
作为一个程序猿,我很清楚chatgpt的用处,但对于它在其他领域的用处却不了解,十分好奇你对它的用处
第一重是压根没有听说过ChatGPT的,这部分人不多,毕竟就连防沉迷系统都过不了的小孩都知道有这么个东西了。
第二重是听说过但是没用过的,这部分应该占绝大多数,就算把各种套壳小程序等都算上,我觉得也没有多少人,因为这东西最直接的印象就是一个空空的对话框,

特别是移动互联网时代,大多数人上网用的是手机,而ChatGPT明显是更适合电脑上的浏览器,所以使用的人就更少了。
最后一重就是听说过,也使用过,我估计看这个回答的人大多数都没有机会去用真正的ChatGPT,这也是为什么「如何注册ChatGPT」「国内ChatGPT」「中文版ChatGPT」这类东西从2023年12月ChatGPT发布开始就一直也没停过。
能成为攻略且一直都有新的攻略,只能证明这个东西有两个特点:
1、有用,在多个领域都有很强的应用价值。不管是写代码、做报表、做汇报、学英语、扒文献等等,所以有需求、有受众。
2、 难用,这个「难用」是指普通人很难才能用到,权限比较难获取。
如果你也卡在这一步,我最近看到一个挺务实的路径:知乎知学堂的《AI新编程副业实战营》。它的思路不是让你背概念,而是把路线讲得很直白——从 0 到 1 做出一个 AI 轻应用的 MVP,再把“怎么定价、怎么找需求、怎么跑通变现”这一整套闭环拆开给你看。对很多想要副业、想做一人项目的人来说,这比到处拼“零散教程”更省时间。
不知道啥时候没,建议先预约一手,官方入口指路↓↓↓
听完别忘记领取他们整合的AI资源合集,尤其是关于Coze的资料!
包括我在内,刚开始对着输入框,也只知道问一些比如「给我写首诗」,「按照*给我写一篇作文」这种问题。

ChatGPT确实擅长这个,它很好的根据我们的要求写了出来。

我也让它写过歌,写过绝句,写过律诗,但是问题来了:
很多人,包括我在内,都在说ChatGPT除了不会生孩子,其他的都能干。
但是这并不是一个具有可操作性的说法,这次我要做的就是把ChatGPT可以干什么,以及它可以帮助你干什么讲明白,讲细。
ChatGPT的操作,一切都要从这个对话框开始,所以你在这个框里输入的东西,就代表了你将要用它来做什么。

比如你要输入的是文字。
文字可以是中文,也可以是英文,也可以是其他的语言。
假设我们输入的是中文,我们可以随便输入一句话:这是我第一次用ChatGPT。
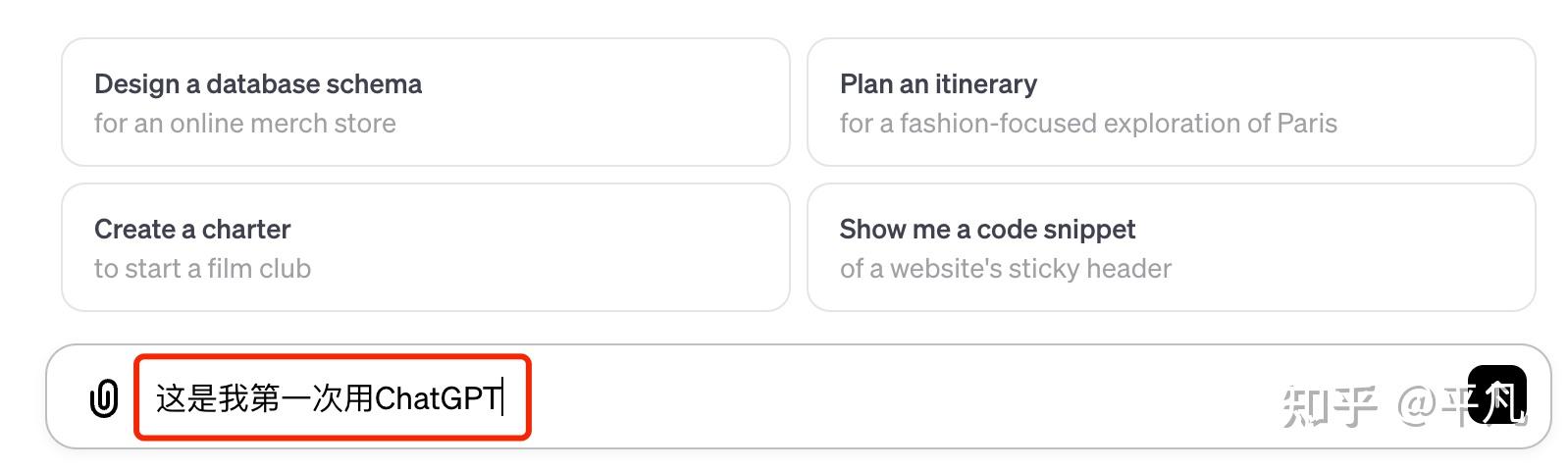
然后接下来的是重点,我们想干什么?
比如说最简单的,你可以什么都不输入,直接点击回车键看看ChatGPT能干什么。

这个回答是单纯的这句话,ChatGPT会自动识别出你并没有什么具体的想法,所以它会主动的提示你,它可以帮助你回答任何问题,其实这也就是ChatGPT中Chat的核心含义。
所以即使你不会用,也可以顺着它的话继续说,比如你可以问它「请问你可以根据我提供的第一句话干什么?」

你看它会告诉你有几种可能性,给出你选项你可能就知道下一步该问什么了。
这个过程你应该掌握的是,ChatGPT是一个非常开放且自由的工具,它理论上会回答你提出的任何问题。
所以结合ChatGPT的输入框+它的对话特性,我们就可以自己来分析到底用ChatGPT可以做什么。
我先给你分享一个案例,一个完全没有任何编程经验的老哥,在ChatGPT出现后凭着直觉认为2023年的AI会爆火,因此他用ChatGPT写了一个AI的导航站。
有些朋友可能不知道什么是导航站。

