
SAS函数是一个子程序,对自变量返回一个结果值。
SAS函数的基本形式:
y=函数名(X1,X2,…),其中X1,X2…为参数值
易混淆的概念
字符—character:一个一个地字符,如’a’,‘a’‘b’(‘ab’);
注:字符常数是与引号括起来的,字符变量的名称是没有引号的,即 字符常数不能作为字符变量的名称;SAS中比较引号括起来的字符时是区分大小写的,如‘ABC’与‘abc’是不同的。十进制的字符常数可以表示为‘543’x,x紧跟在引号后面。
字符串—string:一个或多个字符组成的串,如’a’,‘ab’;
词—word:由分隔符(delimeter)隔开的字符串,如’I love programming’‘I@love@programming’;
数值函数
mod(x,y):返回x除以y的余数;
int(x):返回x的整数部分;
ceil(x):返回≥x的最小整数;
floor(x):返回≤x的最大整数;
round(x,舍入值):根据舍入值对x进行舍入,即将x舍入到最接近能被舍入值整除的数值;
abs(x):返回x的绝对值;
log(x):返回x的自然对数值;
sqrt(x):返回x的平方根;
exp(x):返回x的指数值;
data a; num1=round(8.6,0.1); num2=round(8.6,1); num3=round(8.6,2); a=mod(10,3); b=int(8.6); c=ceil(8.6); d=floor(8.6); e=abs(-8.6); f=sqrt(4); g=log(4); h=exp(4); run; proc print; run; 讯享网
运行结果:
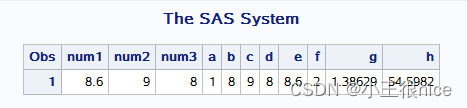
讯享网
日期时间函数
date()、today():返回当天的日期;
year()、month()、day()和qtr():分别提取一个日期中的年、月、日、季度;
mdy(month,day,year):将月、日、年组合成完整日期;
intck(‘’custom-inteval‘’,start-date,end-date):返回在一个给定的时间跨度内发生的时间间隔的数量,可以用来计算天day、周week、月month、年year、季度qtr等;
yrdif(开始日期,结束日期,“计算依据”):当计算依据为actual时,计算两个日期之间以年为单位的差值;当计算依据为age时,计算两个日期之间的年龄差值;
datdif(开始日期,结束日期,“计算依据”):当计算依据为actual时,计算两个日期之间以天为单位的差值;
讯享网data datetime; format td date yymmdd10.; da=date(); td=today(); year=year(td); month=month(td); day=day(td); q=qtr(td); date=mdy(8,02,2018); yd=yrdif(date,td,'actul'); age=yrdif(date,td,'age'); dd=datdif(date,td,'actul'); days=intck('day',date,td); run;
运行结果:

字符型相关函数
字母大小写转换
upcase(‘’):转换为大写;
lowcase(‘’):转换为小写;
propcase(‘argument’<,‘delimiters’>):各单词首字母大写,其余小写,默认的分隔符delimiters是空白,正斜杠,连字符、开括号、句号和制表符;
data change_case; a=upcase('abc'); b=lowcase('Abc'); c=propcase('ab cD'); run; 
空格处理
trim(‘’):移除尾部空格;
trimn(‘’):移除字符串的尾部空格;
left(‘’):移除首部空格;
strip(‘’):移除首尾空格;
compress(‘’):移除所有空格(或指定字符)
compress(source<,character><,modifier(s)>)
compbl(‘’):将多个连续空格,压缩为1个;
讯享网data space; a=trim(' abcd '); b=left(' abcd '); c=strip('abcd '); d=compress(' abcd mn'); e=compbl(' abcd mn'); run;
运行结果:
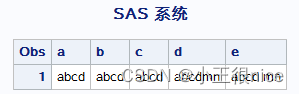
去除变量的字符
compress(变量<,要去除的字符><,修饰符>)
修饰符常用:
| 修饰符 | 含义 |
|---|---|
| a | 去除掉变量中的所有字母 |
| d | 去除掉变量中的所有数字 |
| s | 去除掉变量中的所有空格 |
| i | 忽略大小写 |
| k | 保留“要去除的字符”,去除掉其它字符 |
data compress; /*移除所有空格或特殊字符*/ input p& $ 1-20; q1=compress(p); q2=compress(p,'(-)'); q3=compress(p,'(-)','d'); q4=compress(p,,'d'); q5=compress(p,'(-)','s'); q6=compress(p,'(-)','k'); datalines; (123)456-7890 (123)456-78 90 ; run; proc print; run; 结果如下:
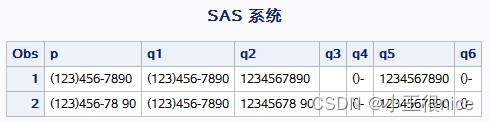
长度
length(变量):返回变量值长度,尾部空格不计数,空字符串与连续空格视为1个字符串;
lengthn(变量):返回变量长度,尾部空格不计数,空字符串与连续空格视为0个字符串;
lengthc(变量):返回变量值长度,对首尾空格及连续空格计数,空字符串记为1个字符;
讯享网data length; a=''; /*没有空格*/ b=' '; /*有一个空格*/ c=' '; /*有三个空格*/ d=' ABC DEF '; /*首尾及中间各有一个空格*/ e=' ABC DEF'; /*首部及中间各有一个空格*/ /* 返回变量值长度,尾部空格不计数,空字符串与连续空格视为1个字符串*/ length_a=length(a); length_b=length(b); length_c=length(c); length_d=length(d); length_e=length(e); run; proc print; run;
结果如下:

data lengthn; set length(keep=a b c d e); /* 返回变量值长度,尾部空格不计数,空字符串与连续空格视为0*/ lengthn_a=lengthn(a); lengthn_b=lengthn(b); lengthn_c=lengthn(c); lengthn_d=lengthn(d); lengthn_e=lengthn(e); run; proc print; run; 结果如下:

讯享网data lengthc; set length(keep=a b c d e); /* 返回变量值长度,对首尾空格及连续空格计数,空字符串为1*/ lengthc_a=lengthc(a); lengthc_b=lengthc(b); lengthc_c=lengthc(c); lengthc_d=lengthc(d); lengthc_e=lengthc(e); run; proc print; run;
结果如下:

字符串连接
||:连字符;
cat(x,y):直接连接;
catt(x,y):去尾部空格再连接;
cats(x,y):去首尾空格再连接;
catx(‘’,x,y):去首尾空格,用分隔符连接;
data link; x=' 性别 '; y=' 女 '; a=x||y; /*连字符,直接连接*/ b=cat(x,y); /*直接连接*/ c=catt(x,y); /*去尾部空格,再连接*/ d=cats(x,y); /*去首尾空格,再连接*/ e=catx(':',x,y); /*去首尾空格,用分隔符连接*/ run; 结果如下:
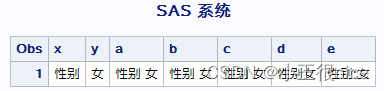
截取
substr(变量,起始位置<,提取长度>):提取字符串;如果字符串是汉字,用ksubstr()来提取;
substrn(变量,起始位置<,提取长度>):提取字符串;允许长度为0或超出;
scan(string,n<,delimiters>):返回第n个word,分隔符delimiters若没有指定,默认的有blank . < ( + | & ! $ * ) ; ^ - / , %;

讯享网data substr_scan; a1=substr('ABCDEF',3); b1=substrn('ABCDEF',3,2); a2=substr('ABCDEF',5,3); b2=substrn('ABCDEF',5,3); a3=scan('AB CDEF',1); b3=scan('AB@CDEF',-1,'@'); id='D12'; city='一线城市'; c=substr(id,2,1); c1=substr(id,2); d=substr(city,3,2); d1=substr(city,2); e=ksubstr(city,3,2); e1=ksubstr(city,2); run; proc print; run;
运行结果:

查看Log会发现a2报错了,因为截取的长度超出了字符串的实际长度,所以在使用时应当留心或者采用substrn()函数来截取,错误提提示:

查找
index(‘x’,‘y’):在x中查找字符串y,返回第一次出现的位置,找不到返回0,如果字符串是汉字使用kindex()函数查找字符串;
indexw(‘x’,‘y’):在x中查找word y,返回第一次出现的位置,找不到返回0;
indexc(‘x’,‘y’):在x中查找字符y,返回第一次出现的位置,找不到返回0;
/*查找函数 index kindex indexw indexc*/ data index; a1=index('abcd cd', 'cd'); b1=index('abcd cd', 'dc'); a2=indexw('abcd cd', 'cd'); b2=indexw('abcd cd', 'dc'); a3=indexc('abcd cd', 'cd'); b3=indexc('abcd cd', 'dc'); /*将'dc'拆分为两个字符,哪个字符先出现,就返回哪个字符的位置*/ run; proc print; run; 运行结果:
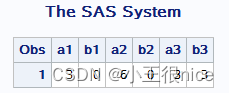
讯享网data index1; /*注意空格,定义长度后,变量不满的部分会用空格填充*/ length a b $14; /*$14. 同样*/ a='ABC.DEF (X=Y)'; b='X=Y'; q=index(a,b); w=index(a,trim(b)); put q= w=; run; proc print; run;
运行结果
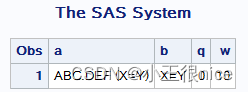
data kindex; text1='汉字汉字汉字'; a=kindex(text1,'字汉'); a1=index(text1,'字汉'); text2='汉字'; b=kindex(text1,text2); b1=index(text1,text2); run; proc print; run; 运行结果
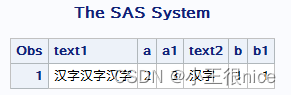
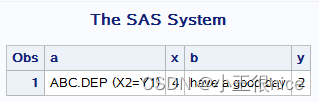
讯享网data indexc; a='ABC.DEP (X2=Y1)'; x=indexc(a, '0123', ';()=.'); put x; b='have a good day'; y=indexc(b, 'pleasant', 'very'); put y; run; proc print; run;
运行结果:
替换
translate(字符串,替换后的字符,需要替换的字符):替换字符函数;
tranwrd(字符串,需要替换的字符串,替换后的字符串):替换字符串函数,子字符串中含有尾部空格时,要用trim()删除,替换后的字符串长度为0时,替换为1个空格,替换后的字符串为多个空格时,替换为相应数目的空格;
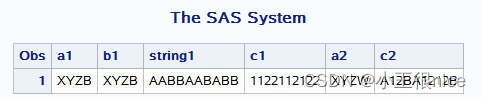
/*替换函数 translate tranwrd*/ data translate; a1=translate('XYZW','A''B','V''W'); b1=translate('XYZW','AB','VW'); string1='AABBAABABB'; c1=translate(string1,'12','AB'); a2=tranwrd('XYZW','VW','AB'); string1='AABBAABABB'; c2=tranwrd(string1,'AB','12'); run; proc print; run; 运行结果
变量类型转换
input(source,informat)函数:把字符串转换为数值函数或其他类型的字符型函数;
put(source,format)函数:把数值型转换为字符型函数或其他类型的字符型函数
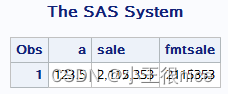
讯享网data input; /*将字符型转换成数值型*/ a=input('123.5',best.); input sale $9.; fmtsale=input(sale, comma9.); datalines; 2,115,353 ; run; proc print; run;
运行结果
proc format; value $ sex 'F'='Female' 'M'='Male'; run; data put; /*将数值型转换成字符型*/ format b $sex.; a=put(123,8.2); b=put('F',$sex.); numdate=; chardate=put(numdate, z6.); sasdate=input(chardate, mmddyy6.); run; proc print; run; 运行结果

与缺失值相关的函数
n(变量1,变量2,…):返回非缺失值的个数(针对数值型变量或常量),即统计数值型变量非空个数;(多个变量时,不是同时满足缺失,而是一个记一个数,下同)
nmiss:返回缺失值的个数(针对数值型变量或常量,将字符型变量的所有值都当作缺失值);
cmiss:返回缺失值的个数(数值型、字符型均可);
not missing:如果是缺失的,则返回0;反之,则返回1;
missing:如果是缺失的,则返回1;反之,则返回0;
call missing:对参数进行操作,置空;
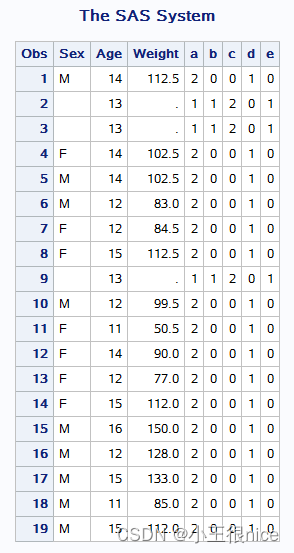
讯享网/*缺失值函数 n,nmiss,cmiss,not missing,missing,call missing/ data class; set sashelp.class; if age=13 then call missing(weight,sex); a=n(age,weight); b=nmiss(age,weight); c=cmiss(sex,weight); d=not missing(sex); e=missing(sex); drop name height; run; proc print; run;
运行结果:
条件判断函数
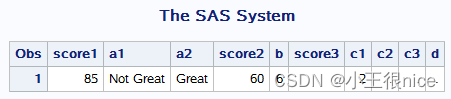
/条件判断函数 ifc ifn*/ data if; score1=85; a1=ifc(score1>95,"Great","Not Great"); a2=ifc(score1>60,"Great","Not Great"); score2=60; b=ifn(score2>90,5,6); score3=.; c1=ifn(score3<90,2,3); c2=ifn(score3=.,.,ifn(score3<90,2,3)); if score3=. then c3=.; else if score3<90 then c3=2; else c3=3; if not missing(score3) then d=ifn(score3<90,2,3); run; proc print; run; 运行结果
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/14404.html