
内核被映射到进程地址空间的意思是,进程页目录有一部分是内核的,实现起来并不难,假设页目录用数组存: pagetable[1024],把内核映射到进程地址空间,只需要直接给 pagetable 部分项赋值为内核页物理地址即可,这只是简单的优化,但带来了很多好处,比如进程陷入内核时,不需要切换为内核页表,进程调度时,不需要为内核线程提供特别的切换代码,并且在x64架构下,对性能有一定的优化,因为陷入内核时不需要刷新 tlb,等等。
最后,不是所有操作系统都会这么做。
内核本质上是一堆代码,想要使用内核代码,必须要知道这些代码的位置。有些进程需要用到内核功能,所以OS会为每一个进程提供映射到内核的地址,方便进程调用。
之所以要特意去分内核代码和普通进程代码(称为用户态),是因为内核涉及到核心功能,直接暴露这些会增加开发的难度以及造成安全和性能问题。
后者虽然比较好,但是由于初学,没有处理器架构相关的知识,会有很多代码,很可能因为太难看不懂。建议先看前者,再看后者。
建议就不要看这么老旧的教材了,里面提到的技术,方法都代表不了现在的OS技术,没法处理像虚拟化,安全模式这些问题。
它的原意是老式的简单系统中,发生中断的时候,CPU寄存器要存到内存中,免得你回不来,但又要切换模式(比如用户到内核),所以硬件就先把堆栈寄存器切换为指定的内核堆栈,然后把比如被中断位置的地址之类的信息压进去,等你恢复回去的时候从这里拿,此外你在OS内部换一个线程的时候,还要切换更多的信息,这些信息没有栈那种层的累加结果,就保存在线程的控制结构中,那个就是你问的进程结构,英文有时叫tcb(任务控制块)。
严格说,栈也是tcb的一部分。
现代CPU根本不会在中断切换的时候中写内存,因为写内存本身又会引起中断(异常),状态机处理太复杂。所以,入门看这种旧东西,只会让你理解错概念,抓不住重点,真不值得。
补充:题主在讨论中似乎对上下文的概念似乎有误解,我解释一下。
题主有必要分开理解线程和进程。
我们一般说调度,说的是线程,进程是附带的。可以这样理解:线程是不同的执行线索,进程是这个执行线索的地址空间。一个进程有多个线程。但每个线程要独占CPU和堆栈,当我们切换线程的时候,我们要把CPU所有运行寄存器全部保存到内存,从而让出CPU,换上另一个线程的寄存器,由于运行寄存器包括堆栈指针,所以堆栈也换了。这些寄存器和相应堆栈等等所有和线程运行相关的东西,我们都叫线程的上下文。由于CPU的寄存器只有一份,线程要分时用它,用不上的线程内容只能在内存里,那个内存就叫tcb。
如果没有进程的概念,上面这个理论就够了,但如果加上进程,进程给线程不同的地址空间,那就相当于换tcb的时候同时换页表,页表也是一个CPU寄存器,只是一般切换线程的时候,如果我们发现没有换进程,我们就不换这个寄存器而已。
x86内核和用户态共享一个页表,只是里面的不同页定义不同的优先级,以便进入内核以后,内核还能访问用户态。现代CPU为了安全,很多是两者各自用自己的页表的。这一点,会引入很多内存地址空间管理上的额外概念,比如保存上下文被分离到多个步骤上,进入内核一个步骤,内核中切换线程又一个步骤等等,但上述逻辑是独立成立的。
最后,纠正题主一个理解:页表在实现的时候一般只需要一个寄存器,不需要一组寄存器说明每个页的位置的。如果每个页都要指定,那不叫页了,那叫段。页是用一个表,说明整个虚拟空间每个固定分块(页)的物理映射。
我的经验是,学操作系统入门最好直接学计算机组成原理。入门后再看操作系统的书,否则你根本不知道它说啥。
学习操作系统前要学会计算机组成原理与数据结构。
《操作系统导论》很不错,强烈推荐。
《现代操作系统 原理与实现》我没看过,不评价。
前言:
在冯诺依曼的 体系结构中,一个进程必须有:代码段,堆栈段,数据段。
内存管理是操作系统的核心功能之一,这对于编程以及系统管理都至关重要。在接下来的叙述中我将着眼于实用方面但兼顾内部原理。这些概念都是通用的,例子大都来源于Linux以及Windows操作系统。首先来描述一下内存中进程的分布。
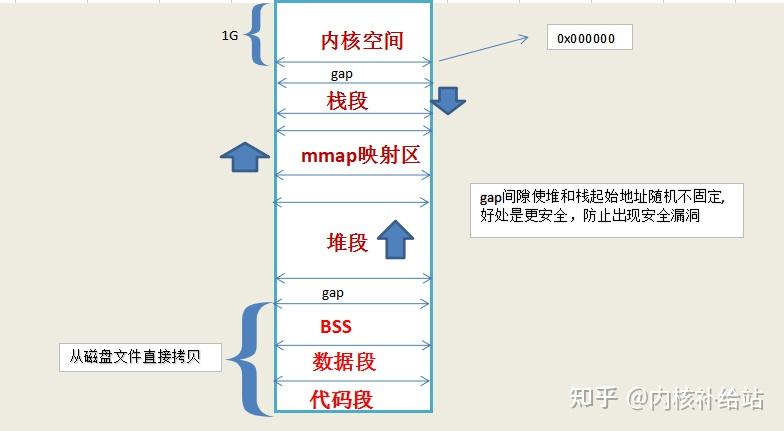
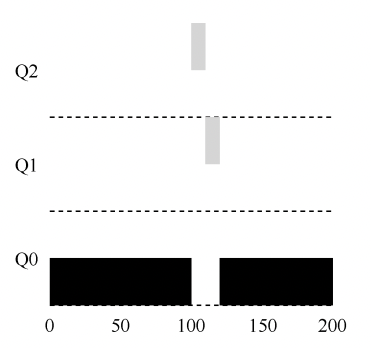
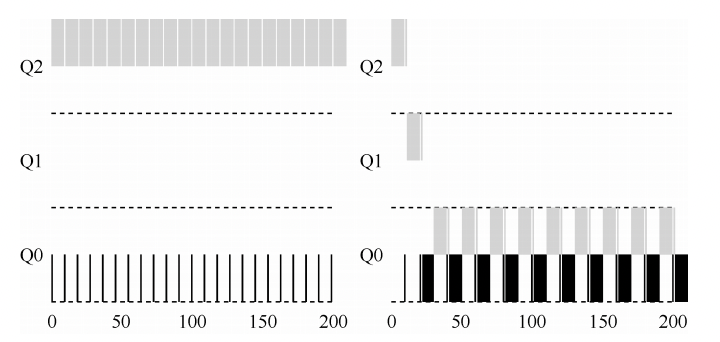
多任务操作系统中进程都运行在各自的地址空间中。在32位系统中进程的地址空间范围是0~2^32 (也即0—4G)。虚拟地址空间通过页表映射到物理内存,页表由操作系统内核维护,由处理器来对其发出请求。每一个进程都有自己的一套页表。这时问题就出现了,一旦虚拟地址投入使用,它就用于此计算机中所有运行的软件,也包括内核本身。所以,虚拟地址空间的一部分必须保留给内核:
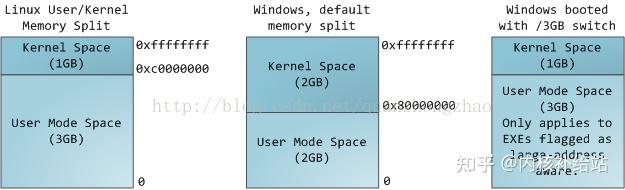
讯享网
这并不意味内核需要使用如此多的物理内存,而是因为内核可以使用这部分地址空间去映射到任何他想要的物理内存。内核空间在页表中被标记为只有特权代码(ring2或者更低。在此说明一下特权等级的概念:Intel x86架构CPU共有四个特权等级,0~3。0级最高,3级最低。硬件在执行每条指令时会检查其特权等级。对于Linux/Unix,只是使用了0级和3级,即Ring0 和 Ring3。在Linux中来看,0级也就表示内核态,3表示用户态)。当用户态程序想染指内核空间时会引发页面异常。在Linux系统中,内核空间总是映射到相同的物理地址空间。
【文章福利】小编推荐自己的Linux内核源码交流群:【 】整理了一些个人觉得比较好的学习书籍、视频资料共享在群文件里面,有需要的可以自行添加哦!!!前50名可进群领取,并额外赠送一份价值600的内核资料包(含视频教程、电子书、实战项目及代码)!
学习直通车:Linux内核源码/内存调优/文件系统/进程管理/设备驱动/网络协议栈
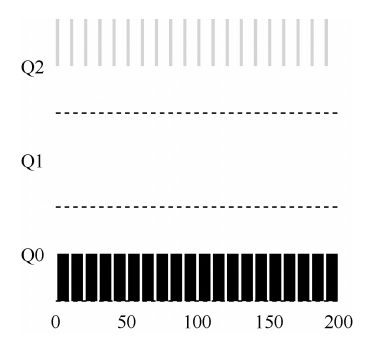
内核代码和数据总是可寻址的,为的是随时准备响应中断或者系统调用。相比之下,进程地址空间的用户态部分随着进程切换而变化。
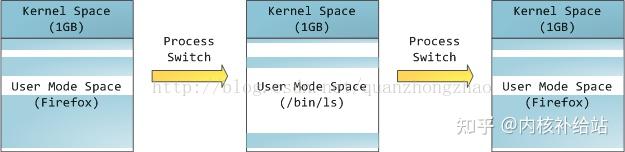
蓝色的部分代表映射到物理内存的虚拟地址空间。而白色的部分表示未映射的地址空间。进程地址空间中不同的段对应内存段(segment)中不同段,比如堆、栈等等。要注意这些所谓的分段只存在于内存地址空间中,他们表示不同的内存地址范围而已,它和Intel的段表机制没有任何关系。 下面是一个标准的Linux进程中各部分在地址空间中的分布:
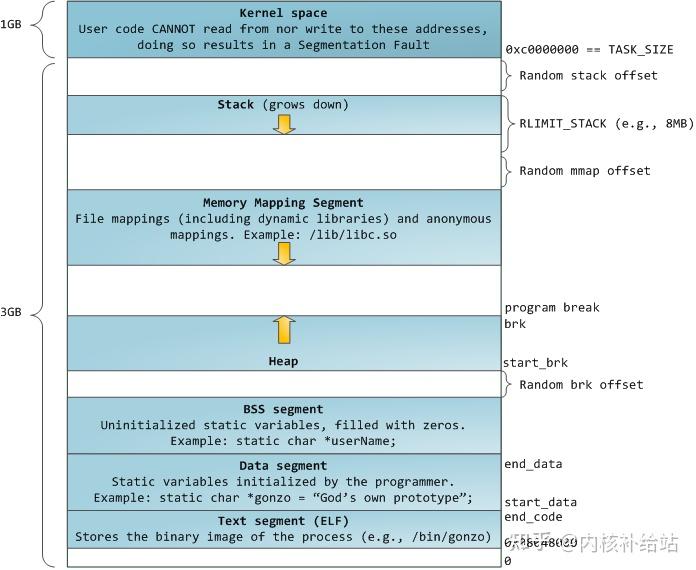
linux中程序结构和进程结构 file 可执行文件如下:
[root@centos1 c]# file getopt_long getopt_long: ELF 64-bit LSB executable, x86-64, version 1 (SYSV), dynamically linked (uses shared libs), for GNU/Linux 2.6.18, not stripped 讯享网
size 可执行程序
查看程序组成部分
讯享网[root@centos1 c]# size getopt_long text data bss dec hex filename 2037 508 56 2601 a29 getopt_long
代码段:
text 主要存放 指令,操作以及只读的(常量)数据(比如字符串常量)
通常是指用来存放程序执行代码的一块内存区域。
这部分区域的大小在程序运行前就已经确定,并且内存区域通常属于只读, 某些架构也允许代码段为可写,即允许修改程序。
在代码段中,也有可能包含一些只读的常数变量,例如字符串常量等
数据段:
data 全局或者静态的已经初始化的变量 数据段属于静态内存分配
bss段:(bss segment)通常是指用来存放程序中未初始化的全局变量的一块内存区域。
BSS 是英文Block Started by Symbol 的简称。BSS 段属于静态内存分配。
全局或者静态的未初始化的变量
#include <stdio.h> #include <stdlib.h> int main(int argc,char *argv[]){讯享网<span class="n">printf</span><span class="p">(</span><span class="s">"hello c</span><span class="se">\n</span><span class="s">"</span><span class="p">);</span> <span class="k">return</span> <span class="mi">0</span><span class="p">;</span>
} [root@centos1 c]# size mem text data bss dec hex filename 1151 492 16 1659 67b mem int i=10; int main(int argc,char *argv[]){ <span class="n">printf</span><span class="p">(</span><span class="s">"hello c</span><span class="se">\n</span><span class="s">"</span><span class="p">);</span> <span class="k">return</span> <span class="mi">0</span><span class="p">;</span>
} [root@centos1 c]# size mem text data bss dec hex filename 1151 496 16 1663 67f mem data端增加了4 #include <stdio.h> #include <stdlib.h> int i=10; static int j; int main(int argc,char *argv[]){ 讯享网<span class="n">printf</span><span class="p">(</span><span class="s">"hello c</span><span class="se">\n</span><span class="s">"</span><span class="p">);</span> <span class="k">return</span> <span class="mi">0</span><span class="p">;</span>
} [root@centos1 c]# size mem text data bss dec hex filename 1151 496 24 1671 687 mem bss段增加到24 进程:linux操作系统最小的资源管理单元
一个进程时执行的程序段
程序在执行时,会动态的申请空间,执行子函数
Linux对一个进程管理采用以下方式
内核空间:
PCB(进程控制块) 结构体 taskstruct,负责管理进程的所有资源
成员 mm_struct 指向这个进程相关的内存资源
mm_struct指向一个结构体
栈
堆
BSS段
数据段
代码段
执行程序时,系统首先在内核空间中创建一个进程,为这个进程申请PCB(进程控制块 task_struct)
用于管理整个进程的所有资源,其中mm_struct成员用来管理与当先进程相关的所有内存资源
1.代码段,数据段,bss段,直接从磁盘拷贝到当前的内存空间,大小相等
2.动态空间
堆,栈空间,mmap段(映射其它库相关的信息)
#include <stdio.h> #include <stdlib.h> int i=10; static int j; int main(int argc,char *argv[]){讯享网<span class="n">printf</span><span class="p">(</span><span class="s">"hello c</span><span class="se">\n</span><span class="s">"</span><span class="p">);</span> <span class="k">while</span><span class="p">(</span><span class="mi">1</span><span class="p">);</span> <span class="k">return</span> <span class="mi">0</span><span class="p">;</span>
} [root@centos1 ]# ps -ef|grep mem root 902 2 0 May20 ? 00:00:02 [vmmemctl] root 28246 27937 98 22:20 pts/0 00:00:29 ./mem root 28271 28249 0 22:21 pts/1 00:00:00 grep mem 一个进程的内存虚拟地址信息列表
[root@centos1 ]# cat /proc/28246/maps 00-00 r-xp 00000000 00:12 33 /mnt/hgfs/www/web/thread/process_thread_study/c/mem 00-00 rw-p 00000000 00:12 33 /mnt/hgfs/www/web/thread/process_thread_study/c/mem 3339e00000-3339e20000 r-xp 00000000 fd:00 /lib64/ld-2.12.so 333a020000-333a021000 r–p 00020000 fd:00 /lib64/ld-2.12.so 333a021000-333a022000 rw-p 00021000 fd:00 /lib64/ld-2.12.so 333a022000-333a023000 rw-p 00000000 00:00 0 333a-333a38a000 r-xp 00000000 fd:00 /lib64/libc-2.12.so 333a38a000-333a58a000 —p 0018a000 fd:00 /lib64/libc-2.12.so 333a58a000-333a58e000 r–p 0018a000 fd:00 /lib64/libc-2.12.so 333a58e000-333a rw-p 0018e000 fd:00 /lib64/libc-2.12.so 333a-333a rw-p 00000000 00:00 0 7f605b8ff000-7f605b rw-p 00000000 00:00 0 7f605b-7f605b rw-p 00000000 00:00 0 7ffce591e000-7ffce rw-p 00000000 00:00 0 [stack] 7ffce59ac000-7ffce59ad000 r-xp 00000000 00:00 0 [vdso] ffffffffff-ffffffffff r-xp 00000000 00:00 0 [vsyscall] 讯享网[root@centos1 ~]# pmap 28246 28246: ./mem 0000000000 4K r-x– /mnt/hgfs/www/web/thread/process_thread_study/c/mem 0000000000 4K rw— /mnt/hgfs/www/web/thread/process_threadstudy/c/mem 0000003339e00000 128K r-x– /lib64/ld-2.12.so 000000333a020000 4K r—- /lib64/ld-2.12.so 000000333a021000 4K rw— /lib64/ld-2.12.so 000000333a022000 4K rw— [ anon ] 000000333a 1576K r-x– /lib64/libc-2.12.so 000000333a38a000 2048K —– /lib64/libc-2.12.so 000000333a58a000 16K r—- /lib64/libc-2.12.so 000000333a58e000 8K rw— /lib64/libc-2.12.so 000000333a 16K rw— [ anon ] 00007f605b8ff000 12K rw— [ anon ] 00007f605b 8K rw— [ anon ] 00007ffce591e000 84K rw— [ stack ] 00007ffce59ac000 4K r-x– [ anon ] ffffffffff 4K r-x– [ anon ] total 3924K
内存映射写时申请
32G平台,一个进程拥有自己的4G虚拟地址空间与其它进程无关
进程和进程之间是相互独立的
进程地址空间的申请
- 代码段,数据段,BSS段,这三个部分直接从磁盘拷贝到内存,起始地址在当前32位平台linux下为0x0地址
- 堆段,动态变化 malloc系列。
- -G”>mmap映射文件(普通文件,也可以是其它类型的文件) 库,用户自己调用mmap函数
- 栈段
- 高地址1G空间供内核映射处理,用户空间不能直接处理
对和栈的其实地址默认是随机产生的,其目的是避免安全漏洞,但是可以指定堆中申请的起始地址
brk(系统调用)/sbrk (库函数)
#include <unistd.h> int brk(void addr); //指定下次申请堆空间的起始地址为addr void sbrk(intptr_t increment);//在当前的地址位置后移increment字节,如果为0返回当前值 讯享网#include <stdio.h> #include <stdlib.h> int i=10; int main(int argc,char *argv[]){<span class="n">brk</span><span class="p">(</span><span class="mh">0xc76000</span><span class="p">);</span> <span class="n">printf</span><span class="p">(</span><span class="s">"sbrk return:%p</span><span class="se">\n</span><span class="s">"</span><span class="p">,</span><span class="n">sbrk</span><span class="p">(</span><span class="mi">0</span><span class="p">));</span> <span class="kt">char</span> <span class="o">*</span><span class="n">ptr</span><span class="o">=</span><span class="n">malloc</span><span class="p">(</span><span class="mi">32</span><span class="p">);</span> <span class="n">printf</span><span class="p">(</span><span class="s">"new malloc:%p</span><span class="se">\n</span><span class="s">"</span><span class="p">,</span><span class="n">ptr</span><span class="p">);</span> <span class="k">return</span> <span class="mi">0</span><span class="p">;</span>
}
讯享网[root@centos1 c]# ./brk sbrk return:0xc76000 new malloc:0xc76010
原文参考:一文搞懂Linux进程结构内存分布是怎样的 - 进程管理 - 我爱内核网 - 构建全国最权威的内核技术交流分享论坛
往期精彩回顾:
超细节!十年码农讲述Linux网络新技术基石——eBPF and XDP
玩转腾讯首发Linux内核源码《嵌入式开发笔记》,也许能帮到你哦
什么?2022届秋招已经正式拉开了帷幕!不看就会后悔
如何正确理解Linux iNode
Linux内核进程状态源码分析

没看过前者,后者确实挺好的。认真读完,就可以自己从0写出一个简单基本的操作系统。不过对初学者可能会有点困难。另外《x86汇编语言 从实模式到保护模式》这本书对《操作系统真象还原》保护模式部分是一个很好的补充。
没看过前后者,俩者确实挺好的。
初学者还是建议看 具体的操作系统理论,比如linux操作系统概念,或linux内核设计与实现等这类,windows不适合初学者,那本深入解析windows太庞大,还是建议从linux入手比较顺。坚持一个月看完足够了!剩下的还是先从开发入手,这样才能加深理解和记忆,等到一定程度,觉得你行了的时候,再去看厚厚的理论包括比如x86 x64处理器,保护模式这些重点知识,然后再这个基础上去研究别的系统怎么利用芯片写那些内存管理,进程线程,调试机制,系统调用与中断等,不然你一开始是很愣逼的,哪怕学完操作系统基础也不行,必须先入门后,去搞开发,到觉得可以了,再返回去继续看真正的底层。
大家好,我是飞哥!