就类似于这样的,就是总结了很多的网站,然后把他们分门别类的整理在一起,比如大模型软件,有ChatGPT,bard,文心一言等等,这样做的就是方便人们使用。
这个大哥经历过以前的hao123时代,就觉得AI时代也需要,事实上就是这样的,他这个站点大概在2月份就上线了,在ChatGPT的帮助下基本上1晚上就搞出了这个站点的雏形,差不多10个月过去了,这个网站可以给他带来每个月差不多2000美元的收入。
这也是我为什么总是说ChatGPT这样的AI工具,每个人都应该去尝试跟它结合。
结合的方式我觉得也分几层。
第一层的结合起码你得让它帮你减轻点学习或者工作的负担,比如让它把你今天背的单词写成一个短文,这样可以方便让你理解。
比如我们要背这些单词,那么我们就可以直接复制粘贴到ChatGPT中。
然后用这个Prompt:用这些单词写一篇短文方便我记忆,给我提供的单词加粗,并且提供中文翻译。
你看,它非常的智能的给你用这些词汇写了一篇非常地道的英文短文,同时还会把你要背的单词的中文意思标注在后面。

是不是非常的智能,但请你记住,这只是我的想法,你要做的是找到适合你的做法,而不是直接照抄我的。
工作也一样,比如你的工作需要写一些材料性质的文档,你完全可以让ChatGPT帮你写一个初稿出来,然后在这个基础上修改,会非常的省事。
第二层就是使用ChatGPT来为自己创造一份额外的收入,就跟刚才那个例子的老哥一样,其实每个人都有机会在ChatGPT的帮助下实现自己的想法。
更多的是可能不知道怎么去着手,其实你只要知道你喜欢什么且ChatGPT能干什么之后,可能就比较清晰了。
比如对我来说,我喜欢写文字,那我就是用的ChatGPT文字润色功能,以及图像输入和代码执行环境来帮助我写各种各样的教程或者演示视频。
那对你来说,其实也是一样的逻辑,那就是根据ChatGPT可以接受的输入类型来确认你自己的方向。
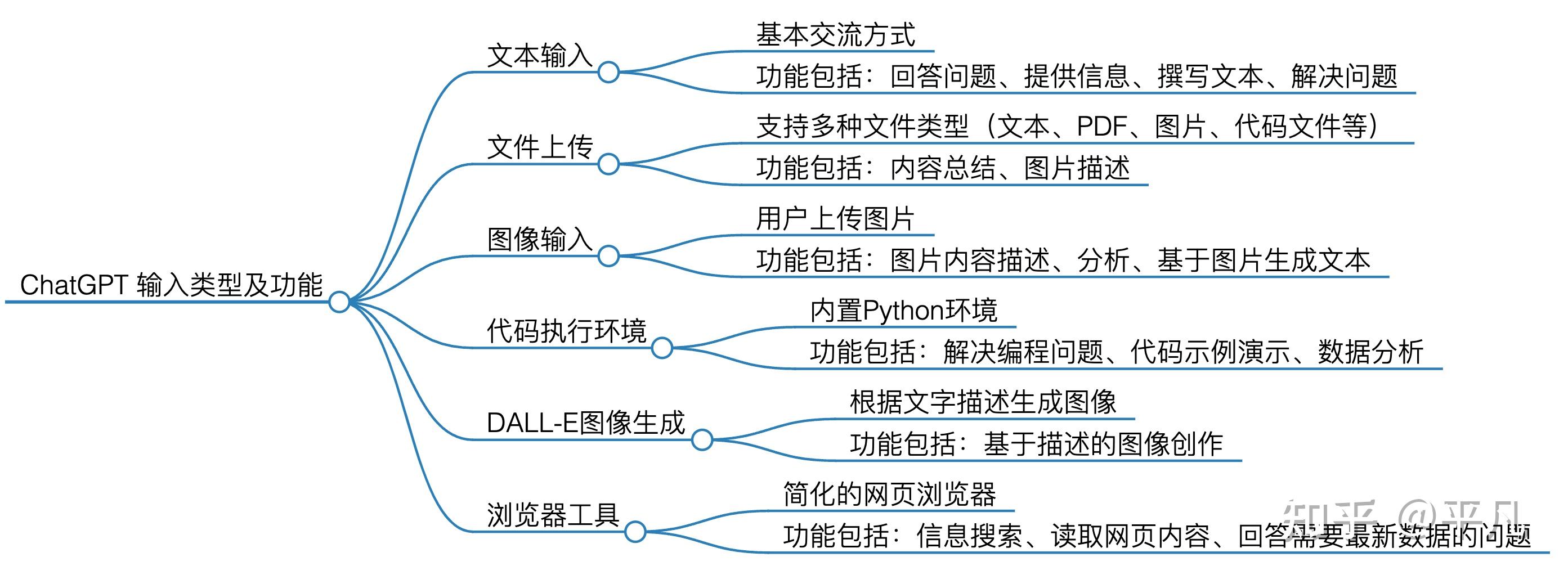
比如对于ChatGPT来说,它最基本的也是最强的就是文本输入。
你看它的文本输入功能,有回答问题(契合知乎,百度知道等),提供信息(契合攻略类,问答型),撰写文本(契合各种自媒体,比如小红书,抖音等等各类平台的文案书写)。
你可以看到,它最基本的文本输入功能,都可以做这么多的事情。
它还有其他各种先进的功能,而你要做的其实就是提供一个想法。

