
一.引言
保序回归又称为单调回归,算法中 Isotonic 意为等渗,其来源于希腊词根, 'iso' 意为相等、'tonos' 意为扩展,表达其在常规线性回归的基础上做了拓展即增加了保序的限制。本文将基于 Spark Isotonic Regression 的原理和实践进行简单的理论分析和代码实战。
二.Isotonic Regression 理论
1.函数形式
保序回归属于回归算法家族,形式上与常规回归类似,给定一组观测值 y1、y2、... 和原始值 x1、x2、...,找到一个映射函数 f(x) 使得下述损失函数达到最小:
其中要求保序:

这里映射函数 f(x) 就是我们最终生成的回归函数。
2.PAV 算法简介

Spark.Mlib 通过 Pool Adjacent Violators Algorithm PAV 算法去近似实现保序回归。首先有一个前提条件,即像其他线性模型一样假定回归模型中方差是相同的。假定每个 yi 满足正态分布:
且满足:
为了满足单调性约束,我们需要将违反单调性约束的点与其相邻的点构成一个单调序列。在序列范围内保证其满足同一分布,即如果存在乱序情况:
则令当前的 x 序列同属于新的分布:
此时 f(x) 给定 x[i] 和 x[i+1] 都会返回 (y[i] + yi+1) / 2 作为预测,即 u = (y[i] + y[i+1]) / 2。继续向 x[i+2] 点前进,如果 y[i] + y[i+1]) / 2 > y[i+2] ,则代表当前序列依然存在乱序情况,此时吸纳 y[i+2] 生成新的分布:
如果往复循环吸纳序列,如果 y[i] + y[i+1]) / 2 < y[i+2] ,则此时 x[i]、x[i+1] 同属一个分布, x[i+2] 构造自己的 μ = y[i+2] 的分布,并重复上述序列扩展过程,直到所有 x 的分布 y 满足单调性。简单来说就是将不满足单调性的点与周围点绑定为一个整体合并为一个分布,此时对应区间预测值也会成为一条直线。这里我们都是假定了权重 w 相同且都为1的情况,如果权重不同,则分布均值的构造过程将会变成加权平均而不是直接平均。
Tips:
在回归任务中我们的 f(x) 给定同一个 x 返回的是同一个 y,而原始数据中可能存在同一个 x 不同 y 的情况,针对这样的 x 我们首先需要将所有 x 的 y 值拿到,然后去 mean(y) 作为 x 的预测值进入下面的步骤。这里取平均也很好理解,因为我们采用均方差的损失函数,给定 y1、y2、...、yn,取 mean(y) 时损失函数最小。
3.算法图例
下图展示了 PAV 算法的序列构成与吸纳成同分布的方法。
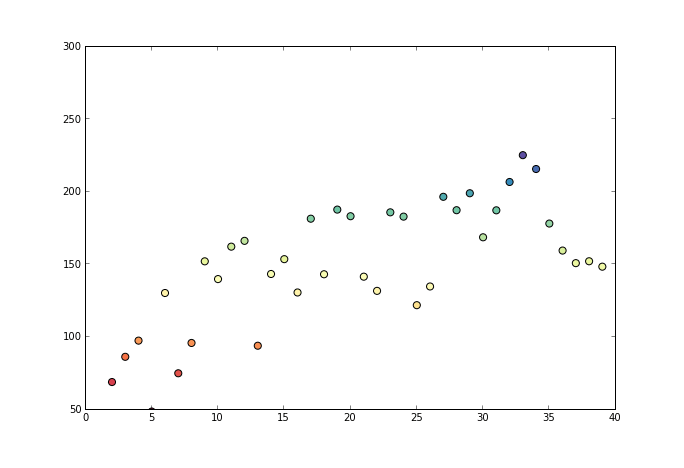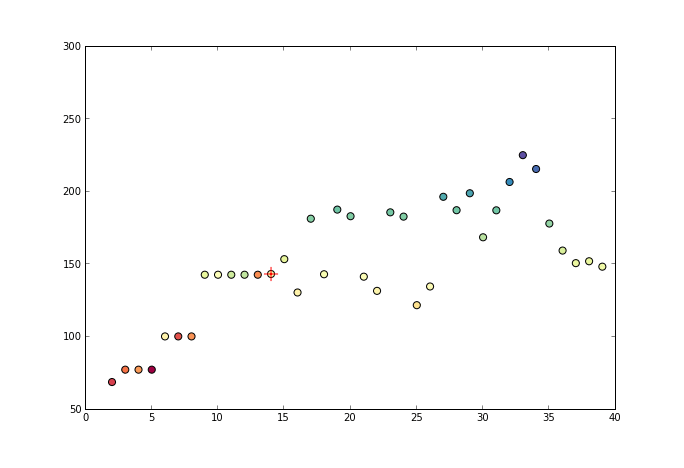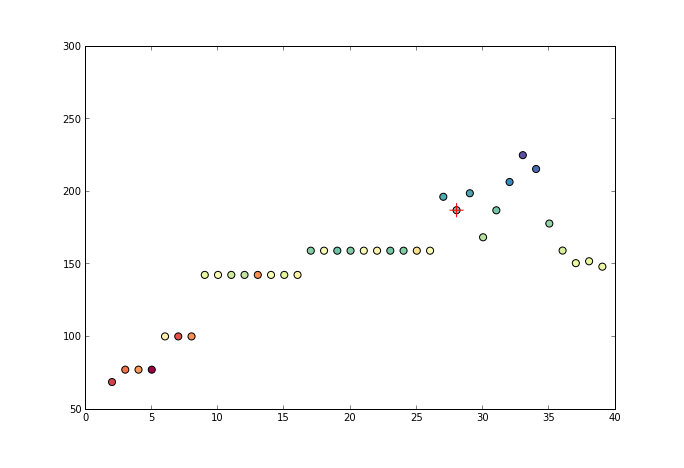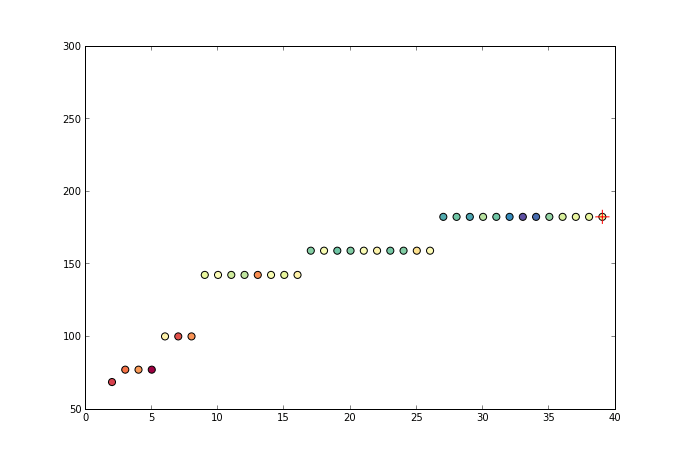
通过回归损失函数与单调性要求,获得的 f(x) 最终为分段函数形式。

