
<p><strong>压测监控平台</strong></p> 讯享网
讯享网
梯度压测:分析接口性能瓶颈
压测接口:响应时间20ms,响应数据包3.8kb,请求数据包0.421kb
讯享网
是与RT和服务端线程数有关的
压测配置:
情况01-模拟低延时场景,用户访问接口并发逐渐增加的过程。
预计接口的响应时间为20ms
线程梯度:5、10、15、20、25、30、35、40个线程
循环请求次数5000次
时间设置:Ramp-up period(inseconds)的值设为对应线程数
测试总时长:约等于20ms x 5000次 x 8 = 800s = 13分
配置断言:超过3s,响应状态码不为20000,则为无效请求
机器环境
应用服务器配置:4C8G
外网-网络带宽25Mbps (峰值)
内网-网络带宽基础1.5/最高10Gbit/s
集群规模:单节点
服务版本:v1.0
数据库服务器配置:4C8G
配置监听器:
- 聚合报告:添加聚合报告
- 查看结果树:添加查看结果树
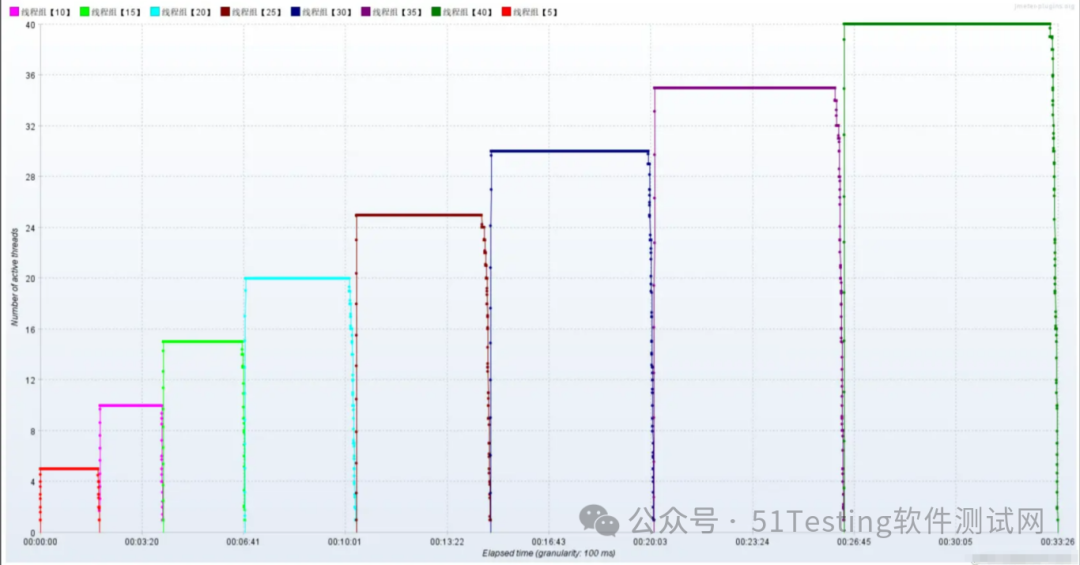
- 活动线程数:压力机中活动的线程数
- TPS统计分析:每秒事务树
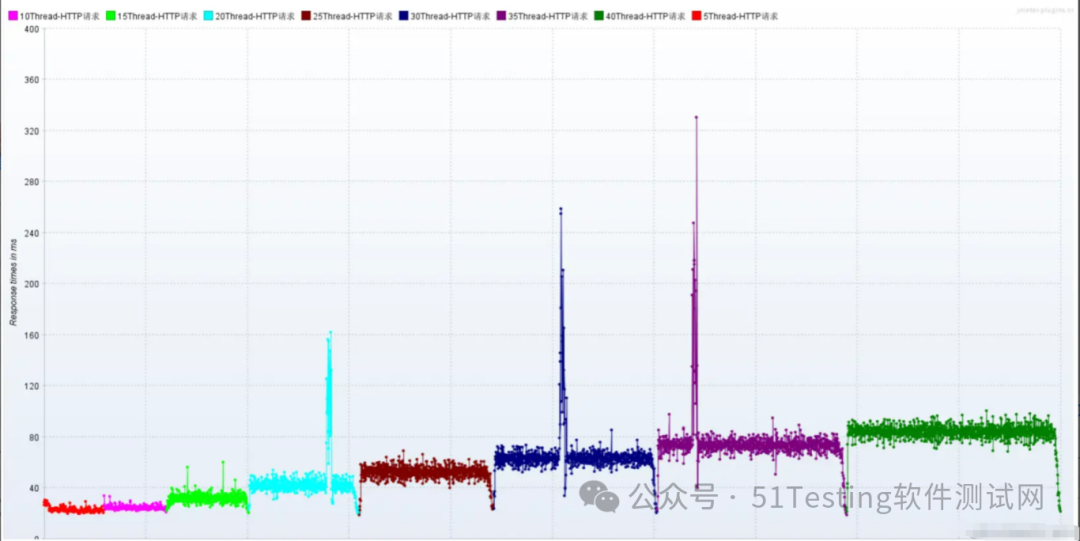
- RT统计分析:响应时间
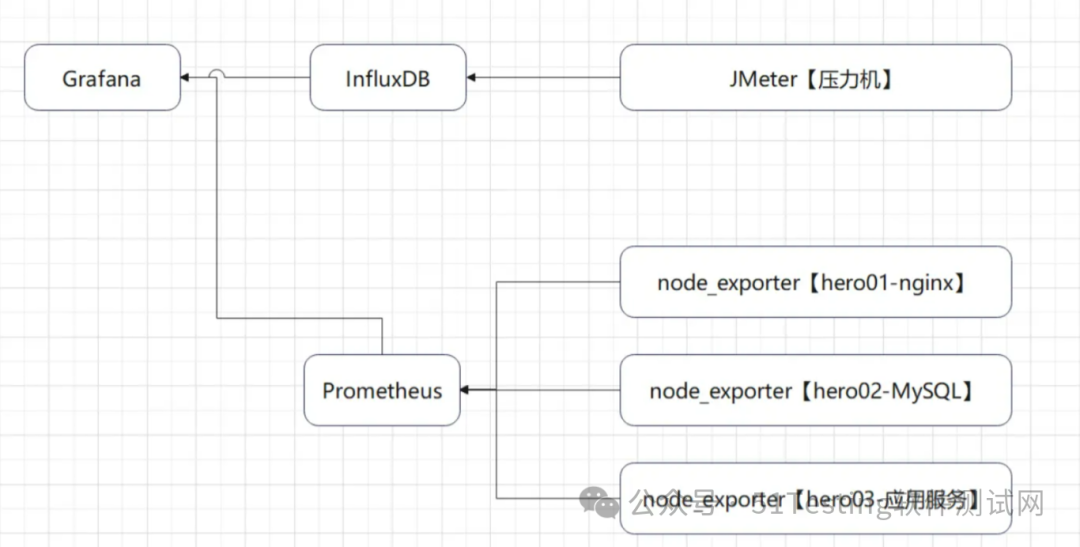
- 后置监听器,将压测信息汇总到InfluxDB,在Grafana中呈现
- 压测监控平台:JMeter DashBoard
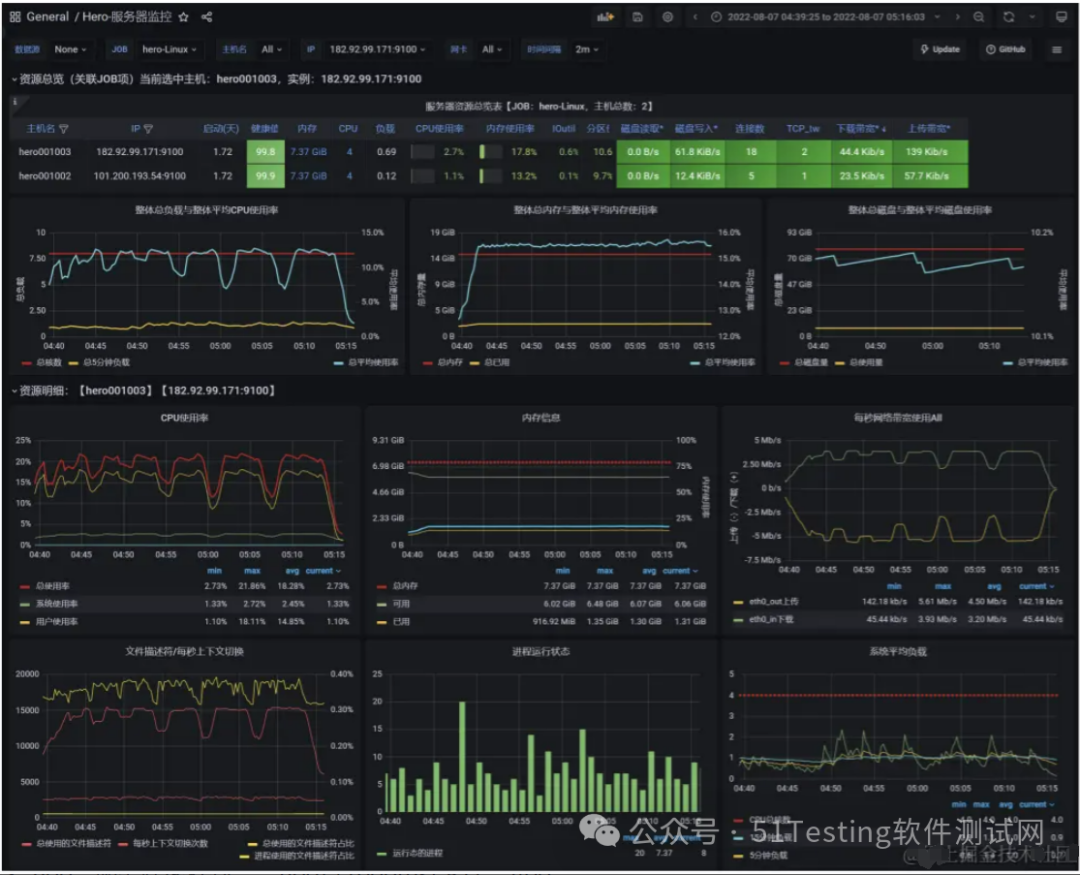