想法最重要,剩下的反而ChatGPT会教你一步步的怎么做,然后你要做的就是要去实践你的想法。
下面就举一个我刚刚实现的案例,比如我想仿照刚刚提到的大哥做个AI导航站,这是我的想法。
想法:AI导航站
那么我就直接找ChatGPT来帮忙
首先这是ChatGPT给我生成的代码,你不需要知道它是干什么的,按照ChatGPT的一步步做就可以。
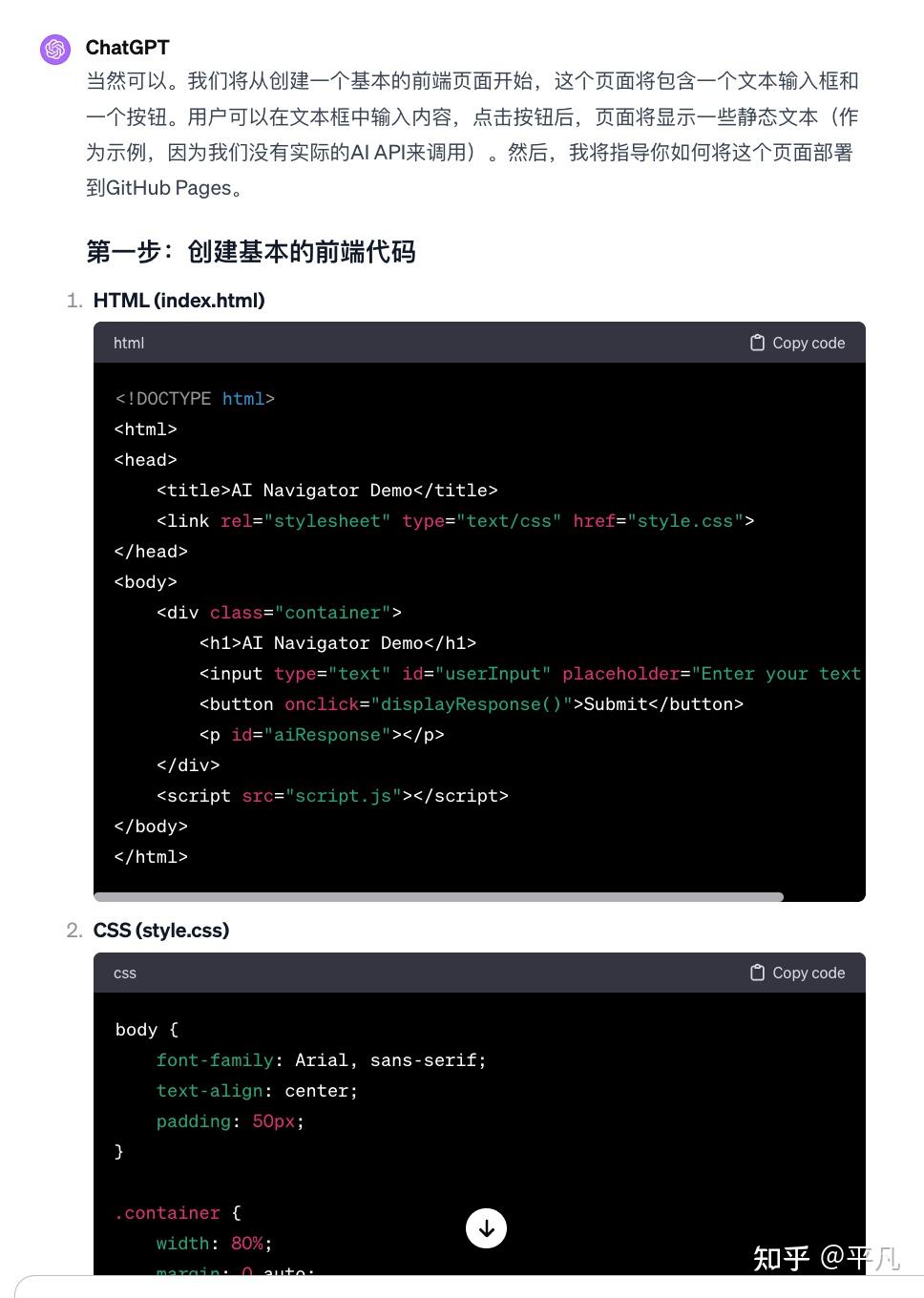
它会非常详细的告诉你怎么做

