
<p id="main-toc"><strong>目录</strong></p> 讯享网
一、langchain-chatchat0.3.1的安装
二、安装模型部署框架(xinference)
三、运行模型部署框架(xinference)、下载启动所需模型
1、运行xinference
2、下载、启动模型
第一种方法:直接在xinference上下载,并启动模型:
第二种方法:手动下载模型,在xinference上启动
下载embedding模型(bge-large-zh-v1.5):
下载LLM(Qwen2.5-7B-Instruct-GPTQ-Int8):
四、运行langchain-chatchat0.3.1
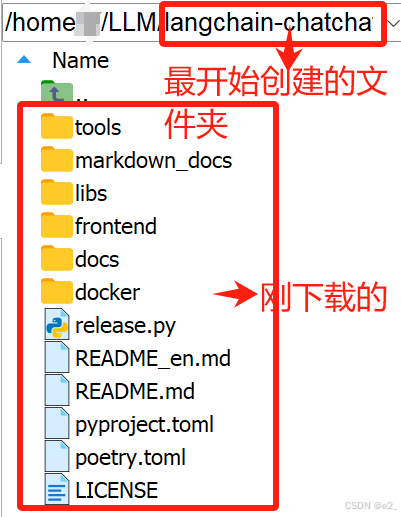
1、创建文件夹(eg:文件夹名为langchian-chatchat)
用于放置langchain-chatchat0.3.1项目,并进入到文件夹
讯享网
2、创建并激活虚拟环境(eg:环境名为langchain)
3、下载项目
讯享网
4、安装
https://github.com/chatchat-space/Langchain-Chatchat?tab=readme-ov-file:从 0.3.0 版本起,Langchain-Chatchat 不再根据用户输入的本地模型路径直接进行模型加载,涉及到的模型种类包括 