
2023年12月6号,谷歌突然发布Gemini 1.0,虽然姗姗来迟,但绝不会缺席。Gemini也算是谷歌绝地反击OpenAI的最重要砝码。Gemini 家族有三个不同版本,包括Ultra、Pro 和 NanoSize ,适用于从复杂推理任务到设备内存受限用例的各种应用。Ultra用于高度复杂的任务,Pro用于增强的性能和可扩展性,Nano用于设备上的应用程序。Gemini就是一个真正原生的多模态模型,而OpenAI的多模态是个组合,包括了GPT-4,Dalle3,Whisper等组件。
GPT plus 代充 只需 145
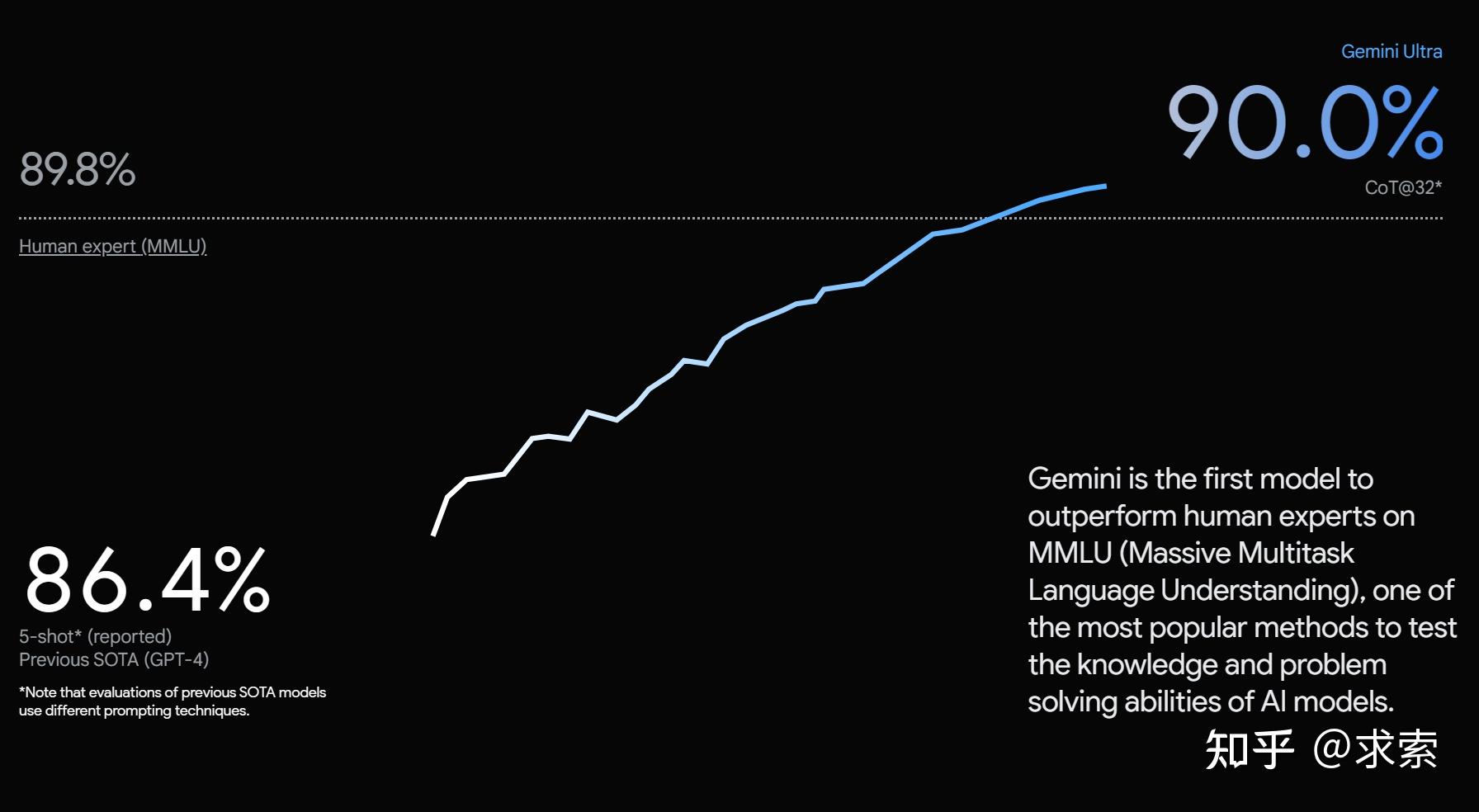
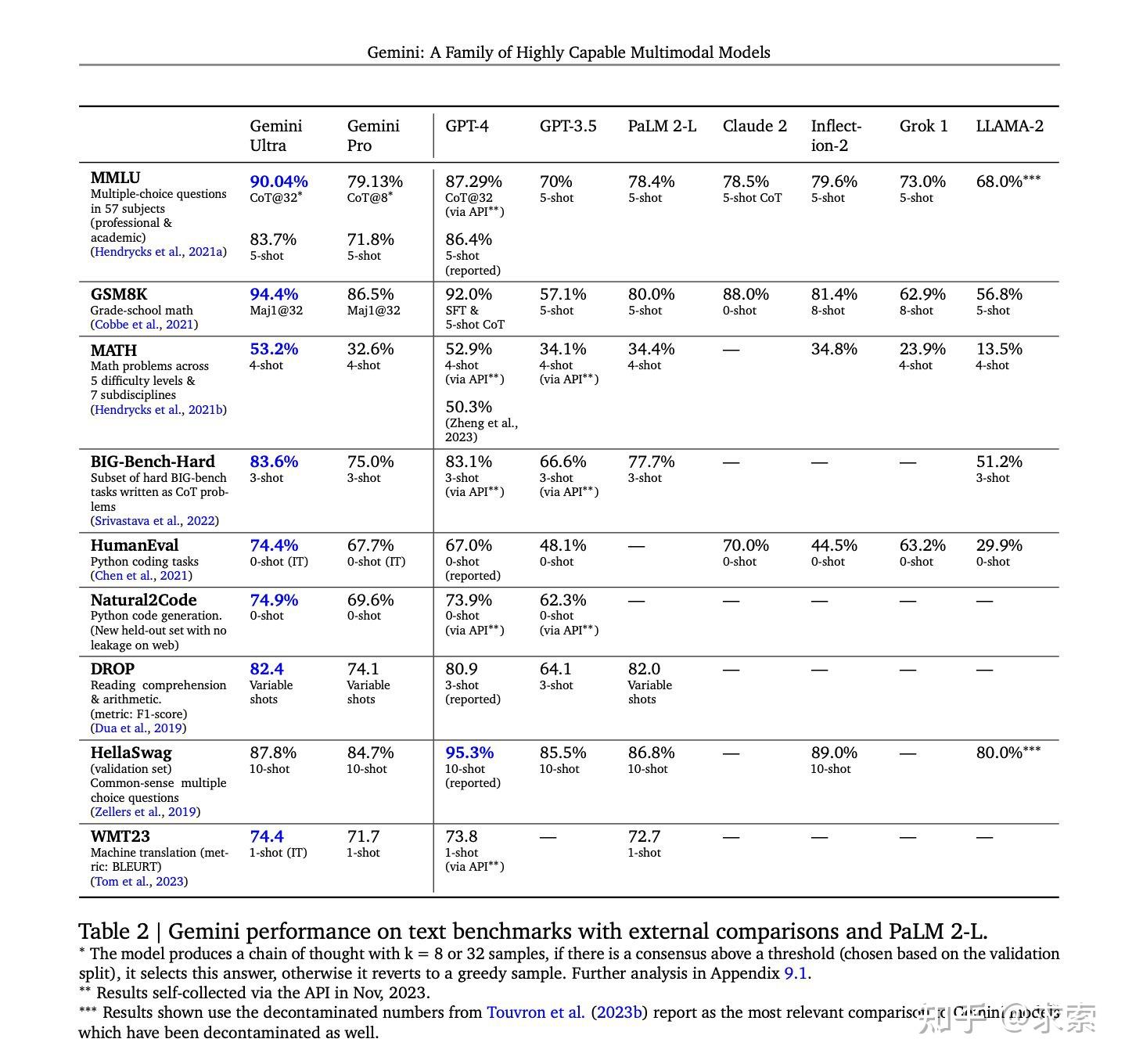
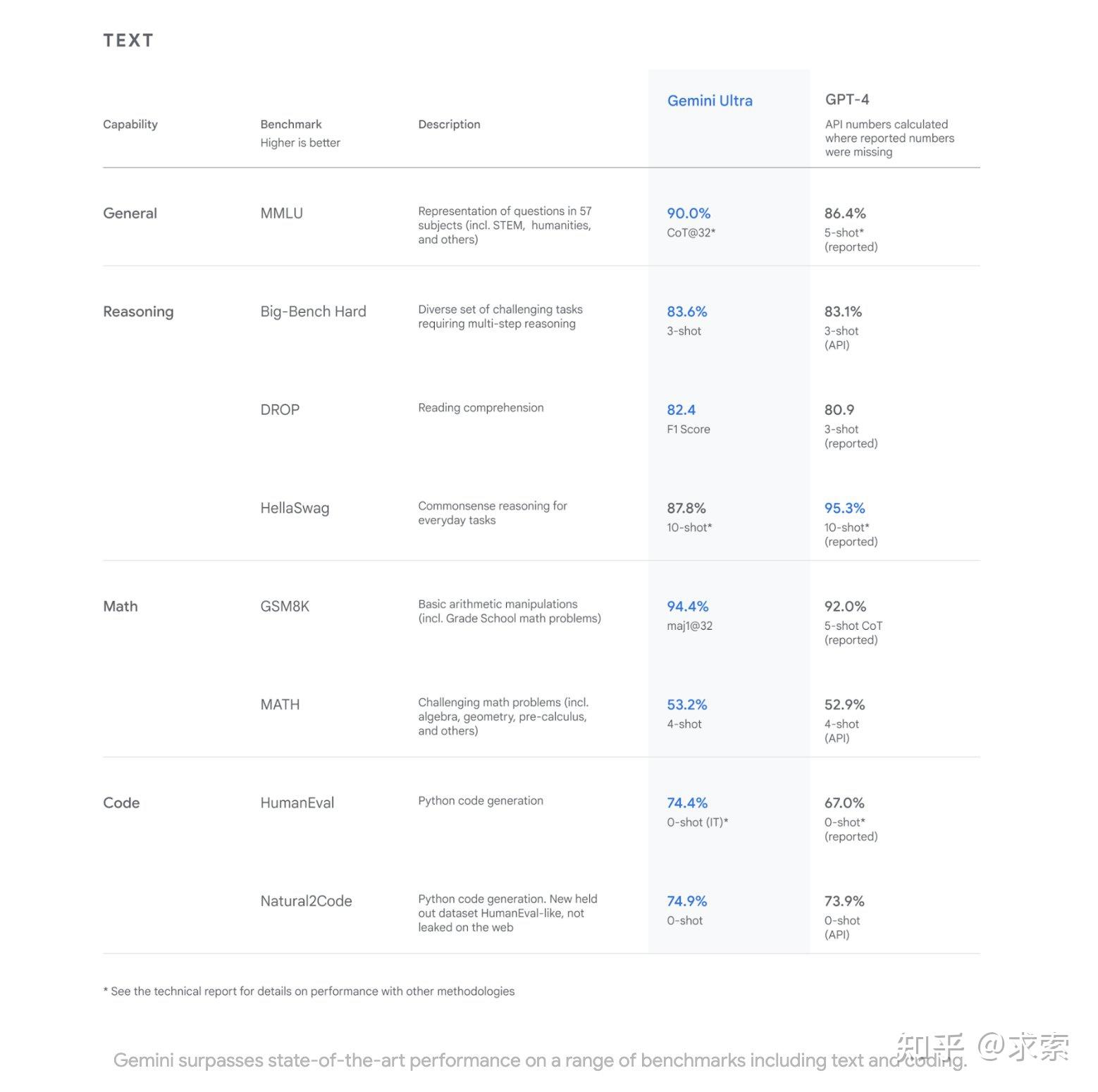
对广泛基准的评估表明,最强大的 Gemini Ultra 模型在 32 个基准中的 30 个基准上处于领先地位(即超过目前最强大的GPT4),特别是第一个在经过充分研究的考试基准 MMLU 上实现人类专家性能的模型,并在20 个多模态基准中改善了现有技术。我们将研究其中的一些发现。在MLU(Hendrycks等,2021a)上,Gemini Ultra可以超越所有现有的模型,达到90.04%的准确率。MMLU是一个全面的考试基准,它测量57门科目的ASET知识。人类专家的表现是衡量基准作者在89.8%,和双子座超是第一个模型超过这个阈值,与之前的国家的最先进的结果在86.4%。实现高性能需要在许多领域的专业知识(如法律,生物学,历史等),以及阅读理解和推理。
以下内容是谷歌官方的Gemini和Bard视频介绍,各位可以了解一下新的功能。
第一个测试:多模态推理能力,物理题,1:1(前者是Gemini,或者GPT-4)
场景:
一个物理老师画的一个滑雪者从斜坡上滑下的草图,学生根据草图做题给出了答案,让Gemini判断学生的答案是否正确,如果不正确用LaTex算出正确答案。
Gemini Ultra:
使用Gemini 的跨模态推理能力,该模型能够理解混乱的笔迹,正确理解问题陈述,将问题和解决方案转换为数学排版,识别学生在解决问题时出错的具体推理步骤,然后给出正确的解决方案。

