
一、RGA关系感知全局注意力模型概述
RGA关系感知全局注意力是中国科学技术大学和微软亚洲研究院在2020年CVPR提出的一篇基于全局注意力的行人重识别文章。行人重识别(re-ID)的目的就是在一个或者多个摄像机拍摄的不同场合下去匹配特定的人。通常给定输入图像,我们使用卷积神经网络来获取特征向量。再识别是通过匹配图像特征向量来找到具有相同身份的图像(基于特征距离)。对于CNN,注意力通常是局部卷积学习到的,而局部卷积会忽略全局信息和隐藏信息的关系。文章提出有效的关系感知全局注意力(RGA)模块使CNN能够充分利用全局的相关性来推断注意力。通过全局考虑特征之间的相互关系来确定注意力,对于每一个特征节点,通过堆叠关于该节点的成对关系和特征本身,提出了一种紧凑的表示。将RGA模块应用于空间和通道维度并且进行组合可以得到更好的效果。
二、RGA整体网络架构—如何利用网络进行预测
行人重识别(re-ID)系统通常的做法就是通过主干特征提取网络(文章中采用了ResNet50)输入图像的特征向量表示,然后基于距离来进行图像匹配找到具有相同身份的图像。而本文的关系感知全局注意力模型是将特有的RGA模块应用于ResNet50主干网络,然后得到图像的特征向量表示。具体做法,就是在ResNet50的每一个残差块即res_layer1,res_layer2,res_layer3,res_layer4之后添加RGA模块,RGA模块包含了基于空间RGA-S和通道维度RGA-C的注意力机制。RGA网络的具体实现如下图所示:

讯享网
需要注意的是,ResNet50的res4_layer中的最后一个空间下采用操作被删除,我们将其步长stride设置为1。
1、主干特征提取网络—ResNet50
ResNet残差网络有两个最主要的基本块,我们称之为Conv Block和Identity Block。Conv Block和Identity Block的结构如下:
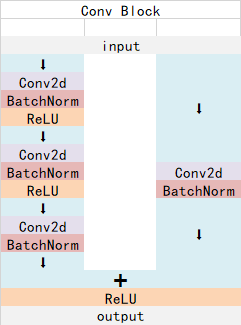

图片转自https://blog.csdn.net/weixin_/article/details/。
可以看到在Conv Block中,输入input在左右两边进行的操作的是不一样的,左边先进行了两次卷积块,一次卷积块即Conv+BN+Relu,然后又进行了Conv+BN的操作;而右边只进行了一次的Conv+BN;最后是将两边的输出进行相加Add和Relu激活函数操作;在Conv Block中输入和输出的shape可以是不一样的,因此Conv Block是不可以连续的串联,它是用来改变网络的维度;而Identity Block中的左边的操作和Conv Block是一样的,而右边输入input不进行任何的操作,因此在Identity Block中输入和输出的shape是一样的,可以进行连续多次的串联,用于加深网络的深度。ResNet网络就是由Conv Block和Identity Block不断重复,ResNet网络不仅能达到很深,而且每次Block提取到的特征总是不比原来差!!!
具体ResNet50特征提取代码如下:
# Networks self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3, bias=False) self.bn1 = nn.BatchNorm2d(64) self.relu = nn.ReLU(inplace=True) self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1) self.layer1 = self._make_layer(block, 64, layers[0]) self.layer2 = self._make_layer(block, 128, layers[1], stride=2) self.layer3 = self._make_layer(block, 256, layers[2], stride=2) self.layer4 = self._make_layer(block, 512, layers[3], stride=last_stride) # 残差卷积块的具体实现 def _make_layer(self, block, channels, blocks, stride=1): downsample = None if stride != 1 or self.in_channels != channels * block.expansion: downsample = nn.Sequential( nn.Conv2d(self.in_channels, channels * block.expansion, kernel_size=1, stride=stride, bias=False), nn.BatchNorm2d(channels * block.expansion), ) layers = [] layers.append(block(self.in_channels, channels, stride, downsample)) self.in_channels = channels * block.expansion for i in range(1, blocks): layers.append(block(self.in_channels, channels)) return nn.Sequential(*layers) 讯享网
2、RGA Module 关系感知全局注意力模块
为实现注意力,就要对特征的重要性有很好的认识,要对其进行客观评估。因此,全局信息至关重要,提出的关系感知全局注意力模块,能够充分利用结构的相关信息。
通常对于具有d维的N个相关特征的特征集
v={xi ∈ \in ∈Rd,i=1,…,N},我们的目标是学习一个mask,其有a=(a1,…,aN) ∈ \in ∈RN表示N个特征的权重,根据它们的重要性进行加权,更新第i个特征向量为zi=ai*xi。要学习第i个特征向量的注意力值ai,有两种常见的策略,如下图(a)和(b)。
(a)局部注意力:每个特征都决定其局部注意力,例如对自身使用共享变换函数 Γ \Gamma Γ,即ai= Γ \Gamma Γ(x)。这种局部策略不能完全利用与其它特征的相关性。关于全局注意力,一种方式就是使用更大kernel size的卷积使注意力的学习更加全局化;
另一种方式,如图(b):通过全连接的操作共同学习注意力。但是这通常在计算上很昂贵,并且需要大量的参数,尤其是当特征数量N较大时。
本文提出的关系感知全局注意力,如图( c )所示。其主要思想就是利用与第i个特征相关的成对关系(例如,相似性),来表示该特征节点的全局结构信息。特别地,使用Ri,j表示第i个特征和第j个特征之间的相似性。则对于第i个特征xi,其相似性向量为Ri=[Ri,1,…,Ri,N,R1,i,…,RN,i]。如何理解该Ri,Ri,1,…,Ri,N表示的是第i个特征与其它特征之间的关系,而R1,i,…,RN,i则表示的是其它特征与第i个特征之间的关系。听上去感觉有点重复?但是论文中解释这样加上去效果会好,而我自己的理解就是,“我(i)认为我跟别人(1,…,N)是好朋友,但是别人(1,…,N)却不一定认为跟我(i)是好朋友”,即Ri,1,…,Ri,N和R1,i,…,RN,i表示的相似性可能是不同的。

