
在我们每天的工作中,可能需要不断地撰写一些计划、方案、总结,而这些方案很可能大多数是从网络上下载下来的。现在网络上能免费下载的资源非常少,我们采用的主要下载方式是通过截屏识别文字来实现文本复制的。复制下来的文本粘贴到word文档当中,还需要我们进一步排版。有些单位对文本格式的要求是特别严格的,必须按照政府部门规定的相关格式进行排版。
例如,以下要求为某单位的排版格式。
文字性材料排版格式要求
标题:方正小标宋-GBK二号,正文:仿宋GB2312三号,一级标题黑体,二级标题楷体,三级标题仿宋加粗。页面设置,上下边距3.7cm、3.5cm,左右边距2.8cm、2.6cm。行距磅值:固定值28磅。文章最后空4行署名、时间,具体位置在靠右边4汉字符的位置,时间用小写阿拉伯数字如2023年7月25日。
在这种情形下,我们撰写、下载并修改文本需要一定的时间,文章修改完之后还要按照格式进行排版,这也需要花费大量的时间。有些年龄大的职工仅完成计划、方案及总结的撰写这几项工作已累得疲惫不堪,而对于排版,真是一窍不通。
今天就给大家分享一款自己编写的Word文档一键排版软件,可以轻松帮助我们完成Word文档公文排版,即使你在电脑方面是小白,也可以一键搞定。从此,公文排版,再也不用求人啦,办公的文秘人员也可以腾出更多时间和精力去从事其他工作。
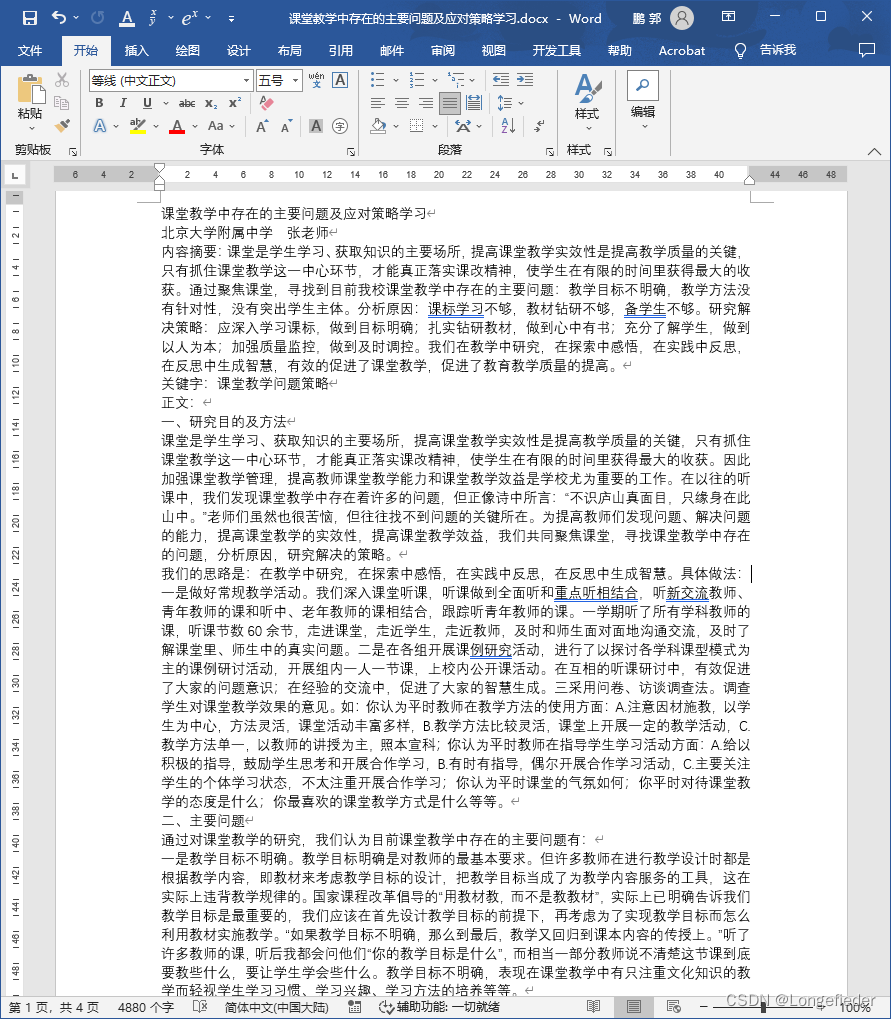
排版前


排版后
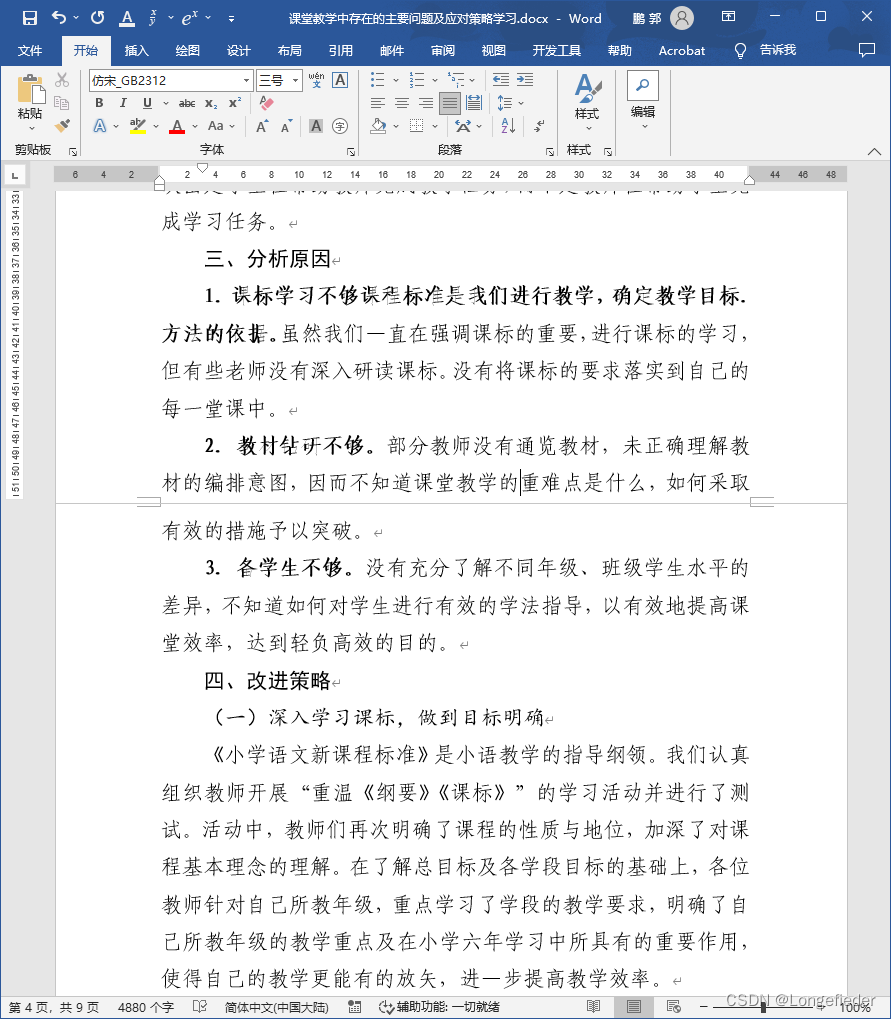
排版后
程序已完成了对文档标题、作者单位及一、二、三、四级标题的智能识别,运行效果基本满意。现将代码作以分享。
import docx from docx.oxml.ns import qn from docx.shared import Pt, Cm, Mm from docx.enum.text import * import os import sys from docx import Document from PyQt5.QtWidgets import QApplication, QFileDialog # 删除段落 def delete_paragraph(paragraph): p = paragraph._element p.getparent().remove(p) # p._p = p._element = None paragraph._p = paragraph._element = None #判断是否为落款格式 def LuoKuan(str): for i in str: if i in punc: return False if ((str[0] in num) and (str[-1] == "日") and (len(str) <= 12)) or ((str[0] in cn_num) and (str[-1] == "日") and (len(str) <= 12)): return True else: return False def setMargin(docx): section = docx.sections[0] section.page_height = Cm(29.7) section.page_width = Cm(21.0) section.left_margin = Cm(2.8) section.right_margin = Cm(2.6) section.top_margin = Cm(3.7) section.bottom_margin = Cm(3.5) #判断是否为一级标题格式(如:一、xxx) def GradeOneTitle(str): if ((str[0] in cn_num) and (str[1] == "、")) or ((str[0] in cn_num) and (str[1] in cn_num) and (str[2] == "、")): return True else: return False #判断是否为二级标题格式(如:(一)xxx) def GradeTwoTitle(str): if ((str[0] == "(") and (str[1] in cn_num) and (str[2] == ")")) or ((str[0] == "(") and (str[1] in cn_num) and (str[2] in cn_num) and (str[3] == ")")): return True else: return False #判断是否为三级标题格式(如:1.xxx) def GradeThreeTitle(str): if ((str[0] in num) and (str[1] in punc)) or ((str[0] in num) and (str[1] in num) and (str[2] in punc)): return True else: return False #判断是否为四级标题格式(如:(1)xxx) def GradeFourTitle(str): if ((str[0] == "(") and (str[1] in num) and (str[2] == ")")) or ((str[0] == "(") and (str[1] in num) and (str[2] in num) and (str[3] == ")")): return True else: return False #判断是否为五级标题格式(如:一是XXX) def GradeFiveTitle(str): if ((str[0] in cn_num) and (str[1] in must)) or ((str[0] in cn_num) and (str[1] in cn_num) and (str[1] in must)): return True else: return False def OneKeyWord(): global cn_num,num,punc,must cn_num = ["一", "二", "三", "四", "五", "六", "七", "八", "九", "十"] num = ["1", "2", "3", "4", "5", "6", "7", "8", "9", "0"] punc = ["。", ",", "!", "?", ":", ";", "、", ".", "(", ")","."] must = ["要", "是", "能"] filecnt = 0 print('欢迎使用Word一键排版工具!创作者:') confirm= input("是否打开Word文档?输入“Y”表示“打开”,输入“N”表示“取消”!") if confirm == 'Y' or confirm == 'y': a = QApplication(['']) files, stylel = QFileDialog.getOpenFileNames(caption="多文件选择", directory="/", filter="Word 文档(*.docx)") print(files) # 打印所选文件全部路径(包括文件名和后缀名)和文件类型 for file in files: docx = Document(file) paragraphcnt = 0 filecnt= filecnt+1 print('这是第%s个文件:%s' %(filecnt,file)) for paragraph in docx.paragraphs: paragraphcnt = paragraphcnt +1 paragraph.text=paragraph.text.replace(",",",") paragraph.text=paragraph.text.replace(";",";") paragraph.text=paragraph.text.replace(":",":") paragraph.text=paragraph.text.replace("!","!") paragraph.text=paragraph.text.replace("?","?") paragraph.text=paragraph.text.replace("(","(") paragraph.text=paragraph.text.replace(")",")") paragraph.text=paragraph.text.replace(" ","") paragraph.text=paragraph.text.replace("\t", "") paragraph.text = paragraph.text.replace("\n", "") if paragraph.text == '': delete_paragraph(paragraph) paragraphcnt = paragraphcnt-1 continue paragraph.paragraph_format.left_indent = 0 #预先对缩进赋值, 防止对象为空报错 paragraph.paragraph_format.element.pPr.ind.set(qn("w:firstLineChars"), '0') #并去除缩进 paragraph.paragraph_format.element.pPr.ind.set(qn("w:firstLine"), '0') paragraph.paragraph_format.element.pPr.ind.set(qn("w:leftChars"), '0') paragraph.paragraph_format.element.pPr.ind.set(qn("w:left"), '0') paragraph.paragraph_format.element.pPr.ind.set(qn("w:rightChars"), '0') paragraph.paragraph_format.element.pPr.ind.set(qn("w:right"), '0') print('这是第%s段' %paragraphcnt) print(paragraph.text) if paragraphcnt == 1 and len(paragraph.text)<40: #处理头部空行 #标题(方正小标宋_GBK、2号、加粗、居中、下端按2号字空一行) paragraph.paragraph_format.line_spacing=Pt(28) #行距固定值28磅 paragraph.paragraph_format.space_after = Pt(0) #段后间距=0 for run in paragraph.runs: run.font.size = Pt(22) # 字体大小2号 run.bold = False # 加粗 run.font.name = '方正小标宋_GBK' # 控制是西文时的字体 run.element.rPr.rFonts.set(qn('w:eastAsia'), '方正小标宋_GBK') # 控制是中文时的字体 paragraph.alignment = WD_ALIGN_PARAGRAPH.CENTER # 居中 continue elif paragraphcnt == 2 and len(paragraph.text) < 30: # 作者单位、姓名 paragraph.paragraph_format.line_spacing = Pt(28) # 行距固定值28磅 paragraph.paragraph_format.space_after = Pt(0) # 段后间距=0 for run in paragraph.runs: run.font.size = Pt(16) # 字体大小2号 run.bold = False # 加粗 run.font.name = '楷体' # 控制是西文时的字体 run.element.rPr.rFonts.set(qn('w:eastAsia'), '楷体') # 控制是中文时的字体 paragraph.alignment = WD_ALIGN_PARAGRAPH.CENTER # 居中 continue elif paragraphcnt == 3 and len(paragraph.text) < 30 and (paragraph.text[0] == "(") and (paragraph.text[1] in num): # 日期,如(2023年6月15日) paragraph.paragraph_format.line_spacing = Pt(28) # 行距固定值28磅 paragraph.paragraph_format.space_after = Pt(0) # 段后间距=0 for run in paragraph.runs: run.font.size = Pt(16) # 字体大小2号 run.bold = False # 加粗 run.font.name = '楷体' # 控制是西文时的字体 run.element.rPr.rFonts.set(qn('w:eastAsia'), '楷体') # 控制是中文时的字体 paragraph.alignment = WD_ALIGN_PARAGRAPH.CENTER # 居中 continue # #处理正文 else: paragraph.paragraph_format.line_spacing = Pt(28) # 行距固定值28磅 paragraph.paragraph_format.space_after = Pt(0) # 段后间距=0 paragraph.paragraph_format.first_line_indent = Pt(32) for run in paragraph.runs: run.font.size = Pt(16) # 字体大小3号 run.bold = False # 字体不加粗 run.font.name = '仿宋_GB2312' run.element.rPr.rFonts.set(qn('w:eastAsia'), '仿宋_GB2312') if GradeOneTitle(run.text): #判断是否为一级标题格式(如:一、xxx) run.font.name = '黑体' run.element.rPr.rFonts.set(qn('w:eastAsia'), '黑体') elif GradeTwoTitle(run.text): #判断是否为二级标题格式(如:(一)xxx) if "。" not in run.text: run.font.name = '楷体' run.element.rPr.rFonts.set(qn('w:eastAsia'), '楷体') else: run.text = run.text.split('。',1) run.font.name = '楷体' run.element.rPr.rFonts.set(qn('w:eastAsia'), '楷体') elif GradeThreeTitle(run.text): #判断是否为三级标题格式(如:1.xxx) if "。" not in run.text: if (run.text[0] in num) and (run.text[1] in punc): run.text = run.text.replace(run.text[1], ".",1) if (run.text[0] in num) and (run.text[1] in num) and (run.text[2] in