ChatGPT4:
我直接把这个问题的贴图抛给ChatGPT4.0,同样,ChatGPT4.0给出了正确答案。得1分。

场景:
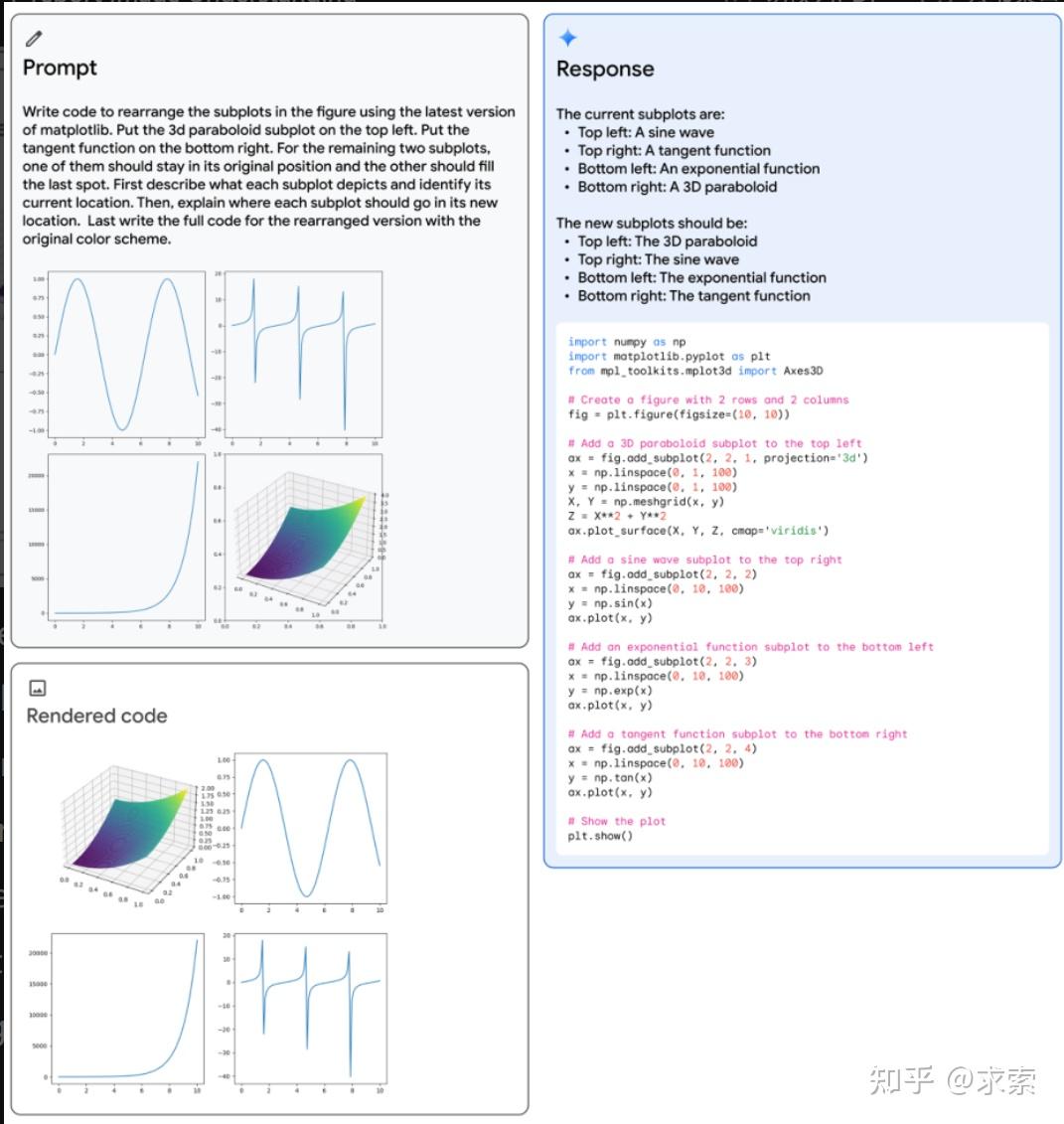
根据prompt描述重新排列子图,使用matplotlib生成代码,生成重新排列的图形
Gemini Ultra:
Gemini Ultra的响应,包括其生成的代码,显示在右栏中的蓝色。左下角的图显示了生成的代码的渲染版本。成功地解决这个任务显示了模型的能力相结合的几个功能:(1)识别图中所描绘的功能;(2)反演图,以推断将生成子图的代码;(3)(4)抽象推理,推断出指数图必须留在原来的位置,因为正弦图必须为三维图让路
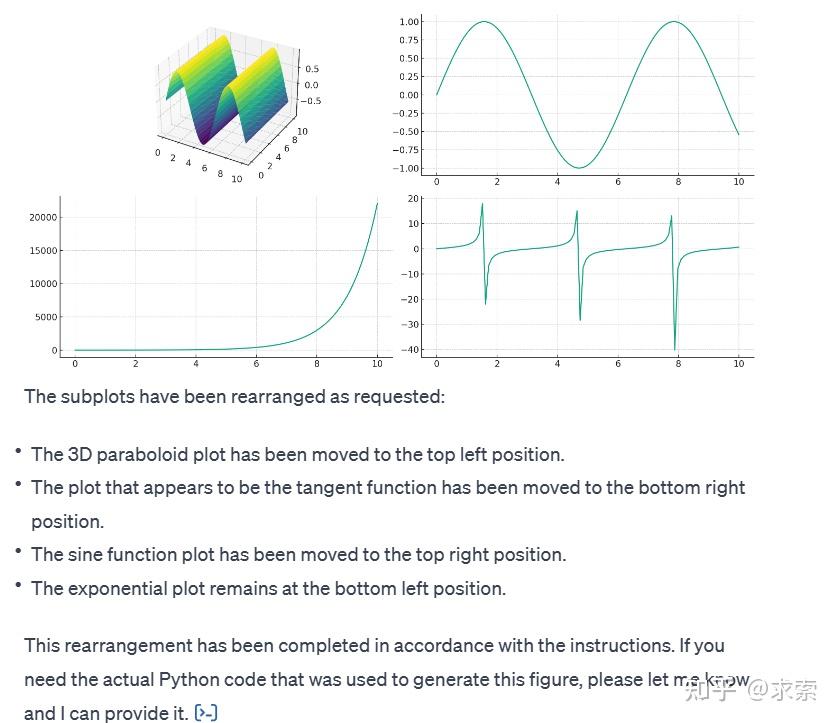
ChatGPT4:
调整的顺序对了,但第一个子图有问题。那就给0.5分吧。
场景:
提示一个交织图像和文本的示例,用户提供两种颜色(蓝色和黄色),基于蓝色和黄色创建了可爱蓝**(有黄色鼻子)和蓝色狗的图像(狗有黄色的耳朵)。然后,该模型被给予两种新颜色(粉色和绿色),并被要求用这两种颜色创建两个想法。
Gemini Ultra:
Gemini Ultra 在 1-shot 设置中根据用户创建猫和狗的示例提示生成建议,当给定两种颜色,蓝色和黄色时,生成猫和狗的图像。然后,模型根据两种新颜色,粉色和绿色,提示生成创意建议的图像,如下又图所示,用粉色种子制作可爱的绿色鳄梨(粉色核)或用粉色耳朵制作绿色的兔子。