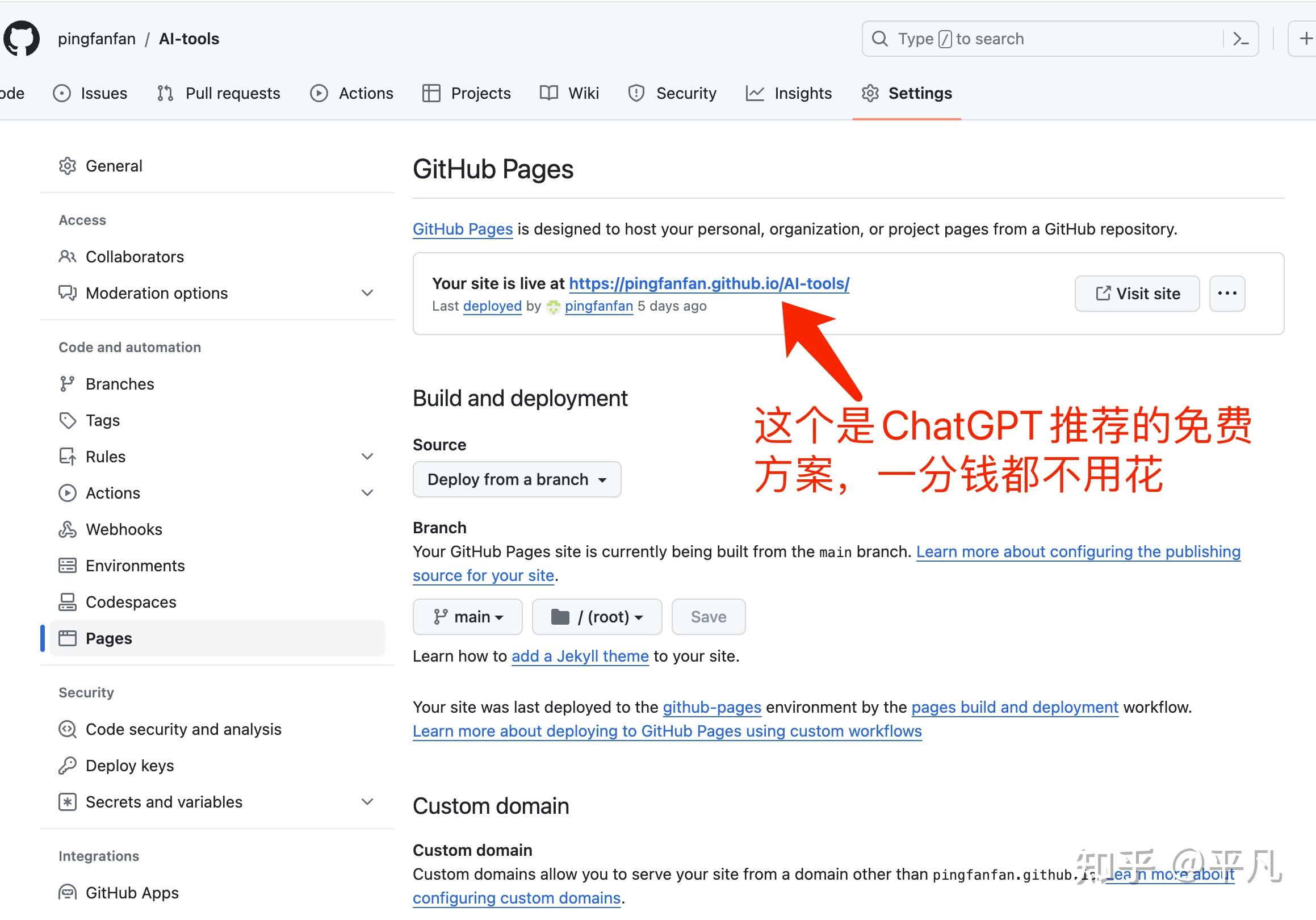
我按照ChatGPT教的方法,花了大概10分钟成功的在Github上做了这个网站。
这个网站打开后是这样的
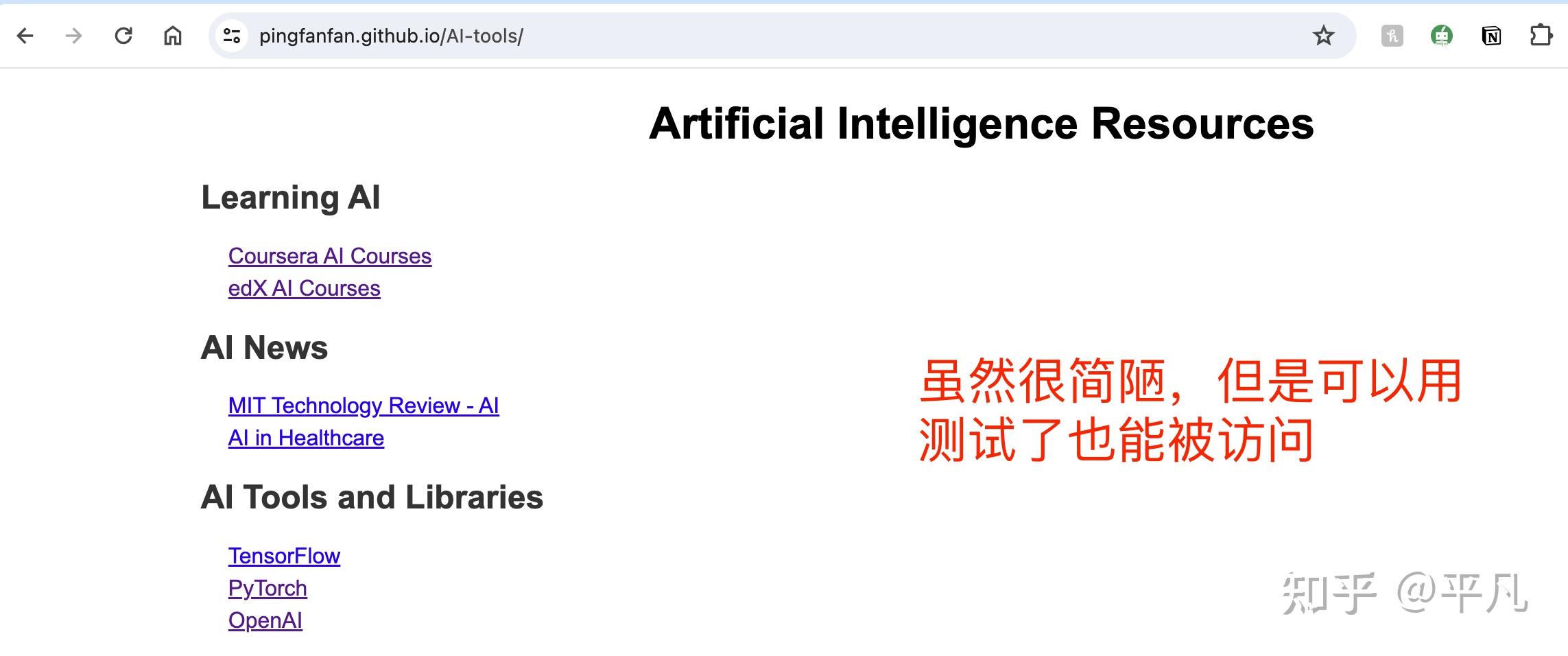
后续完全可以补上更多的AI工具,以及做的更精美一些。
这个过程中可以一分钱不用花,ChatGPT用免费的GPT3.5,Github 完全免费的网站托管功能。
并且这个过程中的任何问题都可以问ChatGPT,直到你完全搞好。
这种情况,但凡是个人就已经烦了,但是ChatGPT不会,它会永远的非常有礼貌的不紧不慢的给你解决问题。
刚出GPT 4时候就开始用了,现在应该快两年了吧。从一个研究生的角度,我来讲讲我平时是怎么用ChatGPT的吧。先从科研角度来讲吧,后续有空慢慢更新其他的。如果大家觉得有什么更好的用法,可以一起分享。
一般读论文,我会先肉眼扫一眼看摘要,决定要不要继续深入。如果要继续深入看的话,我还会再选择GPT来迅速了解全文内容。一般而言我用的提示词如下:
请从摘要、研究背景、难点与调整、贡献、方法以及实验等角度详细介绍一下这篇论文。下面是这篇论文的内容:
「论文内容」
内容我一般是直接复制整个PDF的内容,而不是上传文件(因为就我个人的使用的经验来看,相比于复制内容,直接上传回答的效果没那么好)。根据GPT的回答,如果我对哪部分内容感兴趣,我会继续追问某一部分的细节,比如“论文中方法部分用的是什么架构的编码器?”。
但是这其中往往会遇到一些问题,比如当你问到的细节涉及到论文的一些公式时候,直接复制pdf的公式会很乱(不过简单的公式貌似gpt也能识别),这时候就需要使用到下面的公式识别的神器了Mathpix: Snip Apps ,只需要截图就可以识别。识别后告诉GPT就可以了,这样下来GPT就能很好的理解公式了。上面的这个工具普通邮箱注册的一个月只有10次,教育邮箱注册的一个月可以有20次。
我们导师经常叫我们去调研新的领域,但是文献太多了,想要短时间内调研清楚一个领域确实很难,尤其是最前沿的领域。所以我写了一个脚本爬取arxiv大概100篇的论文摘要,然后用GPT3.5的API总结翻译摘要,最后送入网页版GPT 4给我写一篇综述。实测体验还不错,虽然有些论文引文对应不上,但是可以通过不断调教,不断优化提示来达到最终的目的。
爬取论文摘要的代码是用selenium浏览器实现的,通过点击arxiv网站的more显示所有摘要,然后使用xpath匹配。代码比较简单,如下:
from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support.wait import WebDriverWait from selenium.webdriver.support import expected_conditions as EC
# 创建ChromeOptions对象 options = Options() # 启用无头模式 # options.add_argument(“–headless”) # 启用无痕模式 options.add_argument(“–incognito”) options.add_argument(“–disable-domain-reliability”) options.add_argument(“–disable-blink-features=AutomationControlled”) options.add_argument(“–disable-client-side-phishing-detection”) options.add_argument(“–no-first-run”) options.add_argument(“–use-fake-device-for-media-stream”) options.add_argument(“–autoplay-policy=user-gesture-required”) options.add_argument(“–disable-features=ScriptStreaming”) options.add_argument(“–disable-notifications”) options.add_argument(“–disable-popup-blocking”) options.add_argument(“–disable-save-password-bubble”) options.add_argument(“–mute-audio”) options.add_argument(“–no-sandbox”) options.add_argument(“–disable-gpu”) options.add_argument(“–disable-extensions”) options.add_argument(“–disable-software-rasterizer”) options.add_argument(“–disable-dev-shm-usage”) options.add_argument(“–disable-webgl”) options.add_argument(“–allow-running-insecure-content”) options.add_argument(“–no-default-browser-check”) options.add_argument(“–disable-full-form-autofill-ios”) options.add_argument(“–disable-autofill-keyboard-accessory-view[8]”) options.add_argument(“–disable-single-click-autofill”) options.add_argument(“–ignore-certificate-errors”) options.add_argument(“–disable-infobars”) options.add_argument(“–disable-blink-features=AutomationControlled”) options.add_argument(“–disable-blink-features”) # 禁用实验性QUIC协议 options.add_experimental_option(“excludeSwitches”, [“enable-quic”]) # 创建Chrksome浏览器实例 driver = webdriver.Chrome(options=options, )
key_words = ‘’
url = “https://arxiv.org/search/?searchtype=all&query={}&abstracts=show&size=100&order=-announced_date_first".format(