punc): run.text = run.text.replace(run.text[2], ".", 1) run.font.name = '仿宋_GB2312' run.element.rPr.rFonts.set(qn('w:eastAsia'), '仿宋_GB2312') run.bold = True # 字体加粗 else: if (run.text[0] in num) and (run.text[1] in punc): run.text = run.text.replace(run.text[1], ".", 1) if (run.text[0] in num) and (run.text[1] in num) and (run.text[2] in punc): run.text = run.text.replace(run.text[2], ".", 1) sentence_to_bold = run.text.split('。')[0]+"。" sentence_not_to_bold = run.text.split('。',1)[1] paragraph.insert_paragraph_before(sentence_to_bold) docx.paragraphs[paragraphcnt - 1].paragraph_format.first_line_indent = Pt(32) docx.paragraphs[paragraphcnt - 1].paragraph_format.line_spacing = Pt(28) # 行距固定值28磅 docx.paragraphs[paragraphcnt - 1].paragraph_format.space_after = Pt(0) # 段后间距=0 docx.paragraphs[paragraphcnt - 1].runs[0].font.name = '仿宋_GB2312' docx.paragraphs[paragraphcnt - 1].runs[0].font.size = Pt(16) # 字体大小3号 docx.paragraphs[paragraphcnt - 1].runs[0].element.rPr.rFonts.set(qn('w:eastAsia'), '仿宋_GB2312') docx.paragraphs[paragraphcnt - 1].runs[0].bold = True # 字体加粗 docx.paragraphs[paragraphcnt - 1].add_run(sentence_not_to_bold).bold = False docx.paragraphs[paragraphcnt - 1].runs[1].font.name = '仿宋_GB2312' docx.paragraphs[paragraphcnt - 1].runs[1].font.size = Pt(16) # 字体大小3号 docx.paragraphs[paragraphcnt - 1].runs[1].element.rPr.rFonts.set(qn('w:eastAsia'), '仿宋_GB2312') delete_paragraph(paragraph) elif GradeFourTitle(run.text): #判断是否为四级标题格式(如:(1)xxx) if "。" not in run.text: run.font.name = '仿宋_GB2312' run.element.rPr.rFonts.set(qn('w:eastAsia'), '仿宋_GB2312') run.bold = True # 字体加粗 else: sentence_to_bold = run.text.split('。')[0]+"。" sentence_not_to_bold = run.text.split('。',1)[1] paragraph.insert_paragraph_before(sentence_to_bold) docx.paragraphs[paragraphcnt - 1].paragraph_format.first_line_indent = Pt(32) docx.paragraphs[paragraphcnt - 1].paragraph_format.line_spacing = Pt(28) # 行距固定值28磅 docx.paragraphs[paragraphcnt - 1].paragraph_format.space_after = Pt(0) # 段后间距=0 docx.paragraphs[paragraphcnt - 1].runs[0].font.name = '仿宋_GB2312' docx.paragraphs[paragraphcnt - 1].runs[0].font.size = Pt(16) # 字体大小3号 docx.paragraphs[paragraphcnt - 1].runs[0].element.rPr.rFonts.set(qn('w:eastAsia'), '仿宋_GB2312') docx.paragraphs[paragraphcnt - 1].runs[0].bold = True # 字体加粗 docx.paragraphs[paragraphcnt - 1].add_run(sentence_not_to_bold).bold = False docx.paragraphs[paragraphcnt - 1].runs[1].font.name = '仿宋_GB2312' docx.paragraphs[paragraphcnt - 1].runs[1].font.size = Pt(16) # 字体大小3号 docx.paragraphs[paragraphcnt - 1].runs[1].element.rPr.rFonts.set(qn('w:eastAsia'), '仿宋_GB2312') delete_paragraph(paragraph) elif GradeFiveTitle(run.text): #判断是否为五级标题格式(如:一是xxx) if "。" not in run.text: run.font.name = '仿宋_GB2312' run.element.rPr.rFonts.set(qn('w:eastAsia'), '仿宋_GB2312') run.bold = True # 字体加粗 else: sentence_to_bold = run.text.split('。')[0]+"。" sentence_not_to_bold = run.text.split('。',1)[1] paragraph.insert_paragraph_before(sentence_to_bold) docx.paragraphs[paragraphcnt - 1].paragraph_format.first_line_indent = Pt(32) docx.paragraphs[paragraphcnt - 1].paragraph_format.line_spacing = Pt(28) # 行距固定值28磅 docx.paragraphs[paragraphcnt - 1].paragraph_format.space_after = Pt(0) # 段后间距=0 docx.paragraphs[paragraphcnt - 1].runs[0].font.name = '仿宋_GB2312' docx.paragraphs[paragraphcnt - 1].runs[0].font.size = Pt(16) # 字体大小3号 docx.paragraphs[paragraphcnt - 1].runs[0].element.rPr.rFonts.set(qn('w:eastAsia'), '仿宋_GB2312') docx.paragraphs[paragraphcnt - 1].runs[0].bold = True # 字体加粗 docx.paragraphs[paragraphcnt - 1].add_run(sentence_not_to_bold).bold = False docx.paragraphs[paragraphcnt - 1].runs[1].font.name = '仿宋_GB2312' docx.paragraphs[paragraphcnt - 1].runs[1].font.size = Pt(16) # 字体大小3号 docx.paragraphs[paragraphcnt - 1].runs[1].element.rPr.rFonts.set(qn('w:eastAsia'), '仿宋_GB2312') delete_paragraph(paragraph) elif LuoKuan(run.text): # 判断是否为落款格式 run.font.name = '仿宋_GB2312' run.element.rPr.rFonts.set(qn('w:eastAsia'), '仿宋_GB2312') run.text = "\r" * 2 + run.text # 前置空格,顶到最右,需手动调整空格 paragraph.paragraph_format.left_indent = Pt(288) #18B*16Pt=288Pt else: #普通正文格式 run.font.name = '仿宋_GB2312' run.element.rPr.rFonts.set(qn('w:eastAsia'), '仿宋_GB2312') setMargin(docx) docx.save(file) if __name__ == '__main__': OneKeyWord() os.system("pause")讯享网
这款软件还有一个优点,就是可以批量处理word。但也有一些缺点,就是暂时只支持docx格式的Word文档。同时,在今天早上帮助同事运用些软件排版时,无意中发现,软件竟无法识别word文档中使用了自动编号的标题,再者界面过于丑陋,后期将进下一步完善代码,力争出现新的迭代UI界面作品,敬请关注!
编程不易,且用且珍惜!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/17140.html