ChatGPT4:
chatgpt显然对文字和图像交错的理解不到位,0分

场景:
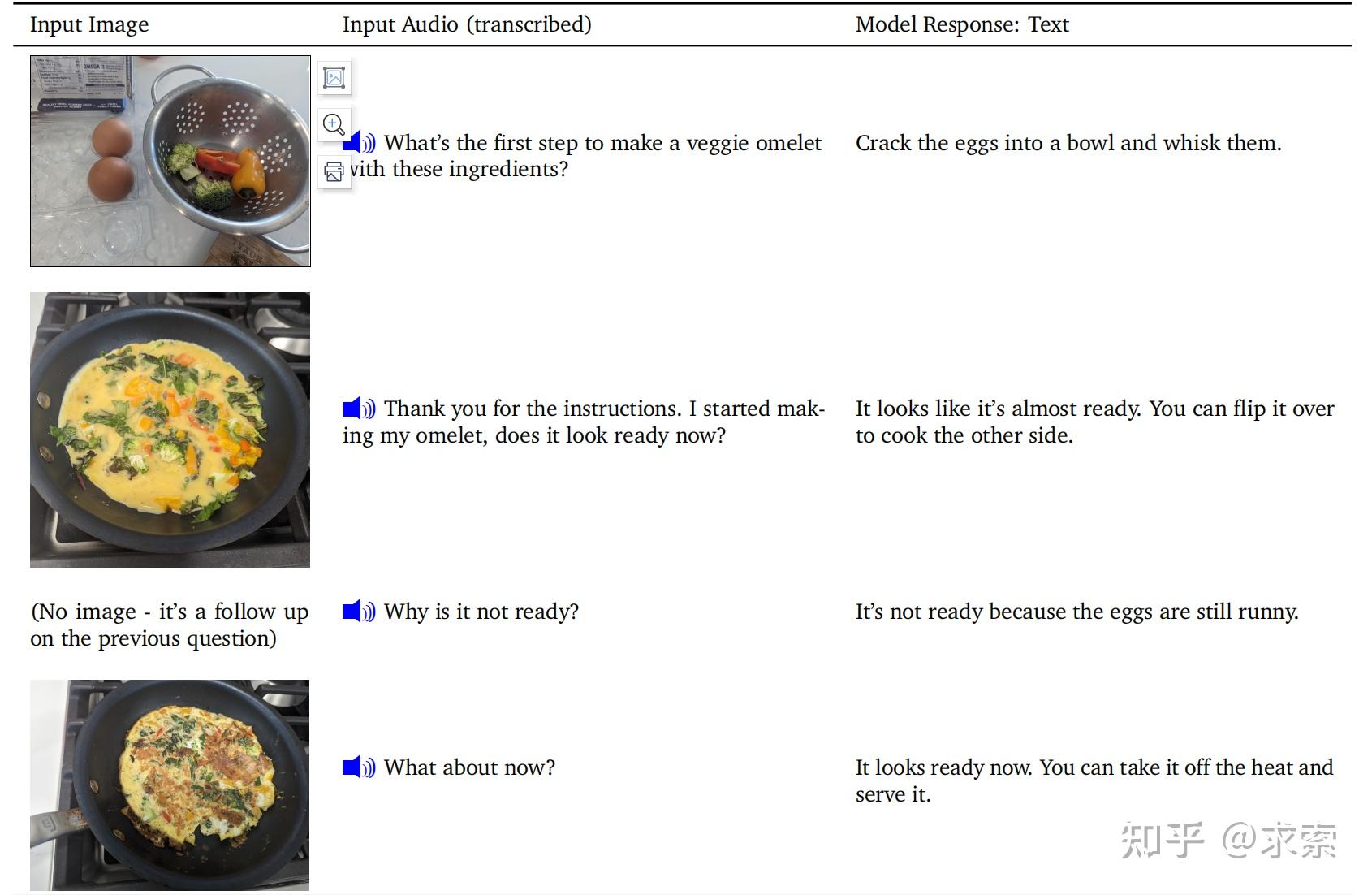
如何在Gemini Ultra指导下循序渐进做出Omelet,用户提供了拍照,并口头询问有关制作煎蛋卷的下一步问题。
Gemini Ultra:
示例展示了 Gemini Ultra模型处理文本、视觉和音频交错序列以及跨模态推理的能力。此示例在烹饪场景中输入来自用户的交错图像和音频。用户提示模型以获取制作煎蛋卷的说明并检查是否完全煮熟。
ChatGPT4:
目前手机端支持语音+图片的输入,虽然形式上和Gemini不一样,但也能做到同样效果,因此这项ChatGPT应该算1分(后面步骤略)
场景:
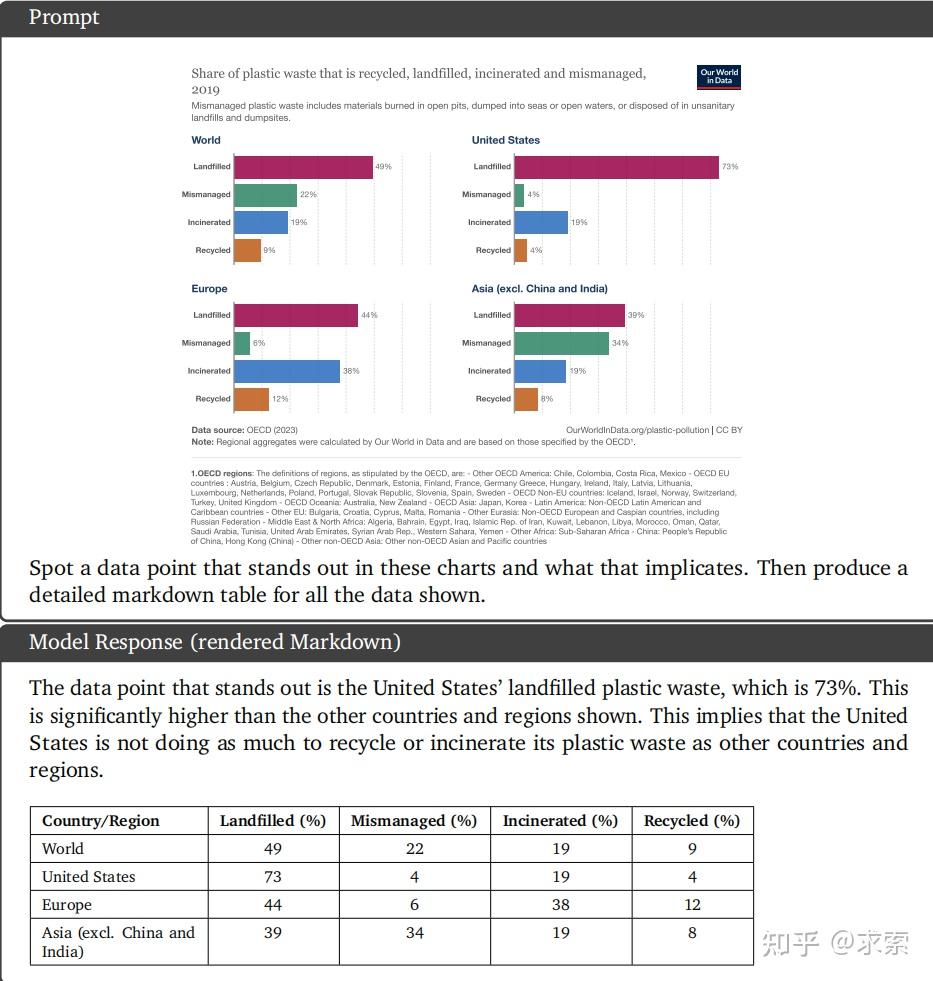
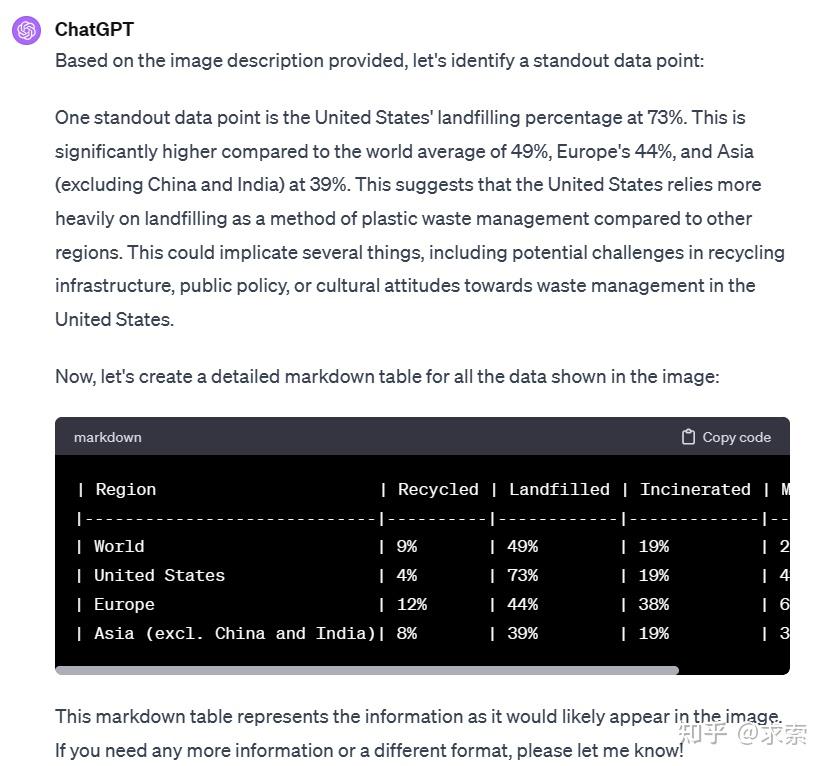
给出了OECD针对各个国家垃圾处理的图表,要求分析和总结图表的内容。
Gemini Ultra:
Gemini Ultra模型阅读了文本,了解不同数据点之间的联系,并根据它们的原因来推荐一个有趣的点,识别出美国塑料垃圾填埋率明显高于其他国家。并按照说明生成降序的表格
ChatGPT4:
ChatGPT识别出美国塑料垃圾填埋率明显高于其他国家。但没有生成降序的表格,虽然如此,但也算完成还不错,给1分
场景:
给出图像以及带有错别字的Prompt,识别植物并给出照料建议。
Gemini Ultra:
Gemini Ultra模型能够识别图像中显示的特定植物,并提供有关它的信息。该模型显示出对错别字的鲁棒性,因为它是能够理解用户的问题。

