
- 考虑到PointNet特征提取时只考虑单点,不能很好的表示局部结构 ==> PointNet++引入了sampling & grouping,考虑局部领域特征
- PointNet中global feature直接由max pool得到,容易造成信息丢失 ==> PointNet++采用层级结构,可以有效的依据不同的感受野大小来提取不同区域的局部特征
- PointNet中采用TNet来保证点云特征旋转的不变性 ==> PointNet++采用局部相对坐标进行特征提取,剔除了TNet网络
- 针对稀疏点云导致样本不均匀问题,PointNet未做处理 ==> PointNet++提出多尺度方法MSG和多层级方法MRG来解决样本不均匀问题
- 对于分割网络来讲,PointNet直接整合global feature和local embedding特征 ==> PointNet++采用Encoder - Decoder结构,特征通过skip link concatenation进行连接
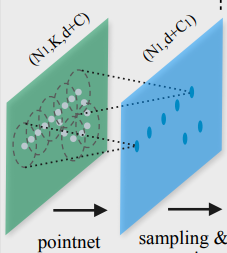
PointNet++网络结构如图所示,主要包含set abstraction(SA)块,分割网络中上采样的插值操作(interpolate),其中SA由sampling layer grouping layer和pointnet layer构成,接下来依次对其进行介绍。
sampling layer
- 作用
考虑到点云数量通常较大且数量不一致,PointNet++采用最远点采样(FPS(farthest point sampling ))从原始个点云中获取个样本进行特征提取。
- 数据变化
比如结构图中输入是点云信息,其中表示点云个数,表示坐标维度(通常为(x, y, z)3维),表示其他特征(如颜色、法线等),经过sampling layer后变成,其中 。
- FPS
采样后的样本集包含于原始样本集
采样过程也简单,先随机选取一个样本点,然后从剩余点中挑选离该样本点最远的点,即:新的样本点是原始样本中离已有样本集距离最远的点
注意:这里的距离度量是参考的坐标维度d,不考虑其他特征
grouping layer
- 作用
为每个样本点从其局部区域中挑选出K个领域点,便于特征能更好的包含局部领域信息,个人理解这里应该参考了图片提取特征时考虑的区域与一个的卷积核作用,因而学习样本点特征时也考虑其相邻K个点进而构成一个子区域。PointNet++中还通过实验证明Ball query比kNN(k近邻)效果更好。

- 数据变化
输入为, 经过grouping layer得到,其中表示点云采样个数,表示每个样本得到的领域点个数。
- Ball query
以样本点为球心,按照给定搜索半径R得到一个球形搜索区域,然后从该区域提取K个邻近点。
- 问题点
- 给定领域中点的个数不足K个或者多余K个如何处理?
如果不足K个,则直接对某个点重采样,凑够K个;
如果大于K个,则选取距离最小的前K个。
- 对于稀疏网络而言,样本分布不均匀,如何处理?
PointNet++提出了多尺度方法MSG和多层级方法MRG,这个见后面具体介绍。
- 给定领域中点的个数不足K个或者多余K个如何处理?