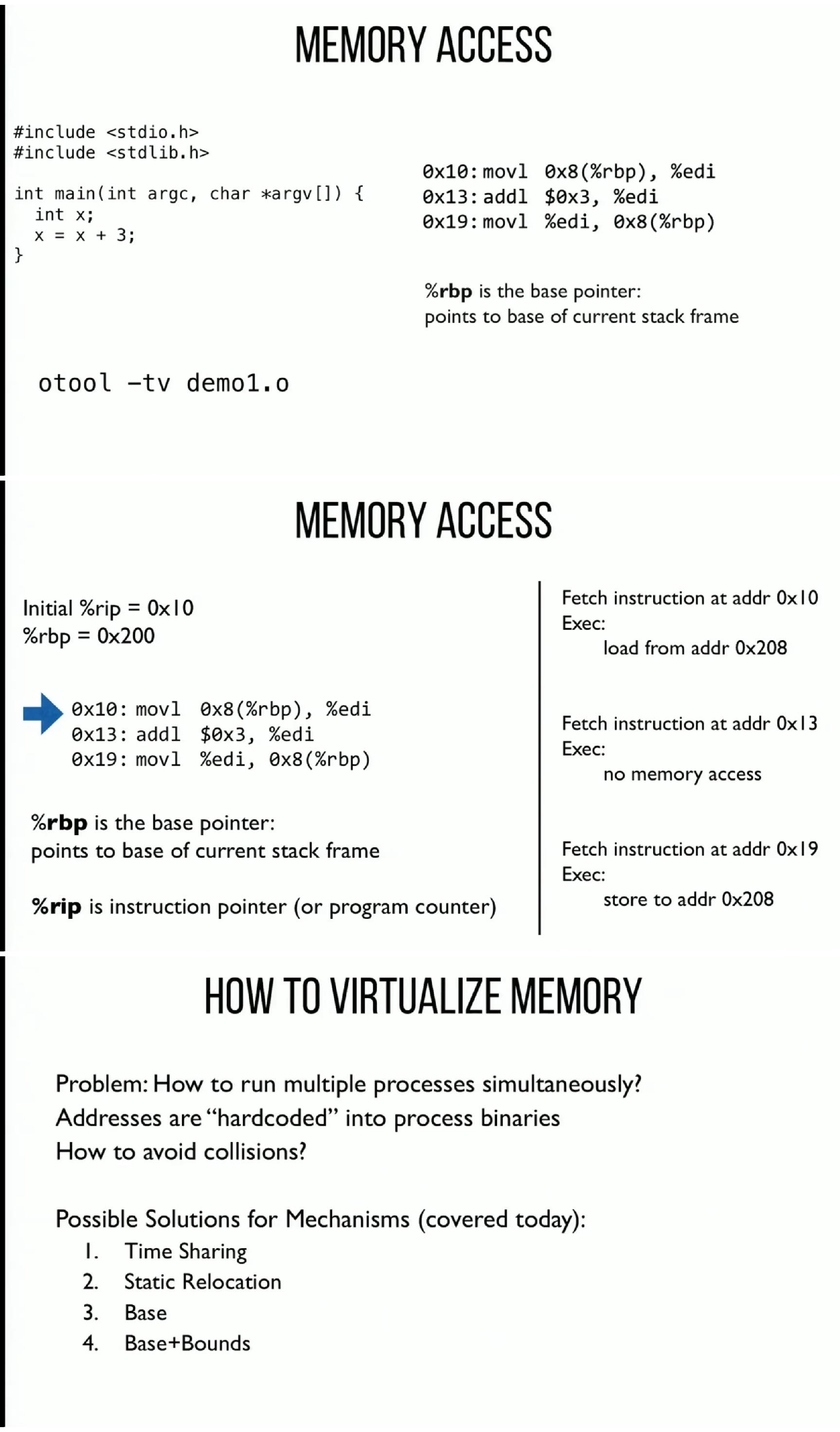
栈是编程中使用内存最简单的方式。例如,下面的简单代码中的局部变量 n 就是在堆栈中分配内存的。
#include <stdio.h> void main() { int n = 0; printf(“0x%x\n”,&v); }那么我有几个问题想问问大家,看看大家对于堆栈内存是否真的了解。
- 堆栈的物理内存是什么时候分配的?
- 堆栈的大小限制是多大?这个限制可以调整吗?
- 当堆栈发生溢出后应用程序会发生什么?
如果你对以上问题还理解不是特别深刻,飞哥今天来带你好好修炼进程堆栈内存这块的内功!我所有技术文章都先在公Z号首发,想及时收获最新推送的同学请关注公众号「开发内功修炼」。另外我历史所有文章都在github在这里汇总https://github.com/yanfeizhang/coder-kung-fu。
前面我们在《你写的代码是如何跑起来的?》这篇文章中介绍了进程的启动过程。我们今天来专门抽取并看一下这段逻辑。
加载系统调用 execve 依次调用 do_execve、do_execve_common 来完成实际的可执行程序加载。
讯享网//file:fs/exec.c static int do_execve_common(const char filename, …) { bprm_mm_init(bprm); … }
在 bprm_mm_init 中会申请一个全新的地址空间 mm_struct 对象,准备留着给新进程使用。
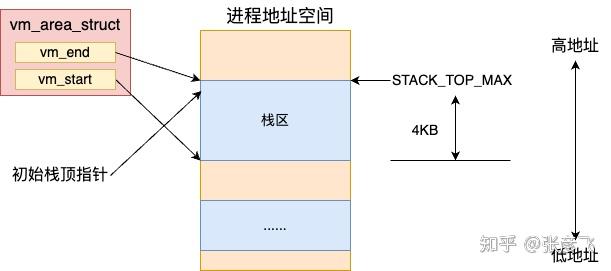
//file:fs/exec.c static int bprm_mm_init(struct linux_binprm bprm) { //申请个全新的地址空间 mm_struct 对象 bprm->mm = mm = mm_alloc(); bprm_mm_init(bprm); }还会给新进程的栈申请一页大小的虚拟内存空间,作为给新进程准备的栈内存。申请完后把栈的指针保存到 bprm->p 中记录起来。
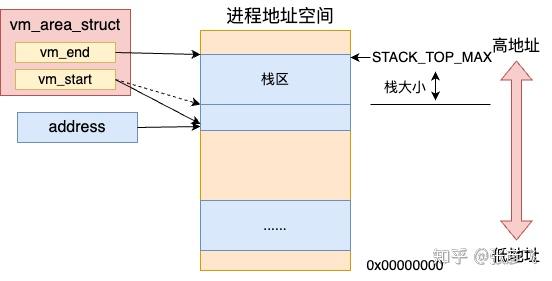
讯享网//file:fs/exec.c static int bprm_mm_init(struct linux_binprm *bprm) { bprm->vma = vma = kmem_cache_zalloc(vm_area_cachep, GFP_KERNEL); vma->vm_end = STACK_TOP_MAX; vma->vm_start = vma->vm_end - PAGE_SIZE; …bprm->p = vma->vm_end - sizeof(void ); }
我们平时所说的进程虚拟地址空间在 Linux 是通过一个个的 vm_area_struct 对象来表示的。
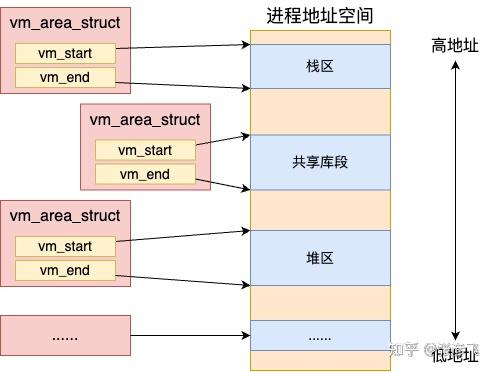
每一个 vm_area_struct(就是上面 __bprm_mm_init 函数中的 vma)对象表示进程虚拟地址空间里的一段范围,其 vm_start 和 vm_end 表示启用的虚拟地址范围的开始和结束。
//file:include/linux/mm_types.h struct vm_area_struct { unsigned long vm_start; unsigned long vm_end; … }要注意的是这只是地址范围,而不是真正的物理内存分配。
在上面 __bprm_mm_init 函数中通过 kmem_cache_zalloc 申请了一个 vma 内核对象。vm_end 指向了 STACK_TOP_MAX(地址空间的顶部附近的位置),vm_start 和 vm_end 之间留了一个 Page 大小。 也就是说默认给栈准备了 4KB 的大小。最后把栈的指针记录到 bprm->p 中。
接下来进程加载过程会使用 load_elf_binary 真正开始加载可执行二进制程序。在加载时,会把前面准备的进程栈的地址空间指针设置到了新进程 mm 对象上。
讯享网//file:fs/binfmt_elf.c static int load_elf_binary(struct linux_binprm bprm) { //ELF 文件头解析 //Program Header 读取 //清空父进程继承来的资源 retval = flush_old_exec(bprm); …current->mm->start_stack = bprm->p; }
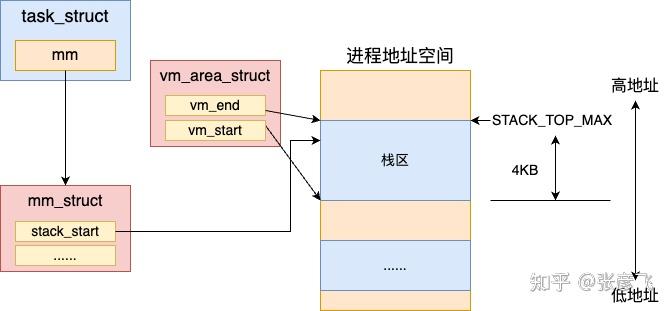
这样新进程将来就可以使用栈进行函数调用,以及局部变量的申请了。
前面我们说了,这里只是给栈申请了地址空间对象,并没有真正申请物理内存。我们接着再来看一下,物理内存页究竟是什么时候分配的。
当进程在运行的过程中在栈上开始分配和访问变量的时候,如果物理页还没有分配,会触发缺页中断。在缺页中断种来真正地分配物理内存。
为了避免篇幅过长,触发缺页中断的过程就先不展开了。我们直接看一下缺页中断的核心处理入口 do_page_fault,它位于 arch/x86/mm/fault.c 文件下。
//file:arch/x86/mm/fault.c static void kprobes __do_page_fault(struct pt_regs *regs, unsigned long error_code) { … //根据新的 address 查找对应的 vma vma = find_vma(mm, address);//如果找到的 vma 的开始地址比 address 小 //那么就不调用expand_stack了,直接调用 if (likely(vma->vm_start <= address)) goto good_area; … if (unlikely(expand_stack(vma, address))) { bad_area(regs, error_code, address); return; } good_area: //调用handle_mm_fault来完成真正的内存申请 fault = handle_mm_fault(mm, vma, address, flags); }当访问栈上变量的内存的时候,首先会调用 find_vma 根据变量地址 address 找到其所在的 vma 对象。接下来调用的 if (vma->vm_start <= address) 是在判断地址空间还够不够用。
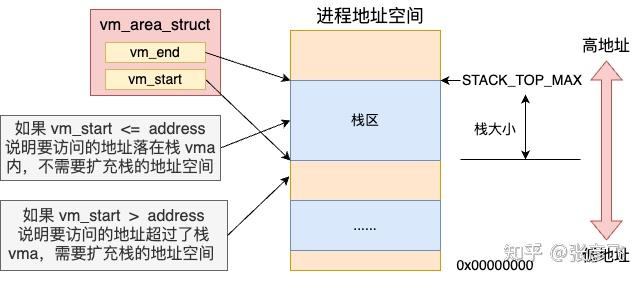
如果栈内存 vma 的 start 比要访问的 address 小,则证明地址空间够用,只需要分配物理内存页就行了。 如果栈内存 vma 的 start 比要访问的 address 大,则需要调用 expand_stack 先扩展一下栈的虚拟地址空间 vma。扩展虚拟地址空间的具体细节我们在第三节再讲。
这里先假设要访问的变量地址 address 处于栈内存 vma 对象的 vm_start 和 vm_end 之间。那么缺页中断处理就会跳转到 good_area 处运行。在这里调用 handle_mm_fault 来完成真正物理内存的申请。
讯享网//file:mm/memory.c int handle_mm_fault(struct mm_struct mm, struct vm_area_struct vma, unsigned long address, unsigned int flags) { …//依次查看每一级页表项 pgd = pgd_offset(mm, address); pud = pud_alloc(mm, pgd, address); pmd = pmd_alloc(mm, pud, address); pte = pte_offset_map(pmd, address); return handle_pte_fault(mm, vma, address, pte, pmd, flags); }
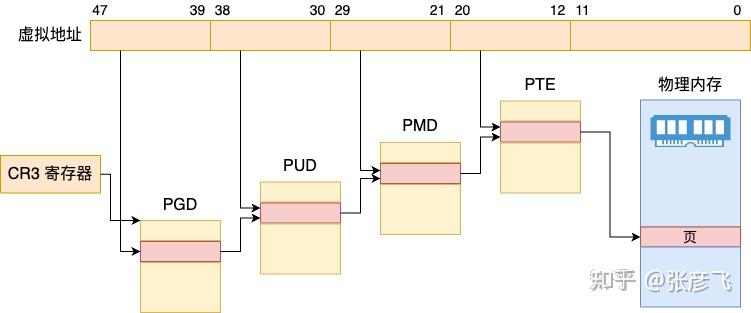
Linux 是用四级页表来管理虚拟地址空间到物理内存之间的映射管理的。所以在实际申请物理页面之前,需要先 check 一遍需要的每一级页表项是否存在,不存在的话需要申请。
为了好区分,Linux 还给每一级页表都起了一个名字。
- 一级页表:Page Global Dir,简称 pgd
- 二级页表:Page Upper Dir,简称 pud
- 三级页表:Page Mid Dir,简称 pmd
- 四级页表:Page Table,简称 pte
看一下下面这个图就比较好理解了
//file:mm/memory.c int handle_pte_fault(struct mm_struct *mm,讯享网<span class="k">struct</span> <span class="n">vm_area_struct</span> <span class="o">*</span><span class="n">vma</span><span class="p">,</span> <span class="kt">unsigned</span> <span class="kt">long</span> <span class="n">address</span><span class="p">,</span> <span class="n">pte_t</span> <span class="o">*</span><span class="n">pte</span><span class="p">,</span> <span class="n">pmd_t</span> <span class="o">*</span><span class="n">pmd</span><span class="p">,</span> <span class="kt">unsigned</span> <span class="kt">int</span> <span class="n">flags</span><span class="p">)</span>
{ … //匿名映射页处理 return do_anonymous_page(mm, vma, address, <span class="n">pte</span><span class="p">,</span> <span class="n">pmd</span><span class="p">,</span> <span class="n">flags</span><span class="p">);</span>
}在 handle_pte_fault 会处理很多种的内存缺页处理,比如文件映射缺页处理、swap缺页处理、写时复制缺页处理、匿名映射页处理等等几种情况。我们今天讨论的主题是栈内存,这个对应的是匿名映射页处理,会进入到 do_anonymous_page 函数中。
讯享网//file:mm/memory.c static int do_anonymous_page(struct mm_struct mm, struct vm_area_struct vma, unsigned long address, pte_t page_table, pmd_t pmd, unsigned int flags) { // 分配可移动的匿名页面,底层通过 alloc_page page = alloc_zeroed_user_highpage_movable(vma, address); … }
在 do_anonymous_page 调用 alloc_zeroed_user_highpage_movable 分配一个可移动的匿名物理页出来。在底层会调用到伙伴系统的 alloc_pages 进行实际物理页面的分配。
内核是用伙伴系统来管理所有的物理内存页的。其它模块需要物理页的时候都会调用伙伴系统对外提供的函数来申请物理内存。
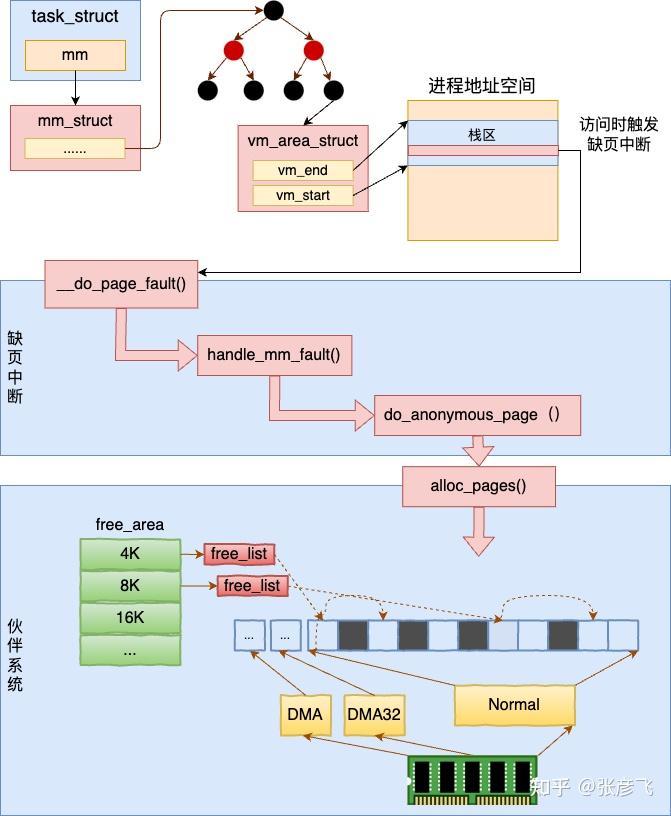
关于伙伴系统我们之前在内核内存管理 这篇文章中详细介绍过,感兴趣的同学可以移步到该文中详细了解。
到了这里,开篇的问题一就有答案了,堆栈的物理内存是什么时候分配的?进程在加载的时候只是会给新进程的栈内存分配一段地址空间范围。而真正的物理内存是等到访问的时候触发缺页中断,再从伙伴系统中申请的。
前面我们看到了,进程在被加载启动的时候,栈内存默认只分配了 4 KB 的空间。那么随着程序的运行,当栈中保存的调用链,局部变量越来越多的时候,必然会超过 4 KB。