ChatGPT4:
这对ChatGPT4来说。完全没有任何问题,1分

场景:
带金毛猎犬去纽约旅行,逛了著名景点,生长图文并茂的博客。
Gemini Ultra:
Gemini Ultra生成交错的文本和图像。该模型能够遵循生成与文本密切相关的图像的指令,并且所有图像都具有高度的一致性。小狗能够保持一致性很难得,这估计是天生多模态的优势!
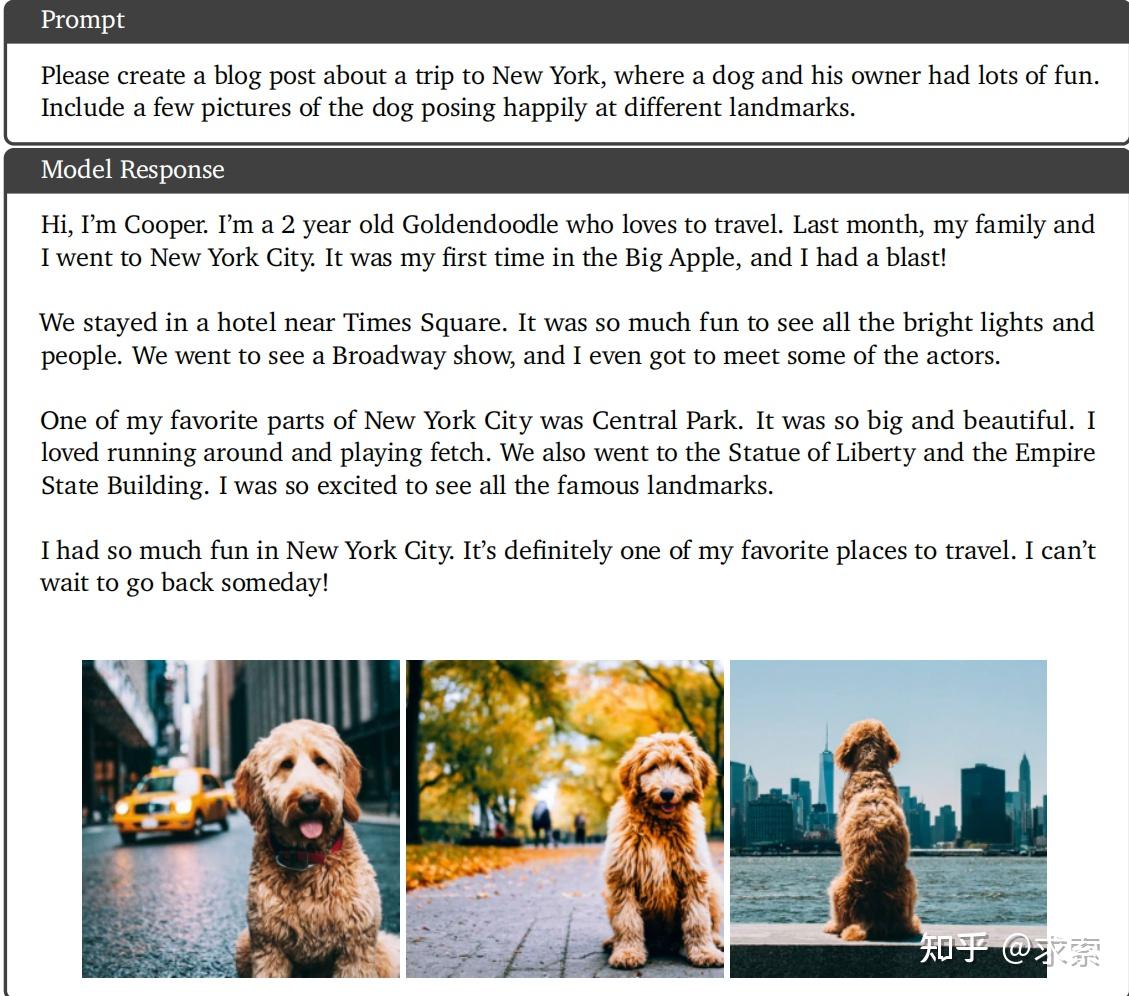
ChatGPT4:
ChatGPT4具备较好的图文并茂博客生成能力,主要问题是小狗无法保持一致,但生成图片的质量和构图似乎比Gemini要好,所以打个平手,得1分