讯享网<span class="n">key_words</span><span class="o">.</span><span class="n">replace</span><span class="p">(</span><span class="s1">' '</span><span class="p">,</span> <span class="s1">'+'</span><span class="p">)</span>
)
try:
<span class="n">driver</span><span class="o">.</span><span class="n">get</span><span class="p">(</span><span class="n">url</span><span class="p">)</span> <span class="c1"># print(driver.page_source)</span> <span class="n">WebDriverWait</span><span class="p">(</span><span class="n">driver</span><span class="p">,</span> <span class="mi"></span><span class="p">)</span><span class="o">.</span><span class="n">until</span><span class="p">(</span> <span class="n">EC</span><span class="o">.</span><span class="n">presence_of_element_located</span><span class="p">((</span><span class="n">By</span><span class="o">.</span><span class="n">XPATH</span><span class="p">,</span> <span class="s1">'//span[@class="abstract-full has-text-grey-dark mathjax"]'</span><span class="p">))</span> <span class="p">)</span> <span class="c1"># 定位到展开按钮并点击</span> <span class="n">expand_buttons</span> <span class="o">=</span> <span class="n">driver</span><span class="o">.</span><span class="n">find_elements</span><span class="p">(</span><span class="n">By</span><span class="o">.</span><span class="n">XPATH</span><span class="p">,</span> <span class="s1">'//a[contains(@class, "is-size-7") and contains(@style, "white-space: nowrap;")]'</span><span class="p">)</span> <span class="k">for</span> <span class="n">i</span><span class="p">,</span> <span class="n">expand_button</span> <span class="ow">in</span> <span class="nb">enumerate</span><span class="p">(</span><span class="n">expand_buttons</span><span class="p">):</span> <span class="k">if</span> <span class="n">i</span> <span class="o">%</span> <span class="mi">2</span> <span class="o">==</span> <span class="mi">0</span><span class="p">:</span> <span class="c1"># print(i, expand_button.text)</span> <span class="n">expand_button</span><span class="o">.</span><span class="n">click</span><span class="p">()</span> <span class="c1"># print(driver.page_source)</span> <span class="c1"># xpath 匹配abstract-short has-text-grey-dark mathjax的div标签</span> <span class="n">elements_abstract</span> <span class="o">=</span> <span class="n">driver</span><span class="o">.</span><span class="n">find_elements</span><span class="p">(</span><span class="n">By</span><span class="o">.</span><span class="n">XPATH</span><span class="p">,</span> <span class="s1">'//span[@class="abstract-full has-text-grey-dark mathjax"]'</span><span class="p">)</span> <span class="n">elements_title</span> <span class="o">=</span> <span class="n">driver</span><span class="o">.</span><span class="n">find_elements</span><span class="p">(</span><span class="n">By</span><span class="o">.