我回头看下缺页处理函数 __do_page_fault。如果栈内存 vma 的 start 比要访问的 address 大,则需要调用 expand_stack 先扩展一下栈的虚拟地址空间 vma。
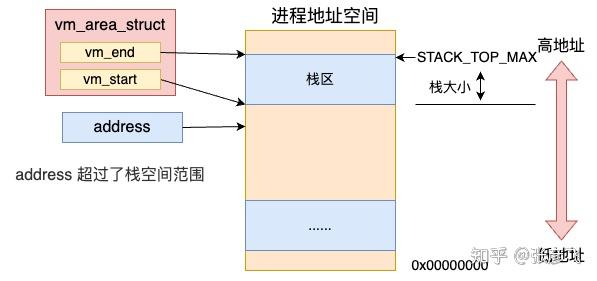
回顾 do_page_fault 源码,看到扩充栈空间的是由 expand_stack 函数来完成的。
//file:arch/x86/mm/fault.c static void kprobes __do_page_fault(struct pt_regs *regs, unsigned long error_code) { … if (likely(vma->vm_start <= address)) goto good_area;//如果栈 vma 的开始地址比 address 大,需要扩大栈 if (unlikely(expand_stack(vma, address))) { bad_area(regs, error_code, address); return; } good_area: … }我们来看下 expand_stack 的内部细节。
其实在 Linux 栈地址空间增长是分两种方向的,一种是从高地址往低地址增长,一种是反过来。大部分情况都是由高往低增长的。本文只以向下增长为例。
讯享网//file:mm/mmap.c int expand_stack(struct vm_area_struct *vma, unsigned long address) { … return expand_downwards(vma, address); }int expand_downwards(struct vm_area_struct *vma, unsigned long address) { … //计算栈扩大后的最后大小 size = vma->vm_end - address; //计算需要扩充几个页面 grow = (vma->vm_start - address) >> PAGE_SHIFT; //判断是否允许扩充 acct_stack_growth(vma, size, grow); //如果允许则开始扩充 vma->vm_start = address; return … }
在 expand_downwards 中先进行了几个计算。
- 计算出新的堆栈大小。计算公式是 size = vma->vm_end - address;
- 计算需要增长的页数。计算公式是 grow = (vma->vm_start - address) >> PAGE_SHIFT;
然后会判断此次栈空间是否被允许扩充, 判断是在 acct_stack_growth 中完成的。如果允许扩展,则简单修改一下 vma->vm_start 就可以了!
我们再来看 acct_stack_growth 都进行了哪些限制判断。
//file:mm/mmap.c static int acct_stack_growth(struct vm_area_struct *vma, unsigned long size, unsigned long grow) { … //检查地址空间是否超出限制 if (!may_expand_vm(mm, grow)) return -ENOMEM;//检查是否超出栈的大小限制 if (size > ACCESS_ONCE(rlim[RLIMIT_STACK].rlim_cur)) return -ENOMEM; … return 0; }在 acct_stack_growth 中只是进行一系列的判断。may_expand_vm 判断的是增长完这几个页后是否超出整体虚拟地址空间大小的限制。rlim[RLIMIT_STACK].rlim_cur 中记录的是栈空间大小的限制。这些限制都可以通过 ulimit 命令查看到。
讯享网# ulimit -a …… max memory size (kbytes, -m) unlimited stack size (kbytes, -s) 8192 virtual memory (kbytes, -v) unlimited
上面的这个输出表示虚拟地址空间大小没有限制,栈空间的限制是 8 MB。如果进程栈大小超过了这个限制,会返回 -ENOMEM。如果觉得系统默认的大小不合适可以通过 ulimit 命令修改。
# ulimit -s 10240 # ulimit -a stack size (kbytes, -s) 10240至于开篇的问题3,当堆栈发生溢出后应用程序会发生什么?写个简单的无限递归调用就知道了,估计你也遇到过。报错结果就是
讯享网‘Segmentation fault (core dumped)
来总结下本文的内容,本文讨论了进程栈内存的工作原理。
第一,进程在加载的时候给进程栈申请了一块虚拟地址空间 vma 内核对象。vm_start 和 vm_end 之间留了一个 Page ,也就是说默认给栈准备了 4KB 的空间。
第二,当进程在运行的过程中在栈上开始分配和访问变量的时候,如果物理页还没有分配,会触发缺页中断。在缺页中断中调用内核的伙伴系统真正地分配物理内存。
第三,当栈中的存储超过 4KB 的时候会自动进行扩大。不过大小要受到限制,其大小限制可以通过 ulimit -s来查看和设置。
注意,今天我们讨论的都是进程栈。线程栈和进程栈有些不一样。等后面有空我们再单独看线程栈。
真像还原挺棒的 , 第一章列了很多问题 和答案讲得很棒 , 后面还手把手教怎么写mbr , 可以动手把写好的mbr 写到U盘 , 然后启动电脑 , 在操作系统启动前 , 打出一个 hello world , 第一次干这事别提有多开心了. 这本书最大的优点就是详细 , 非常的详细(好几千页) , 不会错过任何细节 , 如果你想亲手写一个操作系统那就看这本,如果你只是想了解操作系统,那这本书大量的细节会让你发疯。
如果你只是想了解操作系统原理而不是亲自上手写就选操作系统导论 , 这本书中文版本才500页, 英文版也才700多页 , 比较言简意赅 , 直击要害 , 其实两本配合着看挺好的
《操作系统导论》,一本被名字耽误的操作系统好书,本以为非常难啃,实际读下来发现深入浅出,还是比较容易理解的,整本书围绕三个话题。
- 虚拟化(CPU的时分调度,内存虚拟化)
- 并发(操作系统并发原语介绍)
- 持久化(磁盘,以及文件系统的原理性介绍)
作者讲这些技术点的思路也比较友好,从提出问题,到简单解决方案,到最后我们现在看到的操作系统的原理,由浅入深,将操作系统这支程序的功能以及设计理念讲的非常好,如下是根据学习过程做的一张思维导图,有兴趣的朋友看一看下。
对于程序员来说,虽然不了解操作系统的原理同样也可以写代码,做产品,但我们从事的计算机行业,写的代码,脚本,发布的服务,APP,无一例外都是需要操作系统作为载体来运行的,因此我觉得操作系统可以作为内功来修炼,我们使用的各种编程语言也无一例外最终是使用了操作同提供的能力,比如我们平时使用的多线程开发中的Lock,ULock,我们直到它可以限制同一个线程通过操作一块数据,当我们学习了操作系统时候,再结合变成语言的内部实现,我们发现,哦,原来底层使用了 信号量,这样我们的知识体系会变得更加立体,完整,才能在写代码的时候有一种一切尽在掌握的感觉,而不是打开百度,google,搜索,复制,粘贴,能跑就行。
更新 2023-10-12
最近在学习 javascript 的生成器函数,主要是 es6 中引入的异步编程解决方案,其代码大致是这样子的。
function * gen(){讯享网<span class="nx">data11</span> <span class="o">=</span> <span class="k">yield</span> <span class="nx">readfile</span><span class="p">(</span><span class="s2">"11.txt"</span><span class="p">)</span> <span class="nx">data12</span> <span class="o">=</span> <span class="k">yield</span> <span class="nx">readfile</span><span class="p">(</span><span class="s2">"12.txt"</span><span class="p">,</span> <span class="nx">data11</span><span class="p">)</span> <span class="nx">data</span> <span class="o">=</span> <span class="k">yield</span> <span class="nx">readfile</span><span class="p">(</span><span class="s2">"13.txt"</span><span class="p">,</span> <span class="nx">data12</span><span class="p">)</span> <span class="nx">console</span><span class="p">.</span><span class="nx">log</span><span class="p">(</span><span class="nx">data</span><span class="p">)</span>
} let p = gen() p.next() 该函数每次调用 next 的时候,会执行函数中的一段代码,然后遇到 yield 则暂停,那么结合操作系统中 cpu 的调度,yield 就是让用户近程主动去释放 cpu 资源,将 cpu 的权限交还给操作系统,当时JavaScript肯定不会这么生硬,因为本身就是一个单线程的运行环境,这里的实现更像是 go 中的 goroutine 一样,协goroutine是一种函数的泛化,相比函数,协程可以多次的挂起和恢复运行,并且可以主动让出cpu,具备让cpu来调度的特性,因此可以用于实现并发,不同的是,javascript 使用这种方法来解决单线程环境下的异步编程问题,go 使用这种方法来解决多线程环境下的并发问题,有点意思。
有段时间我一直在寻找计算机操作系统相关的经典书籍,但很多书籍要么年代久远要么晦涩难懂,直到偶然间发现了这本《操作系统:原理与实现》,有种如获至宝的感觉。

通读之后发现,本书有如下优点:①内容比较新,以linux5.x为例进行讲解;②基于ARM指令集架构,更容易实践;③增加了教学版微内核chcore作为课后练习,学以致用,更易掌握。
这里还是要说明一下,为什么要学习操作系统呢?首先肯定是因为好奇心和求知欲,想搞清楚它的来龙去脉;其次,操作系统中涉及数据结构、算法、组成原理、编码等多个方面,如果操作系统搞通了,其它的技术很快就能上手,有点像武侠小说中的内功心法“九阳神功”;最后,针对嵌入式的场景可能需要修改和剪裁内核,必须对操作系统有个整体了解。
废话不多说,下面开始吧~
什么是操作系统呢?要想直接给出一个明确的定义其实不是很容易。
可以先回顾一下我们平时接触到的操作系统:PC上的windows、macOS,服务器上的redHat、centos、ubuntu等,手机和平板上的安卓Android、iOS等,这些都是操作系统。概括起来它们都有两个职责:①对硬件进行管理和抽象;②为应用软件提供服务并进行管理。
首先理解职责①:对硬件的管理和抽象。这里的硬件包括CPU/内存/磁盘/键盘/网卡等,操作系统可以将这些硬件设备纳入统一的管理。抽象是说,操作系统可以将有限的、离散的资源转化为无限的、连续的资源。例如,应用程序无需关心物理内存的硬件型号和容量大小,而是面向一个统一的、近似无限的虚拟地址空间进行编程;当用户打印文件时,不需要考虑不同型号打印机硬件的差异,只需要点击“打印”按钮即可。
再来理解职责②:为应用软件提供服务并进行管理。提供服务是说为应用程序提供了各种不同层次、不同功能的接口,例如访问控制、应用间交互等。管理应用软件是说对应用软件的生命周期进行管理,包括加载、启动、切换、调度、销毁等。通过管理,操作系统可以从全局进行资源调配,保证应用程序间的公平性、性能与安全隔离。
| 既然操作系统可以管理和服务应用软件,那么应用软件可以将操作系统搞死吗?可以看下面的例子============test.c============= #include #include int main() { while(1) { fork(); } } ============================== fork()是一个复制进程的函数,一直复制是否能把操作系统资源耗尽呢?运行该程序之后,发现仍然可以通过ctrl+c终止程序,但执行命令ls,提示资源不足。 # ls -bash: fork: retry: Resource temporarily unavailable -bash: fork: retry: Resource temporarily unavailable -bash: fork: retry: Resource temporarily unavailable 可见,虽然该程序没有将计算彻底搞死,但是却严重影响了其他程序的运行。操作系统既要最大化整体资源的利用率,又要尽量满足单个进程的需求,有时是矛盾的。 |