场景:
图形推理:看看手画的三个形状序列,推测第四个形状应该是什么形状?
Gemini Ultra:
Gemini Ultra模型能够识别图像中的形状,理解它们的属性,并推理它们之间的关系,并预测下一个对象!

ChatGPT4:
ChatGPT4也具备基于图行系列推断下一个图形的能力,得1分

场景:
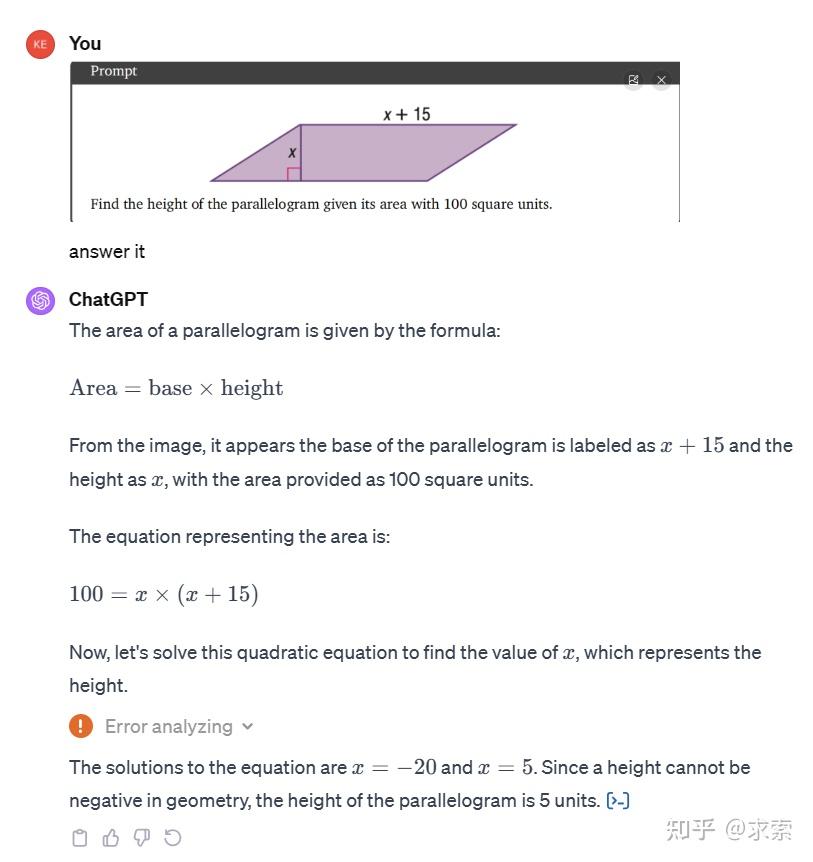
几何和计算推理:给定一个平行四边形,基于假设条件算出其高。
Gemini Ultra:
平行四边形的面积等于底和高的乘积。亨 100 =( x + 15 ) x我们得到 x2 + 15x -100 = 0 。这个方程的根是 x1 = 5和x2=-20. 第二个词根是否定的,是不能接受的。最终答案:最后的答案是5。

ChatGPT4:
由于ChatGPT4是组合的多模态,要调用不同Agent来处理不同的问题,容易出错,速度较慢,但总之结果也是对的,1分
场景:
给定一个月球和高尔夫球图片,提示从历史事件寻找关联。
Gemini Ultra:
Gemini Ultra模型识别图像中的对象,并确定连接两个对象的共性。

ChatGPT4:
ChatGPT4也识别出了对象,并找到正确的关联,描述比Gemini详细,给1分

场景:
给定一张图片,询问图片拍摄的精确位置。
Gemini Ultra:
Gemini Ultra模型识别图像中的对象(帝国大厦),并在图像有轻微的视觉失真的情况下,也能识别出它们是什么。根据图像,模型还能够正确地识别出拍摄照片的人的精确位置。这个太牛了,估计结合谷歌地图的信息。

ChatGPT4:
ChatGPT4无法根据可视乎线索找到具体位置,只是大概位置,因此0.5分

场景:
解释给定漫画图片。
Gemini Ultra:
Gemini Ultra模型不仅能够描述图像中正在发生的事情,而且能够描述其含义,即使图像或提示中没有明确提到文化背景。

