
文本主要内容:
- 链表结构
- 单链表代码实现
- 单链表的效率分析
一、链表结构: (物理存储结构上不连续,逻辑上连续;大小不固定)
概念:
链式存储结构是基于指针实现的。我们把一个数据元素和一个指针称为结点。
数据域:存数数据元素信息的域。
指针域:存储直接后继位置的域。
链式存储结构是用指针把相互直接关联的结点(即直接前驱结点或直接后继结点)链接起来。链式存储结构的线性表称为链表。
链表类型:
根据链表的构造方式的不同可以分为:
- 单向链表
- 单向循环链表
- 双向循环链表
二、单链表:
概念:
链表的每个结点中只包含一个指针域,叫做单链表(即构成链表的每个结点只有一个指向直接后继结点的指针)
单链表中每个结点的结构:

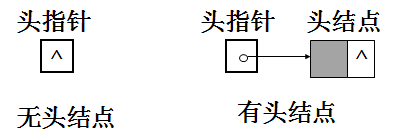
1、头指针和头结点:
单链表有带头结点结构和不带头结点结构两种。
“链表中第一个结点的存储位置叫做头指针”,如果链表有头结点,那么头指针就是指向头结点的指针。
头指针所指的不存放数据元素的第一个结点称作头结点(头结点指向首元结点)。头结点的数据域一般不放数据(当然有些情况下也可存放链表的长度、用做监视哨等)
存放第一个数据元素的结点称作第一个数据元素结点,或称首元结点。
如下图所示:

不带头结点的单链表如下:

带头结点的单链表如下图:

关于头指针和头结点的概念区分,可以参考如下博客:
http://blog.csdn.net/hitwhylz/article/details/
2、不带头结点的单链表的插入操作:

上图中,是不带头结点的单链表的插入操作。如果我们在非第一个结点前进行插入操作,只需要a(i-1)的指针域指向s,然后将s的指针域指向a(i)就行了;如果我们在第一个结点前进行插入操作,头指针head就要等于新插入结点s,这和在非第一个数据元素结点前插入结点时的情况不同。另外,还有一些不同情况需要考虑。
因此,算法对这两种情况就要分别设计实现方法。
3、带头结点的单链表的插入操作:(操作统一,推荐)

上图中,如果采用带头结点的单链表结构,算法实现时,p指向头结点,改变的是p指针的next指针的值(改变头结点的指针域),而头指针head的值不变。
因此,算法实现方法比较简单,其操作与对其它结点的操作统一。
问题1:头结点的好处:
头结点即在链表的首元结点之前附设的一个结点,该结点的数据域中不存储线性表的数据元素,其作用是为了对链表进行操作时,可以对空表、非空表的情况以及对首元结点进行统一处理,编程更方便。
问题2:如何表示空表:
如下图所示:
问题3:头结点的数据域内装的是什么?
头结点的数据域可以为空,也可存放线性表长度等附加信息,但此结点不能计入链表长度值。
三、单项链表的代码实现:
1、结点类:
单链表是由一个一个结点组成的,因此,要设计单链表类,必须先设计结点类。结点类的成员变量有两个:一个是数据元素,另一个是表示下一个结点的对象引用(即指针)。
步骤如下:
(1)头结点的构造(设置指针域即可)
(2)非头结点的构造
(3)获得当前结点的指针域
(4)获得当前结点数据域的值
(5)设置当前结点的指针域
(6)设置当前结点数据域的值
注:类似于get和set方法,成员变量是数据域和指针域。
代码实现:
(1)List.java:(链表本身也是线性表,只不过物理存储上不连续)
(2)Node.java:结点类
2、单链表类:
单链表类的成员变量至少要有两个:一个是头指针,另一个是单链表中的数据元素个数。但是,如果再增加一个表示单链表当前结点位置的成员变量,则有些成员函数的设计将更加方便。
代码实现:
(3)LinkList.java:单向链表类(核心代码)
3、测试类:(单链表的应用)
使用单链表建立一个线性表,依次输入十个0-99之间的随机数,删除第5个元素,打印输出该线性表。
(4)Test.java:
运行效果:

四、开发可用的链表:
对于链表实现,Node类是整个操作的关键,但是首先来研究一下之前程序的问题:Node是一个单独的类,那么这样的类是可以被用户直接使用的,但是这个类由用户直接去使用,没有任何的意义,即:Node这个类有用,但是不能让用户去用,只能让LinkList类去调用,内部类Node中完成。
于是,我们需要把Node类定义为内部类,并且在Node类中去完成addNode和delNote等操作。使用内部类的最大好处是可以和外部类进行私有操作的互相访问。

