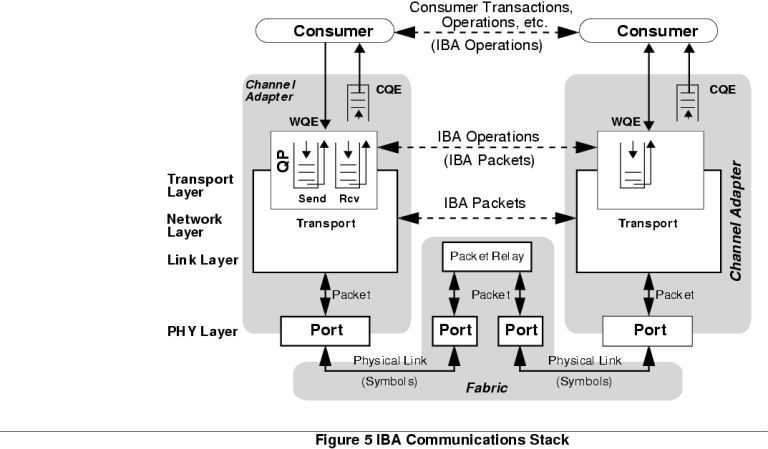
IB的通信堆栈
对NVIDIA的GPGPU来说,A100或H100可以直接访问服务器 Infiniband 结构,通过Infiniband提升服务器间的数据交互带宽,而大带宽的Infiniband一般通过光纤连接(使用SerDes技术)来减少损耗。Infiniband 网络基于“以应用程序为中心 ”的观点,目标是让应用程序访问其他应用程序以及存储尽可能的简单、高效和直接,避免网络分层带来的延迟。这种结构大大提高了GPT-4训练的速度。
Infiniband 基于易于使用的消息服务,该服务可以被用来与其他应用程序、进程或者存储进行通信 。应用程序不再向操作系统提交访问其他资源的申请,而是直接使用 Infiniband 消息服务。
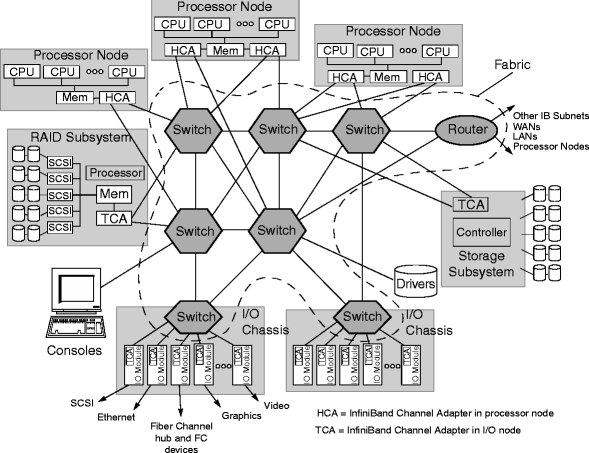
IB的网络结构(来源:互联网)
在GPT-4这类大模型训练和微调中,一般需要使用Infiniband这类服务器互连技术进行大算力芯片间的协同工作,整合海量芯片的算力。
[1] Narayanan D , Shoeybi M , Casper J , et al. Efficient Large-Scale Language Model Training on GPU Clusters[J]. 2021.
[2] Patterson D , Gonzalez J , Le Q , et al. Carbon Emissions and Large Neural Network Training[J]. 2021.
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/211021.html