|---|
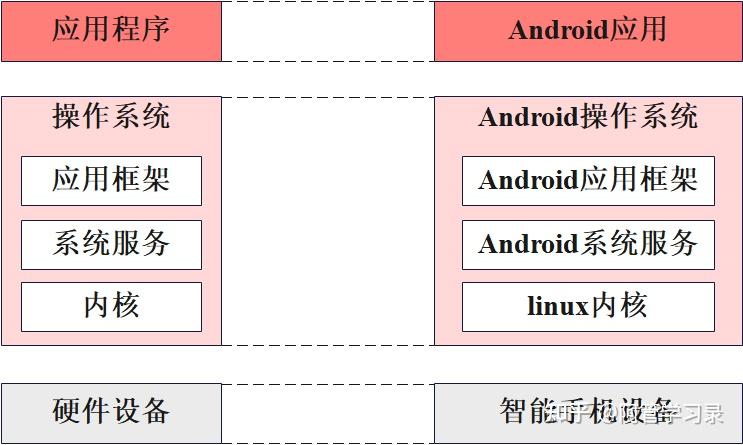
从上面可以看出,操作系统的两个职责分别是对下(硬件)和对上(应用)的,当硬件和应用发生变化时,操作系统也要随之调整。因此操作系统在演进的过程中产生了一种新的形态:操作系统内核+操作系统框架的组合。内核常用于实现通用的、相对稳定的功能;框架则更灵活,面向不同的场景进行适配。操作系统框架进一步分为系统服务与应用框架,前者实现对操作系统内核抽象与管理能力的扩展,后者基于系统服务实现对应用开发与运行所需共性功能的增强。例如,安卓Android操作系统就是这种结构,如下图。
1946年2月14日,世界公认的第一台通用计算机诞生于美国宾夕法尼亚大学。早期的计算机采用纸带的方式记录要计算的任务,并通过打孔的纸带或磁带接收输出的结果,因此需要有个“操作员”进行操作。
1956年,Robert L. Patrick和Owen Mock在IBM704上是实现了第一个实际使用的操作系统GM-NAA I/O(General Motors and North American Aviation Input/Output System)。该系统主要是对输出和输出的自动化管理,由于该系统解放了“操作员”,因此该系统就被称作“操作系统”,操作系统的名字由此而来。GM-NAA I/O是一个批处理操作系统。
1964年,美国IBM公司发布了名为IBM System/360的大型机。该计算机实现了两大突破①通过定义指令集架构,将计算机架构与实现进行解耦。②将操作系统与底层硬件解耦,从而进入通用操作系统时代。
Multics起源于1964年开始的由通用电气和麻省理工联合发起的Multics项目。该项目的目标是实现一套多用户、多任务、多层次的操作系统,Multics的理念非常先进:使用了分时的概念,首次将文件与内存进行分离,也提出了文件系统、动态链接、CPU/内存/硬盘等硬件热替换、特权级分层、命令处理器等开创性概念。由于理念过于超前,该项目最终因为进展缓慢,被迫终止。其实哪怕是到60年后的今天有些功能依然未能实现。这里不禁想起一句话:“领先一步是先进,领先两步是先烈!”。
参与过Multics项目的贝尔实验室工程师Ken Thompson,因为想移植一套名为“太空旅游”的游戏,利用休假时间,经过4周的奋斗,以汇编语言写出UNIX内核程序,还包括一些内核工具程序以及一个小的文件系统。UNIX中引入了shell,可以通过命令行解释器执行不同的计算任务,并且支持管道(pipe)等进程间通信方式。随后Dennis Ritchie于1972~1973年设计实现了C语言,并用C语言重写了UNIX。后来,UNIX和C语言逐渐成为大家熟知的操作系统和编程语言。
由于UNIX系统版权复杂且收费,人们一直难以拥有一款公开且允许自由使用的操作系统。尽管荷兰自由大学的Andrew S. Tanenbaum教授在1987年开源了用于教学版的MINIX操作系统,由于商用版权不友好,仍不能被自由使用。1991年,来自荷兰的年轻人Linus Torvalds在吸收了MINIX精华的基础上,发布了Linux操作系统,此系统已经成为目前世界上最成功、使用范围最广的开源操作系统。
我发现,有时候伟大的发明并不来自宏大的愿景与高强度的努力,而是带着轻松、娱乐的属性。
之前提到的操作系统,主要通过shell命令行进行操作,这对于普通用户是不友好的。
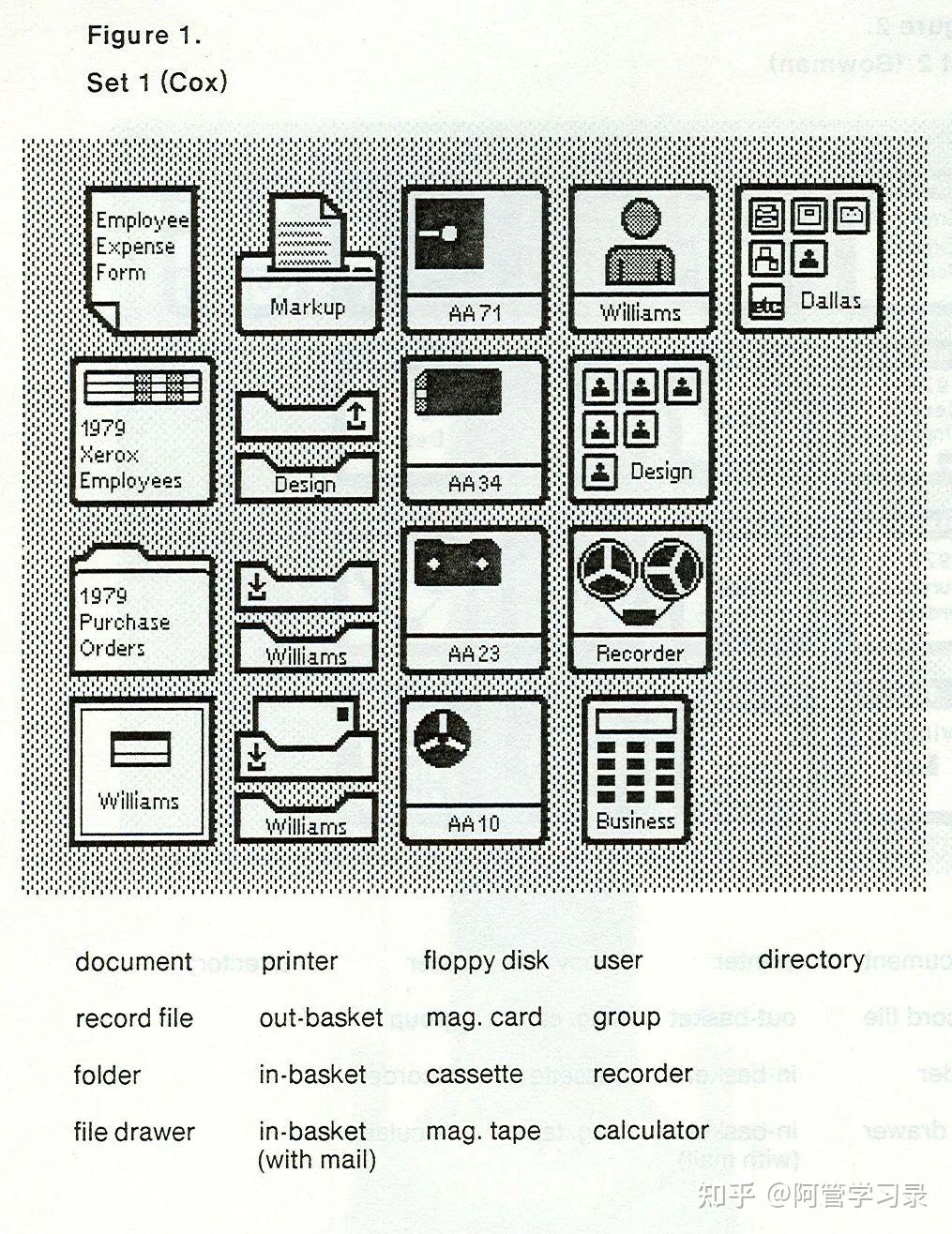
最早的有图形用户界面(GUI)操作系统出现在1973年施乐公司Xerox PARC的Alto计算机中,Xerox Alto引入了桌面的概念,是世界上第一台个人计算机。其界面已经有了现代桌面操作系统的雏形,如下图所示。
1979年,苹果公司的创始人Steve Jobs访问了Xerox PARC,意识到GUI的重要性,开始开发面向图形化的操作系统,并且在1983年发布了Apple Lisa个人桌面计算机,也就是后来著名的Macintosh系列个人计算机。
苹果公司个人计算机大获成功后,微软公司的创始人Bill Gates也意识到图形用户界面的重要性,投入重兵开发了基于图形界面的操作系统Windows。
这里有个小插曲,据说Steve Jobs曾当面斥责Bill Gates偷盗与山寨了他的技术,Bill Gates则给出了一段非常经典的回答“我们都有个有钱的邻居,叫施乐,我闯进他们家准备偷电视机的时候,发现你已经把它偷走了。”这也开启了苹果和微软长达十多年的法律纠纷。
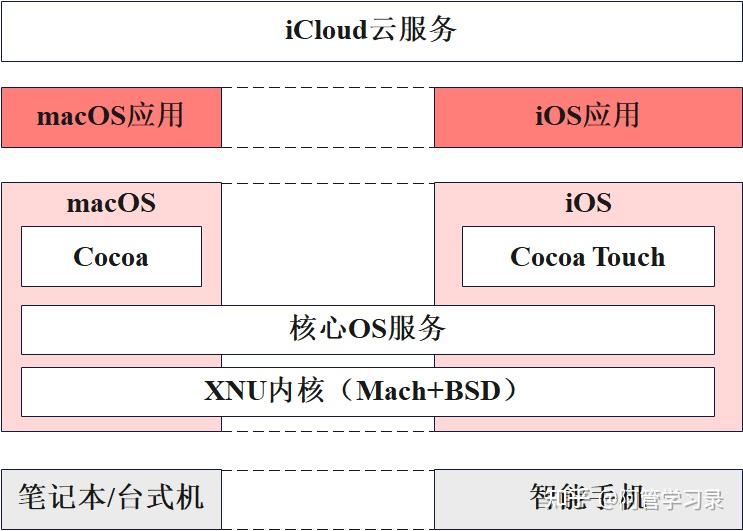
2007年,Steve Jobs发布了第一代iPhone,标志着 iOS操作系统的诞生。iOS的设计很大程度上复用了macOS的功能(如下图),包括XNU操作系统内核(有Mach微内核和BSD内核叠加构成的混合内核),以及一些核心OS服务,并将macOS的应用程序框架(Cocoa)针对iPhone等触屏设备进行了重新设计与优化,形成了面向智能手机的应用程序框架Cocoa Touch。
2005年,谷歌公司收购了Andy Rubin主导设计的Android操作系统,并在此基础上发布了Android1.0操作系统。Android采用开源的方式构建生态,加上谷歌联合34家芯片制造商、网络运行商、手机制造商与应用开发者成立开放手机联盟(Open handset Alliance,OHA),使得Android逐步在移动互联网时代的操作系统中占据主流地位。
①趋势1:从封闭到开发,再到封闭。
操作系统并不是免费的午餐,而是构筑与控制生态的黑土地。
例如,2018年10月起,谷歌正式对欧盟区域的Android进行收费,初步高达40美元每设备。
②趋势2:从专用到通用,再到专用(领域定制)
操作系统的类型和数量均会大幅增加。
原因主要包括:当下传统操作系统不能满足实时、安全、可信等需求;通用计算走向领域计算,各种xPU层出不穷;智能存储、存算一体、持久内存、内存与持久存储走向融合;数据中心Infiniband等网络走向纳秒级延迟;广域网络,5G大连接、低时延、高可靠高吞吐、低时延广域计算。
这些新型硬件发展需要新的操作系统抽象与设计来充分释放算力。
此外,智能驾驶、智能家庭等新场景也需要新的操作系统。
③趋势3:从简单到复杂,到更复杂
现如今,linux代码规模已超过2000万行,每年仍然以200万行的速度增加或更新。这么庞大的规模,真是令人望而生畏。
即使读完本书,做完课后所有的实验,也不能自信地说懂操作系统。
最后赠送物理学家费曼的一句话:
“What I cannot create, I do not understand”讯享网 ——Richard P. Feynman</code></pre></div><p data-pid="jGakW1Xk">参考资料</p><p data-pid="olLs98iy">[1]https://www.bilibili.com/video/BV1BEzp=2&vd_source=35b20cf24ef5a1961e9723c932</p><hr/><p data-pid="nmiOntSA"><b>本文来自微信公众号:阿管学习录</b></p><p data-pid="9tWRgHMv"><b>持续更新学习的新知识......欢迎关注~</b></p>
os系统设计学习的关键:指针与寄存器不仅仅是高级语言中的变量和结构地址或者是表达思想的工具,而是cpu控制硬件的方式:寄存器=IO,指针=内存

初学者,需要言简意赅,《导论》吧。原书作者亲自授课:cs537—网上可以查到视频相关的讲义:https://canvas.wisc.edu/courses//files/folder/Slides
时钟中断,cpu分时,流水线,缓存,虚拟内存,控制硬件。指令集—OS—汇编-ABI虚拟化,并发,持久性相关的调度策略和资源共享机制。
对应的课程国外的是:MIT6.004(计算机专业必听课程)或者南京大学袁春风老师的计算机系统基础(南大袁老师课程缺少了数字逻辑的设计的讲解)
cs537—网上可以查到视频听过课①很多书里不容易理解的地方都得到了解决②书的作者讲解的思路可以得到很多重新的认识:计算机发展的逻辑与历史的结合。问题—思路/方法—新问题:这个循环直到现在计算机
学完这本书,可以直接再去做MIT的os或者哈工大李治军老师的都好进入实操了。
计算进专业学习是难的!
学习是什么?就是不断问问题-解问题,而且问的问题不断的变化的过程!https://dzone.com/articles/word-count-hello-word-program-in-mapreducegithub都进化成这个模样了么?这个是一个例子
https://github.com/XiaochenCui/mit6.824/blob/battle/src/mapreduce/schedule.goHIT OS: Operating System
三个重要的东西
- 虚拟化——cpu的虚拟化(多个程序并发运行),内存的虚拟化(进程自己有自己的内存空间)
- 并行化——互斥
- 持久性——数据储存到系统-通过系统调用
进程的组成
- 指令和数据
- 寄存器
- 持久存储设备如文件列表
进程加载的过程通过将代码和静态数据加载到内存中,通过创建和初始化栈和堆以及执行与I/O设置相关的其他工作,OS现在(终于)为程序执行搭好了舞台。然后它有最后一项任务:启动程序,在入口处运行,即main()。通过跳转到main()例程(第5章讨论的专门机制),OS将CPU的控制权转移到新创建的进程中,从而程序开始执行。
进程状态
进程的数据结构pcb和context(寄存器)
Fork函数新创建的子进程不会从main()函数开始执行,而是直接从fork()系统调用返回,就好像是它自己调用了fork()。但是它从fork()返回的值是不同的。父进程获得的返回值是新创建子进程的PID,而子进程获得的返回值是0。
Exec()函数给定可执行程序的名称(如wc)及需要的参数(如p3.c)后,exec()会从可执行程序中加载代码和静态数据,并用它覆写自己的代码段(以及静态数据),堆、栈及其他内存空间也会被重新初始化。然后操作系统就执行该程序,将参数通过argv传递给该进程。它并没有创建新进程,而是直接将当前运行的程序(以前的p3)替换为不同的运行程序(wc)。子进程执行exec()之后,几乎就像p3.c从未运行过一样。对exec()的成功调用永远不会返回。
如此设计的原因可以实现一些有趣的功能,shell在fork之后exec之前运行代码的机会,这些代码可以在运行新程序前改变环境,从而让一系列有趣的功能很容易实现:
- 实现重定向,当完成子进程的创建后,shell调用exec()之前先关闭了标准输出(standard output),打开了文件newfile.txt。
- 在shell中执行程序。shell可以在文件系统中找到这个可执行程序,调用fork()创建新进程,并调用exec()的某个变体来执行这个可执行程序,调用wait()等待该命令完成。子进程执行结束后,shell从wait()返回并再次输出一个提示符,等待用户输入下一条命令。
虚拟化CPU的基本思想很简单:运行一个进程一段时间,然后运行另一个进程,如此轮换,以这种方式时分共享(time sharing)CPU,就实现了虚拟化。因此就有两个问题:第一个是性能:如何在不增加系统开销的情况下实现虚拟化?第二个是控制权:如何有效地运行进程,同时保留对CPU的控制?控制权对于操作系统尤为重要,因为操作系统负责资源管理。
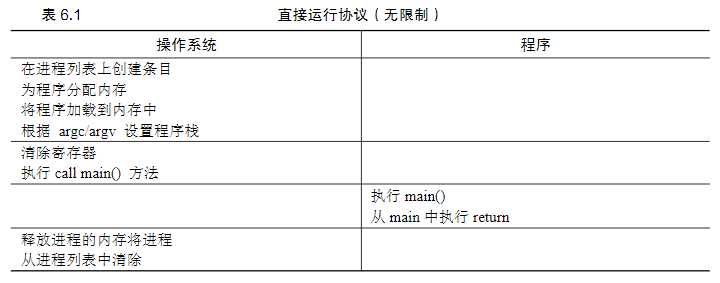
为了使程序尽可能快地运行,操作系统开发人员想出了一种技术——我们称之为受限的直接执行(limited direct execution)。
这个概念的“直接执行”部分很简单:只需直接在CPU上运行程序即可。因此,当OS希望启动程序运行时,它会在进程列表中为其创建一个进程条目,为其分配一些内存,将程序代码从磁盘加载到内存中,找到程序入口,跳转到那里,并开始运行用户的代码。,使用正常的调用并返回跳转到程序的main(),并在稍后回到内核。
但是出现了以下问题:第一个问题:如果我们只运行一个程序,操作系统怎么能确保程序不做任何我们不希望它做的事,同时仍然高效地运行它?第二个问题:当我们运行一个进程时,操作系统如何让它停下来并切换到另一个进程,从而实现虚拟化CPU所需的时分共享?
