

- 删除
最简单的方法是删除,删除属性或者删除样本。如果大部分样本该属性都缺失,这个属性能提供的信息有限,可以选择放弃使用该维属性;如果一个样本大部分属性缺失,可以选择放弃该样本。虽然这种方法简单,但只适用于数据集中缺失较少的情况。
*统计填充
对于缺失值的属性,尤其是数值类型的属性,根据所有样本关于这维属性的统计值对其进行填充,如使用平均数、中位数、众数、最大值、最小值等,具体选择哪种统计值需要具体问题具体分析。另外,如果有可用类别信息,还可以进行类内统计,比如身高,男性和女性的统计填充应该是不同的。 - 统一填充
对于含缺失值的属性,把所有缺失值统一填充为自定义值,如何选择自定义值也需要具体问题具体分析。当然,如果有可用类别信息,也可以为不同类别分别进行统一填充。常用的统一填充值有:“空”、“0”、“正无穷”、“负无穷”等。 - 预测填充
我们可以通过预测模型利用不存在缺失值的属性来预测缺失值,也就是先用预测模型把数据填充后再做进一步的工作,如统计、学习等。虽然这种方法比较复杂,但是最后得到的结果比较好。
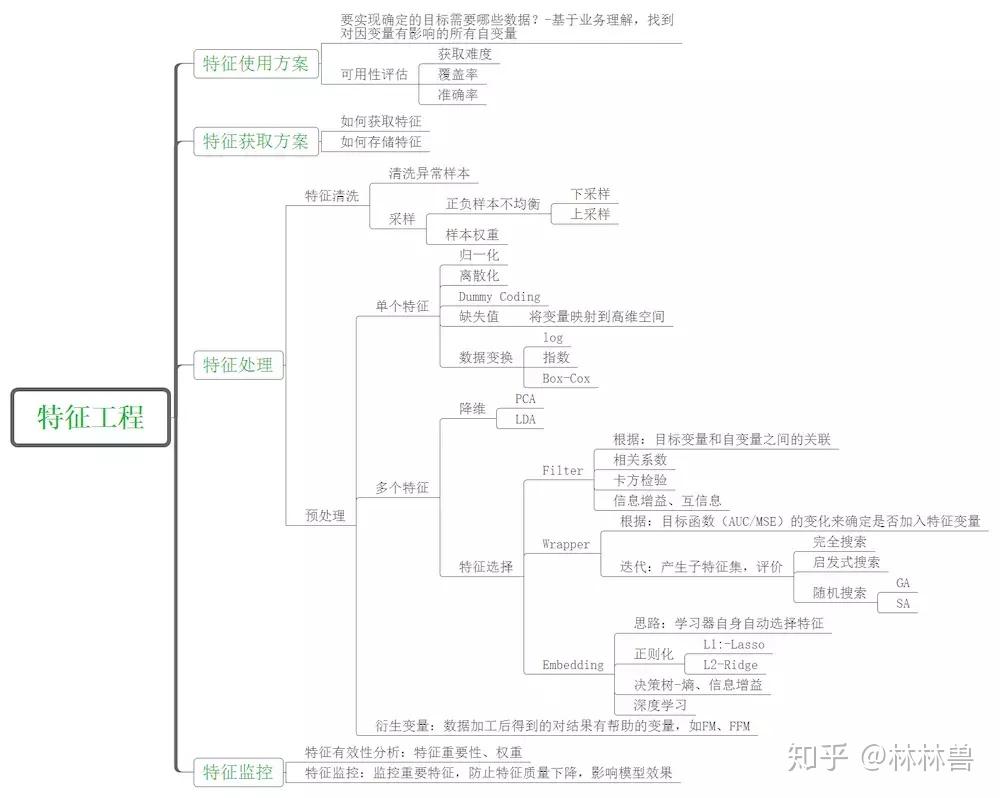
- 特征是否发散:如果一个特征不发散,例如方差接近于0,也就是说样本在这个特征上基本上没有差异,这个特征对于样本的区分并没有什么用。
特征与目标的相关性:这点比较显见,与目标相关性高的特征,应当优选选择。除方差法外,本文介绍的其他方法均从相关性考虑。
根据特征选择的形式又可以将特征选择方法分为3种: - Filter:过滤法,按照发散性或者相关性对各个特征进行评分,设定阈值或者待选择阈值的个数,选择特征。
- Wrapper:包装法,根据目标函数(通常是预测效果评分),每次选择若干特征,或者排除若干特征。
- Embedded:嵌入法,先使用某些机器学习的算法和模型进行训练,得到各个特征的权值系数,根据系数从大到小选择特征。类似于Filter方法,但是是通过训练来确定特征的优劣。
- 使用方差选择法,先要计算各个特征的方差,然后根据阈值,选择方差大于阈值的特征。
- 使用相关系数法,先要计算各个特征对目标值的相关系数以及相关系数的P值。 皮尔森相关系数是一种最简单的,能帮助理解特征和响应变量之间关系的方法,该方法衡量的是变量之间的线性相关性,结果的取值区间为[-1,1],-1表示完全的负相关(这个变量下降,那个就会上升),+1表示完全的正相关,0表示没有线性相关。
- 距离相关系数是为了克服Pearson相关系数的弱点而生的。Pearson相关系数是0,我们也不能断定这两个变量是独立的(有可能是非线性相关);但如果距离相关系数是0,那么我们就可以说这两个变量是独立的。
- 降维度 当特征选择完成后,可以直接训练模型了,但是可能由于特征矩阵过大,导致计算量大,训练时间长的问题,因此降低特征矩阵维度也是必不可少的。常见的降维方法除了以上提到的基于L1惩罚项的模型以外,另外还有主成分分析法(PCA)和线性判别分析(LDA),线性判别分析本身也是一个分类模型。PCA和LDA有很多的相似点,其本质是要将原始的样本映射到维度更低的样本空间中,但是PCA和LDA的映射目标不一样:PCA是为了让映射后的样本具有最大的发散性;而LDA是为了让映射后的样本有最好的分类性能。所以说PCA是一种无监督的降维方法,而LDA是一种有监督的降维方法。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/194313.html