LLM、Embedding、Reranker 及后续会提供支持的多模态模型等,均改为支持市面常见的各大模型推理框架接入,如 Xinference、Ollama、LocalAI、FastChat、One API 等。因此,请确认在启动 Langchain-Chatchat 项目前,首先进行模型推理框架的运行,并加载所需使用的模型。
这里用的是Xinference
1、创建并激活一个新的虚拟环境
为避免依赖冲突,要将 Langchain-Chatchat 和模型部署框架 Xinference 放在不同的 Python 虚拟环境中
讯享网
2、安装
如果需要使用 Xinference 进行模型推理,可以根据不同的模型指定不同的引擎。这里我安装的是 [Transformers] 引擎(也就是用下面那行代码),这是 Pytorch 模型默认使用的引擎 ,该引擎支持几乎有所的最新模型
讯享网
其中指定了 Xinference 的工作目录或模型存储位置
:指定了模型的来源
:是启动 Xinference 本地推理服务的命令
启动成功后,可以通过 http://<服务器ip>:9997来访问 xinference 的 WebGUI 界面
http://<服务器ip>:9997 来访问 xinference 的 WebGUI 界面:
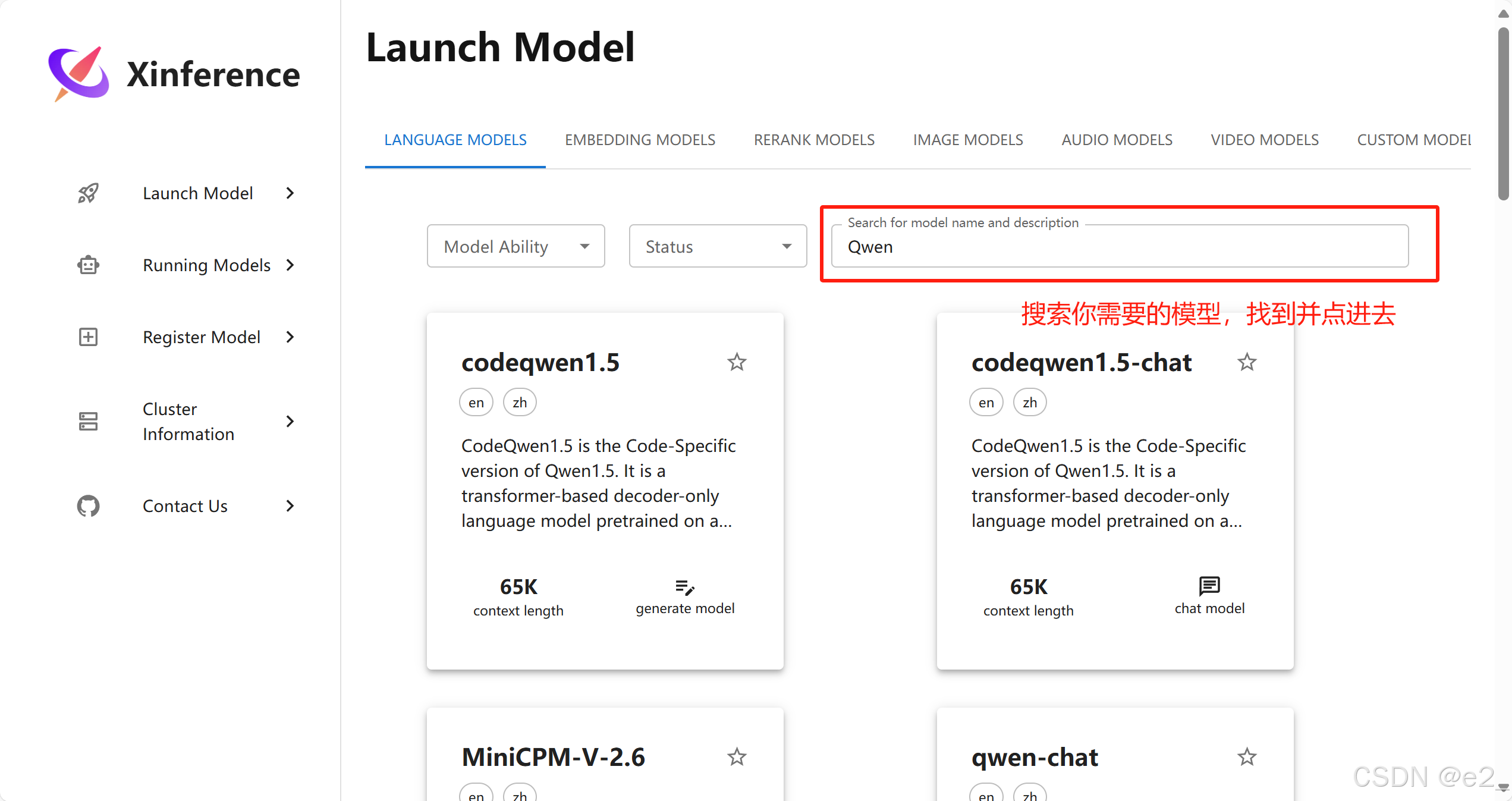