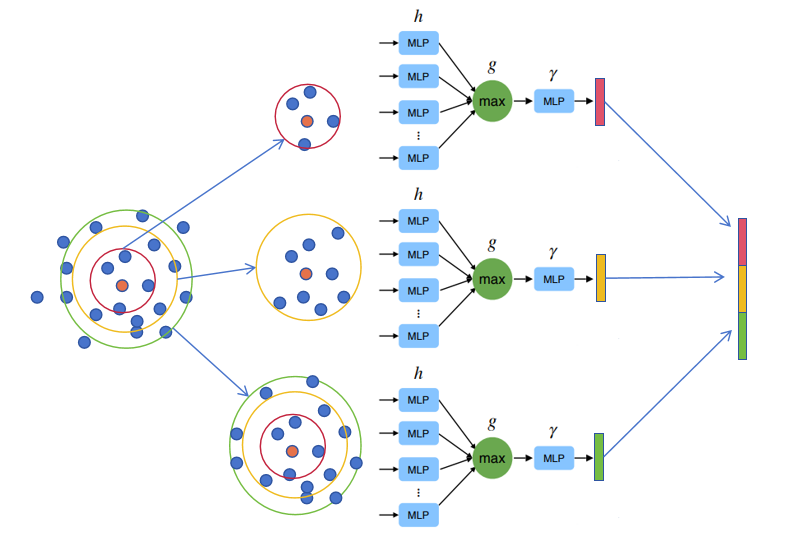
pointnet layer
- 作用
对采样点进行局部特征提取,即:
其提取过程如下图所示
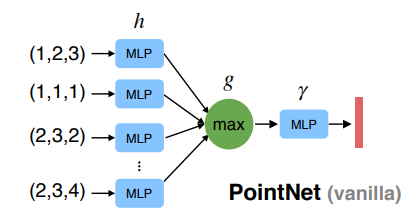
- 数据变化
输入为,输出为,其中表示经过pointNet Layer后特征维度,直观理解可以参照下图,即每一个采样点及其领域K个点经过特征提取后都形成一个新的特征,个采样点最终提取得到个特征。
- 问题点
- 特征提取时,未采用T-Net,那如何保证特征旋转不变性?
PointNet++未像PointNet一样采用T-Net,而是采用局部相对坐标,就是对每个采样点及其K个领域点的空间坐标进行变换:
其中表示采样点坐标,经过变换后其坐标都是想对于球形领域中心点的。
注意:这里变换只针对坐标,其他特征不变
- 特征提取时,未采用T-Net,那如何保证特征旋转不变性?
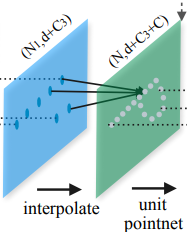
interpolate
- 作用
主要针对分割网络,因为分割结果需要对每一个点云分配一个语义标签。但是目前只获取到了下采样后点云的特征,那插值的作用就是得到下采样过程中忽视的点云的特征。
- 数据变化
输入为,输出为,其中为上采样之前的点云数量。
- 问题点
- 插值操作具体如何实现?
作者采用反向思维,对于采样过程中忽视的点,在采样后的结果中查找领域内的k个点,那这些点的特征都是已知的,对这些已知特征采用加权平均即可得到被忽视点的特征。
其中d表示距离,距离越小,权值越大
- 插值操作具体如何实现?
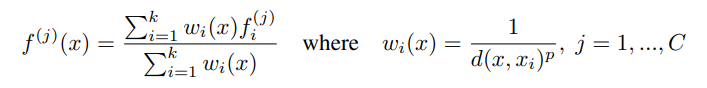
在实际点云采样过程中,其密度是不均匀的,比如下图,离相机较近的点云较密,而远点的点云较稀疏。

如果按照同一领域半径去寻找领域点,那对于稀疏的地方局部特征其实是比较差的,为了解决这一问题,作者提出了MSG和MRG两种方式。

MSG
多尺度进行采样,即前面提到的grouping layer不采用同一个半径R,而是采用不同的半径和采样个数,然后每次采样的特征都经过pointnet layer提取到特征后再进行融合,参照下图应该就清晰了。
MRG
dropout
为提高模型鲁棒性,在训练的时候采用随机丢弃点云的策略DP,即给定一个概率,每个点云都按照概率来决定是否丢弃该点,实验对比结果是加入DP后模型鲁棒性更好,**组合是MSTG+DP,其中SSG就是grouping layer里面提到的单尺度采样。
unit pointnet
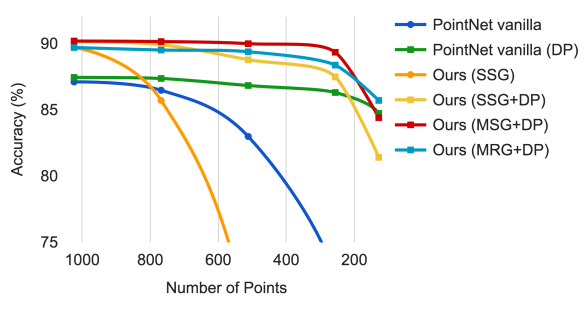
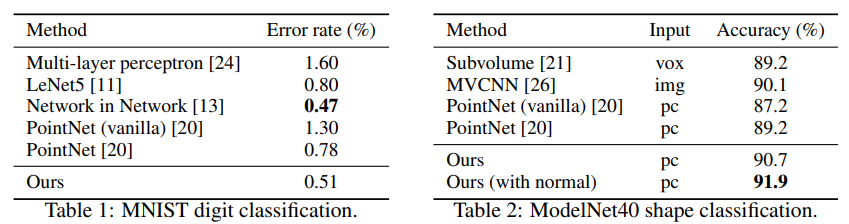
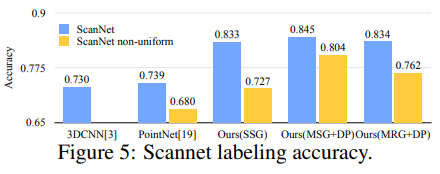
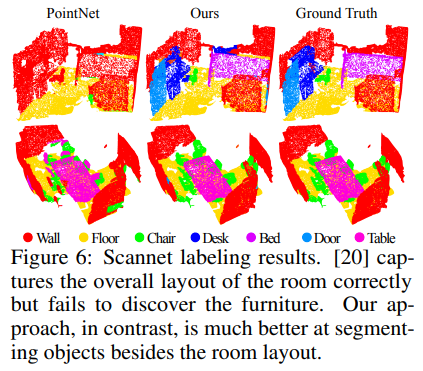
实验效果
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/175784.html