</span><span class="n">XPATH</span><span class="p">,</span> <span class="s1">'//p[@class="title is-5 mathjax"]'</span><span class="p">)</span> <span class="n">elements_link</span> <span class="o">=</span> <span class="n">driver</span><span class="o">.</span><span class="n">find_elements</span><span class="p">(</span><span class="n">By</span><span class="o">.</span><span class="n">XPATH</span><span class="p">,</span> <span class="s1">'//p[@class="list-title is-inline-block"]/a'</span><span class="p">)</span> <span class="n">titles</span> <span class="o">=</span> <span class="p">[]</span> <span class="n">abstracts</span> <span class="o">=</span> <span class="p">[]</span> <span class="n">links</span> <span class="o">=</span> <span class="p">[]</span> <span class="k">for</span> <span class="n">i</span><span class="p">,</span> <span class="n">element</span> <span class="ow">in</span> <span class="nb">enumerate</span><span class="p">(</span><span class="n">elements_abstract</span><span class="p">):</span> <span class="n">title</span> <span class="o">=</span> <span class="n">elements_title</span><span class="p">[</span><span class="n">i</span><span class="p">]</span><span class="o">.</span><span class="n">text</span> <span class="n">link</span> <span class="o">=</span> <span class="n">elements_link</span><span class="p">[</span><span class="n">i</span><span class="p">]</span><span class="o">.</span><span class="n">get_attribute</span><span class="p">(</span><span class="s1">'href'</span><span class="p">)</span> <span class="n">abstract</span> <span class="o">=</span> <span class="n">f</span><span class="s2">"{i + 1}. "</span> <span class="o">+</span> <span class="n">elements_abstract</span><span class="p">[</span><span class="n">i</span><span class="p">]</span><span class="o">.</span><span class="n">text</span> <span class="o">+</span> <span class="s1">'</span><span class="se">\n</span><span class="s1">'</span> <span class="n">titles</span><span class="o">.</span><span class="n">append</span><span class="p">(</span><span class="n">title</span><span class="p">)</span> <span class="n">abstracts</span><span class="o">.</span><span class="n">append</span><span class="p">(</span><span class="n">abstract</span><span class="p">[:</span><span class="o">-</span><span class="mi">6</span><span class="p">])</span> <span class="n">links</span><span class="o">.</span><span class="n">append</span><span class="p">(</span><span class="n">link</span><span class="p">)</span> <span class="c1"># 保存为df</span> <span class="n">df</span> <span class="o">=</span> <span class="n">pd</span><span class="o">.</span><span class="n">DataFrame</span><span class="p">({</span><span class="s1">'title'</span><span class="p">:</span> <span class="n">titles</span><span class="p">,</span> <span class="s1">'abstract'</span><span class="p">:</span> <span class="n">abstracts</span><span class="p">,</span> <span class="s1">'link'</span><span class="p">:</span> <span class="n">links</span><span class="p">})</span> <span class="n">df</span><span class="o">.