需要下载的模型有两个,一个是LLM(我使用的是Qwen),一个是embedding模型(我使用的是bge-large-zh-v1.5)
第一种方法:直接在xinference上下载,并启动模型:
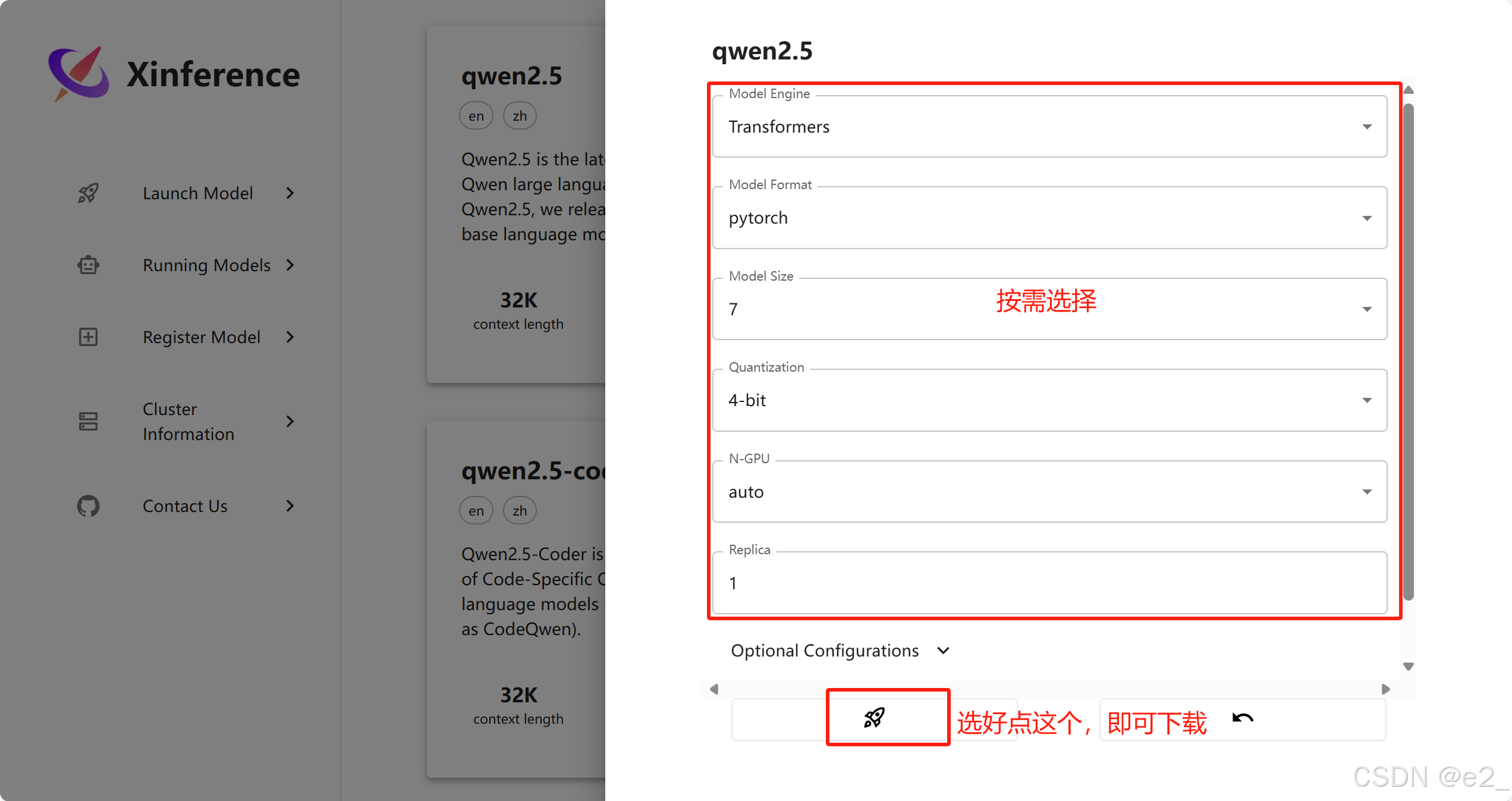 终端可以看到下载进度:
终端可以看到下载进度:

因为我在下载的时候出现cuda版本过低等一些问题,一直无法直接用xinference下载并启动模型。因此我采用第二种方法:
第二种方法:手动下载模型,在xinference上启动
下载embedding模型(bge-large-zh-v1.5):
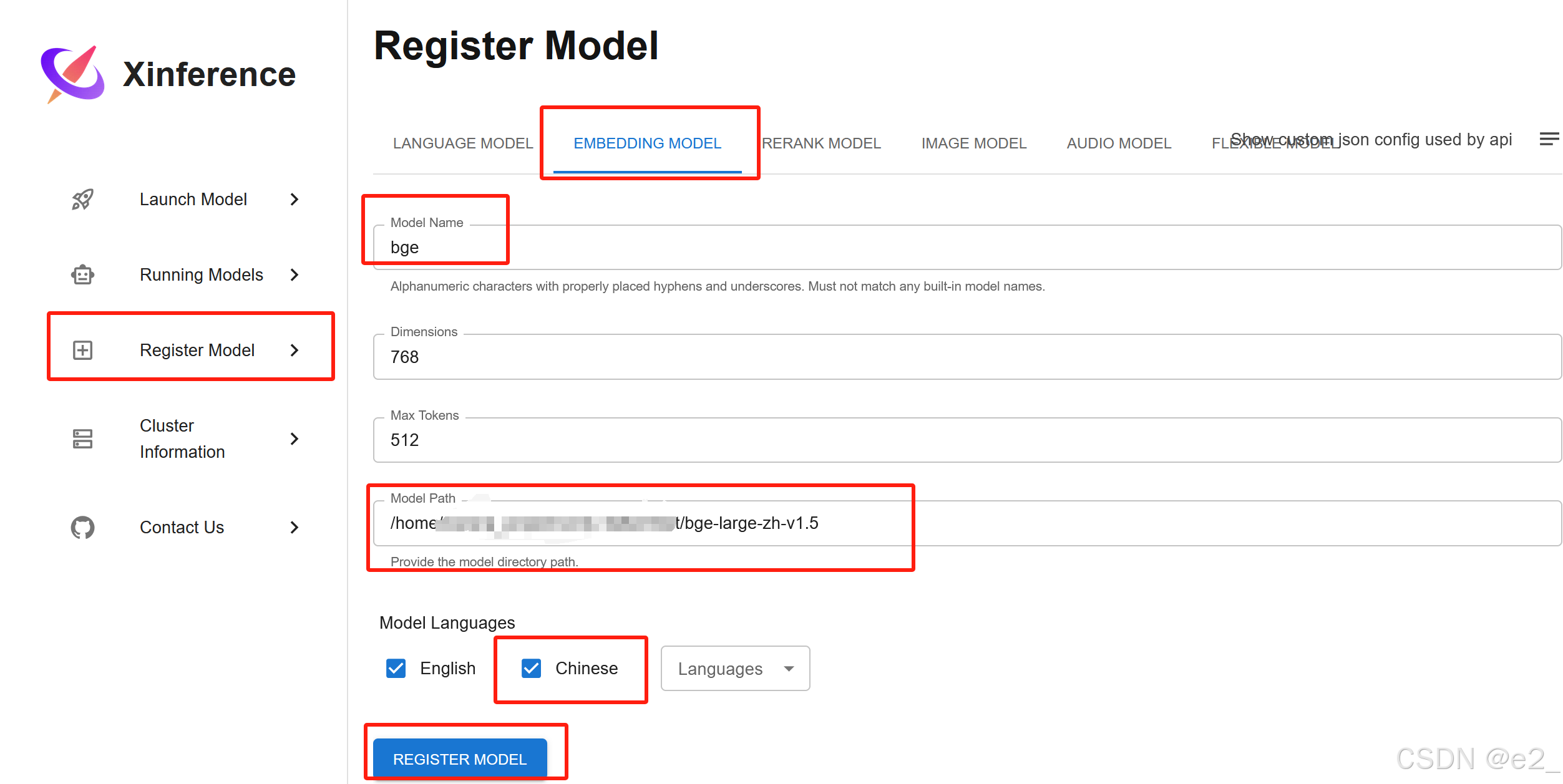