应用服务器:内存、网络、磁盘、系统负载情况
MySQL服务器:内存、网络、磁盘、系统负载情况
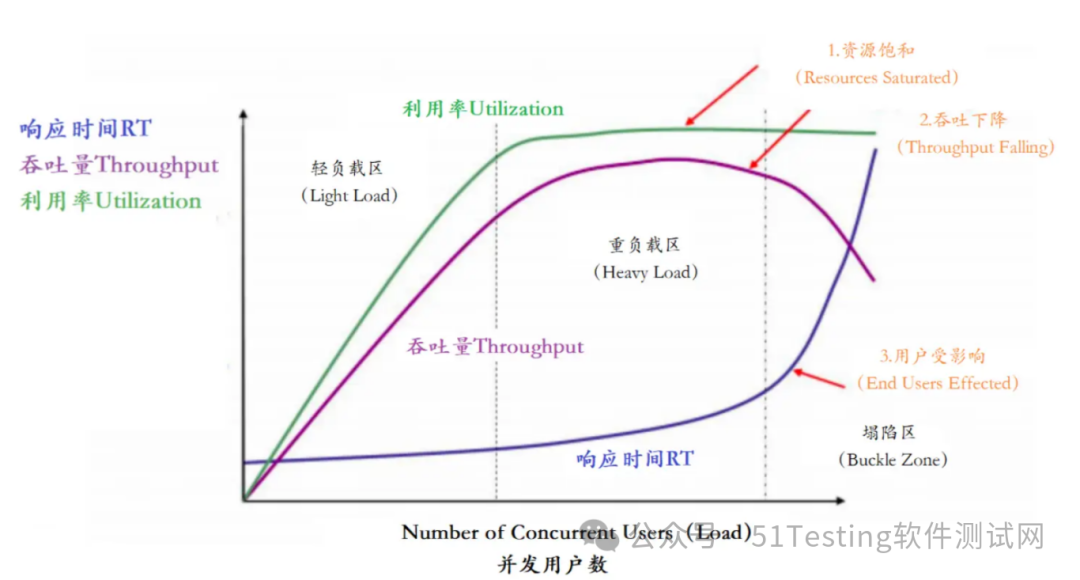
性能瓶颈剖析
1)梯度压测,测出瓶颈
- 进一步提升压力,发现性能瓶颈
- 使用线程:5,然后循环5000次,共2.5万个样本
- 使用线程:10,然后循环5000次,共5万个样本
- 使用线程:15,然后循环5000次,共7.5万个样本
- 使用线程:20,然后循环5000次,共10万个样本
- 使用线程:25,然后循环5000次,共12.5万个样本
- 使用线程:30,然后循环5000次,共15万个样本
- 使用线程:35,然后循环5000次,共17.5万个样本