1、Spatial Relation-Aware Attention 空间关系感知注意力—RGA-S
通过CNN层得到的特征图为的shape为HWC,设计的RGA-S空间关系感知注意力来学习大小为H*W的空间注意力图,取每个空间位置的C维特征向量作为特征节点。所有的空间形成位置形成一个有N=WxH个节点的图形,通过建立空间中节点之间的相似性矩阵,即NxN的矩阵,来表示节点之间的成对关系。
RGA-S的实现如下图所示:

为了方便解释RGA-S如何具体实现,我们以经过第一个残差块res1_layer的RGA-S1为例来给予说明,其它的RGA-S实现于此一样,只不过是特征图的H和W不一样而已。经过数据增强输入图片的shape为3x256x128,首先经过Zeropadding,然后是步长stride=2的卷积块(Conv+BN+Relu),得到的shape为64x128x64,再经过stride=2的MaxPooling,得到的shape为64x64x32,经过残差网络的第一个残差块,其中的卷积步长stride=1,得到res1_layer的shape为256x64x32,作为RGA-S1的输入。
RGA-S1的输入input为256x64x32,两个去向,如上图所示,一个是向右做embedding操作,即嵌入全局信息。具体做法是经过一个1x1卷积进行降维,将通道数减少为 256/8 =32,得到g_xs,此时shape为32x64x32,由于我们需要实现的是空间注意力机制,因此沿着通道数方向,进行mean求平均操作,将64维通道数使用其均值进行替代,此时g_xs的shape维1x64x32。第二个去向向下的操作,首先经过一个1x1卷积进行降维,将通道数减少为 256/8 =32,此时shape为32x64x32,记为theta_xs;进行了两次这样的操作,另一个记为phi_xs,shape同样为32x64x32。然后我们将theta_xs和phi_xs进行reshape操作,reshape为32x(64x32)=32x2048,然后再将theta_xs经过一次维度的调换permute,故此时的shape为2048x32,而phi_xs的shape为32x2048,于是将theta_xs和phi_xs进行矩阵的乘法,得到Gs,shape为2048x2048,至此Gs表示的就是该特征图空间中2048个特征节点之间的成对关系。首先找到我和别人的成对关系,将Gs进行reshape操作得到Gs_out,shape为 2048,64,32。其次,找到别人和我之间的成对关系,于是将Gs进行维度调换permute操作,得到的shape为2048x2048,再进行reshape操作得到Gs_in,shape为2048,64,32,进行关系对的堆叠cat操作,得到Gs_joint,shape为2048+2048=4096,64,32,然后再将Gs_joint进行1x1操作将4096浓缩成2048/8=256, 使用256维来代表空间成对关系,此时Gs_joint的shape变为256,64,32。于是,将全局的信息与空间中特征点之间的关系进行堆叠操作,得到ys,shape为257,64,32,再将关系维度使用1x1卷积进行浓缩,先将维度压缩成257/8=32,再使用1x1卷积压缩为1,shape为1,64,32,即我们得到了1个特征图上空间中特征节点之间的关系,输入input的shape为256,64,32,我们直到空间中的特征节点在即使在不同的特征图中其位置是不变的,于是我们将上述得到的一个特征节点关系特征图进行repeat操作,得到256个关系特征图,shape变为1,64,32->256,64,32,然后求sigmoid,转化为0-1之间的概率值,最后于输入input进行相乘操作,得到最后的输出256,64,32,即输出带有空间注意力的特征节点值。
空间关系感知全局注意力的具体代码实现如下:
讯享网 if self.use_spatial: self.gx_spatial = nn.Sequential( nn.Conv2d(in_channels=self.in_channel, out_channels=self.inter_channel, kernel_size=1, stride=1, padding=0, bias=False), nn.BatchNorm2d(self.inter_channel), nn.ReLU()) if self.use_channel: self.gx_channel = nn.Sequential( nn.Conv2d(in_channels=self.in_spatial, out_channels=self.inter_spatial, kernel_size=1, stride=1, padding=0, bias=False), nn.BatchNorm2d(self.inter_spatial), nn.ReLU()) if self.use_spatial: self.gg_spatial = nn.Sequential( nn.Conv2d(in_channels=self.in_spatial * 2, out_channels=self.inter_spatial, kernel_size=1, stride=1, padding=0, bias=False), nn.BatchNorm2d(self.inter_spatial), nn.ReLU()) if self.use_channel: self.gg_channel = nn.Sequential( nn.Conv2d(in_channels=self.in_channel*2, out_channels=self.inter_channel, kernel_size=1, stride=1, padding=0, bias=False), nn.BatchNorm2d(self.inter_channel), nn.ReLU()) if