
分享41个Python爬虫源代码总有一个是你想要的
下载链接:https://pan.baidu.com/s/1nDDv5DrYPylFFF-hke2kFg?pwd=8888
提取码:8888
项目名称
Amazon商品引流的 python 爬虫
CSDN博客阅读量提升脚本,基于python刷阅读量,简单可用
feapder是一款上手简单,功能强大的Python爬虫框架
html+ python +django +爬虫 +pyecharts 实时疫情动态
python scrapy 企业级分布式爬虫开发架构模板
Python 图片爬虫
import os import shutil def void_folder(path): # 访问path路径下的文件或文件夹 lst = os.listdir(path) # 打印每一层的文件或文件夹 for name in lst: # 拼接名称,得到绝对路径,判断该文件是否符合是文件夹 real_path = os.path.join(path, name) # 如果是文件夹,则打空格表示,并且递归访问下一层 if os.path.isdir(real_path): # print(name) files = os.listdir(real_path) if len(files) == 0: print("void_folder():"+name) shutil.rmtree(real_path) endindex = len(real_path) - len(name) real_path = real_path[0:endindex] void_folder(real_path) else: void_folder(real_path) # 如果不是文件夹,直接打印,不再递归访问下一层 else: #print(name) pass def void_file(dirPath): dirs = os.listdir(dirPath) # 查找该层文件夹下所有的文件及文件夹,返回列表 for file in dirs: file_full_name = dirPath + '/' + file file_ext = os.path.splitext(file_full_name)[-1] if file_ext is None or file_ext=="": continue讯享网
python 爬取各大技术博客网站
python 编写的DHT Crawler 网络爬虫,抓取磁力链接
python-爬虫-web-数据分析
python多线程爬虫爬取电影天堂资源
python模拟登陆一些大型网站,还有一些简单的爬虫
Python爬虫Flask网站免费ShadowSocks账号ssr订阅json 订阅
Python爬虫和Flask实现小说网站
Python爬虫实现百度图片自动下载
Python爬虫框架,内置微博、自如、豆瓣图书、拉勾网、拼多多等爬虫
Python爬虫爬取 Instagram 博主照片视频
Python爬虫爬取github项目里的评论
python爬虫爬取全国高校新闻
python爬虫爬取博客园文章
Python爬虫进阶 JS 解密逆向实战
Python爬虫集合,内含各大网站爬虫,应有尽有
Python爬虫,京东自动登录,在线抢购商品
python爬虫,网易云音乐歌曲爬取,B站视频爬取,知乎问答爬取,壁纸爬取,xvideos视频爬取,有声书爬取,微博爬虫,安居客信息爬取+数据可视化,哔哩哔哩视频封面提取器,ip代理池封装,知乎百万级用户爬虫+数据分析,github用户爬虫
Python网络爬虫与推荐算法的新闻推荐平台
Python脚本。模拟登录知乎, 爬虫,操作excel,微信公众号,远程开机
一个简单的python爬虫,原生python+BeautifulSoup
使用beautifulsoup4爬取新浪新闻首页新闻列表。成功获取新闻标题、时间、来源、详情、评论数、编辑信息,使用pandas整理数据,并保存到数据库
使用python+Scrapy框架去抓取新闻网站
使用Python编写的某dn博客爬虫
利用Python实现基于Requests框架和多线程技术的Tumblr博客空间图片及视频下载

利用python爬取新闻网站的热点新闻
利用python爬虫从日本雅虎网站获取新闻,对新闻文本做相似度计算,训练新闻分类模型
基于python实现将某dn的博客文章爬取并转换为hexo下的markdown博客格式
基于python的1024爬虫,可爬下1024的文章和图片放到当前目录上
基于Scrapy框架的Python新闻爬虫,能够爬取网易,搜狐,凤凰和澎湃网站上的新闻,将标题,内容,评论,时间等内容
新浪微博爬虫,用python爬取新浪微博数据
新闻网络爬虫
汤不热 python 多线程爬虫
简单易用的Python爬虫框架
观察者新闻网爬虫(新闻爬虫),基于python+Flask+Echarts
非常有趣的python爬虫例子,对新手比较友好,主要爬取淘宝、天猫、微信、微信读书、豆瓣、等网站

Python网络爬虫与推荐算法的新闻推荐平台
介绍
网络爬虫:通过Python实现新浪新闻的爬取,可爬取新闻页面上的标题、文本、图片、视频链接(保留排版) 推荐算法:权重衰减+标签推荐+区域推荐+热点推荐
- 权重衰减进行用户兴趣标签权重的衰减,避免内容推荐的过度重复
- 标签推荐进行用户标签与新闻标签的匹配,按照匹配比例进行新闻的推荐
- 区域推荐进行IP区域确定,匹配区域性文章进行推荐
- 热点推荐进行新闻热点的计算的依据是新闻阅读量、新闻评论量、新闻发布时间
涉及框架:Django、jieba、selenium、BeautifulSoup、vue.js
示意图
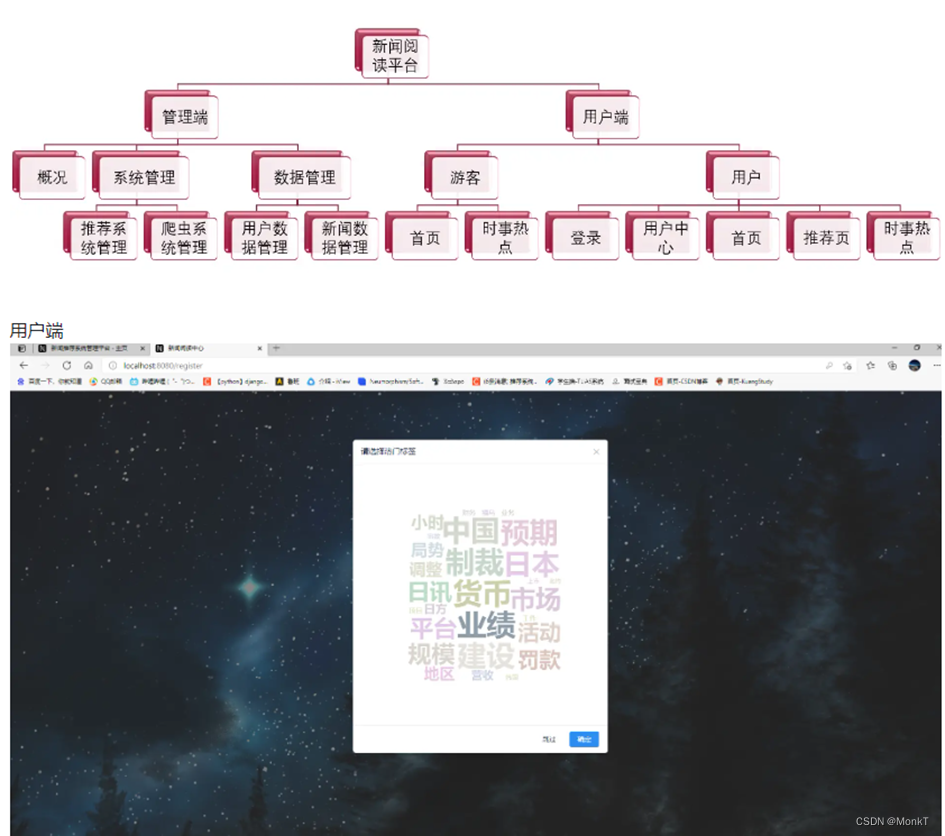

学习知识费力气,
收集整理更不易。
知识付费甚欢喜,
为咱码农谋福利。.
感谢您的支持
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/128075.html