- 使用线程:40,然后循环5000次,共20万个样本
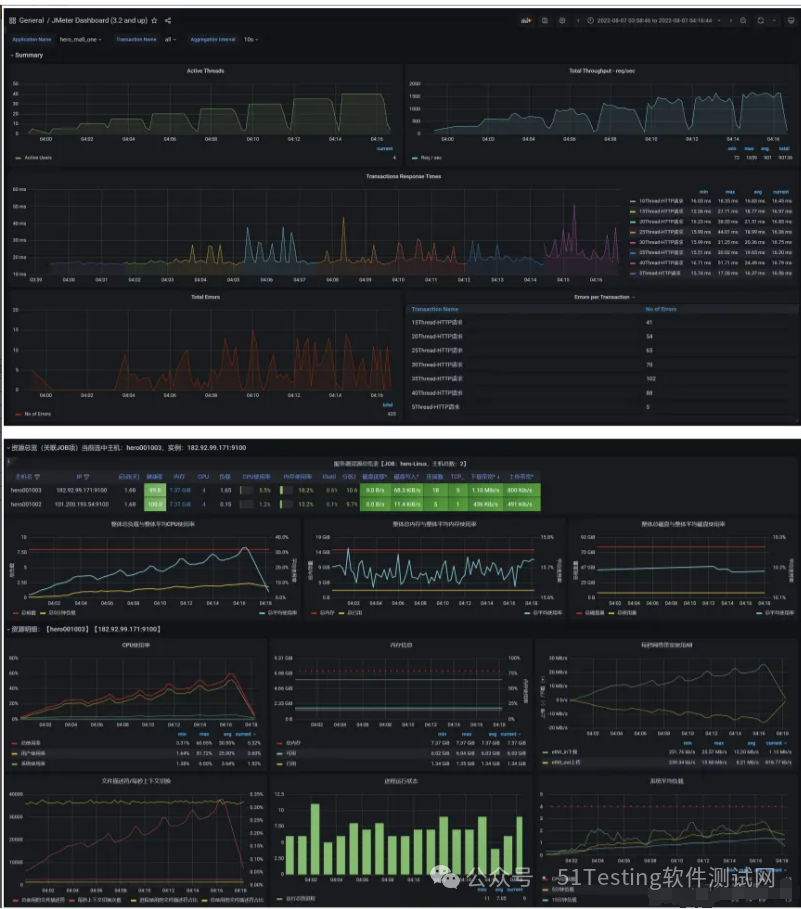
聚合报告

Active Threads
RT
TPS

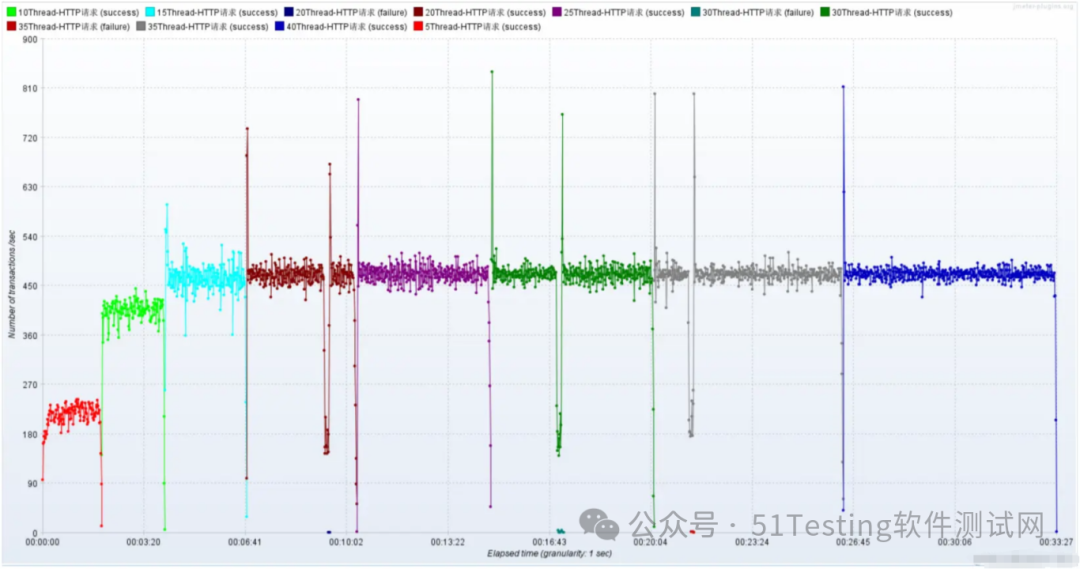
此时就是到了重负载区
压测监控平台与JMeter压测结果一致
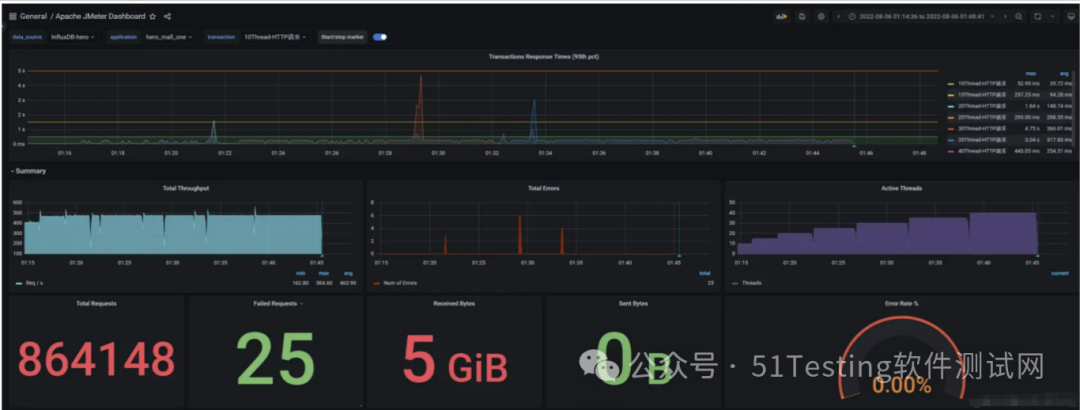
压了13分钟,产生了5G的数据,按照我们的阿里云服务器配置,相当于三四块钱没了
压测中服务器监控指标
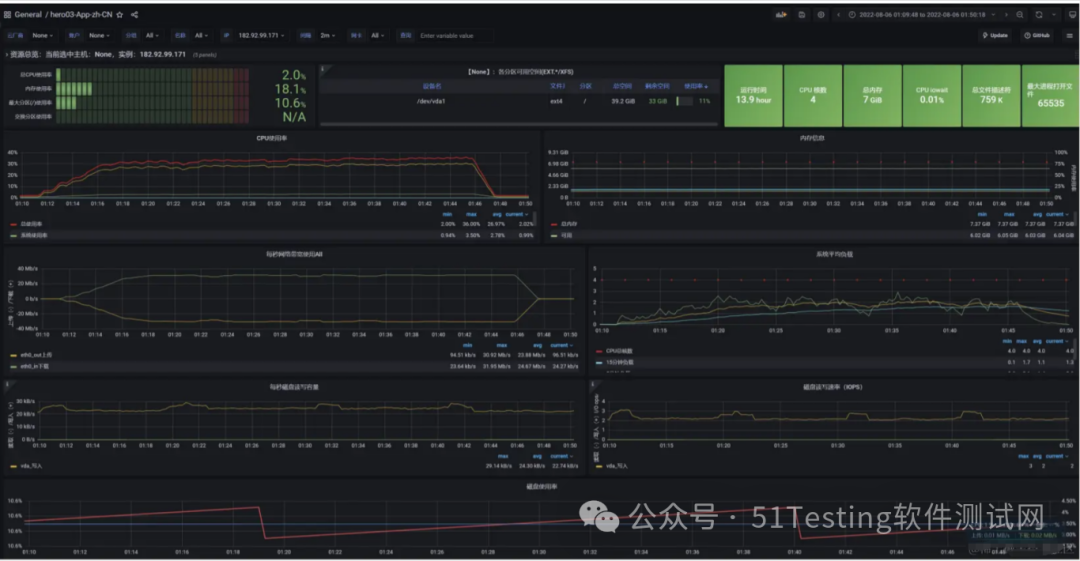
2)问题1:网络到达瓶颈
注意:系统网络带宽为25Mbps
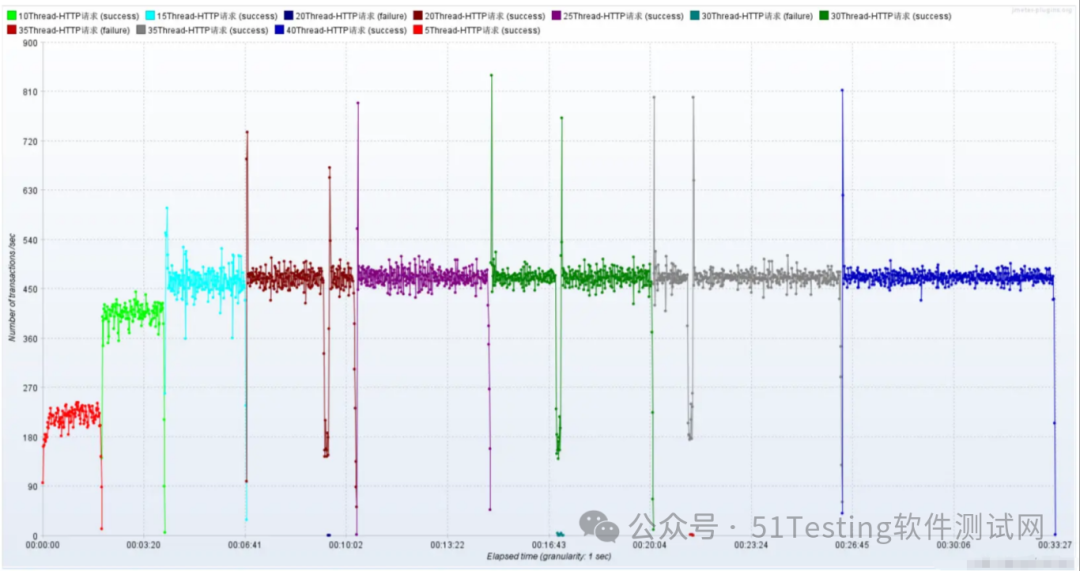