①首先下载所需的模型,并记住它的位置。如下载bge-large-zh-v1.5,我的下载位置是/home/……/bge-large-zh-v1.5
②然后在xinference上注册:
③在xinference上启动:

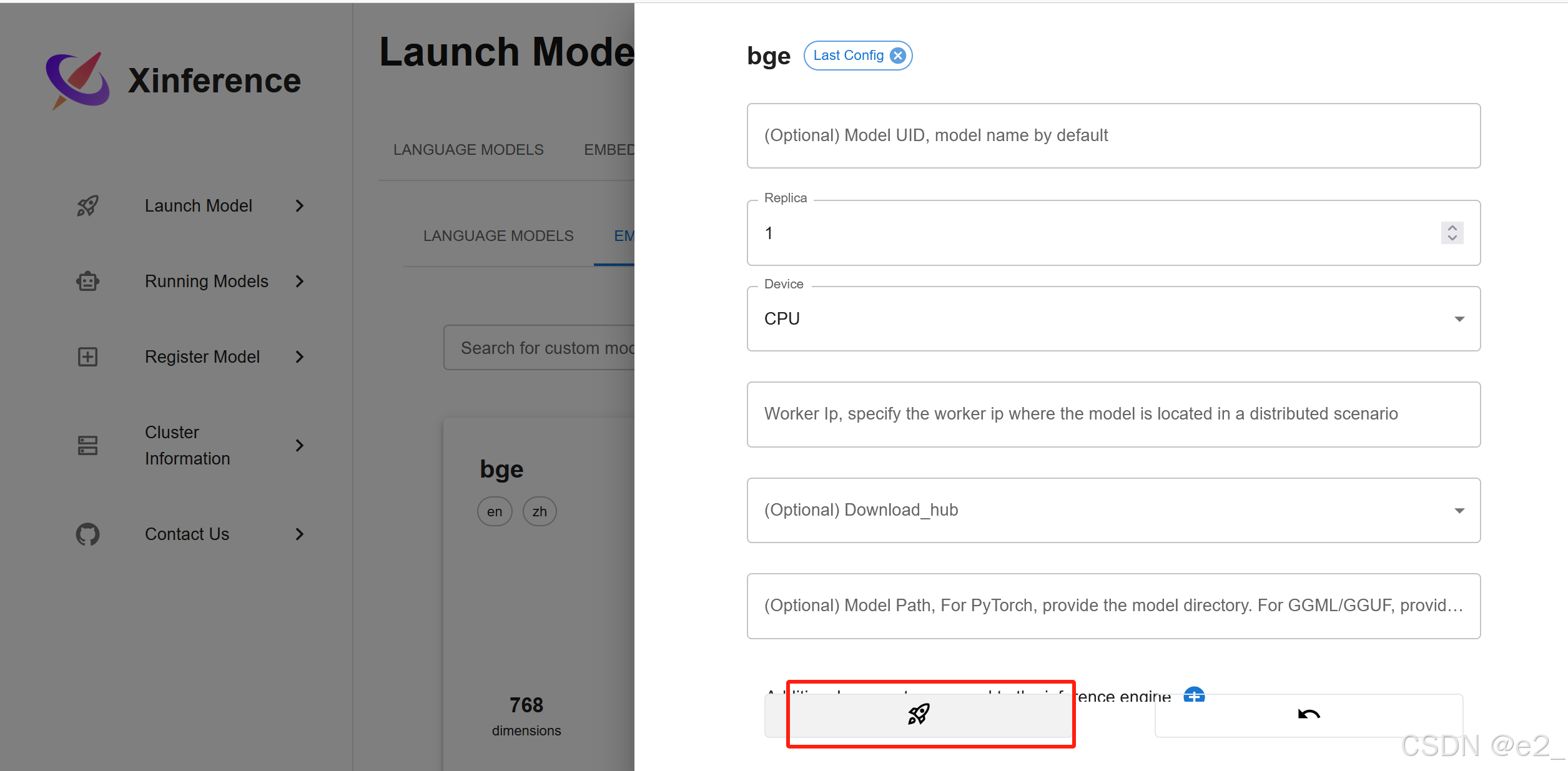
启动成功的样子:
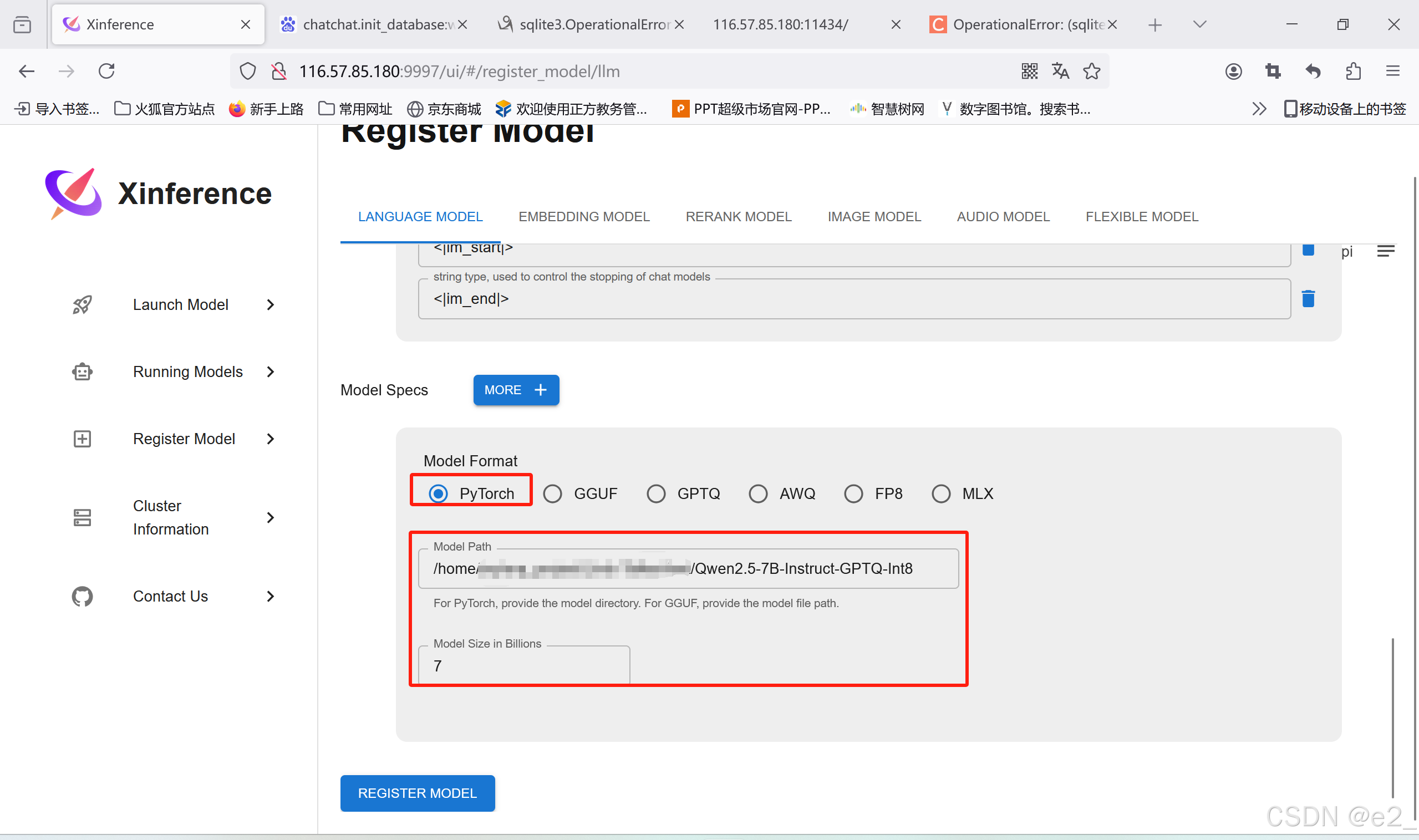
下载LLM(Qwen2.5-7B-Instruct-GPTQ-Int8):
在huggingface上手动下载Qwen2.5-7B-Instruct-GPTQ-Int8