三.Isotonic Regression 实战
1.模拟乱序数据
此处我们模拟 y = 10 * x 的回归问题,并在随机范围内生成乱序数据。

// 构造乱序数据 val dataBuffer = new ArrayBuffer[(Double, Double)]() val random = new Random() (0 to 10000).foreach(num => { val x = random.nextDouble() val y = if (random.nextDouble() < 0.1) { x * 10 - random.nextDouble() * 2 } else { x * 10 } dataBuffer.append((y, x)) }) // 划分训练、预测集 val splits = sc.parallelize(dataBuffer).map(data => { (data._1, data._2, 1.0) }).randomSplit(Array(0.6, 0.4)) val training = splits(0) val test = splits(1)讯享网
2.模型训练
划分训练集预测集并训练,setIsotonic 为 True 即要求模型保序。
讯享网 // 划分训练、预测集 val splits = sc.parallelize(dataBuffer).map(data => { (data._1, data._2, 1.0) }).randomSplit(Array(0.6, 0.4)) val training = splits(0) val test = splits(1) // 模型训练 val model = new IsotonicRegression().setIsotonic(true).run(training)
3.模型评估
使用原始 label 与预测值计算 MSE。
// 预测值与真实值 val predictionAndLabel = test.map { point => val predictedLabel = model.predict(point._2) (predictedLabel, point._1) } // 计算 MSE val meanSquaredError = predictionAndLabel.map { case (p, l) => math.pow((p - l), 2) }.mean() println(s"Mean Squared Error = $meanSquaredError")4.模型保存与加载
通过 .save 方法保存模型,并通过 .load 方法加载模型。
讯享网// Save and load model model.save(sc, "target/tmp/myIsotonicRegressionModel") val sameModel = IsotonicRegressionModel.load(sc, "target/tmp/myIsotonicRegressionModel")
Tips: 完整代码
val conf = (new SparkConf).setAppName("IsotonicLR").setMaster("local[*]") val spark = SparkSession .builder .config(conf) .getOrCreate() val sc = spark.sparkContext // 构造乱序数据 val dataBuffer = new ArrayBuffer[(Double, Double)]() val random = new Random() (0 to 10000).foreach(num => { val x = random.nextDouble() val y = if (random.nextDouble() < 0.1) { x * 10 - random.nextDouble() * 2 } else { x * 10 } dataBuffer.append((y, x)) }) // 划分训练、预测集 val splits = sc.parallelize(dataBuffer).map(data => { (data._1, data._2, 1.0) }).randomSplit(Array(0.6, 0.4)) val training = splits(0) val test = splits(1) // 模型训练 val model = new IsotonicRegression().setIsotonic(true).run(training) // 预测值与真实值 val predictionAndLabel = test.map { point => val predictedLabel = model.predict(point._2) (predictedLabel, point._1) } // 计算 MSE val meanSquaredError = predictionAndLabel.map { case (p, l) => math.pow((p - l), 2) }.mean() println(s"Mean Squared Error = $meanSquaredError")四.Isotonic Regression 应用
1.自定义加载模型
实际场景下,Spark 训练得到的 Isotonic Regression 模型加载需要传入 SC 即 SparkContext:

但如果我们是在 Flink 环境下使用,就不太好初始化 SparkContext 了,这里我们主要到 sc 主要负责读取源数据,而保序回归的源数据其实很简单,两个 Array[Double] 一个为 Boundaries 边界一个是 Predictions 预测 以及标识 isotonic 的 Boolean,所以我们可以通过 Redis 保存这两个数组,在自己的任务中直接 new IsotonicRegressionModel 即可:
讯享网val selfModel = new IsotonicRegressionModel(boundaries, predictions, isotonic)
这样的好处是避免了 sc 的限制,且改模型支持序列化,所以广播也没有问题。
2.自定义代码测试
val boundaries = model.boundaries val predictions = model.predictions println(boundaries.mkString(",")) println(predictions.mkString(",")) val isotonic = true val selfModel = new IsotonicRegressionModel(boundaries, predictions, isotonic) val predictionAndLabelSelf = test.map { point => val predictedLabel = selfModel.predict(point._2) (predictedLabel, point._1) } // Calculate mean squared error between predicted and real labels. val meanSquaredErrorSelf = predictionAndLabelSelf.map { case (p, l) => math.pow((p - l), 2) }.mean() println(s"Mean Squared Error Self = $meanSquaredError")这里使用刚才训练模型的 Boundaries 和 Predictions 直接构造保序回归模型,计算得到的预测结果和 MES 与 load 得到的模型是相同的。这里实战的话把数组存在 Redis 等存储介质即可。
3.自定义模型预测
下面是官方 predict 的源码,思路也很清晰,首先使用二分法判断当前测试数据即 x 是否在 boundaries 中,随后根据数据分四种情况计算:
- 小于所有边界:取 Predictions.head
- 大于所有边界: 取 Predictions.last
- 找不到索引: 执行 linearInterpolation 线性插值
- 找到索引: 直接去 Predictions[Index]

有兴趣的同学可以把源码 copy 下来自己调用看看~
五.总结
保序回归经典的应用案例就是药物使用量试验上,假设药物用量与病人反应成正单调,但如过按照药物反应排序时药物用量乱序则不好评估用药量。在这种情况下,使用保序回归,即不改变 X 的排列顺序,又求的 Y 的平均值状况。例如模型预测后用药量在 20-30 时预测值相同,则我们从经济以及病人抗药性等因素的考虑,可以认为 20 的量是理想的。
除此之外,保序回归也可以应用于点击率预估的矫正,因为我们的先验认知是模型的预测分和其对应的真实点击率应该成正比,基于这个先验认知我们也可以通过保序回归矫正 CTR。
参考:
Spark Isotonic regression DOCS
Predicting Good Probabilities With Supervised Learning
Isotonic Regression Research And Process
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/13549.html