
在模型推理领域中,Prompt-Caching/Context-Caching/Prefix-Cache 等等概念,其背后的核心思想都类似,就是根据指定的 Prompt Prefix 来构建缓存,这样在下次接收到相同前缀的请求时,可以快速返回响应,减少模型编解码、推理和网络传输等成本。
主流的大模型如 Gemini、Claude 和 Moonshot 等,和推理框架 vLLM 等,都支持该功能。
下面以 Claude 为例,介绍下 Prompt-Caching 的核心原理。
技术原理
- Cache Key:对 Prompt 中指定的 Prefix 做 SHA-256 Hash,作为 Cache Key。
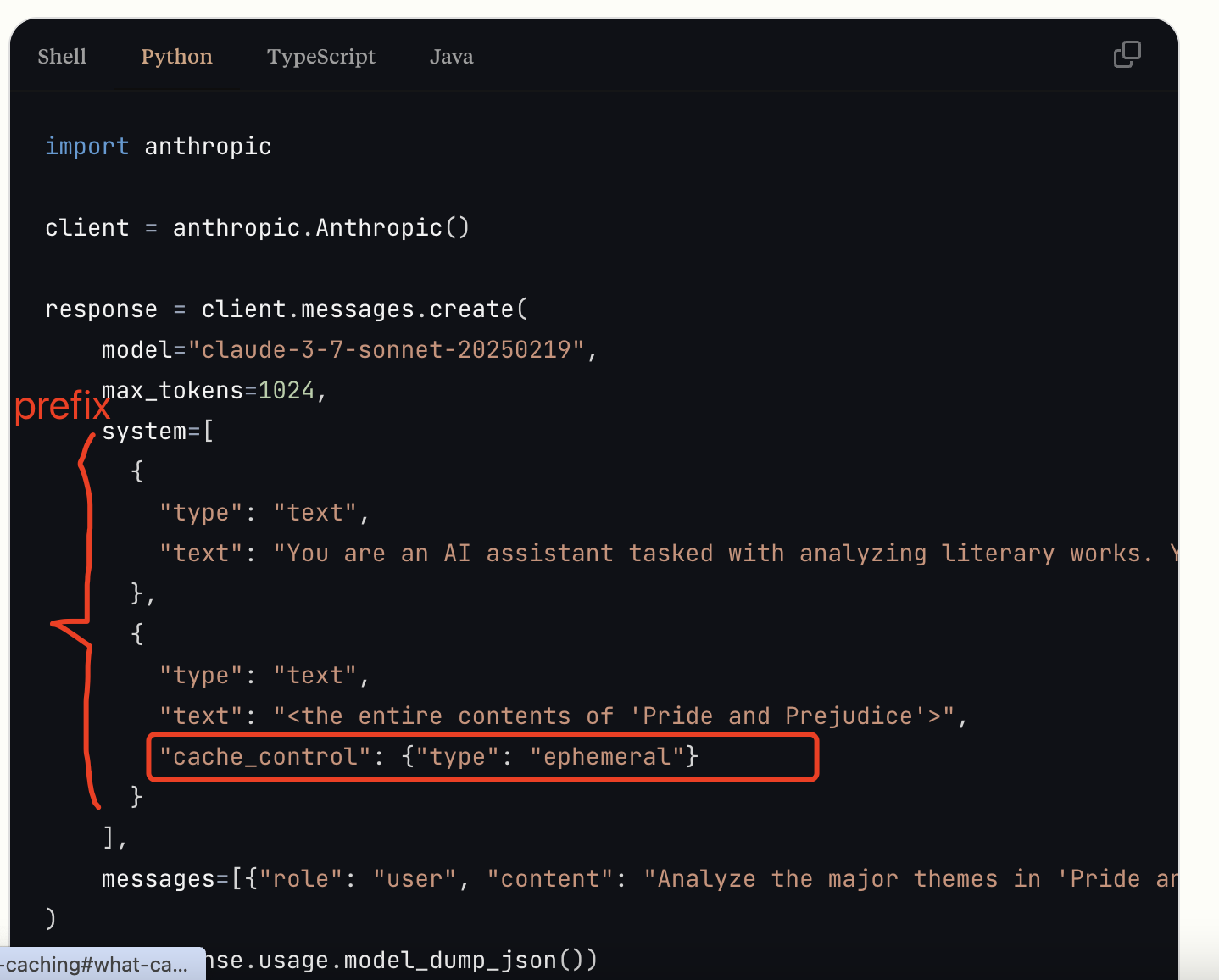
- Cache Hit:若存在匹配缓存,直接读取缓存内容(cache_read_input_tokens)。
- Cache Creation:针对首次请求,或 Cache Miss 的场景,则需要根据指定的 Prompt Prefix 构建缓存。(cache_creation_input_tokens)。
- Hit Ratio 监控:
- 如果是原生的 Claude API,可以根据 response 中的 cache_read_input_tokens 字段,监控缓存命中率。
