
mysql实现hive的explod、lateral view功能
1、概括
hive的explod和lateral view的功能相当于是把一条数据的某个字段的数据变成多条数据,然后这条数据关联返回多条数据。
例如一条数据为(1,‘a,b,c,d,e’) explod和就会把它转为一下五条数据
1,a 1,b 1,c 1,d 1,e 讯享网
hive的这个函数在mysql类型的数据库并没有,所以要想实现这种功能需要自己通过join笛卡尔积来实现。
2、数据准备
1 建表
讯享网 CREATE TABLE dim_rank_config( `id` bigint(20) NOT NULL COMMENT 'id', `rank_num` int(11) NOT NULL COMMENT '排序', PRIMARY KEY (`id`), unique uni_index_rank (`rank_num`) ) ENGINE = InnoDB COMMENT ='序号配置表'; CREATE TABLE dwd_log_content( `id` bigint(20) NOT NULL COMMENT 'id', `json_content` text NOT NULL COMMENT 'json数据', `text_content` text NOT NULL COMMENT '文本数据', PRIMARY KEY (`id`) ) ENGINE = InnoDB COMMENT ='数据表';
2、造数据
insert into dim_rank_config values (0, 0) ,(1, 1) ,(2, 2) ,(3, 3) ,(4, 4) ,(5, 5) ,(6, 6) ,(7, 7) ,(8, 8) ,(9, 9); replace into dwd_log_content values (1,"[{\"id\":1000,\"sku_name\":\"小米13\",\"price\":3599},{\"id\":1001,\"sku_name\":\"iphone14\",\"price\":5699},{\"id\":1002,\"sku_name\":\"huawei P6\",\"price\":4699}]",'mi,iphone,huawei') ,(2,"[{\"id\":1003,\"sku_name\":\"OPPO FindX6\",\"price\":6399},{\"id\":1004,\"sku_name\":\"meizu20\",\"price\":3999},{\"id\":1005,\"sku_name\":\"oneplus11\",\"price\":3199}]",'oppo,onplus,meizu') ,(3,"[{\"id\":1006,\"sku_name\":\"vivoX90\",\"price\":4599},{\"id\":1007,\"sku_name\":\"红米K60\",\"price\":3299},{\"id\":1008,\"sku_name\":\"红米K60U\",\"price\":2699}]",'vivo,redmi') ,(4,"[{\"id\":1009,\"sku_name\":\"samsung\",\"price\":6999}]",'samsung') ; 3、Json数组数据打散
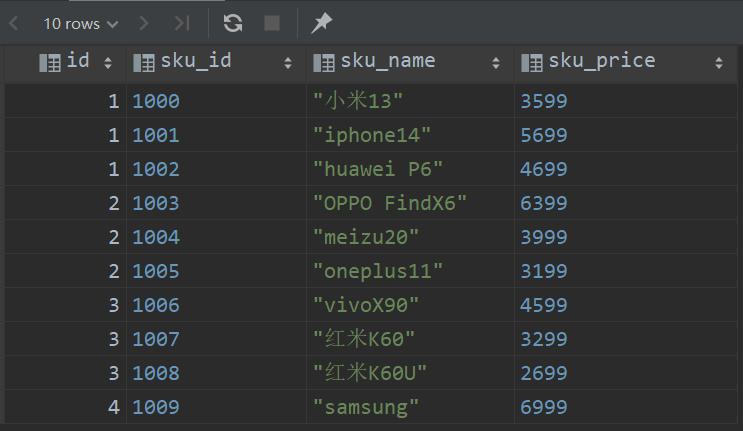
第一条数据,json数组里面是[1000,1001,1002],查询出来应该为
讯享网1,1000,小米13,3599 1,1001,iphone14,5699 1,1002,huawei P6,4699
第二条数据,json数组里面是[1003,1004,1005],查询出来应该为
1,1003,OPPO FindX6,6399 1,1004,meizu20,3999 1,1005,oneplus11,3199 第三条数据,json数组里面是[1006,1007,1008],查询出来应该为
讯享网1,1006,vivoX90,4599 1,1007,红米K60,3299 1,1008,红米K60U,2699
第四条数据,json数组里面是[1009],查询出来应该为
1,10069,samsung,6999 查询sql