链接:https://huggingface.co/Qwen/Qwen2.5-7B-Instruct-GPTQ-Int8/tree/main
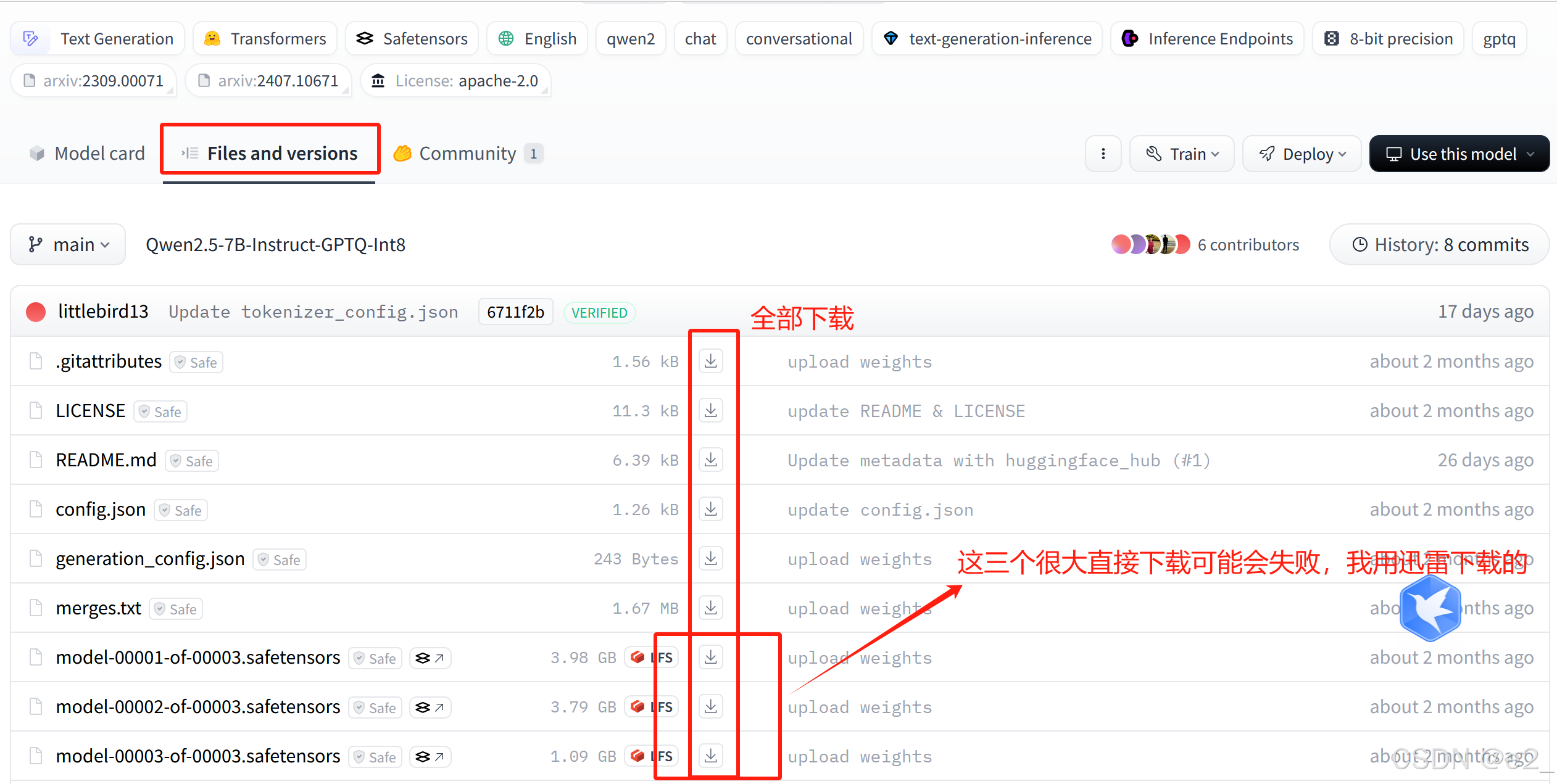
下载好上传到服务器
打开xinference的UI界面:
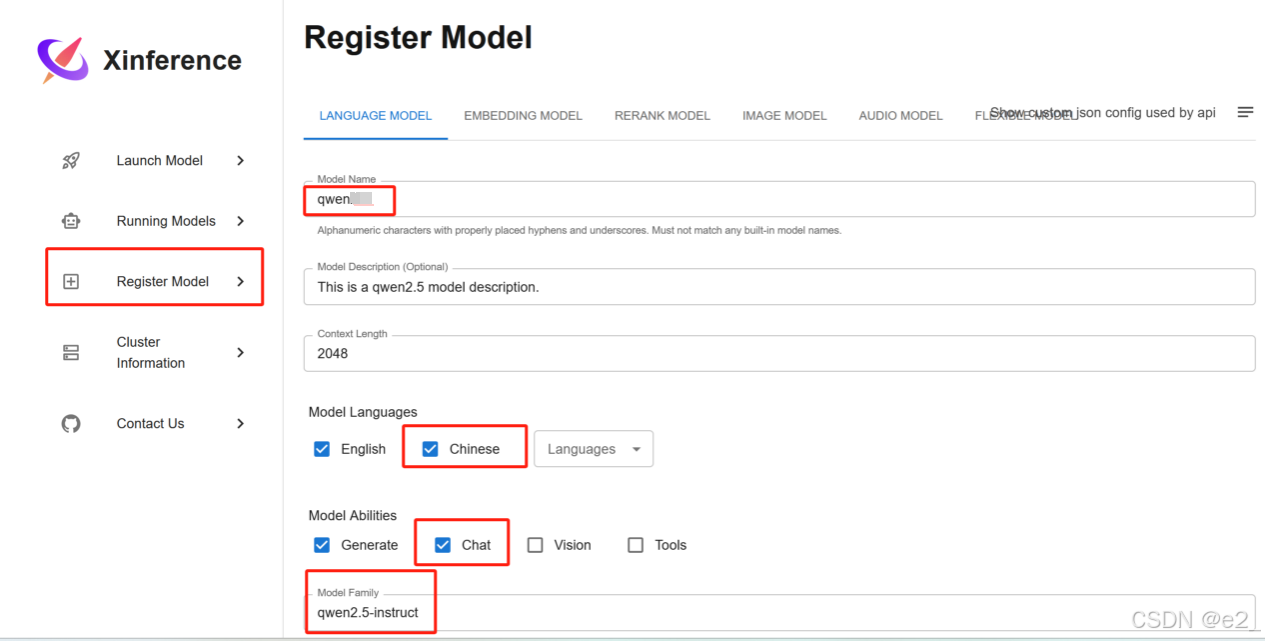
注册:
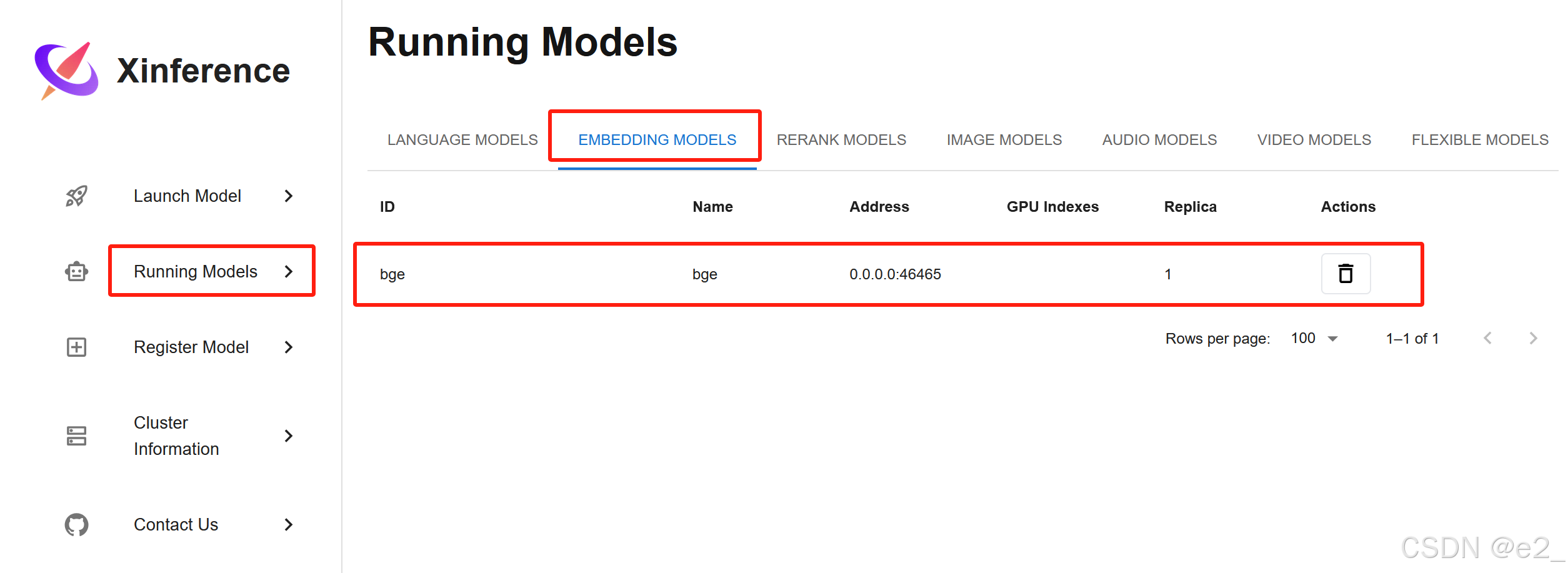
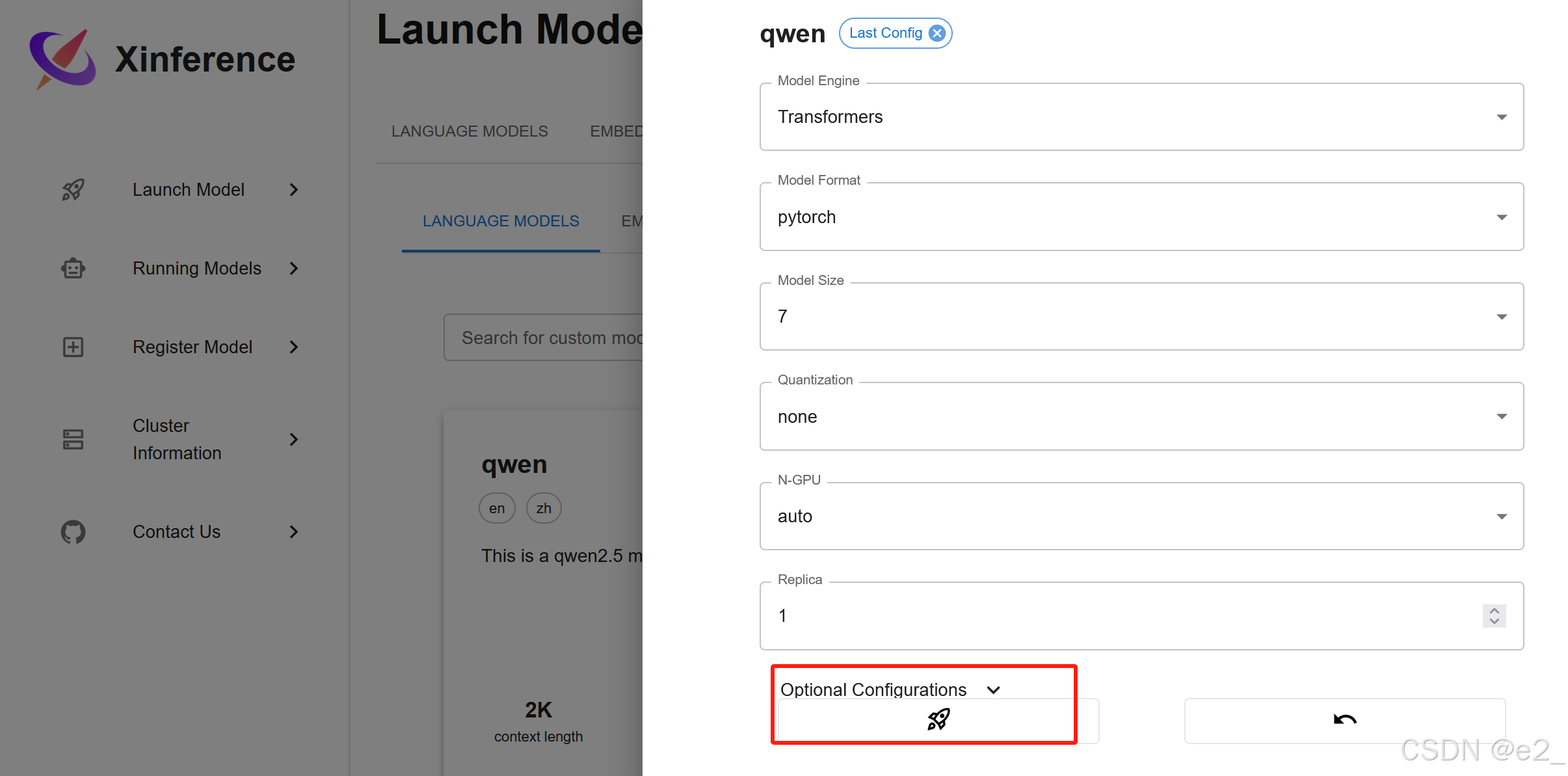
启动: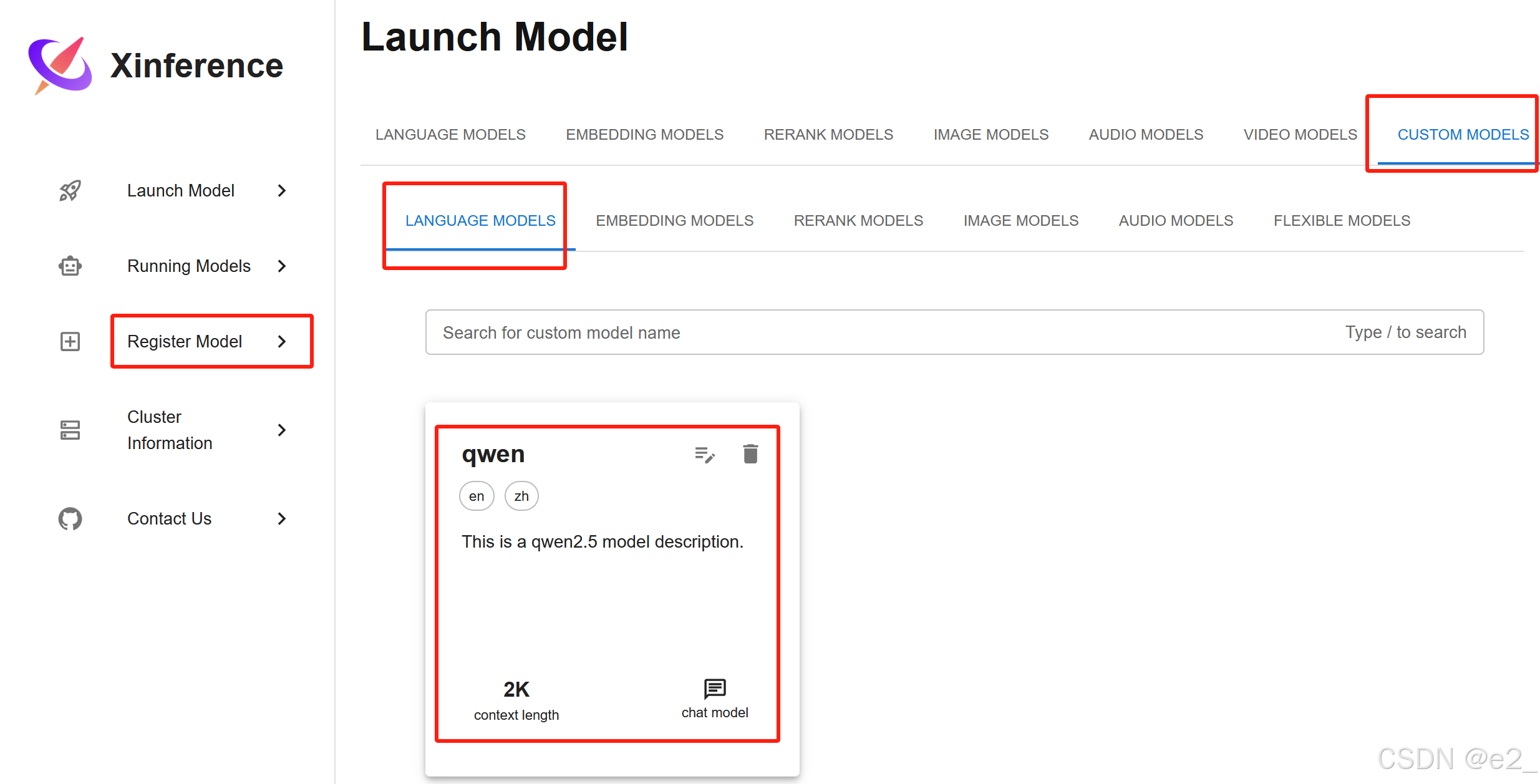
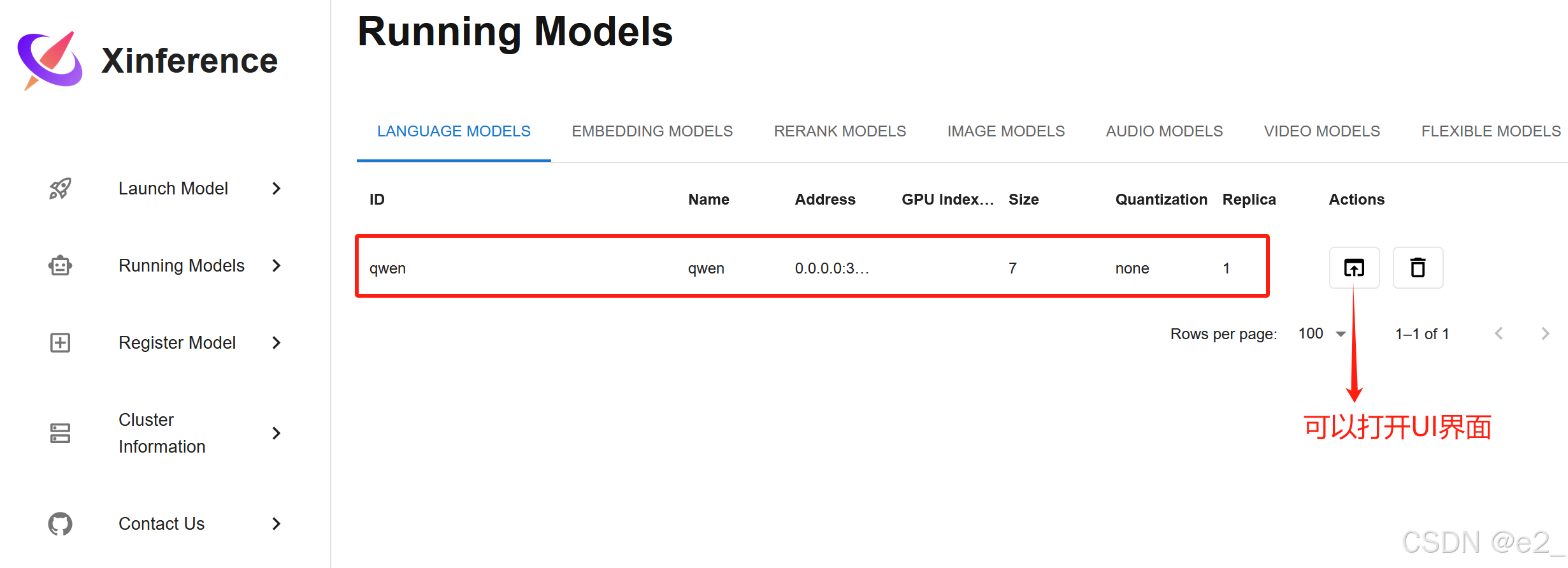