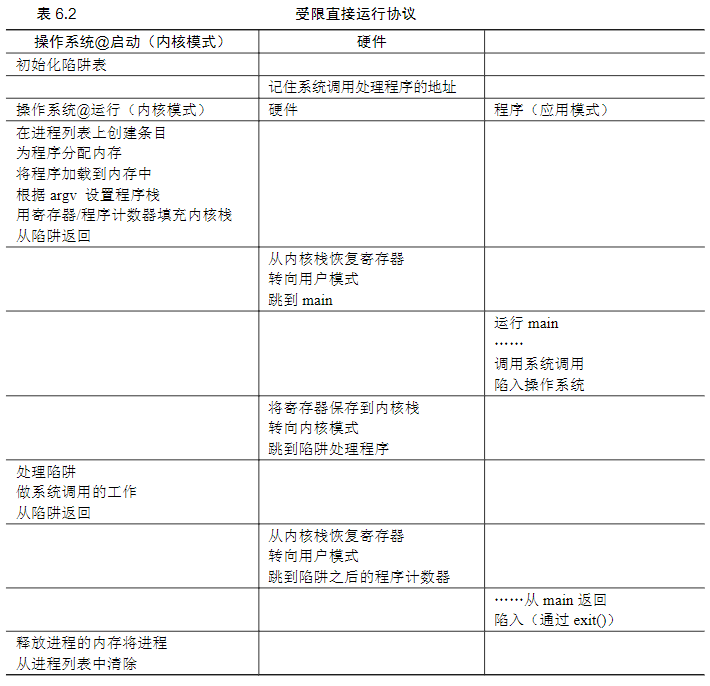
因此就是题目说的,受限制的操作,要加上一些限制。第一个问题的解决方法是:引入一种新的处理器模式,称为用户模式,在用户模式下运行的代码会受到限制。在用户模式下运行时,进程不能发出I/O请求,而操作系统(或内核)运行在内核模式下,代码可以做它喜欢的事,包括特权操作,如发出I/O请求和执行所有类型的受限指令当用户希望执行某种特权操作,可以通过系统调用,执行特殊的陷阱(trap)指令实现。该指令同时跳入内核并将特权级别提升到内核模式。一旦进入内核,系统就可以执行任何需要的特权操作(如果允许),从而为调用进程执行所需的工作。完成后,操作系统调用一个特殊的从陷阱返回指令,该指令返回到发起调用的用户程序中,同时将特权级别降低,回到用户模式。执行陷阱时,硬件必须确保存储足够的调用者寄存器,以便在操作系统发出从陷阱返回指令时能够正确返回。例如,在x86上,处理器会将程序计数器、标志和其他一些寄存器推送到每个进程的内核栈(kernel stack)上。从返回陷阱将从栈弹出这些值,并恢复执行用户模式程序。
陷阱如何知道在OS内运行哪些代码?内核通过在启动时设置陷阱表(trap table)来实现。当机器启动时,它在特权(内核)模式下执行,操作系统利用特权操作告诉硬件在发生某些异常事件时要运行哪些代码。一旦硬件被通知,它就会记住这些处理程序的位置,直到下一次重新启动机器,并且硬件知道在发生系统调用和其他异常事件时要做什么(即跳转到哪段代码)。
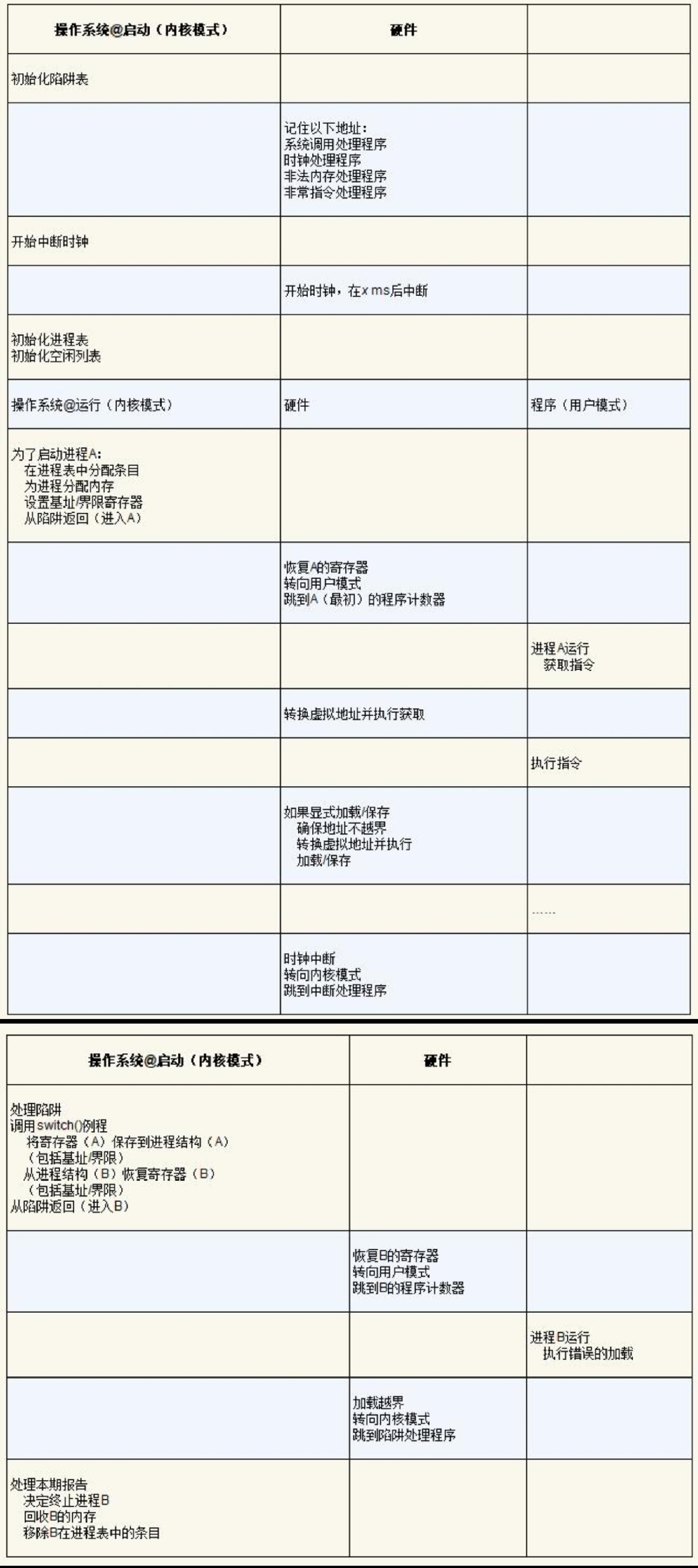
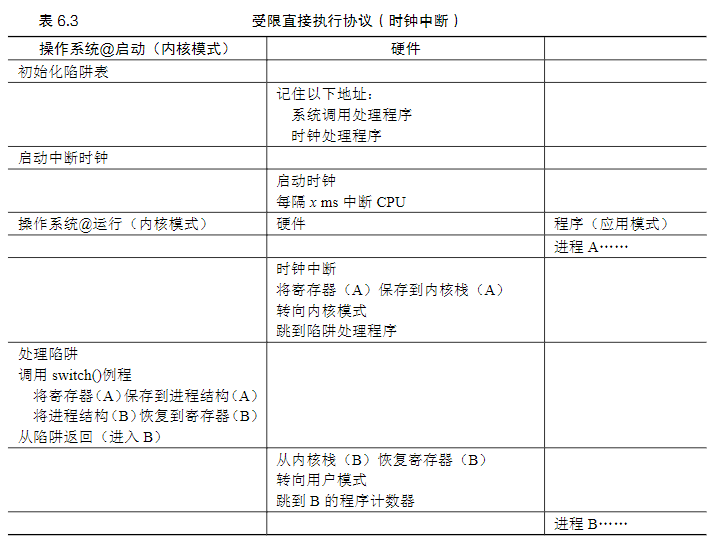
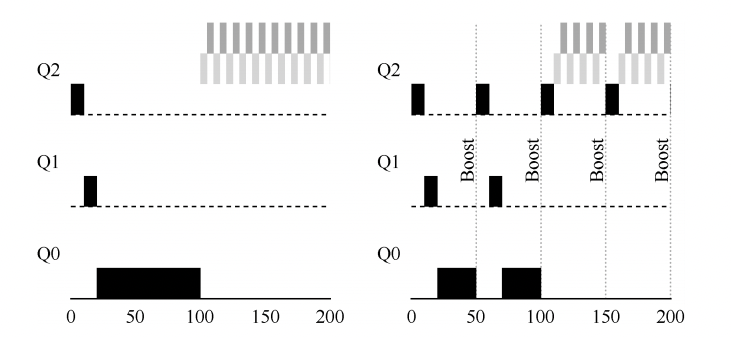
第二个问题是进程的切换操作系统利用时间中断获得CPU的控制权(regain control),并通过调度程序决定是切换进程还是继续执行进程产生时间中断时,当前正在运行的进程停止,操作系统中预先配置的中断处理程序会运行。此时,操作系统重新获得CPU的控制权,因此可以停止当前进程,并启动另一个进程。首先操作系统必须通知硬件哪些代码在发生时钟中断时运行,然后是启动时钟中断,一项特权操作。硬件在发生中断时要为正在运行的程序保存足够的状态(上下文),以便随后从陷阱返回指令能够正确恢复正在运行的程序(与硬件在显式系统调用陷入内核时的行为非常相似),这样一来,操作系统就可以确保最后执行从陷阱返回指令时,不是返回到之前运行的进程,而是继续执行另一个进程。
上下文切换:为当前正在执行的进程保存一些寄存器的值(例如,到它的内核栈),并为即将执行的进程恢复一些寄存器的值(从它的内核栈)。为了保存当前正在运行的进程的上下文,操作系统会执行一些底层汇编代码,来保存通用寄存器、程序计数器,以及当前正在运行的进程的内核栈指针,然后恢复寄存器、程序计数器,并切换内核栈,供即将运行的进程使用。通过切换栈,内核在进入切换代码调用时,是一个进程(被中断的进程)的上下文,在返回时,是另一进程(即将执行的进程)的上下文。当操作系统最终执行从陷阱返回指令时,即将执行的进程变成了当前运行的进程。至此上下文切换完成。
在上面的例子中,进程A正在运行,然后被中断时钟中断。硬件保存它的寄存器(在内核栈中),并进入内核(切换到内核模式)。在时钟中断处理程序中,操作系统决定从正在运行的进程A切换到进程B。此时,它调用switch()例程,该例程仔细保存当前寄存器的值(保存到A的进程结构),恢复寄存器进程B(从它的进程结构),然后切换上下文(switch context),具体来说是通过改变栈指针来使用B的内核栈(而不是A的)。最后,操作系统从陷阱返回,恢复B的寄存器并开始运行它。
注意在此协议中,有两种类型的寄存器保存/恢复:
- 第一种是发生时钟中断的时候。在这种情况下,运行进程的用户寄存器由硬件隐式保存,使用该进程的内核栈。
- 第二种是当操作系统决定从A切换到B。在这种情况下,内核寄存器被软件(即OS)明确地保存,但这次被存储在该进程的进程结构的内存中。后一个操作让系统从好像刚刚由A陷入内核,变成好像刚刚由B陷入内核。
调度指标周转时间,指的是完成任务的时间响应时间,响应时间= T首次运行−T到达时
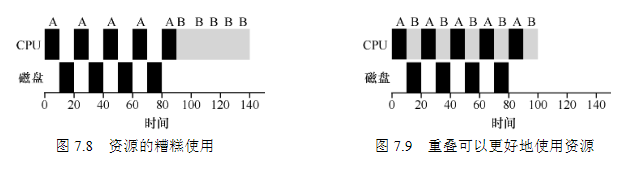
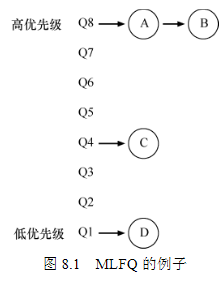
调度算法先进先出(FIFO),缺点就是效率低。最短任务优先(SJF),先运行最短的任务,然后是次短的任务,和下一个进行对比。缺点是长任务容易引饥饿最短完成时间优先(STCF),向SJF添加抢占,每当新工作进入系统时,它就会确定剩余工作和新工作中,谁的剩余时间最少,然后调度该工作。轮转(Round-Robin,RR)调度,在一个时间片(time slice,有时称为调度量子,scheduling quantum)内运行一个工作,然后切换到运行队列中的下一个任务,可以通过增大时间片来摊销切换上下文的成本(上下文切换时间为1ms,可以把时间片增加到100ms。在这种情况下,不到1%的时间用于上下文切换)结合IO来设计调度举个例子有两项工作A和B,每项工作需要50ms的CPU时间。A运行10ms,然后发出I/O请求(假设I/O每个都需要10ms),而B只是使用CPU 50ms,不执行I/O。调度程序先运行A,然后运行B(见图7.8)。一种常见的方法是将A的每个10ms的子工作视为一项独立的工作。因此,当系统启动时,它的选择是调度10ms的A,还是50ms的B。对于STCF,选择是明确的:选择较短的一个,在这种情况下是A。然后,A的工作已完成,只剩下B,并开始运行。然后提交A的一个新子工作,它抢占B并运行10ms。这样做可以实现重叠(overlap),一个进程在等待另一个进程的I/O完成时使用CPU,系统因此得到更好的利用)。
总结任何公平的政策(如RR),在周转时间这类指标上表现不佳,因为周转时间只关心作业何时完成,RR几乎是最差的,在很多情况下甚至比简单的FIFO更差。因此问题就是要么注重周转时间,要么注重响应时间。一般操作系统通常对每个作业的长度知之甚少因此,我们如何建立一个没有这种先验知识的SJF/STCF?更进一步,我们如何能够将已经看到的一些想法与RR调度程序结合起来,以便响应时间也变得相当不没?稍后,我们将看到如何通过构建一个调度程序,利用最近的历史预测未来,从而解决这个问题。
注意:上下文切换的成本不仅仅来自保存和恢复少量寄存器的操作系统操作。程序运行时,它们在CPU高要缓存、TLB、分支预测器和其他片上硬件中建立了大量的状态。切换到另一个工作会导致此状态被刷新,且与当前运行的作业相关的新状态被引入。
本章介绍了一种调度方式,名为多级反馈队列(MLFQ)。你应该已经知道它为什么叫这个名字——它有多级队列,并通过观察工作的运行来给出对应的优先级。通过这种方式,MLFQ可以同时满足各种工作的需求:对于短时间运行的交互型工作,获得类似于SJF/STCF的很好的全局性能,同时对长时间运行的CPU密集型负载也可以公平地、不断地稳步向前。
多级反馈队列需要解决的是,如何优化响应时间和周转时间。首先,它要优化周转时间,通过先执行短工作来实现,但是操作系统通常不知道工作要运行多久。其次,优化响应时间,但是像轮转这样的算法虽然降低了响应时间,周转时间却很差。
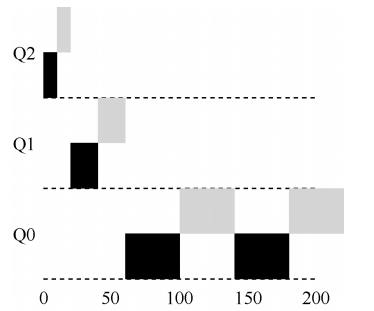
MLFQMLFQ中有许多独立的队列(queue),每个队列有不同的优先级(priority level)。任何时刻,一个工作只能存在于一个队列中。MLFQ总是优先执行较高优先级的工作(即在较高级队列中的工作),具有同样的优先级的工作采用轮转调度。
至此,我们得到了MLFQ的两条基本规则。规则1:如果A的优先级 > B的优先级,运行A(不运行B)。规则2:如果A的优先级 = B的优先级,轮转运行A和B
只有这两条容易出问题:低优先级的没有机会运行,如下。
因此加入了新的规则规则3:工作进入系统时,放在最高优先级(最上层队列)。规则4a:工作用完整个时间片后,降低其优先级(移入下一个队列)。规则4b:如果工作在其时间片以内主动释放CPU,则优先级不变。举例子:
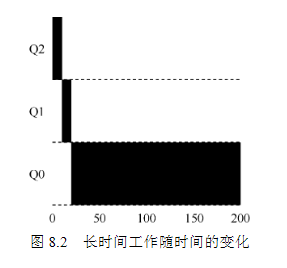
例子1:从上面图可以看出,该工作首先进入最高优先级(Q2)。执行一个10ms的时间片后,调度程序将工作的优先级减1,因此进入Q1。在Q1执行一个时间片后,最终降低优先级进入系统的最低优先级(Q0),然后一直留在那里。
例子2:上图中,A是一个长时间运行的CPU密集型工作,B是一个运行时间很短的交互型工作。假设A执行一段时间后B到达。A(用黑色表示)在最低优先级队列执行(长时间运行的CPU密集型工作都这样)。B(用灰色表示)在时间T=100时到达,并被加入最高优先级队列。由于它的运行时间很短(只有20ms),经过两个时间片,在被移入最低优先级队列之前,B执行完毕。然后A继续运行(在低优先级)。
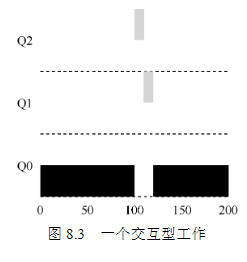
例子3:看一个有I/O的例子。根据上述规则4b,如果进程在时间片用完之前主动放弃CPU,则保持它的优先级不变。交互型工作B(用灰色表示)每执行1ms便需要进行I/O操作,它与长时间运行的工作A(用黑色表示)竞争CPU。MLFQ算法保持B在最高优先级,因为B总是让出CPU。如果B是交互型工作,MLFQ就进一步实现了它的目标,让交互型工作快速运行。这条规则的意图很简单:假设交互型工作中有大量的I/O操作(比如等待用户的键盘或鼠标输入),它会在时间片用完之前放弃CPU。在这种情况下,我们不想处罚它,只是保持它的优先级不变。
可以看出这个算法的一个主要目标:如果不知道工作是短工作还是长工作,那么就在开始的时候假设其是短工作,并赋予最高优先级。如果确实是短工作,则很快会执行完毕,否则将被慢慢移入低优先级队列,而这时该工作也被认为是长工作了。通过这种方式,MLFQ近似于SJF。
但是这样会有问题:
- 如果系统有“太多”交互型工作,就会不断占用CPU,导致长工作永远无法得到CPU(它们饿死了)。
- 如果一个进程在时间片用完之前,调用一个I/O操作(比如访问一个无关的文件),从而主动释放CPU。如此便可以保持在高优先级,占用更多的CPU时间。做得好时(比如,每运行99%的时间片时间就主动放弃一次CPU),工作可以几乎独占CPU。
- 一个程序可能在不同时间表现不同。一个计算密集的进程可能在某段时间表现为一个交互型的进程。用我们目前的方法,它不会享受系统中其他交互型工作的待遇。
因此要对上面的规则进行添加和修改规则4:一旦工作用完了其在某一层中的时间配额(无论中间主动放弃了多少次CPU),就降低其优先级(移入低一级队列)。规则5:经过一段时间S,就将系统中所有工作重新加入最高优先级队列。
新规则解决了上面的问题:
- 进程不会饿死——在最高优先级队列中,它会以轮转的方式,与其他高优先级工作分享CPU,从而最终获得执行。如果一个CPU密集型工作变成了交互型,当它优先级提升时,调度程序会正确对待它。
- S的值应该如何设置?如果S设置得太高,长工作会饥饿;如果设置得太低,交互型工作又得不到合适的CPU时间比例。
- 只要进程用完了自己的配额,进程也无法长时间独占CPU。
当然这里也有很多问题:
- 规则5中的时间段S应该怎么设置?