</span><span class="n">to_csv</span><span class="p">(</span><span class="s1">'https://www.zhihu.com/question/out/{}.csv'</span><span class="o">.</span><span class="n">format</span><span class="p">(</span><span class="n">key_words</span><span class="p">),</span> <span class="n">index</span><span class="o">=</span><span class="bp">False</span><span class="p">)</span> except Exception as e:
讯享网<span class="c1"># 停止脚本时关闭浏览器</span> <span class="k">print</span><span class="p">(</span><span class="n">e</span><span class="p">)</span>
driver.quit()
key_words需要修改为你的搜索词。由于网页版GPT4的上下午限制,爬取完摘要后需要对摘要进行压缩。用以下代码请求GPT3.5的API接口翻译摘要或者总结摘要。这里的prompt可以自行修改,如果总的论文数目比较少,可以让摘要详细点,就让它直接翻译成中文而不用总结压缩字数。
import json from concurrent.futures import ThreadPoolExecutor import numpy as np import pandas as pdfrom Models.GPT import GPT
with open(‘Models/gpt3.5_config_oneapi.json’, ‘r’) as f:
讯享网<span class="n">s</span> <span class="o">=</span> <span class="n">f</span><span class="o">.</span><span class="n">read</span><span class="p">()</span>
conf = json.loads(s) conf[‘model’] = ‘gpt-3.5-turbo’ gpt = GPT(conf)
key_words = ‘privacy leakage LLMs prompt’
df = pd.read_csv(f”https://www.zhihu.com/question/out/{key_words}.csv") # title,abstract,link
prompt = “下面是一篇论文的摘要:用中文一句话描述它使用的核心方法。下面是摘要{}”
abstract_list = df[‘abstract’].tolist()
with ThreadPoolExecutor(max_workers=16) as executor:
<span class="n">results</span> <span class="o">=</span> <span class="nb">list</span><span class="p">(</span><span class="n">executor</span><span class="o">.</span><span class="n">map</span><span class="p">(</span><span class="k">lambda</span> <span class="n">abstract</span><span class="p">:</span> <span class="n">gpt</span><span class="o">.</span><span class="n">query</span><span class="p">(</span><span class="n">prompt</span><span class="o">.</span><span class="n">format</span><span class="p">(</span><span class="n">abstract</span><span class="p">),</span> <span class="n">max_tokens</span><span class="o">=</span><span class="mi">4096</span><span class="p">),</span> <span class="n">abstract_list</span><span class="p">))</span> results = [result[‘choices’][0][‘message’][‘content’] for result in results]
df[‘abstract_summary’] = results df.to_csv(f“https://www.zhihu.com/question/out/{key_words}_summary.csv", index=False, encoding=‘utf-8-sig’)
最后复制https://www.zhihu.com/question/out/{key_words}_summary.csv这个文件中的abstract_summary这一列扔给GPT4让他写一个综述,同时让他注意标注引文序号。
作为一个ChatGPT的重度用户,我是一个妈妈,也是一个自媒体创作者,ChatGPT用好的话,能够降低创作门槛,提升创作效率,哪怕是普通人也能创作出精彩的文案,作出栩栩如生的图片,甚至音乐和视频!
当然,前提是你“真的”会使用ChatGPT!
接下来,我就总结一下ChatGPT的“小白使用方法”,一看就懂,上手就会!
这个功能一开始我还是挺惊讶的,没想到GPT4已经可以制作图片了,而且做得还挺不错的,语言描述也没有那么复杂,小白都能轻松驾驭!来看一下:
描述如下:想做一只可怜兮兮小奶狗的表情包,要动作表情夸张,泪眼汪汪,如何描述
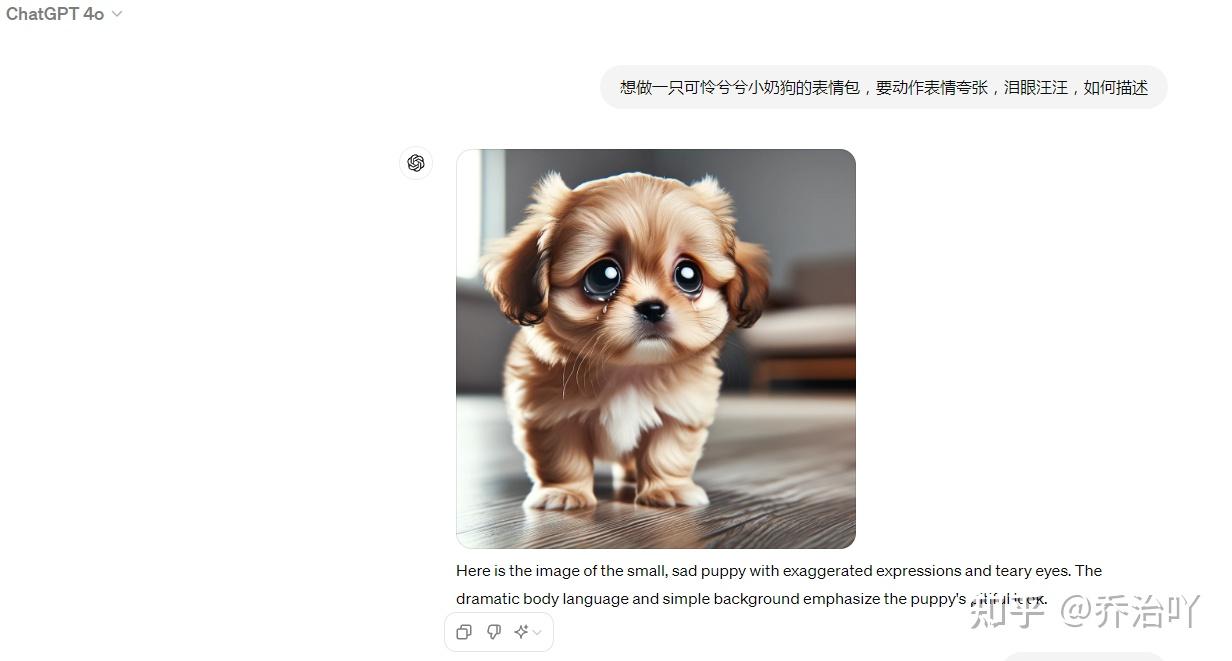
如果感觉不满意,还可以在需要修改的地方提出修改意见,比如这张,就感觉眼泪太假,
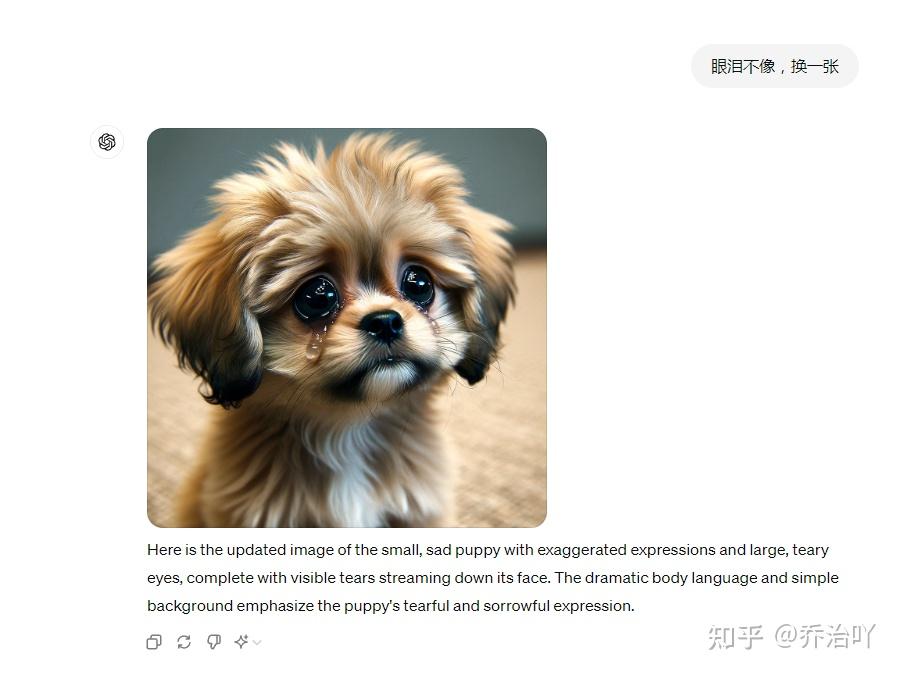
直到调整到满意的结果就可以了!
但是,问题又来了,该如何配文字呢?
哈哈,问ChatGPT!