self.use_spatial: self.theta_spatial = nn.Sequential( nn.Conv2d(in_channels=self.in_channel, out_channels=self.inter_channel, kernel_size=1, stride=1, padding=0, bias=False), nn.BatchNorm2d(self.inter_channel), nn.ReLU()) self.phi_spatial = nn.Sequential( nn.Conv2d(in_channels=self.in_channel, out_channels=self.inter_channel, kernel_size=1, stride=1, padding=0, bias=False), nn.BatchNorm2d(self.inter_channel), nn.ReLU()) if self.use_channel: self.theta_channel = nn.Sequential( nn.Conv2d(in_channels=self.in_spatial, out_channels=self.inter_spatial, kernel_size=1, stride=1, padding=0, bias=False), nn.BatchNorm2d(self.inter_spatial), nn.ReLU()) self.phi_channel = nn.Sequential( nn.Conv2d(in_channels=self.in_spatial, out_channels=self.inter_spatial, kernel_size=1, stride=1, padding=0, bias=False), nn.BatchNorm2d(self.inter_spatial), nn.ReLU()) def forward(self, x): b, c, h, w = x.size() # 空间注意力机制 if self.use_spatial: # 输入的进行向下分支操作 # 1x1卷积进行降维 256,64,32 --> 32,64,32 theta_xs = self.theta_spatial(x) # 1x1卷积进行降维 256,64,32 --> 32,64,32 phi_xs = self.phi_spatial(x) # 进行维度的reshape操作 32,64,32 --> 32,2048 theta_xs = theta_xs.view(b, self.inter_channel, -1) # 进行维度的调换 32,2048 --> 2048,32 用于后续矩阵相乘 theta_xs = theta_xs.permute(0, 2, 1) # 2,64,32 --> 32,2048 phi_xs = phi_xs.view(b, self.inter_channel, -1) # 矩阵相乘 2048,2048 得到成对关系矩阵 Gs = torch.matmul(theta_xs, phi_xs) # 2048,2048 --> 2048,64,32 我和别人的关系 Gs_out = Gs.view(b, h * w, h, w) # 2048,2048 --> 2048,64,32 别人和我的关系 Gs_in = Gs.permute(0, 2, 1).view(b, h*w, h, w) # 关系进行堆叠操作 4096,64,32 Gs_joint = torch.cat((Gs_in, Gs_out), 1) # 进行关系的浓缩 4096,64,32 --> 256,64,32 Gs_joint = self.gg_spatial(Gs_joint) # 输入进行向右分支的操作 嵌入全局信息 # 1x1卷积降维 减少通道数 256,64,32 --> 32,64,32 g_xs = self.gx_spatial(x) # 32,64,32 --> 1,64,32 g_xs = torch.mean(g_xs, dim=1, keepdim=True) # 257,64,32 ys = torch.cat((g_xs, Gs_joint), 1) # 257,64,32 --> 32,64,32 --> 1,64,32 W_ys = self.W_spatial(ys) if not self.use_channel: out = F.sigmoid(W_ys.expand_as(x)) * x return out else: # 空间上施加注意力机制操作 x = F.sigmoid(W_ys.expand_as(x)) * x
2、Channel Relation-Aware Attention 通道关系感知注意力—RGA-C
空间注意力RGA-S和通道注意力RGA-C起到的是互补的作用,两者都可以应用于卷积的任何阶段,并且可以进行端到端的训练,不需要任何额外的辅助监督。即可以单独使用也可以组合使用。论文中经过实验,按顺序进行RGA-S和RGA-C的使用训练难度较低,其中按照先进行RGA-S,再进行RGA-C结果为**。
给定一个中间特征图为的shape为HWC,设计的RGA-C空间关系感知注意力来学习一个通道数为C的通道注意力向量,将每个通道数上的d=HxW维特征向量作为特征节点,所有通道形成C个节点的图形,通过建立节点之间的相似性矩阵,即CxC的矩阵,来表示节点之间的成对关系。
RGA-C的实现如下图所示:其实现过程几乎和RGA-S是一样的。