- 如何配置一个调度程序,例如,配置多少队列?每一层队列的时间片配置多大?为了避免饥饿问题以及进程行为改变,应该多久提升一次进程的优先级?
这些问题都没有显而易见的答案,因此只有利用对工作负载的经验,以及后续对调度程序的调优,才会导致令人满意的平衡。至于别的系统的实现可以去文献中的论文看看。
本章介绍了比例份额调度的概念,并简单讨论了两种实现:彩票调度和步长调度。首先介绍一个不同类型的调度程序——比例份额(proportional-share)调度程序,有时也称为公平份额(fair-share)调度程序。
具体的做法:彩票数(ticket)代表了进程(或用户或其他)占有某个资源的份额,每隔一段时间,都会举行一次彩票抽奖,以确定接下来应该运行哪个进程。
举个例子,假设进程A拥有0到74共75张彩票,进程B拥有75到99的25张,中奖的彩票就决定了运行A或B。调度程序然后加载中奖进程的状态,并运行它。
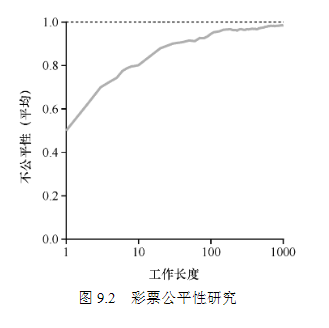
当工作执行时间很短时,平均不公平度非常糟糕。只有当工作执行非常多的时间片时,彩票调度算法才能得到期望的结果。
彩票调度的其他机制:彩票货币(ticket currency):这种方式允许拥有一组彩票的用户以他们喜欢的某种货币,将彩票分给自己的不同工作。之后操作系统再自动将这种货币兑换为正确的全局彩票。比如,假设用户A和用户B每人拥有100张彩票。用户A有两个工作A1和A2,他以自己的货币,给每个工作500张彩票(共1000张)。用户B只运行一个工作,给它10张彩票(总共10张)。操作系统将进行兑换,将A1和A2拥有的A的货币500张,兑换成全局货币50张。类似地,兑换给B1的10张彩票兑换成100张。然后会对全局彩票货币(共200张)举行抽奖,决定哪个工作运行。
如何为工作分配彩票?这是一个非常棘手的问题,很难量化。
彩票转让(ticket transfer):通过转让,一个进程可以临时将自己的彩票交给另一个进程。这种机制在客户端/服务端交互的场景中尤其有用,在这种场景中,客户端进程向服务端发送消息,请求其按自己的需求执行工作,为了加速服务端的执行,客户端可以将自己的彩票转让给服务端,从而尽可能加速服务端执行自己请求的速度。服务端执行结束后会将这部分彩票归还给客户端。
彩票通胀(ticket inflation):利用通胀,一个进程可以临时提升或降低自己拥有的彩票数量。如果一个进程知道它需要更多CPU时间,就可以增加自己的彩票,从而将自己的需求告知操作系统,这一切不需要与任何其他进程通信。
虽然随机方式可以使得调度程序的实现简单(且大致正确),但偶尔并不能产生正确的比例,尤其在工作运行时间很短的情况下,由于这个原因,Waldspurger提出了步长调度
步长调度:系统中的每个工作都有自己的步长,这个值与票数值成反比。举个例子,A、B、C这3个工作的票数分别是100、50和250,我们通过用一个大数分别除以他们的票数来获得每个进程的步长。比如用10000除以这些票数值,得到了3个进程的步长分别为100、200和40。我们称这个值为每个进程的步长(stride)。每次进程运行后,我们会让它的计数器增加它的步长,记录它的总体进展。当需要进行调度时,选择目前拥有最小行程值的进程,并且在运行之后将该进程的行程值增加一个步长。
优缺点
- 步长调度可以在概率上实现比例。
- 彩票调度不需要全局状态。假如一个新的进程在上面的步长调度执行过程中加入系统,应该怎么设置它的行程值呢?设置成0吗?这样的话,它就独占CPU了。而彩票调度算法不需要对每个进程记录全局状态,只需要用新进程的票数更新全局的总票数就可以了。因此彩票调度算法能够更合理地处理新加入的进程。
总结彩票调度通过随机值,聪明地做到了按比例分配。步长调度算法能够确定的获得需要的比例。但以下原因,并没有作为CPU调度程序被广泛使用。
- 这两种方式都不能很好地适合I/O
- 票数分配问题并没有确定的解决方式,例如,如何知道浏览器进程应该拥有多少票数?通用调度程序(像前面讨论的MLFQ及其他类似的Linux调度程序)做得更好,因此得到了广泛的应用。
先放着
- 为了解操作系统如何虚拟化CPU,必须了解一些重要的机制(mechanism):陷阱和陷阱处理程序,时钟中断以及操作系统和硬件在进程间切换时如何谨慎地保存和恢复状态。
- 做课堂项目,它会对你有所帮助。
- 操作系统的哲学:它希望确保控制机器。虽然它希望程序能够尽可能高效地运行 [受限直接执行],但操作系统也希望能够控制好程序和机器。也许这就是我们将操作系统视为资源管理器的原因。
计算机基础 的操作系统系列文章基于这本书:
- 《Operating Systems: Three Easy Pieces》
- 《操作系统导论》(中文版)
就是不断地重复执行指令的操作,即:
- fetch:处理器从内存中获取一条指令。
- decode:解码,弄清这是哪条指令。
- execute:执行。
这就是冯·诺依曼计算模型的基本概念。
Operating System是一类软件,负责让程序运行变得更容易,允许程序共享内存,让程序能够与设备交互等等,总体的目标是确保设备既易于使用又高效地运行,一个OS包含三个核心的概念:
- 虚拟化(virtualization)
- 并发(concurrency)
- 持久性(persistence)
从功能上看,一个操作系统的基本组成:
- 进程管理
- 内存管理
- 文件系统
- 网络通信
- 安全机制
- 用户界面
从主要设计目标看,一个操作系统至少满足:
- abstraction:建立抽象,让系统方便和易于使用。
- performance:高性能,最小化操作系统的开销。
- protection:在OS和应用程序之间提供保护。
- reliability:持续不断地稳定运行。
进程(process)是为正在运行的程序提供的抽象,一个正常的系统能够在少量的物理CPU上运行上百个进程,靠的就是虚拟出很多个CPU的假象,也就是时分共享(time sharing)CPU 技术:通过允许资源由一个进程使用一小段时间,然后由另一个进程使用一小段时间,如此下去,CPU就可以被许多进程共享。
要实现CPU的虚拟化,需要:低级机制(mechanism):低级方法或协议。例如,上下文切换(context switch),它让操作系统能够停止运行 一个程序,并开始在给定的 CPU 上运行另一个程序。高级策略(policy):在操作系统内做出某种决定的算法。例如,操作系统中的调度策略(scheduling policy)会利用历史信息、工作负载知识以及性能指标来做出运行哪个程序的决定。
现代操作系统都会提供以下的进程API:
- 创建(create)
- 销毁(destroy)
- 等待(wait)
- 其他控制(miscellaneous control)
- 状态(statu)
一个调用进程API的例子:UNIX 系统提供了许多与进程交互的API:fork():创建子进程exec():让子进程与父进程执行不同的任务。wait():延迟当前进程的执行,直到被调用的进程执行完毕。kill():向进程发送信号,包括要求进程睡眠、终止或其他有用的指令。
下面的代码展示了使用fork()创建子进程:
use nix::unistd::*; fn main() { println!(“hello world (pid:{})”, getpid()); match fork() { Ok(ForkResult::Parent { child }) => { // 在父进程中 println!(“hello, I am parent of {} (pid:{})”, child, getpid()); } Ok(ForkResult::Child) => { // 在子进程中 println!(“hello, I am child (pid:{})”, getpid()); } Err(_) => { // fork 创建子进程失败 println!(“Fork creation failed!”); } } //hello world (pid:13399) //hello, I am parent of 13400 (pid:13399) //hello, I am child (pid:13400) }
- 将代码和静态数据加载到内存。
- 为程序创建和初始化栈(stack)和堆(heap)。
- 进行IO相关的设置和工作。
完成以上三步后,找到程序的入口,启动程序,将CPU的控制权转移到新建的进程中。
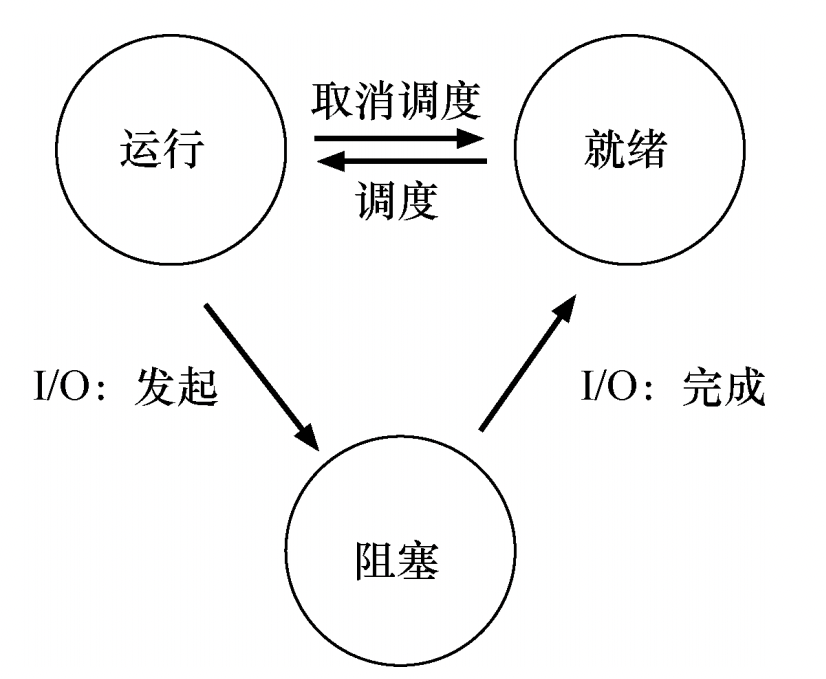
运行(running):在运行状态下,进程正在处理器上运行。这意味着它正在执行指令。就绪(ready):在就绪状态下,进程已准备好运行,但由于某种原因,操作系统选择不在此时运行。阻塞(blocked):在阻塞状态下,一个进程执行了某种操作,直到发生其他事件时才会准备运行。一个常见的例子是,当进程向磁盘发起 I/O 请求时,它会被阻塞,因此其他进程可以使用处理器。状态转换的过程:
使用时分共享(time sharing)CPU技术来虚拟化CPU有两个主要的问题:
- 性能:如何在不增加系统开销的情况下实现虚拟化?
- 控制权:如何有效地运行进程,同时保留对CPU的控制权?
也就是如何高效、可控地虚拟化CPU?这就是操作系统开发人员想出来的技术:受限直接执行(limited direct execution)。直接执行很容易理解:只需直接在 CPU 上运行程序即可。即,当 OS 希望启动程序运行时,它会在进程列表中为其创建一个进程条目,为其分配一些内存,将程序代码(从磁盘)加载到内存中,找到入口点(main()函数或类似的),跳转到那里,并开始运行用户的代码。
受限的部分是什么呢?如果操作系统对运行的程序没有限制,任何程序能够随意地访问硬件,那么操作系统就不能控制任何事情,操作系统本身也就退化为一个库而已。但是必须允许程序执行I/O等受限制的操作,因为硬件本身就是给运行在其上的程序使用的,不可能因噎废食。
LDE 背后的想法很简单:让程序运行的大部分指令直接访问硬件,只在一些关键点(如进程发起系统调用或发生时钟中断)由操作系统介入来确保“在正确时间, 正确的地点,做正确的事”。为了实现高效的虚拟化,操作系统应该尽量让程序自己运行, 同时通过在关键点的及时介入(interposing),来保持对硬件的控制。高效和控制是现代操 作系统的两个主要目标。
那就是说一个进程必须能够执行 I/O 和其他一些受限制的操作,但又不能让进程完全控制系统。操作系统和硬件如何协作实现这一点?