注:内部类访问的特点是:内部类可以直接访问外部类的成员,包括私有;外部类要访问内部类的成员,必须先创建对象。
1、增加数据:
- public Boolean add(数据 对象)
代码实现:
(1)LinkList.java:(核心代码)
代码解释:
14行:如果我们第一次调用add方法,那根结点肯定是空的,此时add的是根节点。
当继续调用add方法时,此时是往根节点后面添加数据,需要用到递归(42行),这个递归需要在内部类中去完成。递归这段代码需要去反复理解。
(2)LinkListDemo.java:
运行效果:
2、增加多个数据:
- public boolean addAll(数据 对象 [] )
上面的操作是每次增加了一个对象,那么如果现在要求增加多个对象呢,例如:增加对象数组。可以采用循环数组的方式,每次都调用add()方法。
在上面的(1)LinkList.java中加入如下代码:
3、统计数据个数:
- public int size()
在一个链表之中,会保存多个数据(每一个数据都被封装为Node类对象),那么要想取得这些保存元素的个数,可以增加一个size()方法完成。
具体做法如下:
在上面的(1)LinkList.java中增加一个统计的属性count:
当用户每一次调用add()方法增加新数据的时候应该做出统计:(下方第18行代码)
而size()方法就是简单的将count这个变量的内容返回:
4、判断是否是空链表:
- public boolean isEmpty()
所谓的空链表指的是链表之中不保存任何的数据,实际上这个null可以通过两种方式判断:一种判断链表的根节点是否为null,另外一个是判断保存元素的个数是否为0。
在LinkList.java中添加如下代码:
5、查找数据是否存在:
- public boolean contains(数据 对象)
现在如果要想查询某个数据是否存在,那么基本的操作原理:逐个盘查,盘查的具体实现还是应该交给Node类去处理,但是在盘查之前必须有一个前提:有数据存在。
在LinkList.java中添加查询的操作:
紧接着,在Node类之中,完成具体的查询,查询的流程:
判断当前节点的内容是否满足于查询内容,如果满足返回true;
如果当前节点的内容不满足,则向后继续查,如果已经没有后续节点了,则返回false。
代码实现:
6、删除数据:
- public boolean remove(数据 对象)
在LinkList.java中加入如下代码:
注意第2代码中,我们是假设删除的这个String字符串是唯一的,不然就没法删除了。
删除时,我们需要从根节点开始判断,如果根节点是需要删除的节点,那就直接删除,此时下一个节点变成了根节点。
然后,在Node类中做节点的删除:
7、输出所有节点:
在LinkList.java中加入如下代码:
然后,在Node类中做节点的输出:
8、取出全部数据:
- public 数据 [] toArray()
对于链表的这种数据结构,最为关键的是两个操作:删除、取得全部数据。
在LinkList类之中需要定义一个操作数组的脚标:
在LinkList类中定义返回数组,必须以属性的形式出现,只有这样,Node类才可以访问这个数组并进行操作:
在LinkList类之中增加toArray()的方法:
修改Node类的操作,增加toArrayNode()方法:
不过,按照以上的方式进行开发,每一次调用toArray()方法,都要重复的进行数据的遍历,如果在数据没有修改的情况下,这种做法是一种非常差的做法,最好的做法是增加一个修改标记,如果发现数据增加了或删除的话,表示要重新遍历数据。
然后,我们修改LinkList类中的toArray()方法:(其他代码保持不变)
9、根据索引位置取得数据:
- public 数据 get(int index)
在一个链表之中会有多个节点保存数据,现在要求可以取得指定节点位置上的数据。但是在进行这一操作的过程之中,有一个小问题:如果要取得数据的索引超过了数据的保存个数,那么是无法取得的。
在LinkList类之中,增加一个get()方法:
在Node类之中配置getNode()方法:
10、清空链表:
- public void clear()
所有的链表被root拽着,这个时候如果root为null,那么后面的数据都会断开,就表示都成了垃圾:
总结:
上面的10条方法中,LinkList的完整代码如下:
四、单链表的效率分析:
在单链表的任何位置上插入数据元素的概率相等时,在单链表中插入一个数据元素时比较数据元素的平均次数为:

删除单链表的一个数据元素时比较数据元素的平均次数为:

因此,单链表插入和删除操作的时间复杂度均为O(n)。另外,单链表读取数据元素操作的时间复杂度也为O(n)。
2、顺序表和单链表的比较:
顺序表:
优点:主要优点是支持随机读取,以及内存空间利用效率高;
缺点:主要缺点是需要预先给出数组的最大数据元素个数,而这通常很难准确作到。当实际的数据元素个数超过了预先给出的个数,会发生异常。另外,顺序表插入和删除操作时需要移动较多的数据元素。
单链表:
优点:主要优点是不需要预先给出数据元素的最大个数。另外,单链表插入和删除操作时不需要移动数据元素;
缺点:主要缺点是每个结点中要有一个指针,因此单链表的空间利用率略低于顺序表的。另外,单链表不支持随机读取,单链表取数据元素操作的时间复杂度为O(n);而顺序表支持随机读取,顺序表取数据元素操作的时间复杂度为O(1)。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/162589.html