- 如果使用的是类似 OpenRouter 的三方代理,可能 response 中不会返回该字段,需要确认下 Dashboard 中是否可以监控缓存命中率。
缓存有效期
5分钟。该 TTL 为固定值,不支持自定义设置。
可缓存项
- System Prompt
- 对话历史
- 图片
- 视频
- Tool-Calling 定义
使用限制

- 最小长度:不同模型要求的最小缓存长度不同,Claude 3.7 Sonnet 为 1024 tokens
- 并发限制:Cache Item 需等待首次响应生成后才能被其他请求使用。
- 多轮长文本对话:针对我们的场景,需要 System Prompt 非常长的角色才能生效。
- 代码助手
- 固定知识库问答
成本
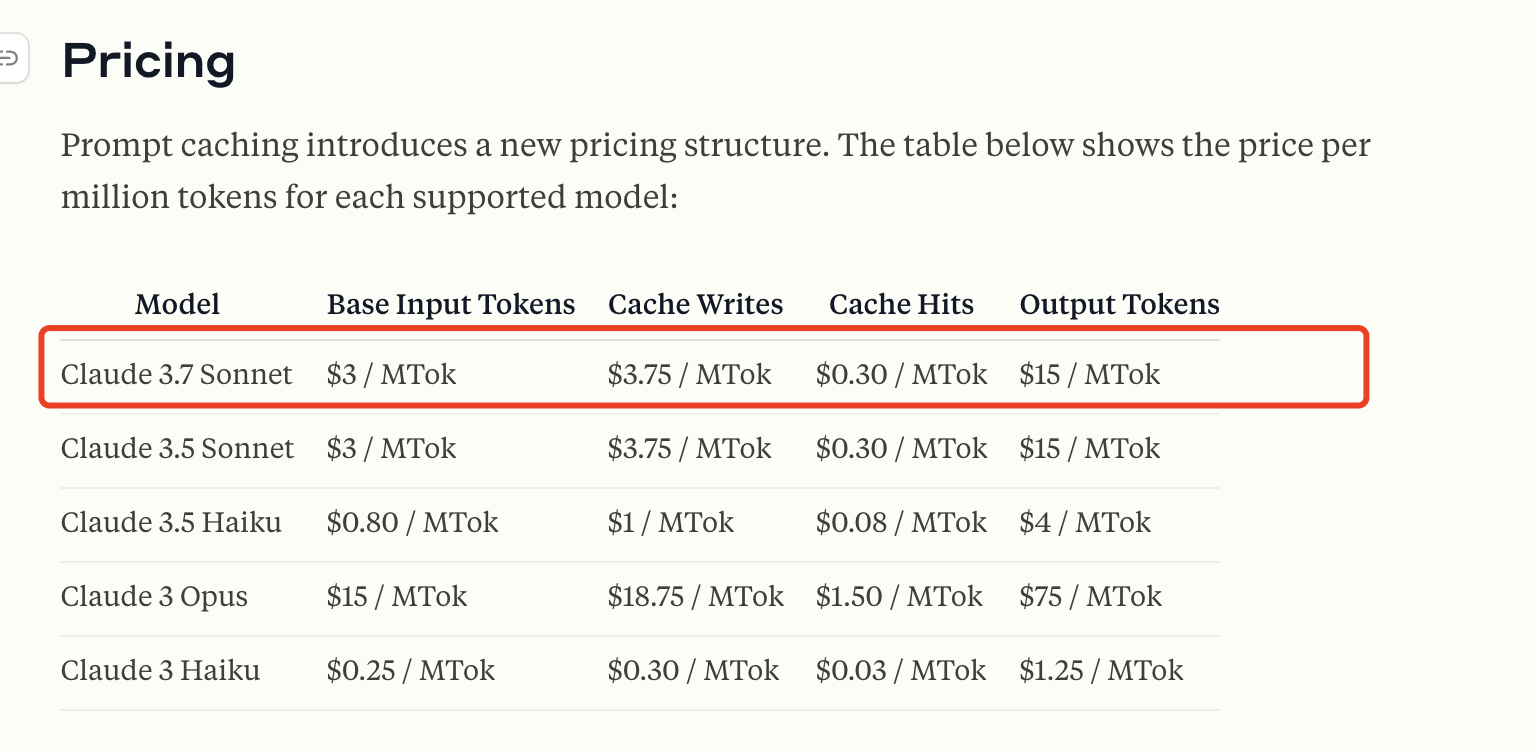
- 如果命中缓存,input token 的成本会减少 90%。
- 需注意:缓存的首次构建和更新的写入成本会增加 125%。
性能
如果命中缓存,预期可以一定程度上提升响应性能,但可能不会太明显,因为聊天的主要耗时还是在模型推理上。
我们实现一个简单的红楼梦问答小助手,基于《红楼梦》前2回的内容进行提问。因为文本长度超过了 1024 个 token,因此可以开启缓存功能。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/209818.html