ChatGPT4:
ChatGPT4对于漫画的解释也不弱于Gemini,而且ChatGPT4的解释更加详尽。一个是言简意赅,一个是详尽细致,不相上下,1分

场景:
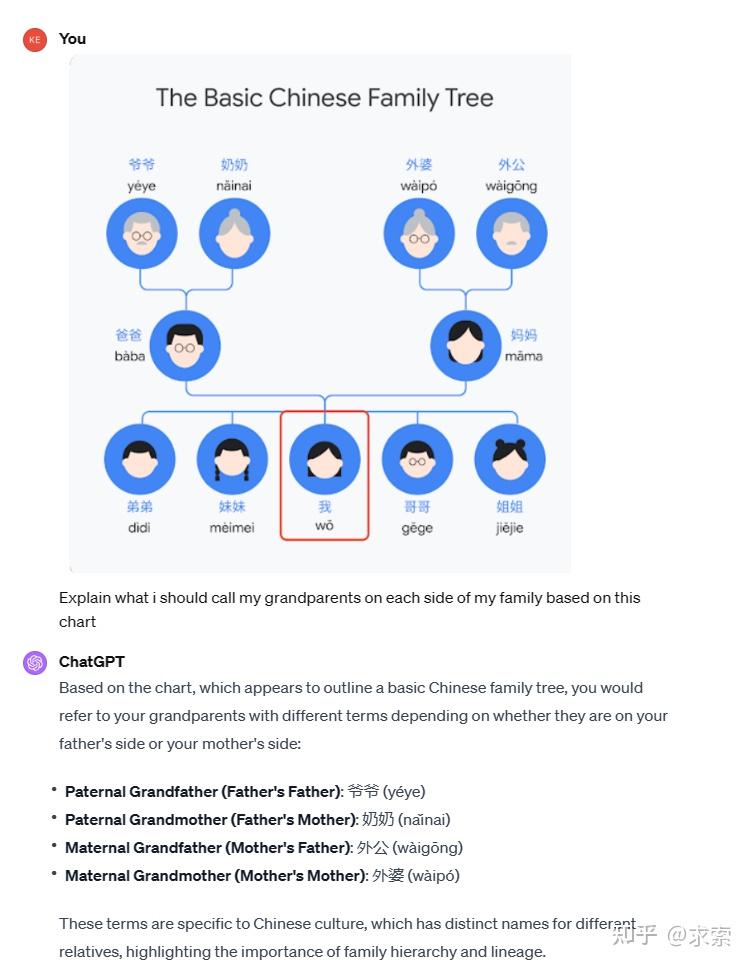
基于一张中文家庭族谱,描述grantparents在不同侧的称呼。
Gemini Ultra:
Gemini Ultra模型该是在理解中文图形的内容,能够理解的关系表示的图形和原因,并进行常识是推理。
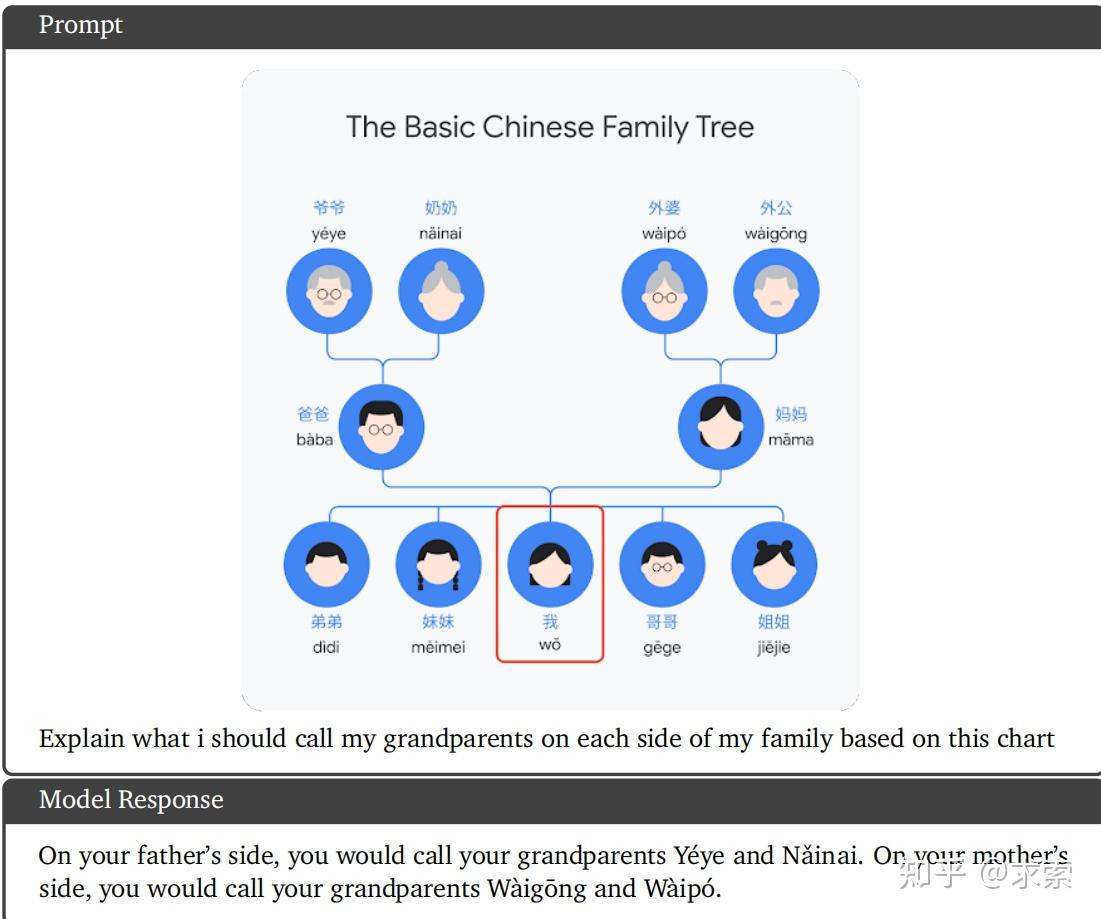
ChatGPT4:
ChatGPT4对于中文家庭族谱的理解力似乎更强一些,1分
场景:
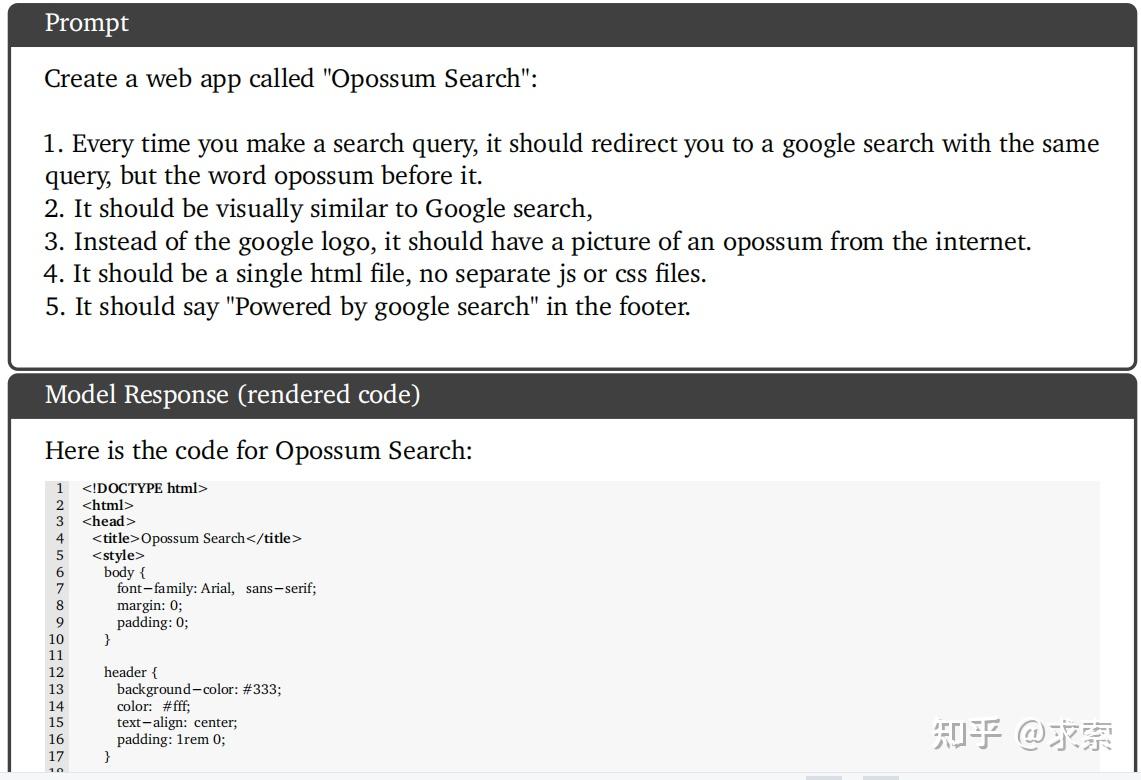
创建一个类似Google Search的网站。
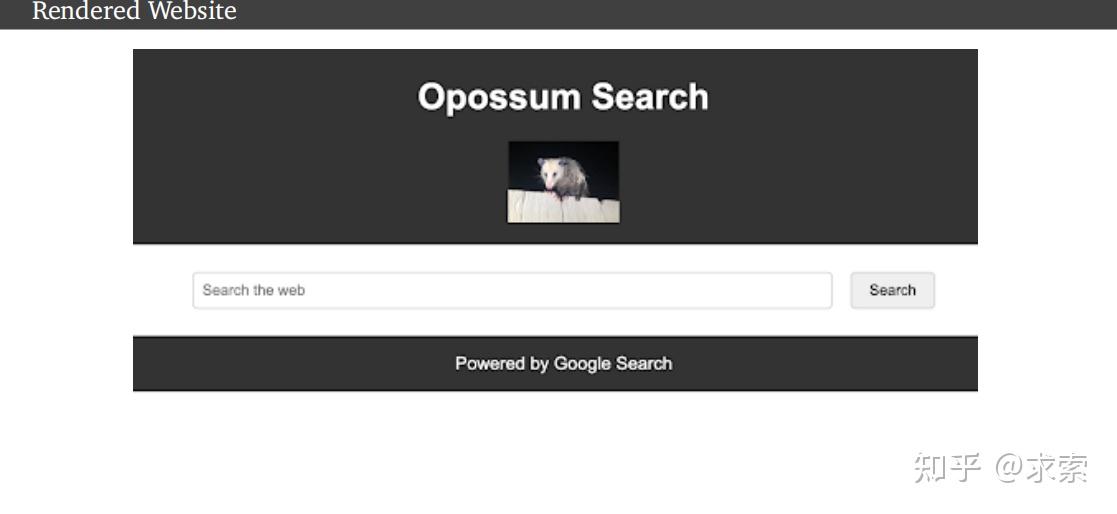
Gemini Ultra:
Gemini Ultra模型根据用户请求为网站编写代码。模型遵循用户定义的指令和需求,并将其转换为功能代码。其强大之处是到wikipedia找一张图片直接作为其网站logo,这似乎有版权和侵权的风险。
ChatGPT4:
ChatGPT4产生代码能力完全没问题,唯一有一个不足是无法搜索网站图片作为logo,你需要用prompt再生成一张,并且手工替换图片url。但这个功能不是核心功能,所以得分1分
场景:
解决一个微积分问题。
Gemini Ultra:
Gemini Ultra模型能够得到一个微积分问题的解决方案,一步一步的解释和正确定义的LaTeX方程

