
我们在用神经网络求解PDE时, 经常要用到输出值对输入变量(不是Weights和Biases)求导; 在训练WGAN-GP 时, 也会用到网络对输入变量的求导。 以上两种需求, 均可以用pytorch 中的autograd.grad() 函数实现。
autograd.grad(outputs, inputs, grad_outputs=None, retain_graph=None, create_graph=False, only_inputs=True, allow_unused=False)
outputs: 求导的因变量(需要求导的函数)
inputs: 求导的自变量
grad_outputs: 如果 outputs为标量,则grad_outputs=None,也就是说,可以不用写; 如果outputs 是向量,则此参数必须写,不写将会报如下错误:

那么此参数究竟代表着什么呢?
先假设  为一维向量, 即可设自变量因变量分别为 , 其对应的 Jacobi 矩阵为
为一维向量, 即可设自变量因变量分别为 , 其对应的 Jacobi 矩阵为
grad_outputs 是一个shape 与 outputs 一致的向量, 即
,
在给定grad_outputs 之后,真正返回的梯度为
为方便下文叙述我们引入记号
其次假设 ,第i个列向量对应的Jacobi矩阵为
此时的grad_outputs 为(维度与outputs一致)
由第一种情况, 我们有
也就是说对输出变量的列向量求导,再经过权重累加。

若 沿用第一种情况记号
, 其中每一个 均由第一种方法得出,
即对输入变量列向量求导,之后按照原先顺序排列即可。
retain_graph: True 则保留计算图, False则释放计算图
create_graph: 若要计算高阶导数,则必须选为True
allow_unused: 允许输入变量不进入计算
下面我们看一下具体的例子:
import torch from torch import autograd x = torch.rand(3, 4) x.requires_grad_()讯享网
观察 x 为

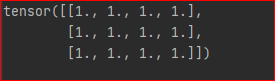
不妨设 y 是 x 所有元素的和, 因为 y是标量,故计算导数不需要设置grad_outputs
讯享网y = torch.sum(x) grads = autograd.grad(outputs=y, inputs=x)[0] print(grads)
结果为
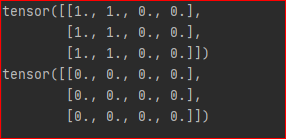
若y是向量
y = x[:,0] +x[:,1] # 设置输出权重为1 grad = autograd.grad(outputs=y, inputs=x, grad_outputs=torch.ones_like(y))[0] print(grad) # 设置输出权重为0 grad = autograd.grad(outputs=y, inputs=x, grad_outputs=torch.zeros_like(y))[0] print(grad)结果为
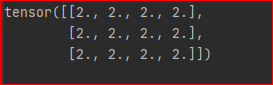
最后, 我们通过设置 create_graph=True 来计算二阶导数
讯享网y = x 2 grad = autograd.grad(outputs=y, inputs=x, grad_outputs=torch.ones_like(y), create_graph=True)[0] grad2 = autograd.grad(outputs=grad, inputs=x, grad_outputs=torch.ones_like(grad))[0] print(grad2)
结果为
综上,我们便搞清楚了它的求导机制.
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/17671.html