这是通过不同的执行模式来实现的,硬件通过提供不同的执行模式来协助操作系统:内核模式(kernel mode)在此模式下,运行的代码可以做它喜欢的事,包括特权操作,如发出 I/O请求和执行所有类型的受限指令。操作系统就是以这种模式运行。
用户模式(user mode)在此模式下运行的代码会受到限制。例如,在用户模式下运行时,进程不能发出 I/O 请求。这样做会导致处理器引发异常,操作系统可能会终止进程。但是它允许内核小心地向用户程序暴露某些关键功能,例如访问文件系统、创建和销毁进程、与其他进程通信,以及分配更多内存。大多数操作系统会提供几百个系统级的API,以使用户程序能够间接执行特权操作,从而进行系统调用。
如果一个进程在 CPU 上运行,这就意味着操作系统没有运行。如果操作系统没有运行,操作系统如何重新获得 CPU 的控制权(regain control),以便它可以在进程之间切换?
早期操作系统采用的方式,协作方式:等待系统调用 。
- 进程通过系统调用,将CPU的控制权转移给操作系统。
- 应用程序执行非法操作,将控制权转移给操作系统。
如果上述两种情况都没有发生,比如进程拒绝进行系统调用,也没有出错,那么操作系统无法做任何事情,只能采用重启大法。
第二种方式,非协作方式:操作系统进行控制。时钟设备可以编程为每隔几毫秒产生一次中断,即:时钟中断(timer interrupt) 。产生中断时,当前正在运行的进程停止,操作系统中预先配置的中断处理程序(interrupt handler)会运行。此时,操作系统重新获得 CPU 的控制权,因此可以做它想做的事:停止当前进程,并启动另一个进程。
操作系统重新获得控制权的过程中主要做两件事:
- 通知硬件,哪些代码在时钟中断时运行,因此硬件有责任为正在运行的程序保存足够的状态。
- 启动时钟,一旦时钟开始运行,操作系统就感到安全了,因为控制权最终会归还给它,因此操作系统可以自由运行用户程序。
上下文切换(context switch)操作系统一旦获得控制权,就必须做出决定:是继续运行当前正在运行的进程,还是切换到另一个进程。这个决定是由调度程序(scheduler)做出的,具体的调度策略稍后讨论。不论如何,假设操作系统决定进行进程切换,OS就会执行一些底层代码,即上下文切换(context switch):即,保存当前正在运行的进程的上下文,也就是操作系统会执行一些底层汇编代码,来保存通用寄存器、程序计数器,以及当前正在运行的进程的内核栈指针,然后恢复寄存器、程序计数器,并切换内核栈,供即将运行的进程使用。通过切换栈,内核在进入切换代码调用时,是一个进程(被中断的进程)的上下文,在返回时,是另一进程(即将执行的进程) 的上下文。
上下文切换需要多长时间?可以使用为 lmbench 这个工具衡量操作系统的性能指标。现代操作系统,在具有 2 GHz 或 3 GHz 处理器的系统上的性能可以达到亚微秒级。(1 μs = 10^−6 秒,也就是说在几十到几百微秒(μs))
前面说过,操作系统的调度程序(scheduler)会做出执行当前进程还是切换到下一个进程的决策,那么到底是按照什么样的策略(policy)做出决定,执行调度的呢?在认识不同的调度策略之前,先需要了解两个概念:
工作负载假设工作负载假设和经济学中的理性人假设一样,是非常不切合实际的,但是为了对比不同的调度策略,简化描述问题的框架,我们可以做出如下假设:
- 每一个工作运行相同的时间。
- 所有的工作同时到达。
- 一旦开始,每个工作保持运行直到完成。
- 所有的工作只是用 CPU(即它们不执行 IO 操作)。
- 每个工作的运行时间是已知的。
调度指标在进程调度中,有不同的指标,同样地把它简化成只用一个指标:周转时间(turnaround time)。任务的周转时间定义为任务完成时间减去任务到达系统的时间,即:T 周转时间 = T 完成时间 − T 到达时间
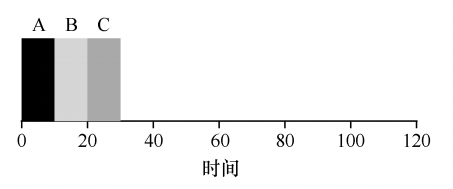
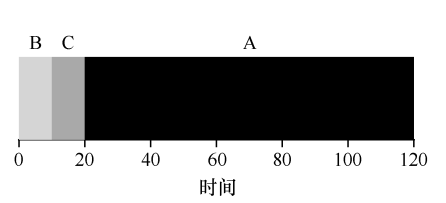
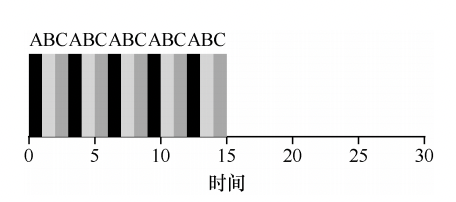
非常简单,先到先服务,先到达系统的任务先运行,如果一切按照工作负载假设第一条说的那样,那这种策略非常好,比如下面的例子,三个任务的平均周转时间是(10 + 20 + 30)/ 3 = 20s:
但是实际上,每个任务的实际运行时间可能差别很大,比如A任务的运行时间可能特别长,比如下面这样:
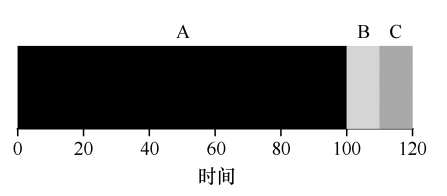
那么三个任务的平均周转时间是(100 + 110 + 120)/ 3 = 110s
这个策略就是运行时间越短的任务,越优先运行,比如对上面的例子,可以先运行B和C,再运行A任务:
这样三个任务的平均周转时间是(10 + 20 + 120)/3 = 50s。
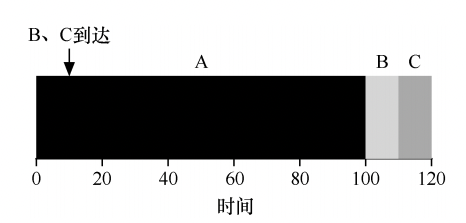
但是实际上,工作负载假设第二条说的也不现实,三个任务可能先后到达,假设 A 在 t = 0 时到达,且需要运行 100s。而 B 和 C 在 t = 10 到达,且各需要运行 10s。则:
这样三个任务的平均周转时间是(100+(110−10)+(120−10))/3 = 103.33s。
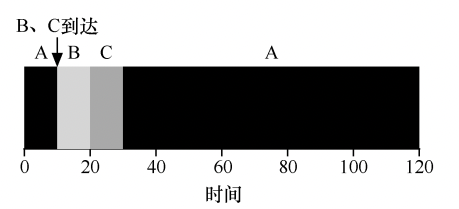
要解决上面的问题,就要放弃工作负载假设第三条(工作必须保持运行直到完成):每当新工作进入系统时,确定剩余工作和新工作中,谁的剩余时间最少,然后调度该工作。
在上面的例子中,STCF 将抢占 A 并运行 B 和 C 以完成。只有在它们完成后,才能调度 A 的剩余时间:
这样三个任务的平均周转时间是(120 + 10 + 20)/3 = 50s。
新度量指标:响应时间上面的例子都是以T 周转时间作为衡量指标,现在提出一个新的指标:响应时间。响应时间定义为从任务到达系统到首次运行的时间。即:T 响应时间= T 首次运行−T 到达时间
对于上面的例子,三个作业的平均响应时间为(0+0+10)/3 = 3.33s。平均每个作业都要过3.33s才会开始运行,从响应时间的指标上看,结果很差。如何解决呢?引入一种新的调度算法:
基本思想很简单:RR 在一个时间片(time slice,有时称为调度量子,scheduling quantum)内运行一个工作,然后切换到运行队列中的下一个任务,而不是运行一个任务直 到结束。它反复执行,直到所有任务完成。因此,RR 有时被称为时间切片(time-slicing)。请注意,时间片长度必须是时钟中断周期的倍数。因此,如果时钟中断是每 10ms 中断一次, 则时间片可以是 10ms、20ms 或 10ms 的任何其他倍数。
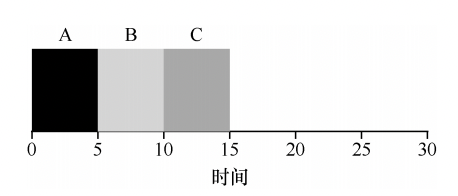
为了更好的理解轮转(Round-Robin, RR)调度,举一个新的例子:假设 3 个任务 A、B 和 C 在系统中同时到达, 并且它们都希望运行 5s。
按照最短任务优先(SJF)算法:
SJF 算法平均响应时间是:(0 + 5 + 10)/ 3 = 5s。SJF 算法平均周转时间是(5 + 10+ 15)/3 = 10s。
按照轮转(Round-Robin, RR)调度:
RR 的平均响应时间是:(0 + 1 + 2)/3 = 1s。RR 的平均周转时间是:(13 + 14 + 15)/3 = 14s。
可以发现响应时间和周转时间两个指标属于鱼和熊掌不可兼得:
- 如果你愿意不公平,你可以运行较短的工作直到完成,但是要以响应时间为代价。
- 如果你重视公平性,则响应时间会较短,但会以周转时间为代价。
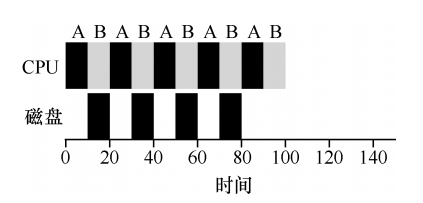
结合I/O进行调度现在到了放弃工作负载假设第四条的时候,基本上很少有程序没有任何I/O,调度策略如何调度一个有I/O的程序呢?假设有两项工作 A 和 B,每项工作需要 50ms 的 CPU时间。但是,有一个明显的区别:A 运行 10ms,然后发出 I/O 请求(假设 I/O 每个都需要 10ms),而 B 只是使用 CPU 50ms,不执行 I/O。
需要考虑的就是,当一个进程在I/O上被阻塞时,应该让其他的进程使用CPU,而不是闲置,所以调度程序要是先运行A,再运行B就是一个差的调度策略:
上图所示,A进程I/O期间,CPU是空闲的。一个好的调度策略应该是当这些交互式作业正在执行 I/O 时,其他 CPU 密集型作业将运行,从而更好地利用处理器。比如使用STCF在I/O 期间抢占CPU:
现在我们还剩下最后一个不切实际的假设,工作负载假设第五条:操作系统无法看到未来,并不能事先确定地知道每个工作的运行时间。
MLFQ需要解决两个问题:
- 优化周转时间
- 优化响应时间
但是在解决这两个问题之前,首先面对的难题是对进程的运行时间一无所知,MLFQ采用的方式是用历史经验来预测未来,调度程序如何在运行过程中学习进程的特征。
- MLFQ 中有许多独立的队列(queue),每个队列有不同的优先级(priority level)。
- 任何时刻,一个工作只能存在于一个队列中。
- MLFQ 总是优先执行较高优先级的工作(即在较高级队列中的工作)。
- 当然,每个队列中可能会有多个工作,因此具有同样的优先级,在这种情况下,我们 就对这些工作采用轮转调度。
下面的图可以表达的很清楚:
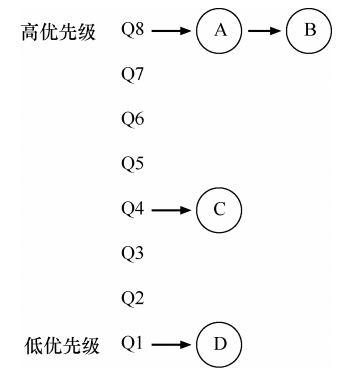
上面的例子展示了MLFQ两条基本规则:
- 规则 1:如果 A 的优先级 > B 的优先级,运行 A(不运行 B)。
- 规则 2:如果 A 的优先级 = B 的优先级,轮转运行 A 和 B。
从上面的图上看,操作系统将交替地调度A和B,在A和B执行完成之前,C和D都没有机会被执行。但实际上,上面是一张静态的图,进程的优先级是不断变化的。
降低优先级MLFQ 没有为每个工作指定不变的优先级,而是根据观察到的行为调整它的优先级。例如,如果一个工作不断放弃CPU 去等待键盘输入,这是交互型进程的可能行为,MLFQ 因此会让它保持高优先级。相反,如果一个工作长时间地占用 CPU,MLFQ 会降低其优先级。通过这种方式,MLFQ 在进程运行过程中学习其行为,从而利用工作的历史来预测它未来的行为。
- 规则 3:工作进入系统时,放在最高优先级(最上层队列)。
- 规则 4a:工作用完整个时间片后,降低其优先级(移入下一个队列)。
- 规则 4b:如果工作在其时间片以内主动释放 CPU, 则优先级不变。
第一个例子:对于一个需要长时间运行的工作,会不断降低它的优先级:
第二个例子:有两个工作:A(用黑色表示) 是一个长时间运行的 CPU 密集型工作,B(用灰色表示) 是一个运行时间很短的交互型工作。假设 A 执行 一段时间后 B 到达:
通过这个例子可以体会到这个算法的一个主要目标:如果不知道工作是短工作还是长工作,那么就在开始的时候假设其是短工作,并赋予最高优先级。如果确实是短工作,则很快会执行完毕,否则将被慢慢移入低优先级队列,而这时该工作也被认为是长工作了。
第三个例子:交互型工作 B(用灰色表示)每执行 1ms 便需要进行 I/O操作,它与长时间运行的工作 A(用黑色表示)竞争 CPU:
上面的三个例子都是优先级降低的例子,如果只进行优先级降低的操作,会有三个问题:
- 饥饿(starvation)问题:如果系统有“太多”交互型工作,就会不断占用CPU,导致长工作永远无法得到 CPU(它们饿死了)
- 有些应用程序会欺骗调度程序,让OS给出远超公平的资源;比如进程在时间片用完之前,调用一个 I/O 操作(比如访问一个无关的文件),从而主动释放 CPU。如此便可以保持在高优先级,占用更多的 CPU 时间。
- 一个程序可能在不同时间表现不同,一个计算密集的进程可能在某段时间表现为一个交互型的进程。
解决的方法就是,改变优先级除了降低,还需要有提升的操作:提升优先级为了让 CPU 密集型工作也能取得一些进展(即使不多),我们能做些什么?一个简单的思路是周期性地提升(boost)所有工作的优先级:
- 规则 5:经过一段时间 S,就将系统中所有工作重新加入最高优先级队列。
新规则一下解决了两个问题。首先,进程不会饿死——在最高优先级队列中,它会以轮转的方式,与其他高优先级工作分享 CPU,从而最终获得执行。其次,如果一个 CPU 密集型工作变成了交互型,当它优先级提升时,调度程序会正确对待它。
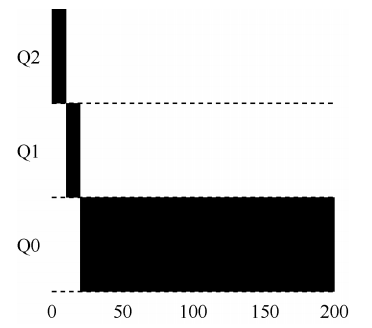
下面是一个长工作与两个交互型短工作竞争 CPU 时的行为。左边没有优先级提升,长工作在两个短工作到达后被饿死。右边每 50ms 就有一次优先级提升(这里只是举例,这个值可能过小),因此至少保证长工作会有一些进展,每过 50ms 就被提升到最高优先级,从而定期获得执行。
现在还有一个问题没解决:如何阻止调度程序被愚弄?这里的解决方案,是为 MLFQ 的每层队列提供更完善的 CPU 计时方式(accounting)。调度程序应该记录一个进程在某一层中消耗的总时间,而不是在调度时重新计时。只要进程用完了自己的配额,就将它降到低一优先级的队列中去。不论它是一次用完的,还是拆成很多次用完。因此,我们重写规则 4a 和 4b:
规则 4:一旦工作用完了其在某一层中的时间配额(无论中间主动放弃了多少次CPU),就降低其优先级(移入低一级队列)。
下面的例子,对比了在规则 4a、4b 的策略下(左图),以及在新的规则 4(右图)的策略下,同样试图愚弄调度程序的进程的表现。没有规则 4 的保护时,进程可以在每个时间片结束前发起一次 I/O 操作,从而垄断 CPU 时间。有了这样的保护后,不论进程的 I/O 行为如何,都会慢慢地降低优先级,因而无法获得超过公平的 CPU 时间比例。
三个问题都解决了,除此之外,MLFQ 还有可以优化的地方。
MLFQ 调优大多数的 MLFQ 变体都支持不同队列可变的时间片长度。高优先级队列通常只有较短的时间片(比如 10ms 或者更少),因而这一层的交互工作可以更快地切换。相反,低优先级队列中更多的是 CPU 密集型工作,配置更长的时间片会取得更好的效果。
下面的例子,两个长工作在高优先级队列执行 10ms,中间队列执行 20ms,最后在最低优先级队列执行 40ms:
Solaris 操作系统的 MLFQ 实现(时分调度类 TS)很容易配置。它提供了一组表来决定进程在其生命周期中如何调整优先级,每层的时间片多大,以及多久提升一个工作的优先级。管理员可以通过这些表,让调度程序的行为方式不同。该表默认有 60 层队列,时间片长度从 20ms(最高优先级),到几百 ms(最低优先级),每一秒左右提升一次进程的优先级。其他一些 MLFQ 调度程序没用表,甚至没用前面讲到的规则,有些采用数学公式来调整优先级。
MLFQ小结
- 规则 1:如果 A 的优先级 > B 的优先级,运行 A(不运行 B)。
- 规则 2:如果 A 的优先级 = B 的优先级,轮转运行 A 和 B。
- 规则 3:工作进入系统时,放在最高优先级(最上层队列)。
- 规则 4:一旦工作用完了其在某一层中的时间配额(无论中间主动放弃了多少次CPU),就降低其优先级(移入低一级队列)。
- 规则 5:经过一段时间 S,就将系统中所有工作重新加入最高优先级队列。
比例调度程序的最终目标,是确保每个工作获得一定比例的 CPU 时间,而不是优化周转时间和响应时间。如何设计调度程序来按比例分配 CPU?其关键的机制是什么?效率如何?