结论:随着压力的上升,TPS不再增加,接口响应时间逐渐在增加,偶尔出现异常,瓶颈凸显。系统的负载不高。CPU、内存正常,说明系统这部分资源利用率不高。带宽带宽显然已经触顶了。
- 优化方案:
方案01-降低接口响应数据包大小(把不应该推送给用户的优化掉)
返回数据量小的接口,响应数据包0.6kb,请求数据包0.421kb
讯享网
方案02-提升带宽【或者在内网压测】
25Mbps –> 100Mbps(但是会变贵)
云服务器内网:这里在Linux中执行JMeter压测脚本
所以就是,想要高并发,money得有才行。
方案03-CDN
买CDN,给用户离他最近的流量
- 优化之后:
方案01-降低接口响应数据包大小,压测结果

问题:可不可以基于RT与TPS算出服务端并发线程数?
服务端线程数计算公式:TPS/ (1000ms/ RT均值)
- RT=21ms,TPS=800,服务端线程数:= 800/ (1000ms/ RT均值) = 17
- RT=500ms,TPS=800,服务端线程数:= 800/ (1000ms/ RT均值) = 400
- RT=1000ms,TPS=800,服务端线程数:= 800/ (1000ms/ RT均值) = 800
结论:
- 在低延时场景下,服务瓶颈主要在服务器带宽。
- TPS数量等于服务端线程数 乘以 (1000ms/ RT均值)
- RT=21ms,TPS=800,服务端线程数:= 800/ (1000ms/ RT均值) = 17
3)问题2:接口的响应时间是否正常?是不是所有的接口响应都这么快?