启动成功的样子:
初始化:
讯享网

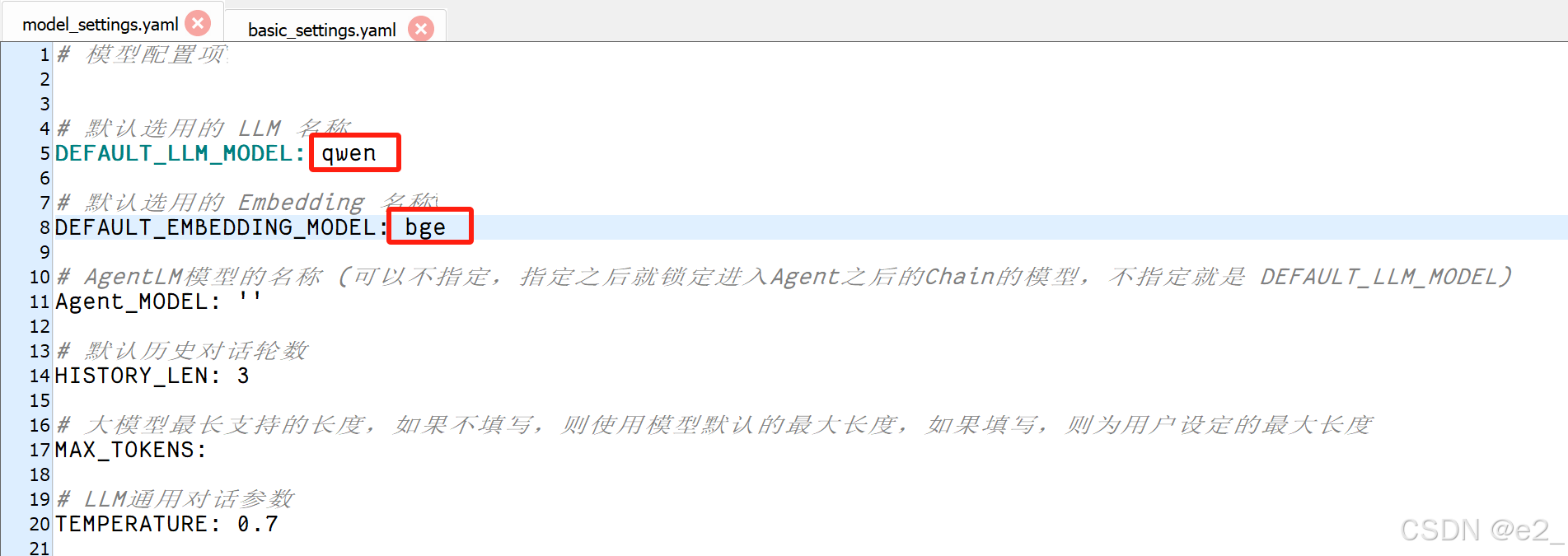
修改配置文件:
打开model_settings.yaml文件按下图进行修改,修改后保存:
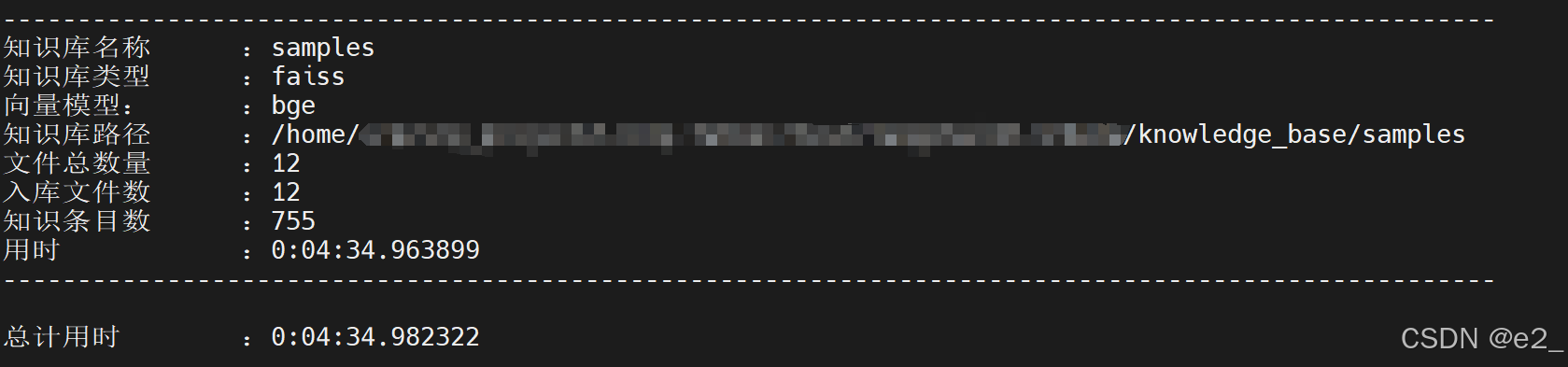
初始化知识库:
等一会,直到出现以下日志即为成功:
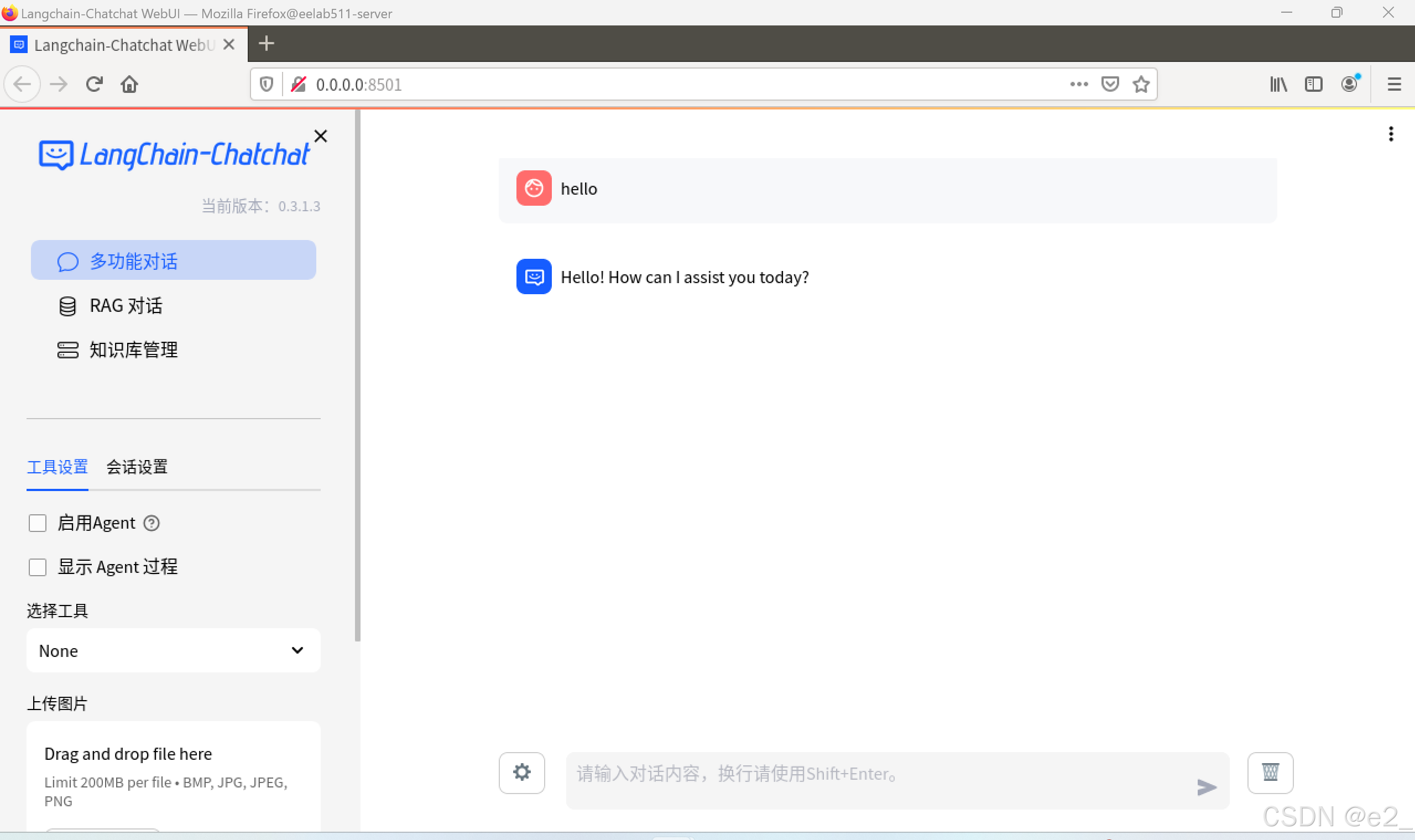
启动项目:
讯享网
成功:
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/175144.html