比例份额调度程序有一个非常优秀的现代例子,由 Waldspurger 和 Weihl 发现,名为:
彩票调度(lottery scheduling)彩票调度背后是一个非常基本的概念:票数(ticket)代表了进程(或用户或其他)占有某个资源的份额。一个进程拥有的彩票数占总票数的百分比,就是它占有资源的份额。通过不断定时地(比如,每个时间片)抽取彩票,彩票调度从概率上(但不是确定的)获得这种份额比例。
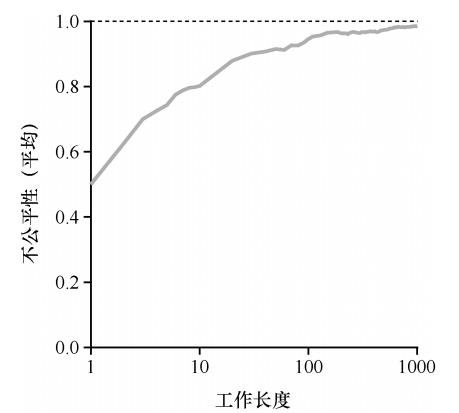
假设有两个互相竞争工作的完成时间,每个工作都有相同数目的 100 张彩票,以及相同的运行时间 R。这种情况下,我们希望两个工作在大约同时完成,但由于彩票调度算法的随机性,有时一个工作会先于另一个完成。为了量化这种区别,我们定义了一个简单的不公平指标 U(unfairness metric),将两个工作完成时刻相除得到 U 的值。如果两个工作几乎同时完成,U 的值将很接近于 1。在这种情况下,我们的目标是: 完美的公平调度程序可以做到 U=1。下图展示了当两个工作的运行时间从 1 到 1000 变化时,30 次试验的平均 U 值。可以看出,当工作执行时间很短时,平均不公平度非常糟糕。只有当工作执行非常多的时间片时,彩票调度算法才能得到期望的结果:
从上面的内容可以看出,虽然随机方式可以使得调度程序的实现简单(且大致正确),但偶尔并不能产生正确的比例,尤其在工作运行时间很短的情况下。由于这个原因,Waldspurger 提出了一个确定性的公平分配算法:
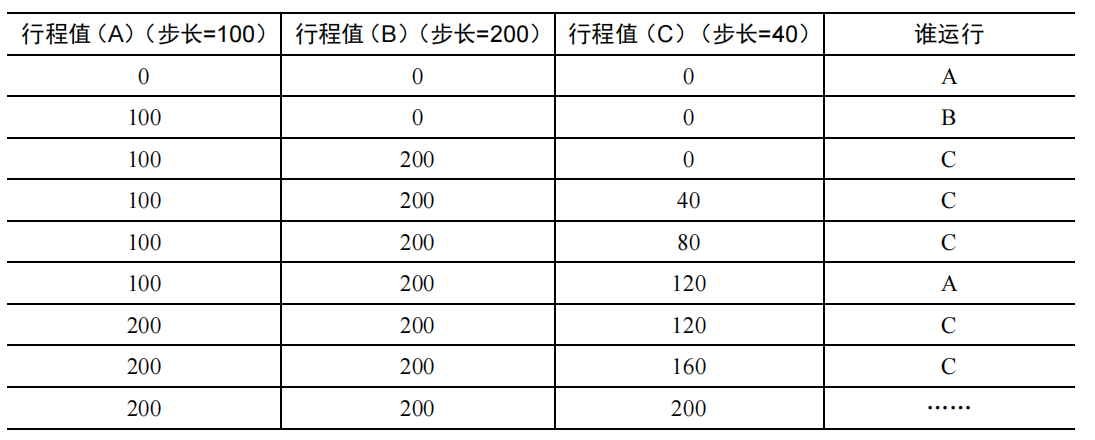
步长调度(stride scheduling)步长调度也很简单。系统中的每个工作都有自己的步长,这个值与票数值成反比。假设A、B、C 这 3 个工作的票数分别是 100、50 和 250,我们通过用一个大数分别除以他们的票数来获得每个进程的步长。比如用 10000 除以这些票数值,得到了 3 个进程的步长分别为 100、200 和 40。我们称这个值为每个进程的步长(stride)。每次进程运 行后,我们会让它的计数器 [称为行程(pass)值] 增加它的步长,记录它的总体进展。
调度程序使用进程的步长及行程值来确定调度哪个进程。基本思路很简单:当需要进行调度时,选择目前拥有最小行程值的进程,并且在运行之后将该进程的行程值增加一个步长。
下面的表记录了A、B、C 这 3 个工作一段时间内的调度记录:
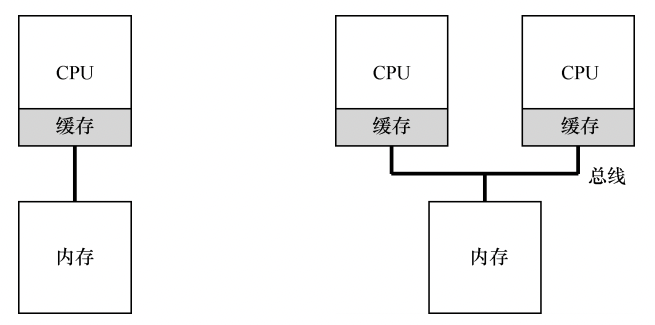
到目前为止,我们讨论了许多单处理器调度的原则,那么如何将这些想法扩展到多处理器上呢?为了理解多处理器调度带来的新问题,必须先知道它与单 CPU 之间的基本区别。区别的核心在于对硬件缓存(cache)的使用,以及多处理器之间共享数据的方式,如下图:
程序第一次读取数据时,数据在内存中,因此需要花费较长的时间(可能数十或数百纳秒)。处理器判断该数据很可能会被再次使用,因此将其放入 CPU 缓存中。如果之后程序再次需要使用同样的数据,CPU 会先查找缓存。因为在缓存中找到了数据,所以取数据快得多(比如几纳秒),程序也就运行更快。
但是如上图右图所示,多个处理器共享一个内存,会有三个问题:
缓存一致性(cache coherence)问题:假设一个运行在 CPU 1 上的程序从内存地址 A 读取数据。由于不在 CPU 1 的缓存中,所以系统直接访问内存,得到值 D。程序然后修改了地址 A 处的值,只是将它的缓存更新为新值 D’。将数据写回内存比较慢,因此系统(通常)会稍后再做。假设这时操作系统中断了该程序的运行,并将其交给 CPU 2, 重新读取地址 A 的数据,由于 CPU 2 的缓存中并没有该数据,所以会直接从内存中读取, 得到了旧值 D,而不是正确的值 D‘。
硬件提供了这个问题的基本解决方案:通过监控内存访问,硬件可以保证获得正确的数据,并保证共享内存的唯一性。在基于总线的系统中,一种方式是使用总线窥探(bus snooping)。每个缓存都通过监听链接所有缓存和内存的总线,来发现内存访问。如 果 CPU 发现对它放在缓存中的数据的更新,会作废(invalidate)本地副本(从缓存中移除),或更新(update)它(修改为新值)。
同步问题:跨 CPU 访问(尤其是写入)共享数据或数据结构时,需要使用互斥原语(比如锁),才能保证正确性。例如,假设多 CPU 并发访问一个共享队列。如果没有锁,即使有底层一致性协议,并发地从队列增加或删除元素,依然不会得到预期结果。需要用锁来保证数据结构状态更新的原子性。
缓存亲和度(cache affinity)问题:所谓的缓存亲和度(cache affinity)是指::一个进程在某个 CPU 上运行时,会在该 CPU 的缓存中维护许多状态。下次 该进程在相同 CPU 上运行时,由于缓存中的数据而执行得更快。相反,在不同的 CPU 上执行,会由于需要重新加载数据而很慢(好在硬件保证的缓存一致性可以保证正确执行)。因此多处理器调度应该考虑到这种缓存亲和性,并尽可能将进程保持在同一个 CPU 上。
认识了上面三个多处理器系统的调度程序需要面对的问题,就可以讨论第一种调度程序:简单地复用单处理器调度的基本架构,将所有需要调度的工作放入一个单独的队列中,我们称之为单队列多处理器调度(Single Queue Multiprocessor Scheduling,SQMS)。这个方法最大的优点是简单。它不需要太多修改,就可以将原有的策略用于多个 CPU,选择最适合的工作来运行(例如,如果有两个 CPU,它可能选择两个最合适的工作)。
SQMS 有两个明显的短板:第一个是缺乏可扩展性(scalability):为了保证在多CPU 上正常运行,调度程序的开发者需要在代码中通过加锁(locking)来保证原子性。然而,锁可能带来巨大的性能损失,尤其是随着系统中的 CPU 数增加时。随着这种单个锁的争用增加,系统花费了越来越多的时间在锁的开销上,较少的时间用于系统应该完成的工作。
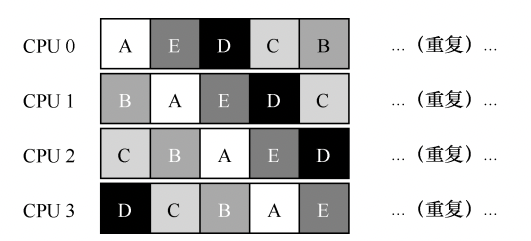
第二个是缓存亲和性:假设我们有 5 个工作(A、B、C、D、 E)和 4 个处理器。调度队列如下:
一段时间后,假设每个工作依次执行一个时间片,然后选择另一个工作,下面是每个CPU 可能的调度序列:
由于每个 CPU 都简单地从全局共享的队列中选取下一个工作执行,因此每个工作都不断在不同 CPU 之间转移,这与缓存亲和的目标背道而驰。为了解决这个问题,大多数 SQMS 调度程序都引入了一些亲和度机制,尽可能让进程在同一个 CPU 上运行。保持一些工作的亲和度的同时,可能需要牺牲其他工作的亲和度来实现负载均衡。例如,针对同样的 5 个工作的调度如下:
这种调度中,A、B、C、D 这 4 个工作都保持在同一个 CPU 上,只有工作 E 不断地来回迁移(migrating),从而尽可能多地获得缓存亲和度。
正是由于单队列调度程序的这些问题,有些系统使用了多队列的方案,比如每个 CPU 一个队列。称之为多队列多处理器调度(Multi-Queue Multiprocessor Scheduling,MQMS)MQMS 中,基本调度框架包含多个调度队列,每个队列可以使用不同的调度规则, 比如轮转或其他任何可能的算法。当一个工作进入系统后,系统会依照一些启发性规则(如随机或选择较空的队列)将其放入某个调度队列。这样一来,每个 CPU 调度之间相互独立,就避免了单队列的方式中由于数据共享及同步带来的问题。
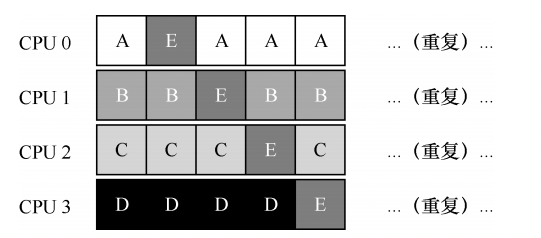
例如,假设系统中有两个 CPU(CPU 0 和 CPU 1)。这时一些工作进入系统:A、B、C 和 D。由于每个 CPU 都有自己的调度队列,操作系统需要决定每个工作放入哪个队列。可能像下面这样做:
根据不同队列的调度策略,每个 CPU 从两个工作中选择,决定谁将运行。例如,利用轮转,调度结果可能如下所示:
MQMS的优势:它天生更具有可扩展性。队列的数量会随着 CPU 的增加而增加,因此锁和缓存争用的开销不是大问题。MQMS 天生具有良好的缓存亲和度。所有工作都保持在固定的 CPU 上,因而可以很好地利用缓存数据。
但是也有个缺点:
负载不均在上面的例子中,假设一段时间后工作C执行完毕,现在调度队列如下:
如果对系统中每个队列都执行轮转调度策略,会获得如下调度结果:
从图中可以看出,A 获得了 B 和 D 两倍的 CPU 时间,这不是期望的结果。更糟的是, 假设 A 和 C 都执行完毕,系统中只有 B 和 D。调度队列看起来如下:
因此 CPU 使用时间线看起来令人难过:
如何解决负载不均的问题呢?答案是不断地迁移一个或多个工作。一种可能的解决方案是不断切换工作,如下面的时间线所示。可以看到,开始的时候 A 独享 CPU 0,B 和 D 在 CPU 1。一些时间片后,B 迁移到 CPU 0 与 A 竞争,D 则独享 CPU 1 一段时间。这样就实现了负载均衡。
系统如何决定发起这样的迁移?一个基本的方法是采用一种技术,名为工作窃取(work stealing)。通过这种方法,工作量较少的(源)队列不定期地“偷看”其他(目标)队列是不是比自己的工作多。如果目标队列比源队列(显著地)更满,就从目标队列“窃取”一个或多个工作,实现负载均衡。当然,这种方法也有让人抓狂的地方——如果太频繁地检查其他队列,就会带来较高的开销,可扩展性不好,而这是多队列调度最初的全部目标!相反,如果检查间隔太长,又可能会带来严重的负载不均。找到合适的阈值仍然是黑魔法,这在系统策略设计中很常见。 操作系统导论(OSTEP) pdf 最新版 文字版 百度网盘 下载如果日常工作中和底层打交道的话会遇到很多操作系统相关的问题,比如:
- 为何系统会出现 load 值高 cpu 利用率却不高的情况?
- 为何会有那么多僵尸进程?
- 某些场景下如何快速创建进程的 snapshot ?
- 如何高效利用 CPU Cache Line(利用 Cache Friendly 的数据结构)?
- 如何避免 False Sharing ?
- 并发情况下如何避免死锁?
- zero-copy 为何高效?
- 单纯的 context switch 都是 micro second 级的,为何频繁的线程调度会导致性能低下?
- 各种锁(互斥锁、自旋锁、读写锁)的适用场景等。
如何去理解以及解决以上这些问题就需要我们对操作系统的底层工作机制有一定的了解。这本书来自美国威斯康星大学课程的教材。为什么要介绍这本书呢?主要由于以下几个方面:
- 阅读体验良好。书中以短句居多,配图丰富,整体下来阅读过程的非常的愉快。
- 讨论问题由浅入深。就像我们有时候做题一样,先考虑简单的情况,然后再一点一点增加条件逐步解决。基本在本书中的论述都是先制定衡量标准,然后将情况一点一点复杂化来对比各种设计的优劣。
- 给出了非常多的阅读材料。
本书围绕虚拟化、并发和持久性这三个主要概念展开,介绍了所有现代系统的主要组件(包括调度、虚拟内存管理、磁盘和 I/O 子系统、文件系统)。全书共 50 章,分为 3 个部分,分别讲述虚拟化、并发和持久性的相关内容。作者以对话形式引入所介绍的主题概念,行文诙谐幽默却又鞭辟入里,力求帮助读者理解操作系统中虚拟化、并发和持久性的原理。 本书内容全面,并给出了真实可运行的代码(而非伪代码),还提供了相应的练习,很适合高等院校相关专业的教师开展教学和高校学生进行自学。作者:[美] 雷姆兹·H.阿帕希杜塞尔( Remzi H. Arpaci-Dusseau), [美]安德莉亚·C.阿帕希杜塞尔(Andrea C. Arpaci-Dusseau)译者:王海鹏操作系统导论(OSTEP)










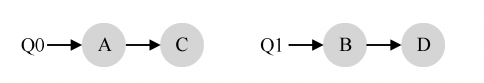

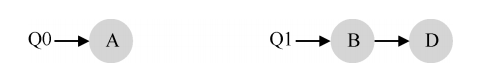



版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/185404.html