还是以第一个残差块为例来说明RGA-C的具体实现,上述我们实现了RGA-S1,RGA-C1就是在RGA-S1之后进一步来实现通道关系感知全局注意力。我们得到RGA-S1的输出256x64x32来作为RGA-C1的输入。
RGA-C1的输入input为256x64x32,先对input进行reshape操作,shape为256x2048,再进行维度的调换permute操作,shape为2048x256,unsqueeze操作,得到xc,shape为2048,256,1。由于我们是在通道上实现关系感知全局注意力,因此需要将特征形式转化为与RGA-S1类似的输入形式。得到的新输入xc有两个去向,如上图所示,一个是向右做embedding操作,即嵌入全局信息。具体做法是经过一个1x1卷积进行降维,将通道数减少为 256/8 =32,得到g_xc,此时shape为32x256x1,由于我们需要实现的是空间注意力机制,因此沿着空间的方向,进行mean求平均操作,将32维空间特征使用其均值进行替代,此时g_xc的shape维1x256x1。第二个去向向下的操作,首先经过一个1x1卷积进行降维,将通道数减少为 256/8 =32,此时shape为32x256x1,记为theta_xc;进行了两次这样的操作,另一个记为phi_xc,shape同样为32x256x1。将theta_xc和phi_xc进行squeeze操作,去掉最后一个维度,因为我们计算关系矩阵时只需要二维的,此时theta_xc和phi_xc的shape都为32x256,再将theta_xc进行permute维度调换操作,shape为256x32,为了进行矩阵乘法操作,然后将theta_xc和phi_xc进行矩阵的乘法,得到Gc,shape为256x256,至此Gc表示的就是该特征图通道上256个特征节点之间的成对关系。首先找到我和别人的成对关系,将Gc进行unsqueeze操作得到Gc_out,shape为 256,256,1。其次,找到别人和我之间的成对关系,于是将Gs进行维度调换permute操作,得到的shape为256x256,再进行unsqueeze操作得到Gc_in,shape为256,256,1,进行关系对的堆叠cat操作,得到Gc_joint,shape为256+256=512,256,1,然后再将Gc_joint进行1x1操作将512浓缩成256/8=32, 使用32维来代表通道上特征节点间关系,此时Gc_joint的shape变为32,256,1 。最后,将全局的信息与空间中特征点之间的关系进行堆叠操作,得到yc,shape为33,256,1,再将关系维度使用1x1卷积进行浓缩,先将维度压缩成33/8=4,再使用1x1卷积压缩为1,shape为1,256,1,最后再进行维度的调换permute,shape变为 256,1,1,。即我们得到了在通道维度上256个特征节点之间的关系,然后求sigmoid,转化为0-1之间的概率值,最后与输入input256x64x32进行相乘操作,得到最后的输出256,64,32,即输出带有通道注意力的特征节点值。