讯享网select id, JSON_EXTRACT(js_data, '$.id') as sku_id, JSON_EXTRACT(js_data, '$.sku_name') as sku_name, JSON_EXTRACT(js_data, '$.price') as sku_price from ( select log.id, JSON_EXTRACT(json_content, concat('$[', r.rank_num, ']')) as js_data from dwd_log_content log join dim_rank_config r ) res where js_data is not null order by id,sku_id
查询结果

上面查询的sql可以优化一下,如果dim_rank_config表有很大的数据(N条),那么每条数据查询数据量有N条,可以用一下sql来查询
select id, JSON_EXTRACT(js_data, '$.id') as sku_id, JSON_EXTRACT(js_data, '$.sku_name') as sku_name, JSON_EXTRACT(js_data, '$.price') as sku_price from ( select log.id, r.rank_num, JSON_EXTRACT(json_content, concat('$[', r.rank_num, ']')) as js_data from ( select log.id,json_content,json_length(json_content) as js_len from dwd_log_content log ) log join dim_rank_config r on r.rank_num < log.js_len )res order by id,sku_id 如果dwd_log_content有M条数据,每天数据有K个JSON数组,dim_rank_config表有N条数据,其中N>=K
那么第一个sql笛卡尔积量:
M*N
Σ M ∗ N \Sigma M*N ΣM∗N
第二个sql笛卡尔积量:
Σ M ∗ K \Sigma M*K ΣM∗K
最后优化后可以少查询
Σ M ∗ ( N − K ) \Sigma M*(N-K) ΣM∗(N−K)
所以建议使用第二种查询
4、字符串指定分隔符打散
字符串按照指定分隔,mysql系统自带函数没有像java的split函数把字符串切割成数组,只有substring_index函数,该函数的功能是 从一个字符串中返回指定出现次数的定界符之前的子字符串,如a,b,c,d,e,f,用substring_index函数用逗号分隔,第一个是获取的是a,第二个是a,b,第三个是a,b,c,故需要处理下。最后sql如下
讯享网select id, text_content, rank_num, replace(substring(curr_content, length(last_content) + 1), ',', '') as content from ( select t.id, t.text_content, r.rank_num, substring_index(t.text_content, ',', r.rank_num - 1) as last_content, substring_index(t.text_content, ',', r.rank_num) as curr_content from ( select id, text_content, length(text_content) - length(replace(text_content, ',', '')) + 1 as len from dwd_log_content ) t join dim_rank_config r on r.rank_num > 0 and r.rank_num <= t.len ) res order by id, rank_num ;
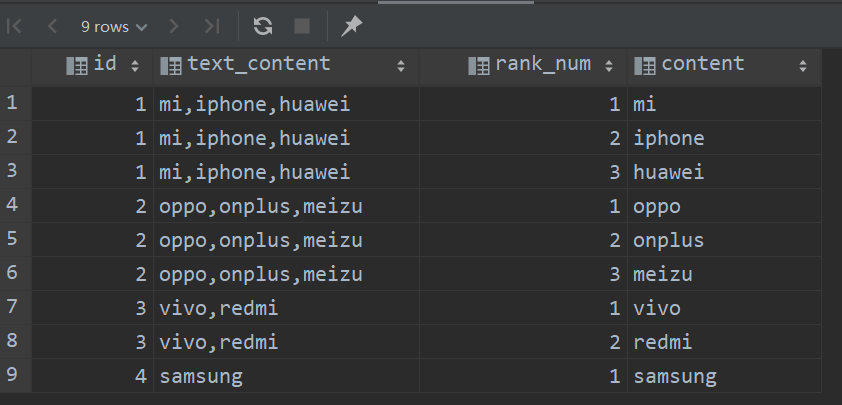
5、结尾
tent
) t
join dim_rank_config r on r.rank_num > 0 and r.rank_num <= t.len
) res
order by id, rank_num
;
[外链图片转存中...(img-J0ThoIu2-46)] 5、结尾 通过mysql内置的函数也能实现类似的hive的explod功能,不过稍微绕一点,其原理都是差不多的。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/125348.html