
前言
今天讲的是CTPN,Detecting Text in Natural Image with Connectionist Text Proposal Network同样无论别人怎么写,我们讲原理力求简单,用最low的话,讲最复杂的原理(吹个牛,别介意),可能讲的并不是那么好但是一定更倾向于我们这儿样的小白。话不多说,开整。
算法初识
算法框架

在开讲主体结构之前我们先讲CTPN的两个核心思想:Anchor和文本线构造算法
Anchor:这个概念来源与Faster RCNN,简单地说就是预先选好的文本框,他的思想是预先选出所有可能的文本框(每个像素点都配备一定数量的Anchor,然后筛选出一部分),然后选出和真值框差距最小进行修正。这种思想类似于穷举法,但是CTPN对Anchor做了些许改动,CTPN限制了Anchor的宽度16(为什么是16后面会讲),然后只取他的中心坐标和高度,而Faster RCNN则需要左上和右下角点坐标。
文本线构造算法:前面说了CTPN对Anchor做出了改变为什么呢?这就要说CTPN的另外一个思想了,我喜欢称他为:微分法,如上图中b部分所示,CTPN的思想中并不直接画出文本框而是利用一种类似微分的思想,先画出多个小文本框,然后利用文本线构造法画出大的文本框。
好了介绍完核心思想我们开始介绍完整结构。
a部分
首先我们做个小假设,假设有N张图片,输入网络中,第一步我们就要送入VGG16网络中进行特征提取。输出大小为NxCxHxW。此处我们把获得结果称为conv5 feature map。
然后在conv5 feature map上做3x3滑动窗口,让NxCxHxW变为Nx9CxHxW,其中具体过程如下图,作用是融合附近区域特征,提升鲁棒性。

然后我们将结果做一下Reshape:Nx9CxHxW变为(NH)xWx9C,然后送入双向LSTM,学习每一行的序列特征。这里停一下我们要说一下为什么要用双向LSTM。对于文本检测我么一般从两种特征:空间特征和序列特征(就是文字的连续性),空间特征cnn就解决了,至于序列特征那就要靠LSTM了,那么为什么用双向LSTM呢?有位前辈做了一个这样的解释:假设有这麽一句话:
我的手机坏了,我打算____一部新手机。
答案是:“买”,如果是单向的LSTM我们就只能看见我的手机坏了,我打算,那么这个填空不好填了,可能性太多,但如果是双向LSTM我们就可以看到整句话,就大大的提高填空的准确性。
然后输出为:(NH)xWx256再Reshape为Nx256xHxW。然后送入“FC”卷积层,变为Nx512xHxW。
下一步我们就要将输出结果送入RPN网络了首先让我们看一下RPN网络结构:

这里RPN网络有两支:
1》左边分支用于bounding box regression。由于fc feature map每个点配备了10个Anchor,同时只回归中心y坐标与高度2个值,所以rpn_bboxp_red有20个channels

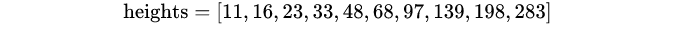
这样在配合文本线构造算法就可以覆盖大多数文本框情况,而且由于宽度和中心坐标已经确定了,就避免了文本框重复的情况,这样就不必要进行NMS筛选了。
然后最后输出三个返回值:分类结果,坐标偏差和输入输出权重(匪夷所思的东西,似乎有无对结果影响不大)。
b部分
文本线构造法:

文本线构造法就是将微分的Anchor连成一个整体文本框。在构造前我们要做两个准备:1为文本框编号,2获得文本框的分数,3计算文本框竖直方向的overlap。(注意这不是真的重合只是相对的,我们不看x坐标只看y坐标只要在y坐标上重合即认为重合)于是我们得到下图:
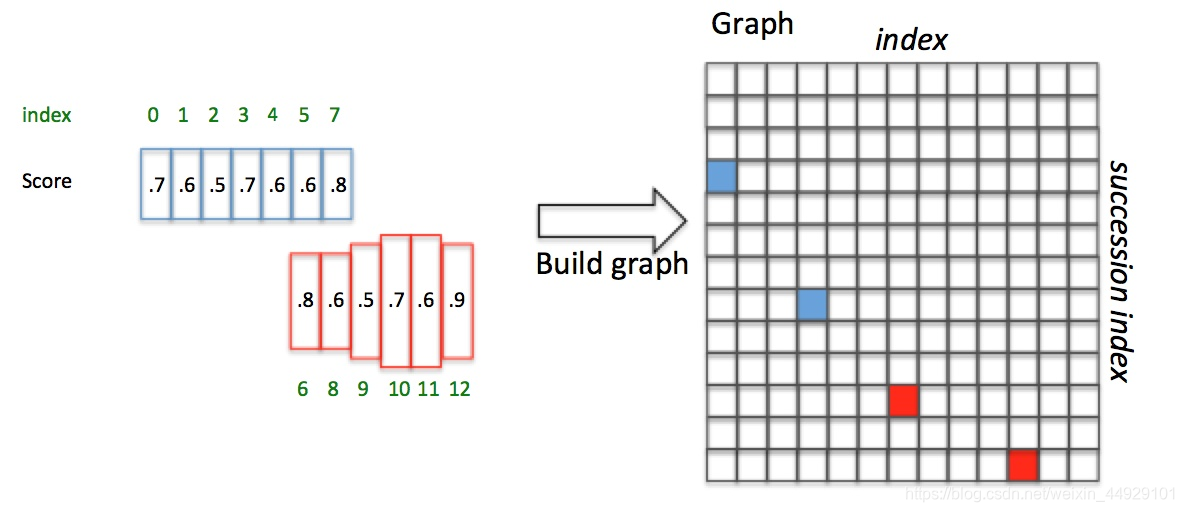
现在我们说一下构造规则:构造分正反两向。
正向寻找:
沿水平正方向,寻找和水平距离小于50的候选Anchor
从候选Anchor中,挑出与竖直方向 overlap>0.7的Anchor
挑出符合条件2中Softmax score最大的 Anchor
再反向寻找:
沿水平负方向,寻找和水平距离小于50的候选Anchor
从候选Anchor中,挑出与竖直方向 overlap>0.7的Anchor
挑出符合条件2中Softmax score最大的Anchor
然后我们就找到了Graph(0,3)和Graph(3,7),我们可以看到他俩的边界是重合的,那么我们把它连接到一起,这样就通过Text proposals确定了文本检测框。同理红色部分也可以这么构成,而且并不是标准的矩形框,所以CTPN可以在一定程度上预测倾斜矩形框。
损失函数
同样我们这块略讲:
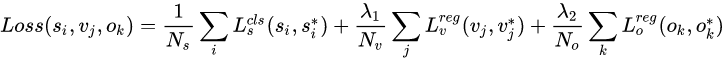
明显可以看出,该Loss分为3个部分:
Anchor Softmax loss:该Loss用于监督学习每个Anchor中是否包含文本。
Anchor y coord regression loss:该Loss用于监督学习每个包含为本的Anchor的Bouding box regression y方向offset,类似于Smooth L1 loss。
Anchor x coord regression loss:该Loss用于监督学习每个包含文本的Anchor的Bouding box regression x方向offset,与y方向同理。前两个Loss存在的必要性很明确,但这个Loss有何作用作者没有解释(从训练和测试的实际效果看,作用不大)
总结
CTPN讲的差不多了,我们关注的是整体原理至于细节我相信大家可以在其他前辈的博客中很好学习,写这个就是为了大家能有个捷径去学习算法,不保证理解深刻但是树立整体框架是个不错选择,在这里向各位前辈致以诚挚敬意。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/20584.html