情况02-模拟高延时场景,用户访问接口并发逐渐增加的过程。接口的响应时间为500ms,
- 线程梯度:100、200、300、400、500、600、700、800个线程;
- 循环请求次数200次
- 时间设置:Ramp-up period(inseconds)的值设为对应线程数的1/10;
- 测试总时长:约等于500ms x 200次 x 8 = 800s = 13分
- 配置断言:超过3s,响应状态码不为20000,则为无效请求
讯享网

响应慢接口:500ms+,响应数据包3.8kb,请求数据包0.421kb
测试结果:RT、TPS、网络IO、CPU、内存、磁盘IO

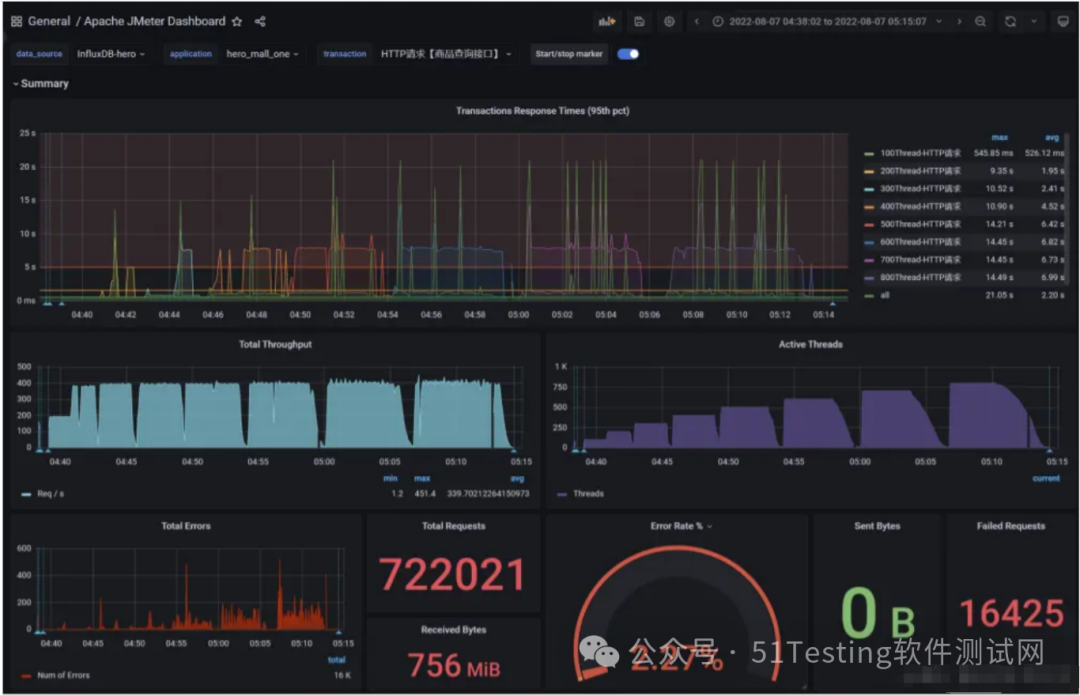
结论:
- 在高延时场景下,服务瓶颈主要在容器最大并发线程数。
- RT=500ms,TPS=800,服务端线程数:= 800/ (1000ms/ RT) = 400
Tomcat的默认线程数是200
- 观察服务容器最大线程数,发现处理能力瓶颈卡在容器端
4)问题3:TPS在上升到一定的值之后,异常率较高
可以理解为与IO模型有关系,因为当前使用的是阻塞式IO模型。这个问题我们在服务容器优化部分解决。
因为是使用的是NIO,阻塞了之后我们前面配置的是超过3s就会报错,所以报异常了。
分布式压测
使用JMeter做大并发压力测试的场景下,单机受限与内存、CPU、网络IO,会出现服务器压力还没有上去,但是压测机压力太大已经死机!为了让JMeter拥有更强大的负载能力,JMeter提供分布式压测能力。
- 单机网络带宽有限
- 高延时场景下,单机可模拟最大线程数有限
如下是分布式压测架构:
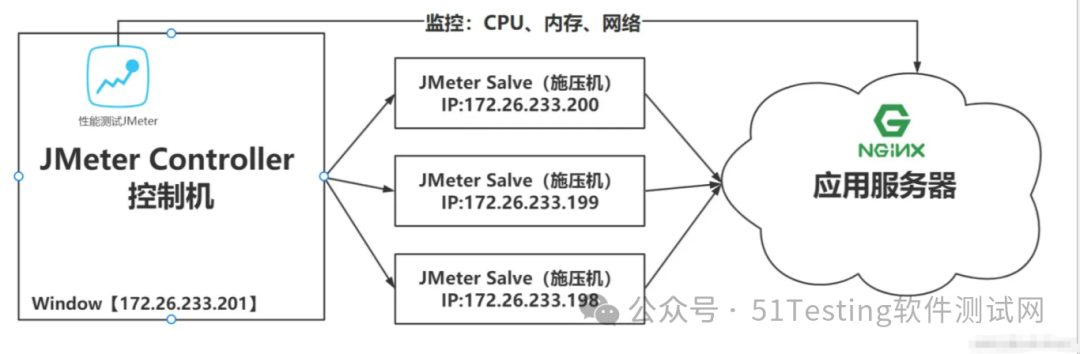
注意:在JMeter Master节点配置线程数10,循环100次【共1000次请求样本】。如果有3台Salve 节点。
那么Master启动压测后,每台Salve都会对被测服务发起10x100次请求。因此,压测产生的总样本数量是:10 x 100 x 3 = 3000次。