通道关系感知全局注意力的具体代码实现如下:
if self.use_channel: # channel attention # 256,64,32 --> 256,2048 --> 2048,256 --> 2048,256,1 xc = x.view(b, c, -1).permute(0, 2, 1).unsqueeze(-1) theta_xc = self.theta_channel(xc).squeeze(-1).permute(0, 2, 1) phi_xc = self.phi_channel(xc).squeeze(-1) Gc = torch.matmul(theta_xc, phi_xc) Gc_in = Gc.permute(0, 2, 1).unsqueeze(-1) Gc_out = Gc.unsqueeze(-1) Gc_joint = torch.cat((Gc_in, Gc_out), 1) Gc_joint = self.gg_channel(Gc_joint) g_xc = self.gx_channel(xc) g_xc = torch.mean(g_xc, dim=1, keepdim=True) yc = torch.cat((g_xc, Gc_joint), 1) W_yc = self.W_channel(yc).transpose(1, 2) out = F.sigmoid(W_yc) * x return out 3、网络预测的整体过程
input(3,256,128) --> Conv1(64,128,64) --> Pool1(64,64,32) --> Res1+RGA-S1+RGA-C1(256,64,32) --> Res2+RGA-S2+RGA-C2(512,32,16) --> Res3+RGA-S3+RGA-C3(1024,16,8) --> Res4+RGA-S4+RGA-C4(1024,16,8) -->Avg_Pool(,2048)
相关代码为:
讯享网 def forward(self, inputs, training=True): im_input = inputs[0] # N,2048,16,8 feat_ = self.backbone(im_input) # N,2048,1,1 --> N,2048 feat_ = F.avg_pool2d(feat_, feat_.size()[2:]).view(feat_.size(0), -1) feat = self.feat_bn(feat_) if self.dropout > 0: feat = self.drop(feat) if training and self.num_classes is not None: # N,2048 --> N,num_classes cls_feat = self.cls(feat) if training: return (feat_, feat, cls_feat) else: return (feat_, feat)
三、如何利用网络预测结果进行特征匹配得到最后的识别准确率
假设我们的查询库中有M个人的图片,即需要去匹配这M个人在摄像头中哪些场合出现过,而待匹配的这些图像我们称之为图像库,即我们的图像库中记录着不同的人在不同的场合出现过,假设图像库中有N张图片。于是,我们进行网络的前向传播,分别得到M张图片和N张图片的编码特征向量,我们可以利用特征向量计算出距离,距离可以是欧式距离或者余弦距离等,于是构建出M x N的距离矩阵,也就是相似度矩阵,距离越小相似度越高。每一个查询的图片都对应返回图像库N张图片N个距离的结果,于是对距离进行升序排序,利用行人再识别中通用的评估指标rank1和map值来得到最后的识别准确率。
根据上面,我们知道输入一张查询的图片,首先会计算它与图像库中N张图像的距离,按距离进行升序排序,然后按顺序返回相应的图片,假设返回排名前十的图片,如下图所示:

rank1指的就是第一个返回结果正确,如果M个查询图片中第一个返回结果正确m个,则rank1的值为m / M,当然rank1的值越高识别的准确率越高,rank1的值大于等于0,小于等于1。
Map值的计算,Map要计算多次输入的综合ap结果,每张测试图像的计算如下:

ap = (1+2/3+3/6+4/9+5/10)/5 = 0.62,也就是一张正确图像本应该是第几个。理想的ap值就应该是(1+2/2+3/3+4/4+5/5+…+10/10)/10=1,也就是返回的每个位置都是与测试图像相似的图像。
输入第二张测试图像,其ap值得计算:

ap=(1/2+2/5+3/7)/3= 0.44,则Map的计算为:(0.62+0.44)/=0.53。
具体预测的代码如下:
class ImgEvaluator(object): def __init__(self, model, file_path, flip_embedding=False): super(ImgEvaluator, self).__init__() self.model = model self.file_path = file_path # 图片的标准化操作 self.normlizer = torchvision.transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) # 数据增强 翻转 if flip_embedding: self.flipper = torchvision.transforms.RandomHorizontalFlip(p=1.0) print ('[Info] Flip Embedding is OPENED in evaluation!') else: self.flipper = None print ('[Info] Flip Embedding is CLOSED in evaluation!') self.to_pil = torchvision.transforms.ToPILImage() self.to_tensor = torchvision.transforms.ToTensor() def eval_worerank(self, query_loader, gallery_loader, query, gallery, metric, types_list, cmc_topk=(1, 5, 10)): query_features_list, _ = extract_features(self.model, query_loader, \ self.normlizer, self.flipper, self.to_pil, self.to_tensor, types_list) gallery_features_list, _ = extract_features(self.model, gallery_loader, \ self.normlizer, self.flipper, self.to_pil, self.to_tensor, types_list) query_features = {
} gallery_features = {
} for feat_name in types_list: x_q = torch.cat([query_features_list[feat_name][f].unsqueeze(0) for f, _, _ in query], 0) x_q = x_q.view(x_q.size(0), -1) query_features[feat_name] = x_q x_g = torch.cat([gallery_features_list[feat_name][f].unsqueeze(0) for f, _, _ in gallery], 0) x_g = x_g.view(x_g.size(0), -1) gallery_features[feat_name] = x_g query_ids = [pid for _, pid, _ in query] gallery_ids = [pid for _, pid, _ in gallery] query_cams = [cam for _, _, cam in query] gallery_cams = [cam for _, _, cam in gallery] for feat_name in types_list: for dist_type in metric: print('Evaluated with "{}" features and "{}" metric:'.format(feat_name, dist_type)) x = query_features[feat_name] y = gallery_features[feat_name] m, n = x.size(0), y.size(0) # Calculate the distance matrix if dist_type == 'euclidean': dist = torch.pow(x, 2).sum(dim=1, keepdim=True).expand(m, n) + \ torch.pow(y, 2).sum(dim=1, keepdim=True).expand(n, m).t() dist.addmm_(1, -2, x, y.t()) elif dist_type == 'cosine': x = F.normalize(x, p=2, dim=1) y = F.normalize(y, p=2, dim=1) dist = 1 - torch.mm(x, y.t()) else: raise NameError # Compute mean AP mAP = mean_ap(dist, query_ids, gallery_ids, query_cams, gallery_cams) print('Mean AP: {:4.1%}'.format(mAP)) # Compute CMC scores cmc_configs = {
'rank_results':dict(separate_camera_set=False,single_gallery_shot=False, first_match_break=True)} cmc_scores = {
name: cmc(dist, query_ids, gallery_ids,query_cams, gallery_cams, **params) for name, params in cmc_configs.items()} print('CMC Scores') for k in cmc_topk: print(' top-{:<4}{:12.1%}'.format(k, cmc_scores['rank_results'][k-1])) return 四、网络的训练部分
1、loss函数的计算
上面提到,当进行网络的训练时,网络的输出结果应该是两个,即输入图像的编码特征向量和类别的分类结果,即shape为(batch,2048)和(batch,n_classes)。编码的特征向量用于计算三元组损失Triplet loss,类别的结果用于计算类别损失。采用这两个损失函数,是为了能让特征提取更好!
分类损失
对于分类损失,采用了平滑标签的交叉熵损失函数。具体的实现代码如下:
讯享网class CrossEntropyLabelSmoothLoss(nn.Module): """Cross entropy loss with label smoothing regularizer. Reference: Szegedy et al. Rethinking the Inception Architecture for Computer Vision. CVPR 2016. Equation: y = (1 - epsilon) * y + epsilon / K. Args: num_classes (int): number of classes. epsilon (float): weight. """ def __init__(self, num_classes, epsilon=0.1, use_gpu=True): super(CrossEntropyLabelSmoothLoss, self).__init__() self.num_classes = num_classes self.epsilon = epsilon self.use_gpu = use_gpu self.logsoftmax = nn.LogSoftmax(dim=1) def forward(self, inputs, targets): """ Args: inputs: prediction matrix (before softmax) with shape (batch_size, num_classes) targets: ground truth labels with shape (num_classes) """ log_probs = self.logsoftmax(inputs) # 进行one-hot编码 batch,num_classes targets = torch.zeros(log_probs.size()).scatter_(1, targets.unsqueeze(1).cpu(), 1) if self.use_gpu: targets = targets.cuda() # 进行标签平滑 targets = (1 - self.epsilon) * targets + self.epsilon / self.num_classes loss = (- targets * log_probs).mean(0).sum() return loss```c
三元组损失
重点就是三元组损失,首先三元组损失需要准备3份数据(我们都是从一个batch中进行选取的),其包含的信息如下图所示:

其中Anchor表示当前的数据,Positive是跟Anchor相同人的数据,而Negative则是与Anchor不同人的数据。三元组损失计算的流程大致如下:

一个batch中取出这3份数据,然后输入到统一的CNN网络进行特征编码,3份数据是权值共享的,得到编码的特征向量后,然后计算差异,通过差异来更新权重参数。
Triplet三元组损失函数的公式如下:

f表示的就是CNN进行特征提取,a通常叫做margin,也就是间隔,表示d(A,P)和d(A,N)至少得相差多少,但是我们直到A和P是相同的数据,它们的距离肯定很小,而A和N是不同的数据,距离自然很大。因此在实际中,我们在三元组损失中添加了hard negative mining的方法,具体做法就是,假设我们的一个batch中共8张图像,其中前四张是同一个人的一组图像,而后四张与前四张不是同一个人的一组图像,我们假设第一章图像就是当前的数据,对于hard negative,我们就是在第2-4张图像中,找到与当前数据距离最大的图像,即使||f(A)-f§||尽可能的很大,而在后四张图像中找到与当前数据距离最小的图像,即使||f(A)-f(N)||尽可能的很小。也就是在选择样本的时候让d(A,P)和d(A,N)尽可能相等,给网络一些挑战,才能刺激它来学习!!
具体的三元组损失的代码如下:
class TripletHardLoss(object): def __init__(self, margin=None, metric="euclidean"): self.margin = margin self.metric = metric if margin is not None: self.ranking_loss = nn.MarginRankingLoss(margin=margin) else: self.ranking_loss = nn.SoftMarginLoss() def __call__(self, global_feat, labels, normalize_feature=False): # global_feat N,2048 if normalize_feature: global_feat = normalize(global_feat, axis=-1) if self.metric == "euclidean": # 计算batch之间的相互距离 dist_mat = euclidean_dist(global_feat, global_feat) elif self.metric == "cosine": dist_mat = cosine_dist(global_feat, global_feat) else: raise NameError dist_ap, dist_an = hard_example_mining( dist_mat, labels) y = dist_an.new().resize_as_(dist_an).fill_(1) if self.margin is not None: loss = self.ranking_loss(dist_an, dist_ap, y) else: loss = self.ranking_loss(dist_an - dist_ap, y) prec = (dist_an.data > dist_ap.data).sum() * 1. / y.size(0) return loss 2、数据集的介绍
数据集我们采用的是公开数据集香港中文大学CUHK03校园行人数据集,5组摄像头拍摄的共1467张图片。就第一张图片信息而言:第一个1表示的是摄像头组的id,我们这里是第一组摄像头,接着后面的001表示是第1个人,002则表示第2个人…,类别的id,再后面的1表示的是一组摄像头中的第一个摄像头,2表示的是第一组摄像头中部的第2个摄像头,最后的01表示的是一个人共拍摄了10张图像,即一个人图像的id编号。

3、训练细节
对于输入的图像,使用常规的数据增强策略,即随机裁剪、水平翻转和随机擦除等操作。将输入图像的大小统一crop为256x128。主干特征提取网络在ImageNet上进行了预训练,优化器选择Adam优化器,学习率设置为8x10-4,权重衰减为5x10-4。
4、如何训练自己的RGA模型
RGA的整体文件摆放如下:

其中data/cuhk03中存放了训练需要的CUHK03数据集。models中是主干特征网络ResNet50,以及RGA模块。logs存放的是训练信息,包括了训练的保存的权重参数。loss存放的是loss两个函数。weights存放的是云训练的ResNet50模型。默认运行main_imgreid即可进行模型的训练,如果将参数evaluate设置为true,即可进行图像的预测,注意保存好的模型的路径的导入!!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/126884.html