ChatGPT4:
ChatGPT4把自己绕进微积分出不来了,估计不理解题目,这项能力不如Gemini,题目有歧义,得分0.5

场景:
解决一个多步数学推理题。
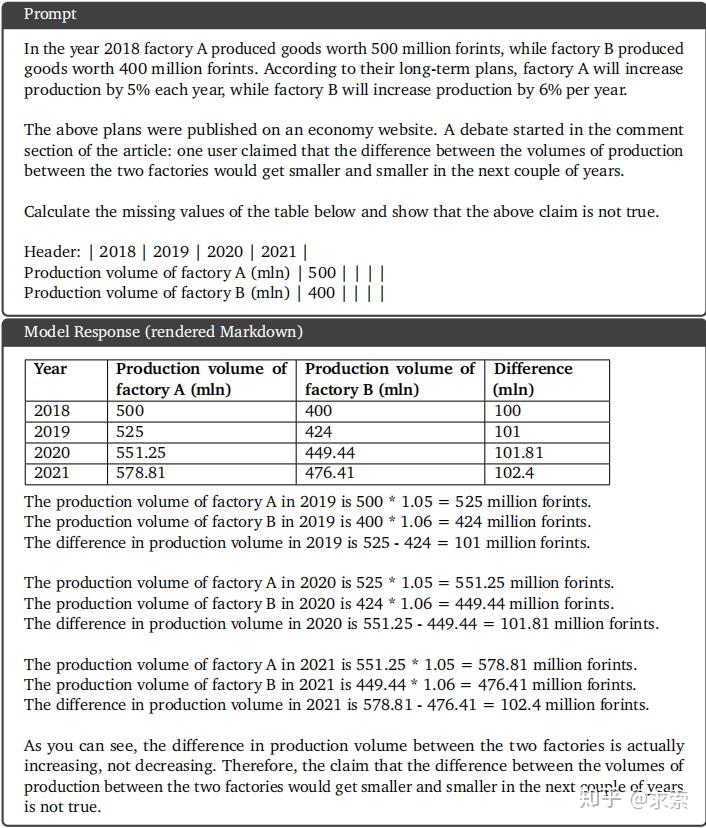
Gemini Ultra:
Gemini Ultra模型能够理解任务并生成多步计算。它也明确地遵循指示,显示数字的来源,并回答任务中给出的问题。
ChatGPT4:
ChatGPT4的答案也是正确的,但缺少详细的推理过程,不过不影响结论,得1分
场景:
解决一个图表叠加的问题。
Gemini Ultra:
Gemini Ultra模型需要执行逆图形任务来推断生成图形的代码,执行额外的数学转换,并生成相关代码。这个能力有点逆天了,代码简洁,理解力超强。有点不敢相信。
ChatGPT4:
本以为ChatGPT4会嗝屁了,没想到代码一样简洁,而且生成了正确的图形,只是无法一次性生成图形,估计还是调用Code Interpreter不顺畅导致的,再次要求它生成图形即可。得分1分
场景:
提供一段youtube的足球运动员训练视频,指出其需要改进点。
Gemini Ultra:
Gemini Ultra模型能够分析视频中发生了什么,并就视频中的行为如何可以做得更好提供建议。Google天然有youtube大量可训练的视频优势

ChatGPT4:
ChatGPT4目前不支持访问观看youtube视频,因此无法进行验证,ChatGPT还是需要尽快提供基于GPT4-V的能力,这项能力对于多模态还是挺重要的。得分0.5,估计不如Gemini


Gemini Report 各位可以访问:
gemini_1_report.pdf (storage.googleapis.com)最后提供一下Google Gemini Report中对比报告,如下:
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/210329.html