搭建JMeter Master控制机和JMeter Salve施压机
- 第一步:三台JMeter Salve搭建在Linux【Centos7】环境下
- 第二步:JMeter Master搭建在Windows Server环境下【当然也可以搭建在Linux里面,这里用win是为了方便观看】
搭建注意事项:
- 需保证Salve和Server都在一个网络中。如果在多网卡环境内,则需要保证启动的网卡都在一个网段。
- 需保证Server和Salve之间的时间是同步的。
- 需在内网配置JMeter主从通信端口【1个固定,1个随机】,简单的配置方式就是关闭防火墙,但存在安全隐患。
Windows Server部署JMeter Master
与Window中安装JMeter一样,略
Linux部署JMeter Salve
- (1)下载安装
讯享网
- (2)配置修改rmi主机hostname
- (3)配置rmi_keystore.jks
- (4)启动jmeter-server服务
讯享网
分布式环境配置
- (1)确保JMeter Master和Salve安装正确。
- (2)Salve启动,并监听1099端口。
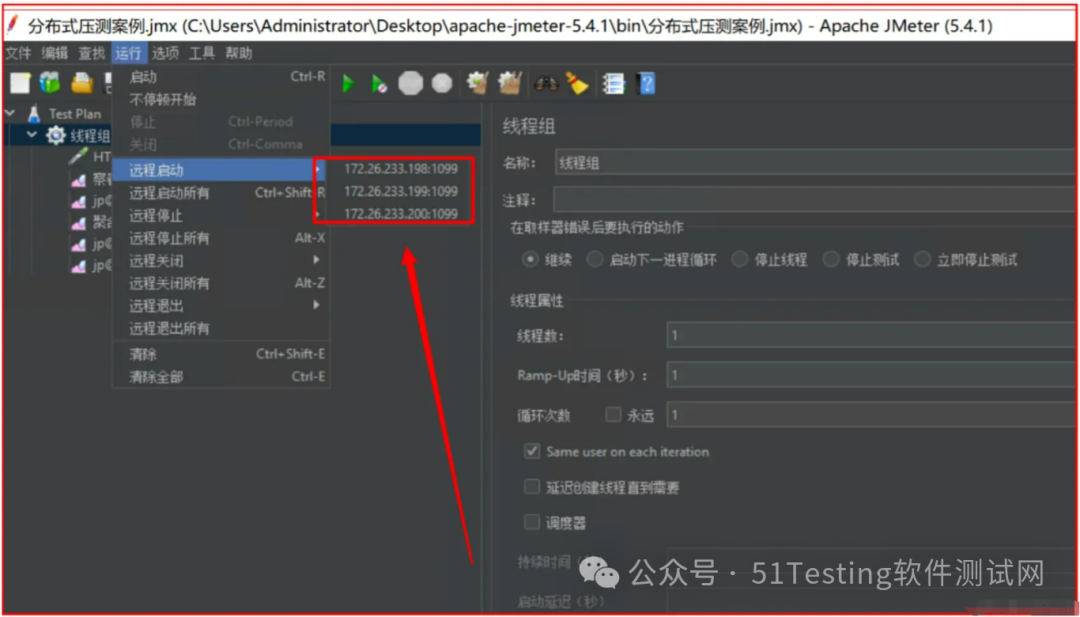
- (3)在JMeter Master机器安装目录bin下,找到jmeter.properties文件,修改远程主机选项,添加3个Salve服务器的地址。
(4)启动jmeter,如果是多网卡模式需要指定IP地址启动
讯享网
(5)验证分布式环境是否搭建成功:
感谢每一个认真阅读我文章的人,礼尚往来总是要有的,虽然不是什么很值钱的东西,如果你用得到的话可以直接拿走:
这些资料,对于【软件测试】的朋友来说应该是最全面最完整的备战仓库,这个仓库也陪伴上万个测试工程师们走过最艰难的路程,希望也能帮助到你!有需要的小伙伴可以点击下方小卡片领取
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/167106.html