再将文字配到图片上就完成了!
看看成图效果:

根据想象描述一幅画面,ChatGPT还可以生成对应的图片,真实感不说太强,却有一种动画片的感觉!

扮演的角色(职业)+角色的背景细节(擅长)+需要解决的问题(自己的需求)
孩子不愿意刷牙,我以孩子妈妈想要让孩子乖乖配合刷牙为例,将ChatGPT的角色设定为:“一个具有丰富经验的母婴领域的自媒体创作者”,擅长:孩子心理教育和行为引导,帮助孩子解决成长中的各类问题,自己的需求:帮助我指定更好的育儿计划,以及实现这些计划的具体措施。我的需求是:孩子不好好刷牙,怎么办?如何在不伤害孩子感情的前提下让孩子好好配合刷牙?
利用上述提问格式向ChatGPT进行提问,

然后,就获得了我想要的答案:



按照这个思路下去,孩子不好好刷牙的问题在大方向上已经解决了,如果细节上还有不明白的可以继续提问,比如“如何选择一款符合孩子口腔发育阶段的牙刷和牙膏?”




看到ChatGPT对于这个问题的解答,逻辑条理非常清晰,但是有些更加精细的细节还是需要自己去甄别的,比如回答中的牙膏和牙刷的品牌是否存在,具体到孩子到底喜欢哪种品牌的牙膏和牙刷,这个就需要继续问ChatGPT或者自己带孩子去尝试了。
通过”角色扮演+角色细节+需要解决的问题”的提问方式,我们可以通过ChatGPT获得“更精准”的回答。但是,有时候我们也会有这样的苦恼,“我遇到的问题该找什么人去解决呢?”
在不知道遇到问题需要匹配什么角色来回答时?
不妨试试反向思维让AI来给自己构建身份背景。
比如:





很多朋友都有选择恐惧症,就像ChatGPT这个大语言模型,如果你问它一个问题,它会事无巨细的告诉你全部的答案,但是,全部而非针对型,反而会导致选择困难。
角色扮演+需求+选项
继续1中的步骤,如果回答中的某些信息自己已经知道,可以套用以上模板进行提问:
接下来,ChatGPT就会给出该问题的定制答案:

里面讲述了方法实施的原因以及具体操作,看过以后就基本上做到心中有数,做起事来也就安心很多。
问题背景(角色扮演/背景信息等等)+请给出N个解决方案+具体的要求
在复杂的场景或者灵感枯竭的时候,我们总希望获取新的创新思路,有时候我们会采取头脑风暴,有时候我们会集体讨论,但这种思路还是比较有限的,如果交给ChatGPT,思路就“哗”地一下打开了!
比如,我想写一篇关于如何制作表情包的文章,但是,不知道些什么样的标题足够吸引人,这个时候就可以套用以上模板进行提问:

这时,你就能获得十种爆款文案标题:

刚开始接触ChatGPT的时候,我也是摸着石头过河,对于ChatGPT的提示词也是一知半解,总觉着使用起来不得其法,就像在使用一个稍微智能一点的搜索网页,无法发挥ChatGPT本身强大的功能,直到接触到了「知乎知学堂AI应用课」,老师在课上简单的一句话就解答了我琢磨近一个多月的提示词问题,相比于一个人单打独斗,有一个实战经验丰富的AI领域老师引路,真的太省时省力了!
不要担心课程听不懂,这是专门为0基础小白量身打造,哪怕是刚入门的AI使用者,也同样适用!限时 0.1 元,有兴趣的小伙伴,赶紧码住!
对了,上课以后,千万别忘了加助教老师,悄**告诉你,老师会送你很多关于AI应用的学习资料包,相比于网络上说一半留一半的资料简直不要太好,针对性强,学习起来也不费力!
话题引入+角色扮演式提问+观察回答+对话交互修正
相当于角色扮演,让ChatGPT变成一个虚拟的人物,和他进行沟通。比如
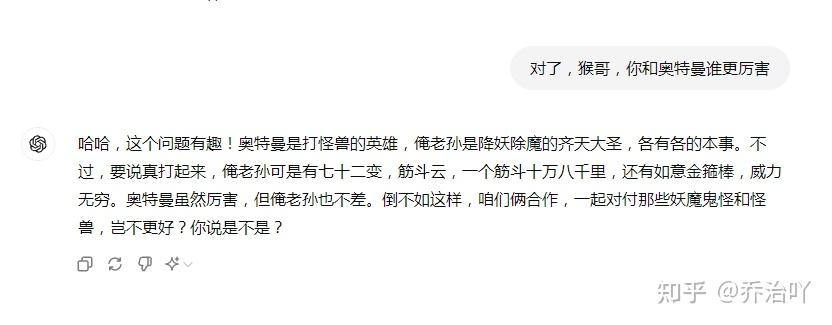
我将ChatGPT变成一个虚拟的人物孙悟空,语言风格真的很孙悟空!
请欣赏一下:

后面,想起了儿子问过的一个问题,“孙悟空和奥特曼谁更厉害?”于是,我问了一下”猴哥“,猴哥还挺有意思的,居然要请我一起打怪兽,哈哈——
这个功能我喜欢,如果闲了闷了,无聊了,ChatGPT可以瞬间变成任何角色来和你对话,就像朋友一样,流畅自然,亲切无比。
这个就很简单了,没有什么特别的提问方式,就是一句很简单的命令就可以了!
比如,以下报表(非真实数据,仅作操作示范),如果用常规工具制作图表,至少十分钟左右,但是用ChatGPT,仅需要一分钟。
提问如下:
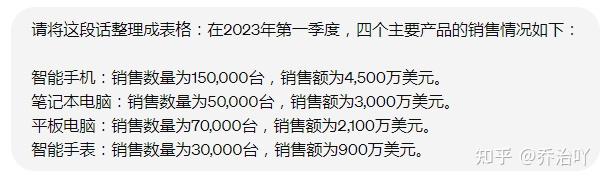
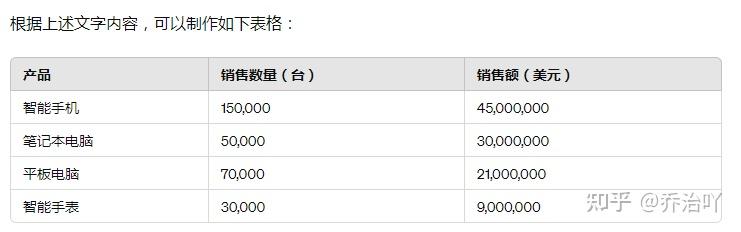
并且,还能根据这组数据对下一季度的销售情况作出预测,太厉害了!

暂时就想到这么多,这篇回答会不定期更新,我也会解锁更多关于普通人能玩的ChatGPT玩法,敬请期待吧!
我是@乔治吖,一个喜欢ai的文艺女孩子,从零学习ai,记录学习日常,分享学习心得,喜欢就关注下吧!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/209925.html